Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel erfahren Sie, wie Sie Daten aus Azure Storage (ADLS Gen2-Container, BLOB-Container oder einzelne Blobs) abrufen. Sie können Daten kontinuierlich oder als einmalige Aufnahme in Ihre Tabelle aufnehmen. Nach der Erfassung stehen die Daten für die Abfrage zur Verfügung.
Kontinuierliche Datenaufnahme (Vorschau): Die kontinuierliche Datenaufnahme umfasst das Einrichten einer Datenaufnahmepipeline, die es einer Ereignisverwaltung ermöglicht, Azure Storage-Ereignisse zu untersuchen. Die Pipeline benachrichtigt das Ereignishaus, Informationen abzurufen, wenn abonnierte Ereignisse auftreten. Die Ereignisse sind BlobCreated und BlobRenamed.
Von Bedeutung
Dieses Feature befindet sich in der Vorschauphase.
Anmerkung
Ein fortlaufender Aufnahmedatenstrom kann sich auf Ihre Abrechnung auswirken. Weitere Informationen finden Sie unter Eventhouse- und KQL-Datenbanknutzung.
Einmalige Erfassung: Verwenden Sie diese Methode, um Daten aus Azure Storage als einmaligen Vorgang abzurufen.
Voraussetzungen
- Ein Arbeitsbereich mit einer Microsoft Fabric-fähigen Kapazität
- Eine KQL-Datenbank mit Bearbeitungsberechtigungen.
- Ein Speicherkonto.
Für eine kontinuierliche Aufnahme benötigen Sie auch Folgendes:
Eine Arbeitsbereichsidentität. Mein Arbeitsbereich wird nicht unterstützt. Erstellen Sie bei Bedarf einen neuen Arbeitsbereich.
Aktivieren Sie den hierarchischen Namespace auf dem Speicherkonto.
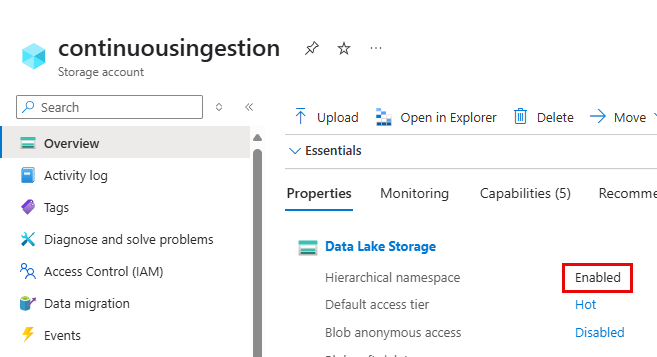
Rollenberechtigungen für den Speicher-Blob-Datenleser, die der Arbeitsbereichsidentität zugewiesen sind.
Ein Container zum Speichern der Datendateien.
Eine In den Container hochgeladene Datendatei. Die Datendateistruktur wird verwendet, um das Tabellenschema zu definieren. Weitere Informationen finden Sie unter Datenformate, die von Real-Time Intelligenceunterstützt werden.
Anmerkung
Sie müssen eine Datendatei hochladen:
- Vor der Konfiguration zum Definieren des Tabellenschemas während der Einrichtung.
- Nach der Konfiguration, um die kontinuierliche Aufnahme auszulösen, um Daten in der Vorschau anzuzeigen und die Verbindung zu überprüfen.
Fügen Sie die Rollenzuweisung der Identität des Arbeitsbereichs zum Speicherkonto hinzu
Kopieren Sie in den Arbeitsbereichseinstellungen in Fabric Ihre Arbeitsbereichsidentitäts-ID.
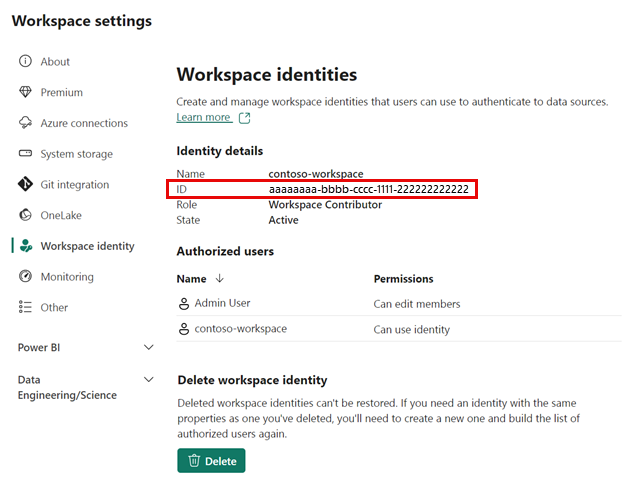
Navigieren Sie im Azure-Portal zu Ihrem Azure Storage-Konto, und wählen Sie Access Control (IAM)>">" aus.
Wählen Sie den Speicher-BLOB-Datenleser aus.
Wählen Sie im Dialogfeld " Rollenzuweisung hinzufügen " +Mitglieder auswählen.
Fügen Sie die Arbeitsbereichsidentitäts-ID ein, wählen Sie die Anwendung aus, und wählen Sie dann ">Überprüfen+ zuweisen" aus.
Erstellen eines Containers mit Datendatei
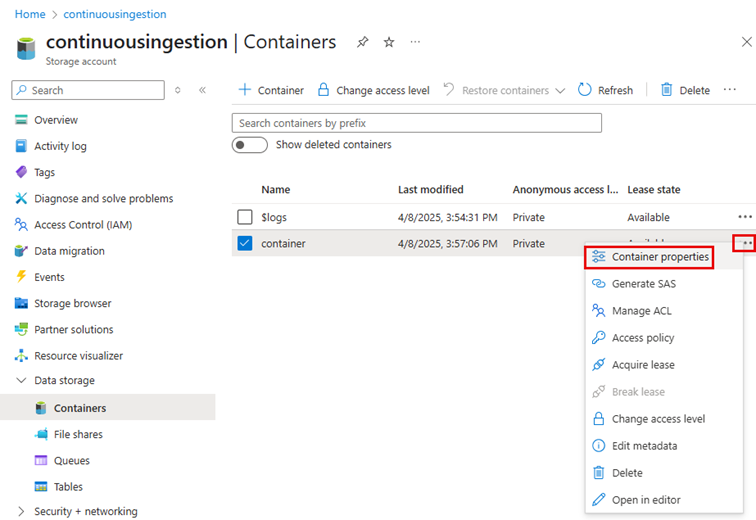
Wählen Sie im Speicherkonto "Container" aus.
Wählen Sie +Container aus, geben Sie einen Namen für den Container ein, und wählen Sie "Speichern" aus.
Geben Sie den Container ein, wählen Sie "Hochladen" aus, und laden Sie die zuvor vorbereitete Datendatei hoch.
Weitere Informationen finden Sie unter unterstützten Formaten und unterstützten Komprimierungen.
Wählen Sie im Kontextmenü [...]Containereigenschaften aus, und kopieren Sie die URL, die während der Konfiguration eingegeben werden soll.
Quelle
Legen Sie die Quelle fest, um Daten abzurufen.
Öffnen Sie in Ihrem Arbeitsbereich das EventHouse, und wählen Sie die Datenbank aus.
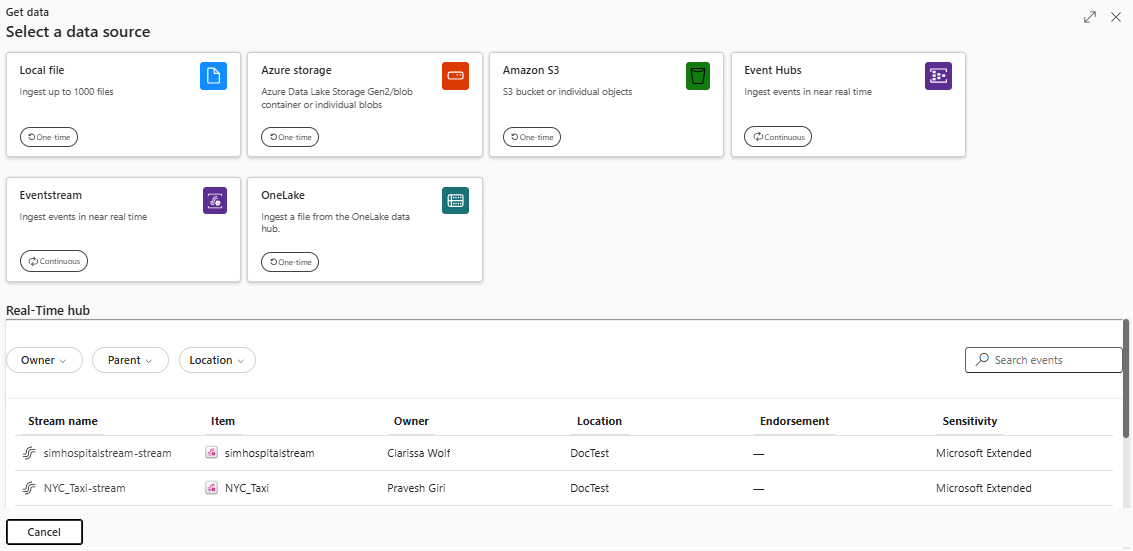
Wählen Sie im Menüband der KQL-Datenbank die Option "Daten abrufen" aus.
Wählen Sie die Datenquelle aus der verfügbaren Liste aus. In diesem Beispiel nehmen Sie Daten aus Azure Storageein.

Konfigurieren
Wählen Sie eine Zieltabelle aus. Wenn Sie Daten in eine neue Tabelle aufnehmen möchten, wählen Sie + Neue Tabelle aus, und geben Sie einen Tabellennamen ein.
Anmerkung
Tabellennamen können bis zu 1.024 Zeichen umfassen und alphanumerische Zeichen, Bindestriche und Unterstriche enthalten. Sonderzeichen werden nicht unterstützt.
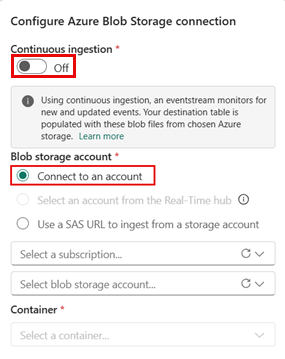
Stellen Sie in der Verbindung "Azure Blob Storage konfigurieren" sicher, dass die kontinuierliche Aufnahme aktiviert ist. Sie ist standardmäßig aktiviert.
Konfigurieren Sie die Verbindung, indem Sie eine neue Verbindung erstellen oder eine vorhandene Verbindung verwenden.
So erstellen Sie eine neue Verbindung:
Wählen Sie "Mit einem Speicherkonto verbinden" aus.
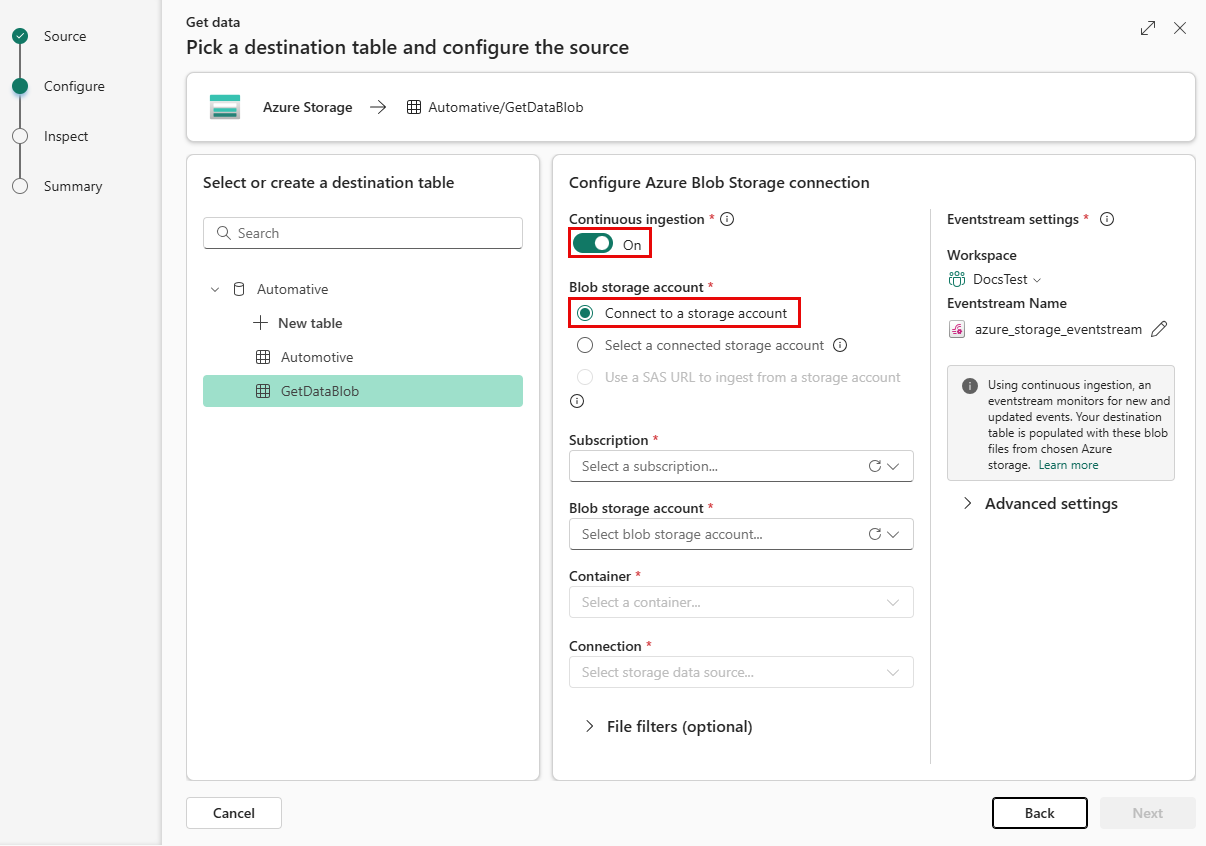
Verwenden Sie die folgenden Beschreibungen, um die Felder auszufüllen.
Einstellung Feldbeschreibung Abonnement Das Speicherkontoabonnement. Blob-Speicherkonto Speicherkontoname. Behälter Der Speichercontainer, der die Datei enthält, die Sie importieren möchten. Öffnen Sie im Feld "Verbindung" das Dropdownmenü, und wählen Sie "+ Neue Verbindung", dann Speichern>Schließen. Die Verbindungseinstellungen sind vorgefüllt.
Anmerkung
Das Erstellen einer neuen Verbindung führt zu einem neuen Eventstream. Der Name wird als <storate_account_name>_eventstream definiert. Stellen Sie sicher, dass Sie den Ereignisstream für die kontinuierliche Erfassung nicht aus dem Arbeitsbereich entfernen.
So verwenden Sie eine vorhandene Verbindung:
Wählen Sie ein vorhandenes Speicherkonto aus.
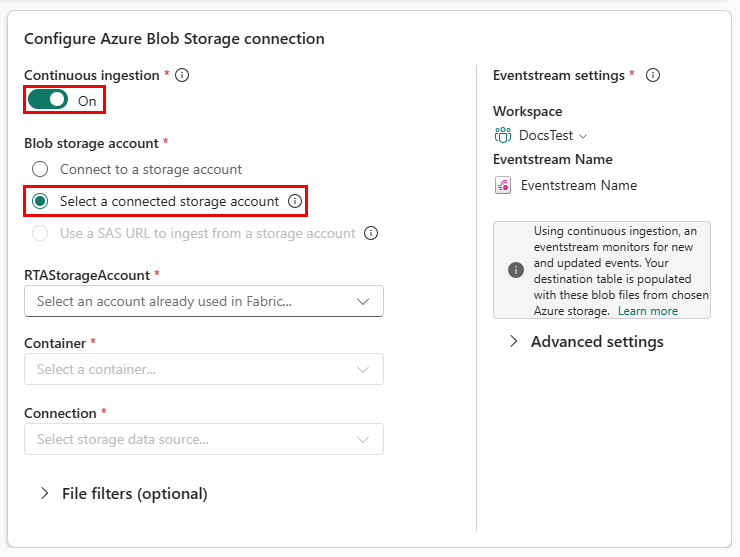
Verwenden Sie die folgenden Beschreibungen, um die Felder auszufüllen.
Einstellung Feldbeschreibung RTAStorageAccount Ein Ereignisdatenstrom, der mit Ihrem Speicherkonto über Fabric verbunden ist. Behälter Der Speichercontainer, der die Datei enthält, die Sie importieren möchten. Verbindung Dies wird mit der Verbindungszeichenfolge vorab aufgefüllt. Öffnen Sie im Feld "Verbindung " das Dropdownmenü, und wählen Sie die vorhandene Verbindungszeichenfolge aus der Liste aus. Wählen Sie dann Speichern>Schließen aus.
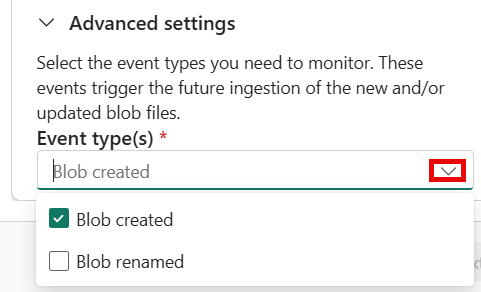
Erweitern Sie optional Dateifilter , und geben Sie die folgenden Filter an:
Einstellung Feldbeschreibung Ordnerpfad Filtert Daten zum Aufnehmen von Dateien mit einem bestimmten Ordnerpfad. Dateierweiterung Filtert Daten, um Dateien nur mit einer bestimmten Dateierweiterung aufzunehmen. Im Abschnitt "Eventstearm-Einstellungen" können Sie die Ereignisse auswählen, die in den Erweiterten Einstellungen unter > überwacht werden sollen. Standardmäßig ist blob created ausgewählt. Sie können auch Blob umbenannt auswählen.
Wählen Sie "Weiter" aus, um eine Vorschau der Daten anzuzeigen.



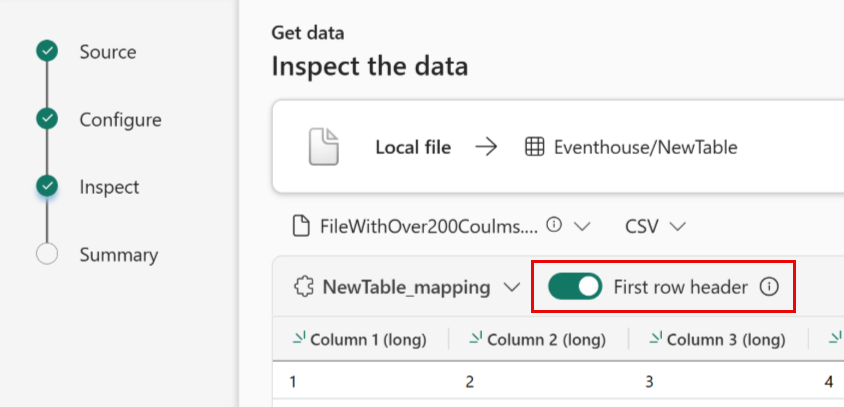
Inspizieren
Die Registerkarte Untersuchen wird mit einer Vorschau der Daten geöffnet.
Um den Erfassungsprozess abzuschließen, wählen Sie Fertig stellen aus.

Anmerkung
Um kontinuierliche Aufnahme- und Vorschaudaten zu erzeugen, stellen Sie sicher, dass Sie nach der Konfiguration ein neues Speicher-Blob hochgeladen haben.
Optionalerweise:
Verwenden Sie das Dropdownmenü der Schemadefinitionsdatei, um die Datei zu ändern, von der das Schema abgeleitet wird.
Verwenden Sie das Dropdownmenü "Dateityp", um erweiterte Optionen basierend auf dem Datentyp zu erkunden.
Verwenden Sie das Dropdown-Menü Table_mapping, um eine neue Zuordnung zu definieren.
Wählen Sie </> aus, um die Befehlsanzeige zu öffnen und die automatisch aus Ihren Eingaben generierten Befehle anzuzeigen und zu kopieren. Sie können die Befehle auch in einem Queryset öffnen.
Wählen Sie das Bleistiftsymbol aus, um Spalten zu bearbeiten.
Spalten bearbeiten
Anmerkung
- Bei tabellarischen Formaten (CSV, TSV, PSV) können Sie eine Spalte nicht zweimal zuordnen. Löschen Sie bei einer Zuordnung zu einer vorhandenen Spalte zunächst die neue Spalte.
- Sie können keinen vorhandenen Spaltentyp ändern. Wenn Sie versuchen, einer Spalte ein abweichendes Format zuzuordnen, könnte dies zu leeren Spalten führen.
Die Änderungen, die Sie in einer Tabelle vornehmen können, hängen von den folgenden Parametern ab:
- Tabellentyp ist neu oder vorhanden
- Die Zuordnung ist neu oder vorhanden.
| Tabellentyp | Zuordnungstyp | Verfügbare Anpassungen |
|---|---|---|
| Neue Tabelle | Neue Zuordnung | Spalte umbenennen, Datentyp ändern, Datenquelle ändern, Zuordnungstransformation, Spalte hinzufügen, Spalte löschen |
| Vorhandene Tabelle | Neue Zuordnung | Spalte hinzufügen (auf der Sie dann den Datentyp ändern, sie umbenennen und aktualisieren können) |
| Vorhandene Tabelle | Vorhandene Zuordnung | nichts |

Zuordnungstransformationen
Einige Datenformatzuordnungen (Parquet, JSON und Avro) unterstützen einfache Transformationen während der Erfassung. Erstellen oder aktualisieren Sie zum Anwenden von Zuordnungstransformationen eine Spalte im Fenster Spalten bearbeiten.
Zuordnungstransformationen können für eine Spalte vom Typ "Zeichenfolge" oder "datetime" ausgeführt werden, wobei die Quelle den Datentyp "int" oder "long" aufweist. Weitere Informationen finden Sie in der vollständigen Liste der unterstützten Zuordnungstransformationen.
Erweiterte Optionen basierend auf dem Datentyp
Tabellarisch (CSV, TSV, PSV):
Wenn Sie Tabellenformate in eine bestehende Tabelle übernehmen, wählen Sie Erweitert>Tabellenschema beibehalten aus. Tabellarische Daten enthalten nicht unbedingt die Spaltennamen, die zum Zuordnen von Quelldaten zu den vorhandenen Spalten verwendet werden. Wenn diese Option aktiviert ist, erfolgt die Zuordnung nach Reihenfolge, und das Tabellenschema bleibt gleich. Wenn diese Option deaktiviert ist, werden neue Spalten für eingehende Daten erstellt, unabhängig von der Datenstruktur.
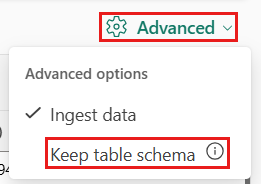
Tabellarische Daten enthalten nicht unbedingt die Spaltennamen, die zum Zuordnen von Quelldaten zu den vorhandenen Spalten verwendet werden. Wählen Sie Erste Zeile ist Spaltenüberschrift aus, um die erste Zeile als Spaltennamen zu verwenden.
Tabellarisch (CSV, TSV, PSV):
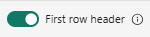
Wenn Sie tabellarische Formate in einer vorhandenen Tabelle aufnehmen, können Sie Table_mapping>Vorhandenes Schema verwenden auswählen. Tabellarische Daten enthalten nicht unbedingt die Spaltennamen, die zum Zuordnen von Quelldaten zu den vorhandenen Spalten verwendet werden. Wenn diese Option aktiviert ist, erfolgt die Zuordnung nach Reihenfolge, und das Tabellenschema bleibt gleich. Wenn diese Option deaktiviert ist, werden neue Spalten für eingehende Daten erstellt, unabhängig von der Datenstruktur.
Wenn Sie die erste Zeile als Spaltennamen verwenden möchten, wählen Sie die Überschrift " Erste Zeile" aus.
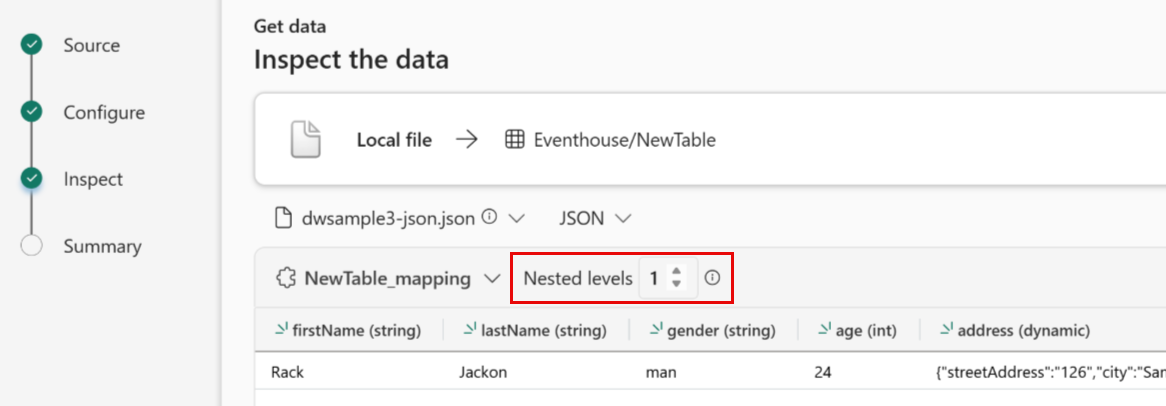
JSON:
Um die Spaltenteilung von JSON-Daten zu bestimmen, wählen Sie "Geschachtelte Ebenen" von 1 bis 100 aus.
Zusammenfassung
Im Zusammenfassungsfenster werden alle Schritte mit grünen Häkchen gekennzeichnet, wenn die Datenaufnahme erfolgreich abgeschlossen ist. Sie können eine Karte auswählen, um die Daten zu durchsuchen, die aufgenommenen Daten zu löschen oder ein Dashboard mit wichtigen Metriken zu erstellen.

Wenn Sie das Fenster schließen, können Sie die Verbindung auf der Registerkarte "Explorer" unter "Datenströme" sehen. Von hier aus können Sie die Datenströme filtern und einen Datenstrom löschen.


Verwandte Inhalte
- Informationen zum Verwalten ihrer Datenbank finden Sie unter Verwalten von Daten
- Informationen zum Erstellen, Speichern und Exportieren von Abfragen finden Sie unter Abfragen von Daten in einem KQL-Abfrageset.