Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Je nach Datenquelle können Informationen zu Datentypen und Spaltennamen explizit bereitgestellt werden oder auch nicht. OData-REST-APIs behandeln dies in der Regel mithilfe der $metadata Definition, und die Power Query-Methode OData.Feed verarbeitet automatisch die Analyse dieser Informationen und das Anwenden auf die von einer OData-Quelle zurückgegebenen Daten.
Viele REST-APIs haben keine Möglichkeit, ihr Schema programmgesteuert zu bestimmen. In diesen Fällen müssen Sie eine Schemadefinition in Ihren Connector einschließen.
Einfacher hartcodierter Ansatz
Der einfachste Ansatz besteht darin, eine Schemadefinition in Ihren Connector zu hartcodieren. Dies reicht für die meisten Anwendungsfälle aus.
Insgesamt hat das Erzwingen eines Schemas für die von Ihrem Connector zurückgegebenen Daten mehrere Vorteile, z. B.:
- Festlegen der richtigen Datentypen.
- Entfernen von Spalten, die endbenutzern nicht angezeigt werden müssen (z. B. interne IDs oder Statusinformationen).
- Stellen Sie sicher, dass jede Datenseite dasselbe Shape hat, indem Sie spalten hinzufügen, die möglicherweise in einer Antwort fehlen (REST-APIs geben häufig an, dass Felder null sein sollten, indem sie vollständig weggelassen werden).
Anzeigen des vorhandenen Schemas mit Table.Schema
Betrachten Sie den folgenden Code, der eine einfache Tabelle aus dem TripPin OData-Beispieldienst zurückgibt:
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
asTable
Hinweis
TripPin ist eine OData-Quelle, daher wäre es realistischer, einfach die automatische Schemabehandlung der OData.Feed Funktion zu verwenden. In diesem Beispiel behandeln Sie die Quelle als typische REST-API und verwenden Web.Contents , um die Technik der Hartcodierung eines Schemas manuell zu veranschaulichen.
Diese Tabelle ist das Ergebnis:
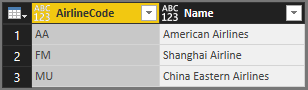
Sie können die praktische Table.Schema Funktion verwenden, um den Datentyp der Spalten zu überprüfen:
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
Table.Schema(asTable)

Sowohl AirlineCode als auch Name sind vom any Typ.
Table.Schema gibt viele Metadaten zu den Spalten in einer Tabelle zurück, einschließlich Namen, Positionen, Typinformationen und vielen erweiterten Eigenschaften wie Precision, Scale und MaxLength. Vorerst sollten Sie sich nur mit dem beschriftten Typ (TypeName), dem Grundtyp (Kind) und der Angabe befassen, ob der Spaltenwert null (IsNullable) sein kann.
Definieren einer einfachen Schematabelle
Ihre Schematabelle besteht aus zwei Spalten:
| Kolumne | Einzelheiten |
|---|---|
| Name | Der Name der Spalte. Dies muss mit dem Namen in den Ergebnissen übereinstimmen, die vom Dienst zurückgegeben werden. |
| Typ | Der Datentyp M, den Sie festlegen möchten. Hierbei kann es sich um einen Grundtyp (Text, Zahl, Datumsangaben usw.) oder um einen beschriftten Typ (Int64.Type, Currency.Type usw.) handeln. |
Die hartcodierte Schematabelle für die Airlines-Tabelle wird ihre AirlineCode- und Name-Spalten auf text setzen und sieht wie folgt aus:
Airlines = #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
})
Berücksichtigen Sie beim Blick auf einige der anderen Endpunkte die folgenden Schematabellen:
Die Airports Tabelle enthält vier Felder, die Sie beibehalten möchten (einschließlich eines typs record):
Airports = #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
})
Die People Tabelle enthält sieben Felder, einschließlich lists (Emails, AddressInfo), eine nullfähige Spalte (Gender) und eine Spalte mit einem beschriftten Typ (Concurrency):
People = #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})
Sie können alle diese Tabellen in eine einzelne Masterschematabelle SchemaTableeinfügen:
SchemaTable = #table({"Entity", "SchemaTable"}, {
{"Airlines", Airlines},
{"Airports", Airports},
{"People", People}
})
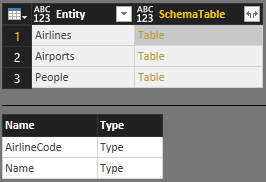
Die Hilfsfunktion "SchemaTransformTable"
Die SchemaTransformTable unten beschriebene Hilfsfunktion wird verwendet, um Schemas für Ihre Daten zu erzwingen. Es verwendet die folgenden Parameter:
| Parameter | Typ | Description |
|---|---|---|
| Tisch | Tisch | Die Tabelle der Daten, für die Sie Ihr Schema erzwingen möchten. |
| schema | Tisch | Die Schematabelle zum Lesen von Spalteninformationen mit dem folgenden Typ: type table [Name = text, Type = type] |
| enforceSchema | number | (optional) Eine Enumeration, die das Verhalten der Funktion steuert. Der Standardwert ( EnforceSchema.Strict = 1) stellt sicher, dass die Ausgabetabelle der bereitgestellten Schematabelle entspricht, indem fehlende Spalten hinzugefügt und überflüssige Spalten entfernt werden. Die EnforceSchema.IgnoreExtraColumns = 2 Option kann verwendet werden, um zusätzliche Spalten im Ergebnis beizubehalten. Wenn EnforceSchema.IgnoreMissingColumns = 3 sie verwendet wird, werden sowohl fehlende Spalten als auch zusätzliche Spalten ignoriert. |
Die Logik für diese Funktion sieht ungefähr wie folgt aus:
- Ermitteln Sie, ob in der Quelltabelle fehlende Spalten vorhanden sind.
- Ermitteln Sie, ob zusätzliche Spalten vorhanden sind.
- Ignorieren Sie strukturierte Spalten (vom Typ
list,recordundtable) und Spalten, die auf den Typanyfestgelegt sind. - Verwenden Sie
Table.TransformColumnTypes, um jeden Spaltentyp festzulegen. - Ordnen Sie Spalten basierend auf der Reihenfolge neu an, in der sie in der Schematabelle angezeigt werden.
- Legen Sie den Typ mithilfe von
Value.ReplaceTypefür die Tabelle selbst fest.
Hinweis
Der letzte Schritt zum Festlegen des Tabellentyps entfernt die Notwendigkeit, dass die Power Query-Benutzeroberfläche Typinformationen ableiten muss, wenn die Ergebnisse im Abfrage-Editor angezeigt werden, was manchmal zu einem doppelten Aufruf der API führen kann.
Alles zusammensetzen
Im größeren Kontext einer vollständigen Erweiterung erfolgt die Schemabehandlung, wenn eine Tabelle von der API zurückgegeben wird. In der Regel erfolgt diese Funktionalität auf der niedrigsten Ebene der Pagingfunktion (sofern vorhanden), wobei Entitätsinformationen aus einer Navigationstabelle übergeben werden.
Da der Großteil der Implementierung von Paging- und Navigationstabellen kontextspezifisch ist, wird hier nicht das vollständige Beispiel für die Implementierung eines hartcodierten Schemabehandlungsmechanismus gezeigt. In diesem TripPin-Beispiel wird veranschaulicht, wie eine End-to-End-Lösung aussehen kann.
Anspruchsvoller Ansatz
Die oben beschriebene hartcodierte Implementierung eignet sich gut dafür, sicherzustellen, dass Schemas für einfache JSON-Antworten konsistent bleiben, aber es ist auf die Analyse der ersten Ebene der Antwort beschränkt. Tief geschachtelte Datasets würden von dem folgenden Ansatz profitieren, der die Vorteile von M-Typen nutzt.
Hier ist eine schnelle Aktualisierung der Typen in der Sprache M aus der Sprachspezifikation:
Ein Typwert ist ein Wert, der andere Werte klassifiziert. Ein Wert, der durch einen Typ klassifiziert wird, wird als konform mit diesem Typ bezeichnet. Das M-Typsystem besteht aus den folgenden Arten von Typen:
- Primitive Typen, die primitive Werte klassifizieren (
binary,date, ,datetime,datetimezone,durationlist,logicalnull,number, ,record,texttimetype) und enthalten auch eine Reihe abstrakter Typen (function,table,anyund ).none- Datensatztypen, die Datensatzwerte basierend auf Feldnamen und Werttypen klassifizieren.
- Listentypen, die Listen mithilfe eines einzelnen Elementbasistyps klassifizieren.
- Funktionstypen, die Funktionswerte basierend auf den Typen ihrer Parameter klassifizieren und Werte zurückgeben.
- Tabellentypen, die Tabellenwerte basierend auf Spaltennamen, Spaltentypen und Schlüsseln klassifizieren.
- Nullable-Typen, die den Wert null zusätzlich zu allen Werten klassifizieren, die durch einen Basistyp klassifiziert wurden.
- Typtypen, die Werte klassifizieren, die Typen sind.
Mithilfe der von Ihnen abgerufenen rohen JSON-Ausgabe (und/oder durch Nachschlagen der Definitionen im $metadata des Diensts) können Sie die folgenden Datensatztypen definieren, um komplexe OData-Typen darzustellen:
LocationType = type [
Address = text,
City = CityType,
Loc = LocType
];
CityType = type [
CountryRegion = text,
Name = text,
Region = text
];
LocType = type [
#"type" = text,
coordinates = {number},
crs = CrsType
];
CrsType = type [
#"type" = text,
properties = record
];
Beachten Sie, wie LocationType auf die CityType und LocType verwiesen wird, um die strukturierten Spalten darzustellen.
Für die Entitäten auf oberster Ebene, die Als Tabellen dargestellt werden sollen, können Sie Tabellentypen definieren:
AirlinesType = type table [
AirlineCode = text,
Name = text
];
AirportsType = type table [
Name = text,
IataCode = text,
Location = LocationType
];
PeopleType = type table [
UserName = text,
FirstName = text,
LastName = text,
Emails = {text},
AddressInfo = {nullable LocationType},
Gender = nullable text,
Concurrency Int64.Type
];
Anschließend können Sie Die SchemaTable Variable (die Sie als Nachschlagetabelle für Entitäts-zu-Typ-Zuordnungen verwenden können) aktualisieren, um diese neuen Typdefinitionen zu verwenden:
SchemaTable = #table({"Entity", "Type"}, {
{"Airlines", AirlinesType},
{"Airports", AirportsType},
{"People", PeopleType}
});
Sie können sich auf eine allgemeine Funktion (Table.ChangeType) verlassen, um ein Schema für Ihre Daten zu erzwingen, ähnlich wie sie in der früheren Übung verwendet wurde SchemaTransformTable . Im Gegensatz zu SchemaTransformTable verwendet Table.ChangeType einen tatsächlichen M-Tabellentyp als Argument und wendet das Schema für alle geschachtelten Typen rekursiv an. Die Signatur lautet:
Table.ChangeType = (table, tableType as type) as nullable table => ...
Hinweis
Zur Flexibilität kann die Funktion sowohl für Tabellen als auch für Listen von Datensätzen verwendet werden (in denen Tabellen in einem JSON-Dokument dargestellt werden).
Anschließend müssen Sie den Connectorcode aktualisieren, um den schema Parameter von table zu type zu ändern und einen Aufruf hinzuzufügen Table.ChangeType. Auch hier sind die Details zur Umsetzung sehr spezialisiert und daher nicht wert, hier im Detail besprochen zu werden.
Dieses erweiterte TripPin-Connectorbeispiel veranschaulicht eine End-to-End-Lösung, die diesen komplexeren Ansatz zur Behandlung von Schemas implementiert.