Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Allgemeine Informationen zur Erkennung von multivariaten Anomalien in Real-Time Intelligence finden Sie unter Erkennung von multivariaten Anomalien in Microsoft Fabric – Überblick. In diesem Lernprogramm verwenden Sie Beispieldaten, um ein multivariates Anomalieerkennungsmodell mithilfe des Spark-Moduls in einem Python-Notizbuch zu trainieren. Anschließend prognostizieren Sie Anomalien, indem Sie das trainierte Modell mithilfe der Eventhouse-Engine auf neue Daten anwenden. In den ersten Schritten werden Ihre Umgebungen eingerichtet, und in den folgenden Schritten wird das Modell trainiert und Anomalien werden vorhergesagt.
Voraussetzungen
- Ein Arbeitsbereich mit einer Microsoft Fabric-fähigen Kapazität
- Admin-, Mitglieds- oder Contributor-Rolle in einem Arbeitsbereich. Diese Berechtigungsstufe ist erforderlich, um Objekte wie z. B. eine Umgebung zu erstellen.
- Ein Eventhouse in Ihrem Arbeitsbereich mit einer Datenbank.
- Laden Sie die Beispieldaten aus dem GitHub Repo herunter
- Laden Sie das Notebook von der GitHub-Website herunter
Teil 1: Aktivieren der OneLake-Verfügbarkeit
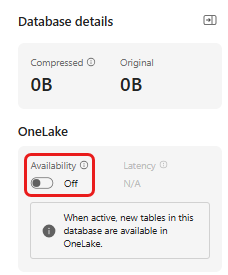
Die Verfügbarkeit von OneLake muss aktiviert sein, bevor Sie Daten im Eventhouse abrufen. Dieser Schritt ist wichtig, da er dafür sorgt, dass die Daten, die Sie importieren, in OneLake verfügbar werden. In einem späteren Schritt greifen Sie auf dieselben Daten in Ihrem Spark Notebook zu, um das Modell zu trainieren.
Wählen Sie in Ihrem Arbeitsbereich das Eventhouse aus, das Sie in den Voraussetzungen erstellt haben. Wählen Sie die Datenbank, in der Sie Ihre Daten speichern möchten.
Schalten Sie im Bereich Datenbankdetails die Schaltfläche "OneLake-Verfügbarkeit" auf Ein um.
Teil 2: Aktivieren des KQL Python-Plug-Ins
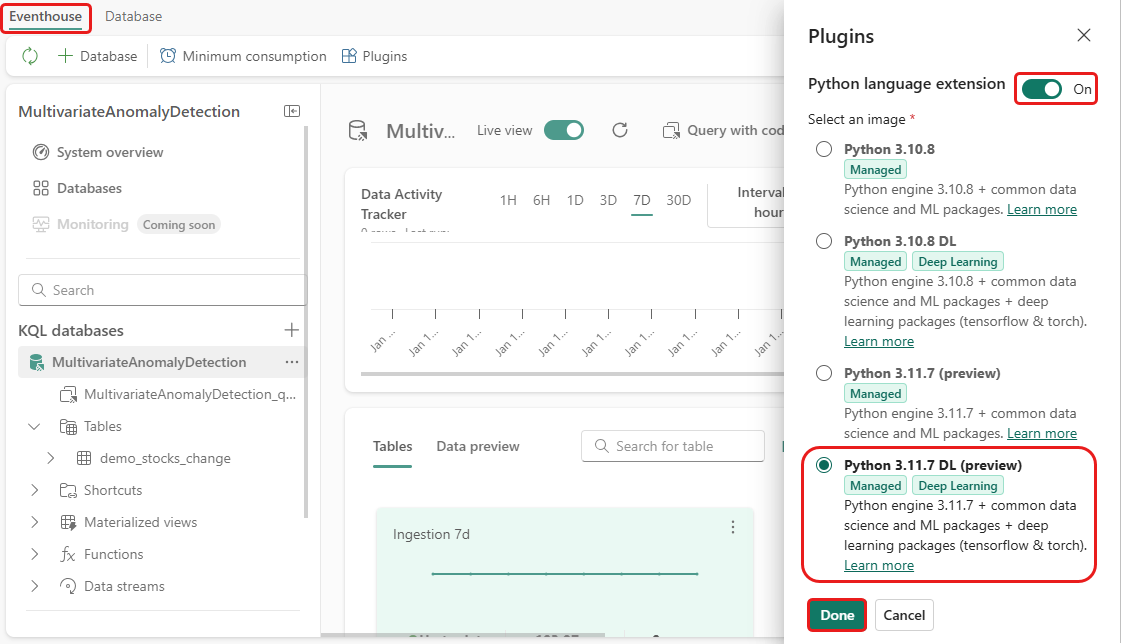
In diesem Schritt aktivieren Sie das Python-Plug-In in Ihrem Eventhouse. Dieser Schritt ist erforderlich, um den Python-Code zur Vorhersage von Anomalien im KQL-Abfragesatz auszuführen. Es ist wichtig, das richtige Paket auszuwählen, das das Paket time-series-anomaly-detector enthält.
Wählen Sie im Eventhouse-Bildschirm im Menüband Eventhouse>Plug-Ins aus.
Schalten Sie im Plug-In-Bereich die Python-Spracherweiterung auf Ein um.
Wählen Sie Python 3.11.7 DL (Vorschau) aus.
Wählen Sie Fertig aus.

Teil 3: Erstellen einer Spark-Umgebung
In diesem Schritt erstellen Sie eine Spark-Umgebung, um das Python-Notebook auszuführen, das das Modell zur Erkennung von multivariaten Anomalien mit der Spark-Engine trainiert. Weitere Informationen zum Erstellen von Umgebungen finden Sie unter Erstellen und Verwalten von Umgebungen.
Wählen Sie in Ihrem Arbeitsbereich + Neues Element und dann Umgebung aus.
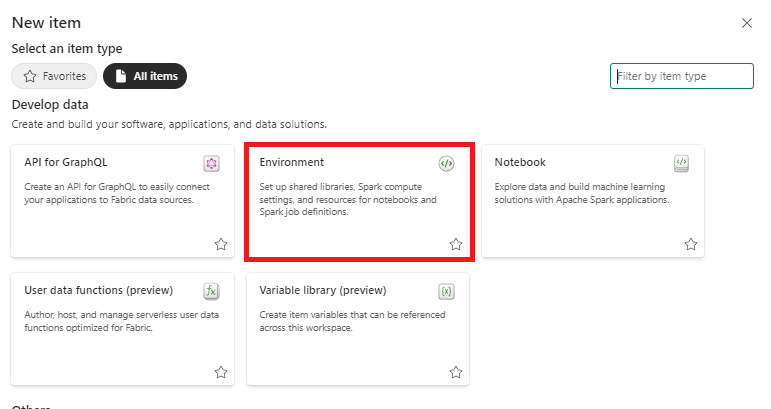
Geben Sie für die Umgebung den Namen MVAD_ENV ein, und wählen Sie dann Erstellen aus.
Wählen Sie unter Bibliotheken die Option Öffentliche Bibliotheken aus.
Wählen Sie Hinzufügen aus PyPI aus.
Geben Sie im Suchfeld time-series-anomaly-detector ein. Das Versionsfeld wird automatisch mit der neuesten Version aufgefüllt. Ändern Sie sie in Version 0.3.9, die die neueste Version ist, die mit MLflow 2.19.0 kompatibel ist (die aktuelle Version im Python-Image)
Wählen Sie Speichern.

Wählen Sie in der Umgebung die Registerkarte Start.
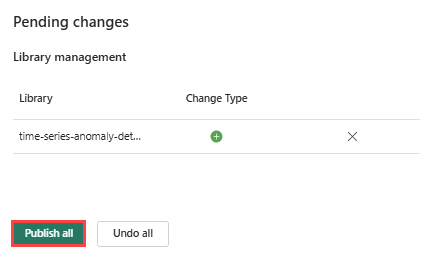
Wählen Sie Veröffentlichen im Menüband aus.

Wählen Sie Alle veröffentlichen aus. Dieser Schritt kann mehrere Minuten dauern.


Teil 4: Abrufen von Daten in das Eventhouse
Bewegen Sie den Mauszeiger über die KQL-Datenbank, in der Sie Ihre Daten speichern möchten. Wählen Sie das Menü "Weitere" [...]aus>Daten abrufen>Lokale Datei.
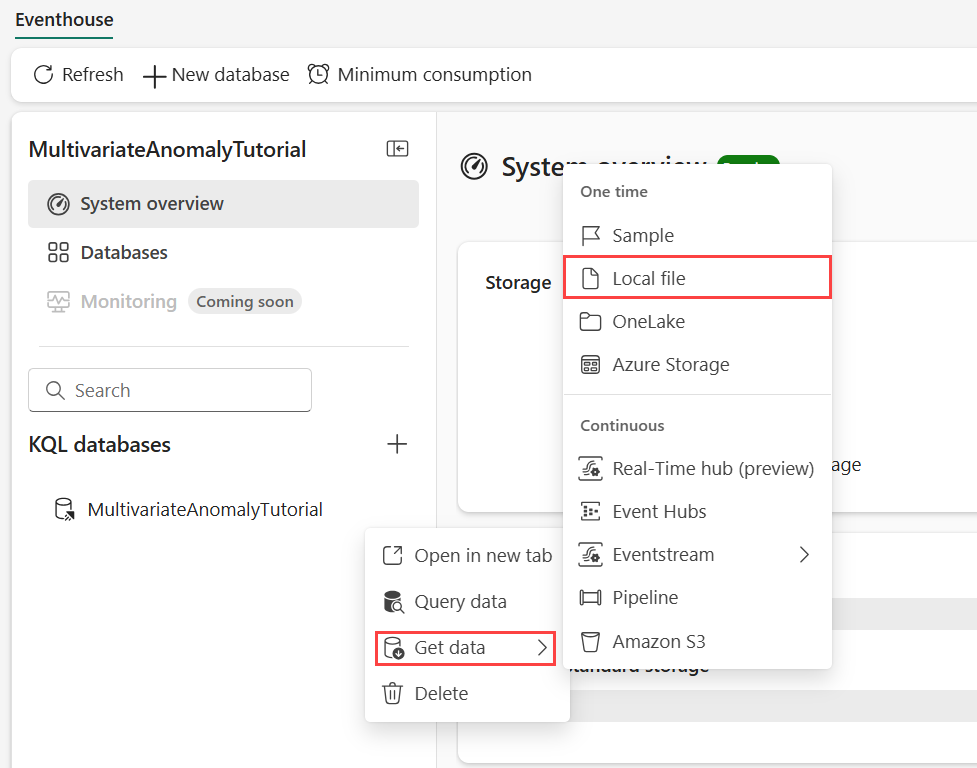
Wählen Sie + Neue Tabelle aus, und geben Sie demo_stocks_change als Tabellennamen ein.
Wählen Sie im Dialogfeld Daten hochladen die Option Nach Dateien suchen und laden Sie die Beispieldatendatei hoch, die Sie im Abschnitt Voraussetzungen heruntergeladen haben
Wählen Sie Weiter aus.
Überprüfen Sie im Abschnitt "Daten untersuchen", ob "Erste Zeile ist Spaltenüberschrift" auf "Ein" steht.
Wählen Sie Fertig stellen aus.
Wenn die Daten hochgeladen sind, wählen Sie Schließen.
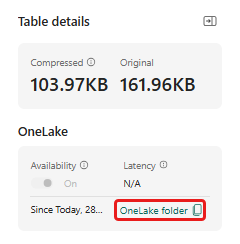
Teil 5: Kopieren des OneLake-Pfads in die Tabelle
Stellen Sie sicher, dass Sie die Tabelle demo_stocks_change auswählen. Wählen Sie im Bereich Tabellendetails den OrdnerOneLake aus, um den OneLake-Pfad in die Zwischenablage zu kopieren. Speichern Sie den kopierten Text in einem Texteditor, um ihn in einem späteren Schritt zu verwenden.
Teil 6: Vorbereiten des Notebooks
Wählen Sie Ihren Arbeitsbereich aus.
Wählen Sie Import, Notebook und dann Von diesem Computer aus.
Wählen Sie Hochladen und wählen Sie das Notebook, das Sie unter den Voraussetzungen heruntergeladen haben, aus.
Nachdem das Notebook hochgeladen wurde, können Sie es in Ihrem Arbeitsbereich suchen und öffnen.
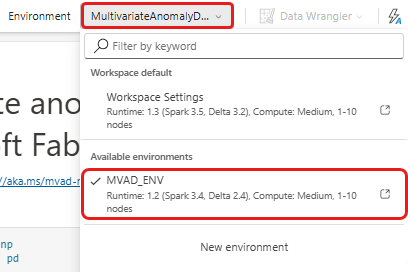
Wählen Sie in der oberen Multifunktionsleiste das Dropdown-Menü Arbeitsbereichs-Standard und wählen Sie die Umgebung, die Sie im vorherigen Schritt erstellt haben.
Teil 7: Ausführen des Notebooks
Importieren Sie Standardpakete.
import numpy as np import pandas as pdSpark benötigt eine ABFSS-URI, um sich sicher mit dem OneLake-Speicher zu verbinden. Daher wird im nächsten Schritt diese Funktion definiert, um die OneLake-URI in eine ABFSS-URI zu konvertieren.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriErsetzen Sie den Platzhalter OneLakeTableURI durch den OneLake-URI, den Sie in Teil 5: Kopieren des OneLake-Pfads in die Tabelle kopiert haben, um die Tabelle demo_stocks_change in einen Pandas-Dataframe zu laden.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Führen Sie die folgenden Zellen aus, um die Trainings- und Vorhersagedatenrahmen vorzubereiten.
Hinweis
Die eigentlichen Vorhersagen werden mit den Daten des Eventhouse in Teil 9: Vorhersage von Anomalien im KQL-Abfrageset durchgeführt. In einem Produktionsszenario, wenn Sie Daten in das Eventhouse streamen, würden die Vorhersagen auf der Grundlage der neuen Streaming-Daten erstellt. Für den Zweck des Lernprogramms wurde der Datensatz nach Datum in zwei Abschnitte für Training und Vorhersage aufgeteilt. Dies dient der Simulation von historischen Daten und neuen Streaming-Daten.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Führen Sie die Zellen aus, um das Modell zu trainieren und speichern Sie es in der Fabric MLflow-Modell-Registrierung.
from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)model_name = "mvad_5_stocks_model"import mlflow with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name=model_name, )Führen Sie die folgende Zelle aus, um den registrierten Modellpfad zu extrahieren, der für die Vorhersage mithilfe der Kusto Python-Sandbox verwendet werden soll.
from mlflow.tracking import MlflowClient client = MlflowClient() mvs = client.search_model_versions(f"name='{model_name}'") latest = max(mvs, key=lambda v: v.creation_timestamp) model_abfss = latest.source print(model_abfss)Kopieren Sie den Modell-URI aus der Ausgabe der letzten Zelle, um ihn in einem späteren Schritt zu verwenden.
Teil 8: Einrichten des KQL-Abfragesets
Allgemeine Informationen finden Sie unter Erstellen eines KQL-Abfragesets.
- Klicken Sie in Ihrem Arbeitsbereich auf + Neues Element>KQL-Abfrageset.
- Geben Sie den Namen MultivariateAnomalyDetectionTutorial ein, und klicken Sie dann auf Erstellen.
- Wählen Sie im OneLake Data Hub-Fenster die KQL-Datenbank aus, in der Sie die Daten gespeichert haben.
- Wählen Sie Verbinden.
Teil 9: Vorhersagen von Anomalien im KQL-Abfrageset
Führen Sie die folgende Abfrage ".create-or-alter function" aus, um die gespeicherte funktion
predict_fabric_mvad_fl()zu definieren:.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Führen Sie die folgende Vorhersageabfrage aus, und ersetzen Sie den Ausgabemodell-URI durch den URI, der am Ende von Schritt 7 kopiert wurde.
Die Abfrage erkennt multivariate Anomalien auf den fünf Aktien basierend auf dem trainierten Modell und rendert die Ergebnisse als
anomalychart. Die anomalen Punkte werden auf der ersten Aktie (AAPL) dargestellt, obwohl sie multivariate Anomalien darstellen (mit anderen Worten, Anomalien der gemeinsamen Veränderungen der fünf Aktien an einem bestimmten Datum).let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
Das resultierende Anomalie-Diagramm sollte wie das folgende Bild aussehen:

Bereinigen von Ressourcen
Wenn Sie das Löschen abgeschlossen haben, können Sie die Ressourcen löschen, die Sie erstellt haben, um andere Kosten zu vermeiden. Um die Ressourcen zu löschen, gehen Sie wie folgt vor:
- Navigieren Sie zu Ihrer Arbeitsbereichs-Homepage.
- Löschen Sie die in diesem Lernprogramm erstellte Umgebung.
- Löschen Sie den Notebook, den Sie in diesem Tutorial erstellt haben.
- Löschen Sie das in diesem Tutorial verwendete Eventhouse oder Datenbank.
- Löschen Sie das in diesem Lernprogramm erstellte KQL-Queryset.