Verwenden der Branchendaten-API als ETL-Engine (Extrahieren, Transformieren und Laden) (Vorschau)
Wichtig
Die APIs unter der /beta Version in Microsoft Graph können sich ändern. Die Verwendung dieser APIs in Produktionsanwendungen wird nicht unterstützt. Um festzustellen, ob eine API in v1.0 verfügbar ist, verwenden Sie die Version Selektor.
Die Branchendaten-API ist eine branchenspezifische ETL-Plattform (Extract-Transform-Load), die Daten aus mehreren Quellen in einem einzigen Azure Data Lake-Datenspeicher kombiniert, die Daten normalisiert und in ausgehenden Datenflüssen exportiert. Die API stellt Ressourcen bereit, mit denen Sie Statistiken abrufen können, nachdem die Daten verarbeitet wurden, und die Sie bei der Überwachung und Problembehandlung unterstützen können.
Die Branchendaten-API ist im OData-Unternamespace microsoft.graph.industryDatadefiniert.
Branchendaten-API und Bildungseinrichtungen
Die Branchendaten-API unterstützt die Microsoft School Data Sync (SDS)-Plattform, um den Prozess des Importierens von Daten zu automatisieren und Organisationen, Benutzer- und Benutzerzuordnungen sowie Gruppen mit Microsoft Entra ID und Microsoft 365 aus Sis (Student Information Systems) und Student Management Systems (SMS) zu synchronisieren. Nach dem Normalisieren der Daten verwendet die API die Daten über mehrere ausgehende Bereitstellungsflows, um Benutzer, Klassengruppen, Verwaltungseinheiten und Sicherheitsgruppen zu verwalten.
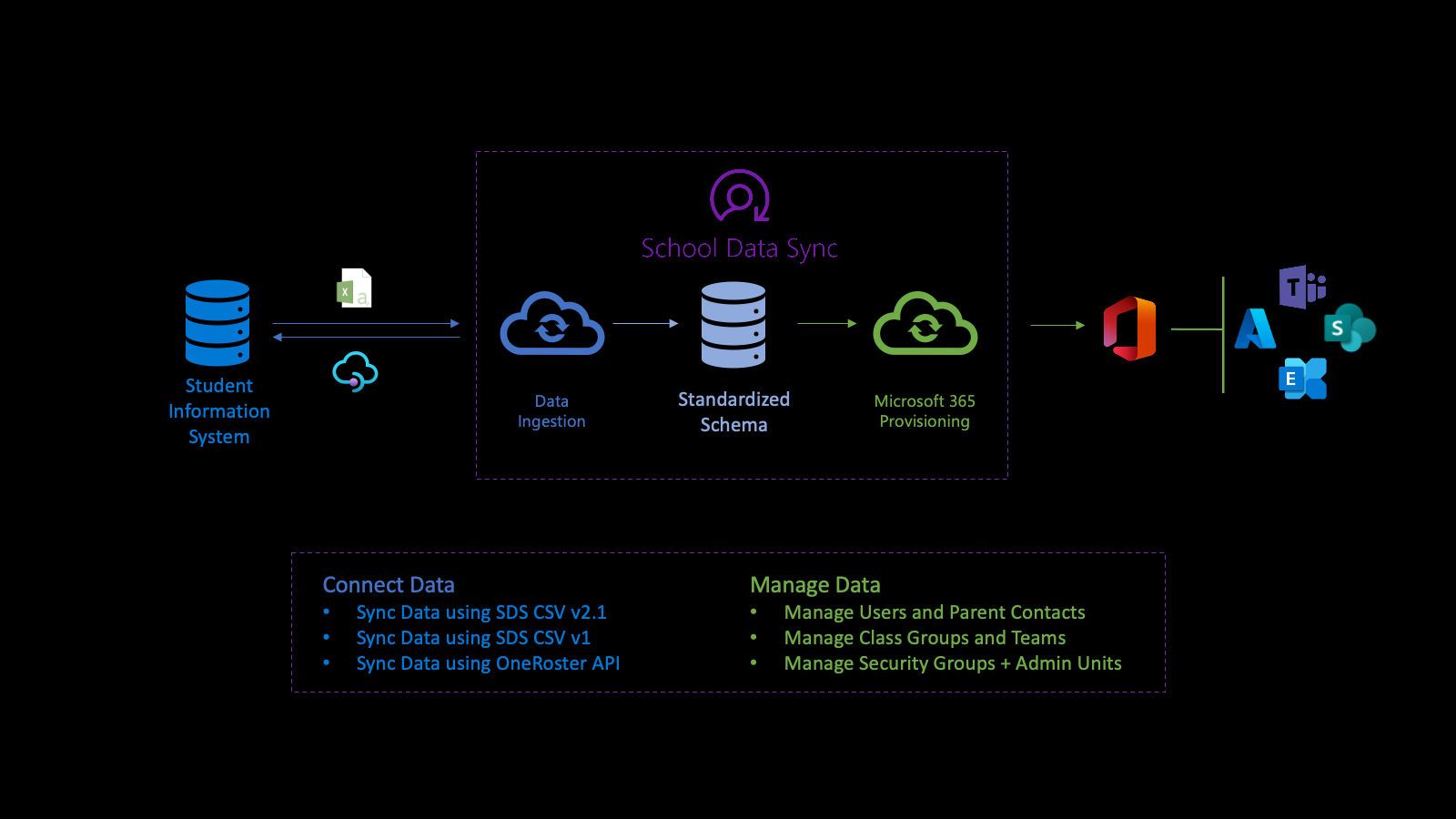
Zunächst stellen Sie eine Verbindung mit den Daten Ihrer Einrichtung her. Um einen eingehenden Flow zu definieren, erstellen Sie eine sourceSystemDefinition, dataConnector und yearTimePeriodDefinition. Standardmäßig wird der eingehende Flow zweimal (2x) täglich aktiviert (als Ausführung bezeichnet).
Wenn die Ausführung gestartet wird, stellt sie eine Verbindung mit sourceSystemDefinition und dataConnector des eingehenden Flows her und führt eine grundlegende Überprüfung durch. Die grundlegende Überprüfung stellt sicher, dass die Verbindung korrekt ist, wenn die OneRoster-API die Quelle ist oder die Dateinamen und Header korrekt sind, wenn eine CSV-Datei die Quelle ist.
Als Nächstes transformiert das System die Daten für den Import, um die erweiterte Validierung vorzubereiten. Im Rahmen der Datentransformation werden die Daten basierend auf der konfigurierten yearTimePeriodDefinition zugeordnet.
Das System speichert die neueste Kopie der Microsoft Entra-ID des Mandanten in Azure Data Lake. Die Kopie von Microsoft Entra hilft beim Abgleich von Benutzern zwischen dem SourceSystemDefinition-Objekt und dem Microsoft Entra-Benutzerobjekt. In dieser Phase wird der Übereinstimmungslink nur in Azure Data Lake geschrieben.
Als Nächstes führt der eingehende Flow eine erweiterte Überprüfung durch, um die Datenintegrität zu bestimmen. Die Überprüfung konzentriert sich auf die Identifizierung von Fehlern und Warnungen, um sicherzustellen, dass gute Daten ein- und ungültige Daten nicht vorhanden sind. Fehler deuten darauf hin, dass ein Datensatz die Überprüfung nicht bestanden hat und aus der weiteren Verarbeitung entfernt wurde. Warnungen zeigen an, dass der Wert in einem optionalen Feld eines Datensatzes nicht übergeben wurde. Der Wert wird aus dem Datensatz entfernt, aber der Datensatz wird zur weiteren Verarbeitung eingeschlossen.
Fehler und Warnungen helfen Ihnen dabei, die Datenintegrität besser zu verstehen.
Für die Daten, die die Überprüfung bestanden haben, verwendet der Prozess die konfigurierte yearTimePeriodDefinition , um seine Zuordnung für den Längsschnittspeicher wie folgt zu bestimmen:
- Wenn die Daten in der internen Darstellung im Azure Data Lake des Mandanten gespeichert werden, wird identifiziert, wann sie von Branchendaten zum ersten Mal erkannt wurden.
- Für Daten, die mit einer Benutzerorganisation, Rollenzuordnung und Gruppenzuordnung verknüpft sind, werden auch Daten basierend auf yearTimePeriodDefinition als aktiv in der Sitzung identifiziert.
- In zukünftigen Ausführungen für denselben eingehenden Flow, sourceSystemDefinition und yearTimePeriodDefinition, identifizieren Branchendaten, ob der Datensatz noch angezeigt wird.
- Basierend auf dem Vorhandensein oder Fehlen eines Datensatzes wird der Datensatz aktiv oder als nicht mehr aktiv in der Sitzung für die konfigurierte yearTimePeriodDefinition markiert. Dieser Prozess bestimmt den historischen und längsschnittsbezogenen Charakter der Daten zwischen Tagen, Monaten und Jahren.
Am Ende jeder Ausführung ist industryDataRunStatistics verfügbar, um die Datenintegrität zu bestimmen.
Fehler und Warnungen im Zusammenhang mit industryDataRunStatistics werden erzeugt, um ein erstes Verständnis der Datenintegrität zu ermöglichen. Wenn Sie die Datenintegrität untersuchen, bieten Branchendaten die Möglichkeit, eine Protokolldatei herunterzuladen, die Informationen basierend auf den Fehlern und Warnungen enthält, die gefunden wurden, um den Datenuntersuchungsprozess zur Korrektur der Daten im Quellsystem zu starten.
Wenn Sie mit dem aktuellen Zustand der Datenintegrität vertraut sind, können Sie nach der Untersuchung und Behandlung von Datenfehlern oder -warnungen die Szenarien mit den Daten aktivieren. Wenn Sie ein Szenario für die Verwendung dieser Daten aktivieren, erstellt das Szenario einen ausgehenden Bereitstellungsflow.
Die Verwaltung von Daten über ausgehende Bereitstellungsflows vereinfacht die Verwaltung von Benutzern und Klassen. Nur aktive und übereinstimmende Benutzer sind in den Daten enthalten, die zum Schreiben des Links zum Microsoft Entra-Benutzerobjekt verwendet werden. Dieser Link erleichtert die Integration zwischen SIS/SMS und ihren Abschnitten für Gruppen und Microsoft Teams-Klassenzimmer.
Weitere Informationen finden Sie in den Abschnitten School Data Sync, SDS-Voraussetzungen und SDS-Kernkonzepte der Übersicht über School Data Sync.
Registrierung, Berechtigungen und Autorisierung
Sie können Branchendaten-APIs in Apps von Drittanbietern integrieren. Ausführliche Informationen dazu finden Sie in den folgenden Artikeln:
- Grundlagen zur Authentifizierung und Autorisierung.
- Registrieren Sie eine Anwendung bei Microsoft Identity Platform.
- Erhalten Sie Zugriff im Namen eines Benutzers.
- Microsoft Graph Berechtigungsreferenz.
- Beheben Sie Microsoft Graph-Autorisierungsfehler.
Allgemeine Anwendungsfälle
| Anwendungsfall | REST-Ressource | Siehe auch |
|---|---|---|
| Erstellen einer Aktivität zum Importieren eines durch Trennzeichen getrennten Datasets | inboundFileFlow | inboundFileFlow-Methoden |
| Definieren einer Quelle eingehender Daten | sourceSystemDefinition | sourceSystemDefinition-Methoden |
| Erstellen eines Connectors zum Veröffentlichen von Daten in azure Data Lake (falls CSV) | azureDataLakeConnector | azureDataLakeConnector-Methoden |
Datendomäne
Die dataDomain-Eigenschaft definiert den Typ der importierten Daten und bestimmt das allgemeine Datenmodellformat, in dem sie gespeichert werden sollen. Derzeit wird educationRosteringnur dataDomain unterstützt.
Referenzdefinitionen
Ein referenceDefinition-Element stellt einen aufgezählten Wert dar. Jede unterstützte Branchendomäne erhält eine eigene Sammlung von Definitionen.
referenceDefinition-Ressourcen werden im gesamten System umfassend verwendet, sowohl für die Konfiguration als auch für die Transformation, wobei die potenziellen Werte für eine bestimmte Branche spezifisch sind. Jede referenceDefinition verwendet einen zusammengesetzten Bezeichner von , {referenceType}-{code} um eine konsistente Erfahrung für kundenmandanten zu bieten.
Referenzwerte
Typen, die auf referenceValue basieren, bieten eine vereinfachte Entwicklerumgebung für das Binden von referenceDefinition-Ressourcen . Jeder referenceValue-Typ ist an einen einzelnen Verweistyp gebunden, sodass Entwickler nur den Codeteil der verweisenden Definition als einfache Zeichenfolge angeben können, um potenzielle Verwirrung darüber zu vermeiden, welcher Typ von referenceDefinition für eine bestimmte Eigenschaft erwartet wird.
Beispiel
Die userMatchingSettings.sourceIdentifier-Eigenschaft akzeptiert einen identifierTypeReferenceValue-Typ , der an den RefIdentifierTypereferenceType gebunden ist.
"sourceIdentifier": {
"code": "username"
},
Ein referenceDefinition-Element kann auch direkt mithilfe der value-Eigenschaft gebunden werden.
"sourceIdentifier": {
"value@odata.bind": "external/industryData/referenceDefinitions/RefIdentifierType-username"
},
Rollengruppen
Die Transformation der Daten wird häufig durch die Rolle jedes einzelnen Benutzers innerhalb einer Organisation bestimmt. Diese Rollen werden als Verweisdefinitionen definiert. Angesichts der Anzahl potenzieller Rollen würde die Bindung der einzelnen Rollen zu einer mühsamen Benutzererfahrung führen.
Rollengruppen sind eine Sammlung von RefRole Codes.
{
"@odata.type": "#microsoft.graph.industryDataRoleGroup",
"id": "37a9781b-db61-4a3c-a3c1-8cba92c9998e",
"displayName": "Staff",
"roles": [
{ "code": "adjunct" },
{ "code": "administrator" },
{ "code": "advisor" },
{ "code": "affiliate" },
{ "code": "aide" },
{ "code": "alumni" },
{ "code": "assistant" }
]
}
Branchendatenconnectors
Ein industryDataConnector fungiert als Brücke zwischen sourceSystemDefinition und inboundFlow. Sie ist für das Abrufen von Daten aus einer externen Quelle und die Bereitstellung der Daten für eingehende Datenflüsse verantwortlich.
Hochladen und Überprüfen von CSV-Daten
Informationen zu CSV-Daten finden Sie unter:
Im Folgenden sind die Anforderungen für die CSV-Datei aufgeführt:
- Bei Dateinamen und Spaltenüberschriften wird die Groß-/Kleinschreibung beachtet.
- CSV-Dateien müssen im UTF-8-Format vorliegen.
- Eingehende Daten dürfen keine Zeilenumbrüche aufweisen.
Informationen zum Überprüfen und Herunterladen eines Beispielsatzes von SDS V2.1-CSV-Dateien finden Sie im SDS-GitHub-Repository.
Wichtig
Der industryDataConnector akzeptiert keine Deltaänderungen, sodass jede Uploadsitzung das vollständige Dataset enthalten muss. Die Angabe von Nur-Teil- oder Deltadaten führt zum Übergang von fehlenden Datensätzen in einen inaktiven Zustand.
Anfordern einer Uploadsitzung
AzureDataLakeConnector verwendet CSV-Dateien, die in einen sicheren Container hochgeladen wurden. Dieser Container befindet sich im Kontext einer einzelnen fileUploadSession und wird automatisch gelöscht, nachdem die Datenüberprüfung oder die Dateiuploadsitzung abläuft.
Die aktuelle Dateiuploadsitzung wird von einem azureDataLakeConnector über die getUploadSession abgerufen, die die SAS-URL zum Hochladen der CSV-Dateien zurückgibt.
Überprüfen hochgeladener Dateien
Hochgeladene Datendateien müssen überprüft werden, bevor ein eingehender Flow die Daten verarbeiten kann. Der Überprüfungsprozess schließt die aktuelle fileUploadSession ab und überprüft, ob alle erforderlichen Dateien vorhanden und ordnungsgemäß formatiert sind. Die Überprüfung wird durch Aufrufen der Aktion industryDataConnector: validate der Ressource azureDataLakeConnector initiiert.
Durch die Überprüfungsaktion wird eine Datei mit langer AusführungsdauerValidateOperation erstellt. Der URI für fileValidateOperation wird im Location Header der Antwort angegeben. Sie können diesen URI verwenden, um den Status des zeitintensiven Vorgangs und alle Fehler oder Warnungen, die während der Überprüfung erstellt wurden, nachzuverfolgen.
Nächste Schritte
Verwenden Sie die Microsoft Graph-Branchendaten-APIs als ETL-Engine (Extrahieren, Transformieren und Laden). So erhalten Sie weitere Informationen:
- Erfahren Sie, welche Ressourcen und Methoden für Ihr Szenario am besten geeignet sind.
- Probieren Sie die API im Graph-Tester aus.
Verwandte Inhalte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für