Teil 5 des Tutorials zu Real-Time Analytics: Verwenden erweiterter KQL-Abfragen
Hinweis
Dieses Tutorial ist Teil einer Reihe. Den vorherigen Abschnitt finden Sie unter Teil 4 des Tutorials: Untersuchen Ihrer Daten mit KQL und SQL.
Erstellen eines KQL-Abfragesets
Im folgenden Schritt verwenden Sie die erweiterten Datenanalysefunktionen der Kusto-Abfragesprache zum Abfragen der beiden Tabellen, die Sie in der Datenbank erfasst haben.
Navigieren Sie zu Ihrer KQL-Datenbank namens NycTaxiDB.
Wählen Sie Neues verknüpftes Element>KQL-Abfrageset aus.
Geben Sie nyctaxiqs als KQL-Abfragesetnamen ein.
Klicken Sie auf Erstellen. Das KQL-Abfrageset wird mit mehreren automatisch aufgefüllten Beispielabfragen geöffnet.

Daten abfragen
In diesem Abschnitt werden einige der Abfrage- und Visualisierungsfunktionen des KQL-Abfragesets erläutert. Kopieren Sie die Abfragen, und fügen Sie sie in Ihren eigenen Abfrage-Editor ein, um die Ergebnisse auszuführen und zu visualisieren.
Führen Sie die folgende Abfrage aus, um die 10 besten Abholorte in New York City für Yellow Taxis zurückzugeben.
nyctaxitrips | summarize Count=count() by PULocationID | top 10 by Count
Diese Abfrage fügt der vorherigen Abfrage einen Schritt hinzu. Führen Sie die Abfrage aus, um die entsprechenden Zonen der besten 10 Abholorte mithilfe der Tabelle Orte nachzuschlagen. Der lookup-Operator erweitert die Spalten einer Faktentabelle mit Werten, die in einer Dimensionstabelle nachgeschlagen wurden.
nyctaxitrips | lookup (Locations) on $left.PULocationID == $right.LocationID | summarize Count=count() by Zone | top 10 by Count | render columnchart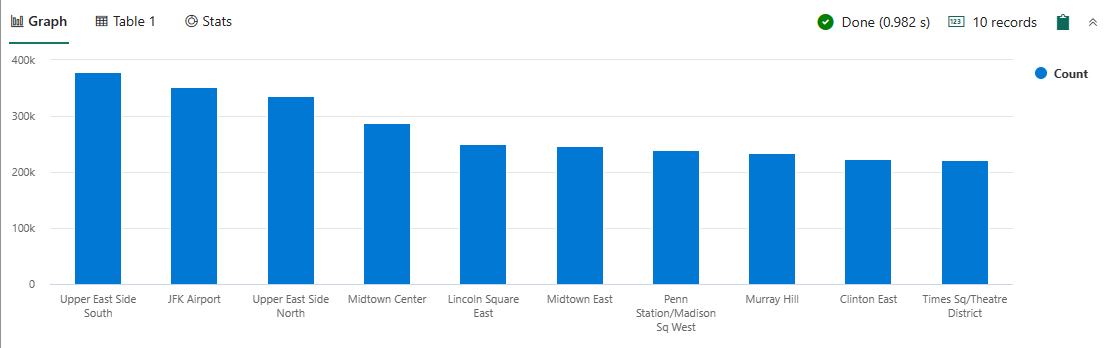
KQL bietet auch Machine Learning-Funktionen zum Erkennen von Anomalien. Führen Sie die folgende Abfrage aus, um Anomalien in den Trinkgeldern der Kunden im Bezirk Manhattan zu überprüfen. Diese Abfrage verwendet die Funktion series_decompose_anomalies.
nyctaxitrips | lookup (Locations) on $left.PULocationID==$right.LocationID | where Borough == "Manhattan" | make-series s1 = avg(tip_amount) on tpep_pickup_datetime from datetime(2022-06-01) to datetime(2022-06-04) step 1h | extend anomalies = series_decompose_anomalies(s1) | render anomalychart with (anomalycolumns=anomalies)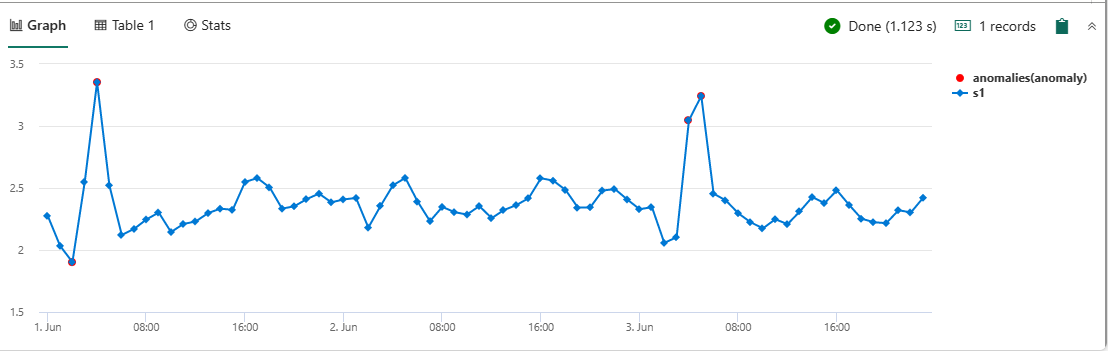
Zeigen Sie auf die roten Punkte, um die Werte der Anomalien zu sehen.
Sie können auch die Vorhersagekraft der series_decompose_forecast-Funktion verwenden. Führen Sie die folgende Abfrage aus, um sicherzustellen, dass ausreichend Taxen im Bezirk Manhattan arbeiten und Sagen Sie die Anzahl der benötigten Taxis pro Stunde vorher.
nyctaxitrips | lookup (Locations) on $left.PULocationID==$right.LocationID | where Borough == "Manhattan" | make-series s1 = count() on tpep_pickup_datetime from datetime(2022-06-01) to datetime(2022-06-08)+3d step 1h by PULocationID | extend forecast = series_decompose_forecast(s1, 24*3) | render timechart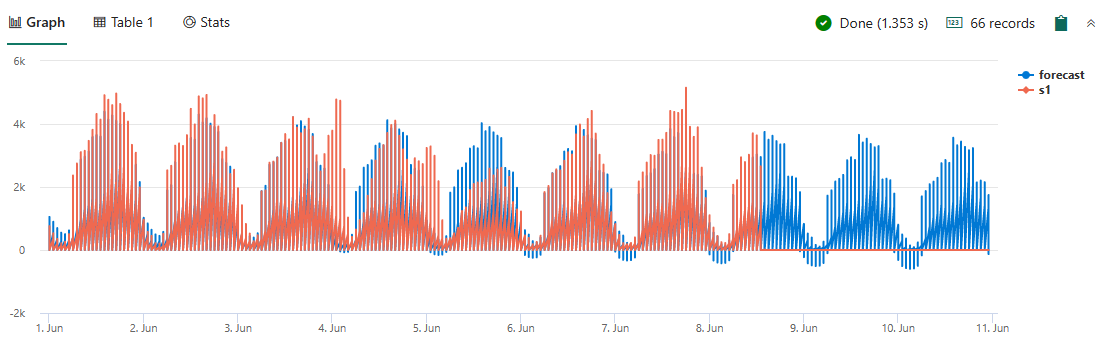



Zugehöriger Inhalt
Weitere Informationen zu Aufgaben, die in diesem Tutorial ausgeführt werden, finden Sie unter:
Nächster Schritt
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für