Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Befolgen Sie die Anweisungen unter Erstellen eines Unternehmensmodells für die Dokumentverarbeitung , um ein strukturiertes oder freihandform-Dokumentverarbeitungsmodell in einem Inhaltscenter zu erstellen. Oder befolgen Sie die Anweisungen unter Erstellen eines Modells auf einer lokalen SharePoint-Website , um das Modell auf einer lokalen Website zu erstellen. Verwenden Sie dann diesen Artikel, um Ihr Modell zu trainieren.

Führen Sie die folgenden Schritte aus, um ein strukturiertes oder freihandform-Dokumentverarbeitungsmodell zu trainieren:
- Schritt 1: Hinzufügen und Analysieren von Dokumenten
- Schritt 2: Markieren von Feldern und Tabellen
- Schritt 3: Trainieren und Veröffentlichen Ihres Modells
- Schritt 4: Verwenden Ihres Modells
Schritt 1: Hinzufügen und Analysieren von Dokumenten
Nachdem Sie Ihr strukturiertes oder freihandform-Dokumentverarbeitungsmodell erstellt haben, wird die Seite Zu extrahierende Informationen auswählen geöffnet. Hier listen Sie alle Informationen auf, die das KI-Modell aus Ihren Dokumenten extrahieren soll, z. B. Name, Adresse oder Betrag.
Hinweis
Wenn Sie nach Beispieldateien suchen, die verwendet werden sollen, lesen Sie die Anforderungen und Optimierungstipps für die Dokumentverarbeitungsmodelleingabe.
Definieren Sie zunächst auf der Seite Informationen zum Extrahieren die Felder und Tabellen, die Ihr Modell lernen soll zu extrahieren. Ausführlich beschriebene Schritte finden Sie unter Definieren von Feldern und Tabellen zum Extrahieren.
Sie können beliebig viele Sammlungen von Dokumentlayouts erstellen, die Ihr Modell verarbeiten soll. Ausführlich beschriebene Schritte finden Sie unter Gruppieren von Dokumenten nach Sammlungen.
Nachdem Sie Ihre Sammlungen erstellt und jeweils mindestens fünf Beispieldateien hinzugefügt haben, untersucht AI Builder die hochgeladenen Dokumente, um die Felder und Tabellen zu erkennen. Dieser Vorgang dauert in der Regel einige Sekunden. Wenn die Analyse abgeschlossen ist, können Sie mit dem Taggen der Dokumente fortfahren.
Schritt 2: Markieren von Feldern und Tabellen
Sie müssen die Dokumente taggen, um dem Modell beizubringen, welche Felder und Tabellendaten extrahiert werden sollen. Ausführlich beschriebene Schritte finden Sie unter Taggen von Dokumenten.
Schritt 3: Trainieren und Veröffentlichen Ihres Modells
Nachdem Sie Ihr Modell erstellt und trainiert haben, können Sie es veröffentlichen und in SharePoint verwenden. Um das Modell zu veröffentlichen, wählen Sie Veröffentlichen aus. Ausführliche Schritte finden Sie unter Trainieren und Veröffentlichen Ihres Dokumentverarbeitungsmodells.
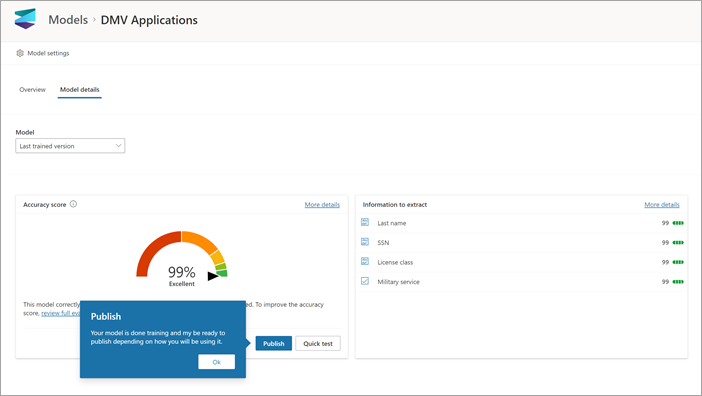
Nachdem das Modell veröffentlicht wurde, wechseln Sie zur Startseite des Modells. Anschließend haben Sie die Möglichkeit, das Modell auf eine Dokumentbibliothek anzuwenden.
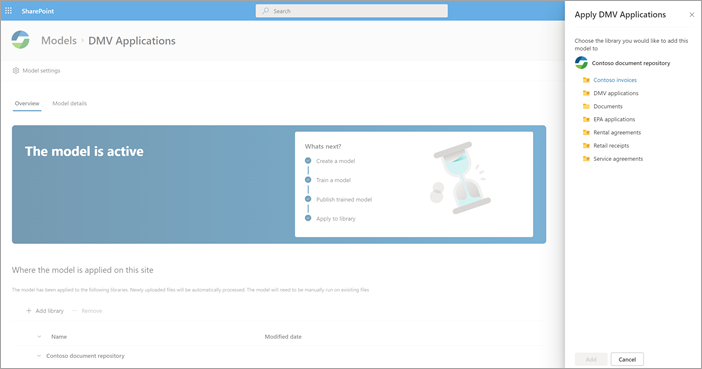
Schritt 4: Verwenden Ihres Modells
In der Dokumentbibliotheksmodellansicht werden die von Ihnen ausgewählten Felder nun als Spalten angezeigt.
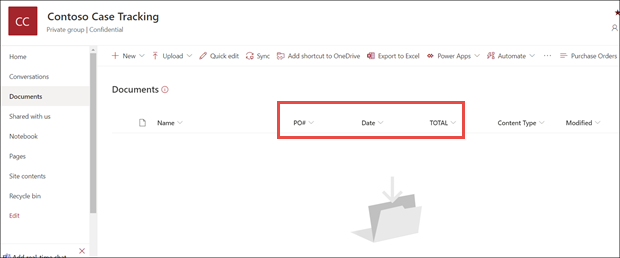
Der Infolink neben Dokumente informiert darüber, dass auf diese Dokumentbibliothek ein Formularverarbeitungsmodell angewendet wird.
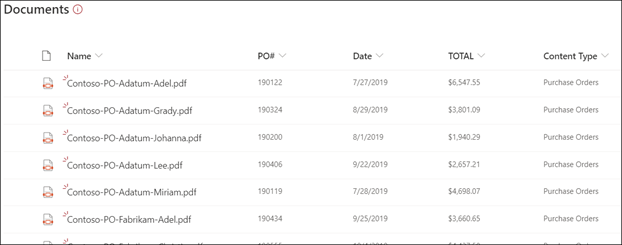
Laden Sie Dateien in Ihre Dokumentbibliothek hoch. Alle Dateien, die das Modell als Inhaltstyp identifiziert, listen die Dateien in Der Ansicht auf und zeigen die extrahierten Daten in den Spalten an.
Hinweis
Wenn ein strukturiertes oder freihandform-Dokumentverarbeitungsmodell und ein unstrukturiertes Dokumentverarbeitungsmodell auf dieselbe Bibliothek angewendet werden, wird die Datei mithilfe des unstrukturierten Dokumentverarbeitungsmodells und aller trainierten Extraktoren für dieses Modell klassifiziert. Wenn leere Spalten vorhanden sind, die mit dem Dokumentverarbeitungsmodell übereinstimmen, werden die Spalten mit diesen extrahierten Werten aufgefüllt.
Festlegen eines Seitenbereichs für die Verarbeitung
Bei diesem Modell können Sie angeben, dass anstelle der gesamten Datei ein Seitenbereich für eine Datei verarbeitet werden soll. Dies geschieht unter Modelleinstellungen in der Einstellung Seitenbereich . Standardmäßig ist die Einstellung Seitenbereich leer. Wenn kein Seitenbereich angegeben wird, wird das gesamte Dokument verarbeitet. Weitere Informationen finden Sie unter Festlegen eines Seitenbereichs zum Extrahieren von Informationen aus bestimmten Seiten.
Feld "Klassifizierungsdatum"
Wenn ein benutzerdefiniertes Modell auf eine Dokumentbibliothek angewendet wird, ist das Feld Klassifizierungsdatum im Bibliotheksschema enthalten. Standardmäßig ist dieses Feld leer. Wenn Dokumente jedoch von einem Modell verarbeitet und klassifiziert werden, wird dieses Feld mit einem Datums-/Uhrzeitstempel für den Abschluss aktualisiert.
Wenn ein Modell mit dem Klassifizierungsdatum gestempelt wird, können Sie den Flow E-Mail senden nach der Verarbeitung eines Dateivorgangs verwenden, um Benutzer zu benachrichtigen, dass eine neue Datei von einem Modell in der SharePoint-Dokumentbibliothek verarbeitet und klassifiziert wurde.
So führen Sie den Flow aus:
Wählen Sie eine Datei und dann Integrieren von>Power Automate>Flow erstellen aus.
Wählen Sie im Bereich Flow erstellen die Option E-Mail senden aus, nachdem Syntex eine Datei verarbeitet hat.
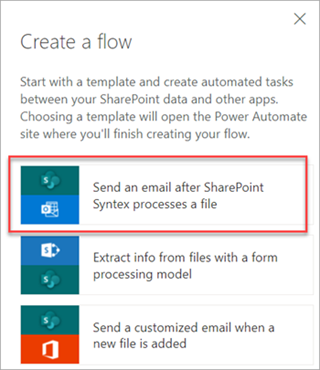
Verwenden von Flows zum Extrahieren von Informationen
Wichtig
Die Informationen in diesem Abschnitt gelten nicht für die neueste Version von Dokumentverarbeitungsmodellen. Sie bleibt nur für die Formularverarbeitungsmodelle, die in früheren Versionen erstellt wurden, als Referenz erhalten. In der neuesten Version müssen Sie die Flows nicht mehr konfigurieren, um vorhandene Dateien zu verarbeiten.
Zwei Flows sind verfügbar, um eine ausgewählte Datei oder einen Batch von Dateien in einer Bibliothek zu verarbeiten, in der ein strukturiertes oder freihandform-Dokumentverarbeitungsmodell angewendet wurde.
Extrahieren von Informationen aus einem Bild oder einer PDF-Datei mit einem Dokumentverarbeitungsmodell – Verwenden Sie , um Text aus einem ausgewählten Bild oder einer PDF-Datei zu extrahieren, indem Sie ein Dokumentverarbeitungsmodell ausführen. Unterstützt jeweils eine einzelne ausgewählte Datei und nur PDF-Dateien und Bilddateien (.png, .jpg und .jpeg). Wählen Sie zum Ausführen des Flows eine Datei und dann Informationen extrahieren aus>.
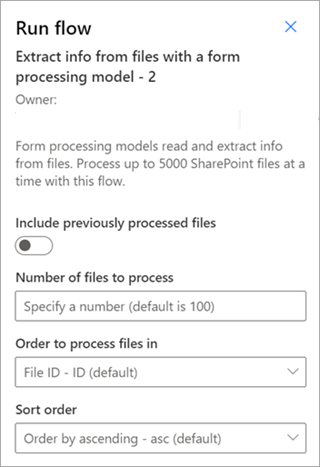
Extrahieren von Informationen aus Dateien mit einem Dokumentverarbeitungsmodell – Verwenden Sie mit Dokumentverarbeitungsmodellen, um Informationen aus einem Batch von Dateien zu lesen und zu extrahieren. Verarbeitet bis zu 5.000 SharePoint-Dateien gleichzeitig. Wenn Sie diesen Flow ausführen, gibt es bestimmte Parameter, die Sie festlegen können. Sie haben folgende Möglichkeiten:
- Wählen Sie aus, ob zuvor verarbeitete Dateien eingeschlossen werden sollen (standardmäßig werden zuvor verarbeitete Dateien nicht eingeschlossen).
- Wählen Sie die Anzahl der zu verarbeitenden Dateien aus (der Standardwert ist 100 Dateien).
- Geben Sie die Reihenfolge an, in der die Dateien verarbeitet werden sollen (Auswahlmöglichkeiten sind die Datei-ID, der Dateiname, der Zeitpunkt der Erstellung der Datei oder der Zeitpunkt der letzten Änderung).
- Geben Sie an, wie die Reihenfolge sortiert werden soll (aufsteigend oder absteigend).
Hinweis
Der Flow Extrahieren von Informationen aus einer Bild- oder PDF-Datei mit einem Dokumentverarbeitungsmodell ist automatisch für eine Bibliothek mit zugeordnetem Dokumentverarbeitungsmodell verfügbar. Der Flow Informationen aus Dateien mit einem Dokumentverarbeitungsmodell extrahieren ist eine Vorlage, die bei Bedarf der Bibliothek hinzugefügt werden muss.