Arbeiten mit Microsoft Fabric-Lakehouses
Nachdem Sie sich mit den wichtigsten Funktionen eines Microsoft Fabric-Lakehouse vertraut gemacht haben, erfahren Sie, wie Sie damit arbeiten können.
Erstellen und Erkunden eines Lakehouse
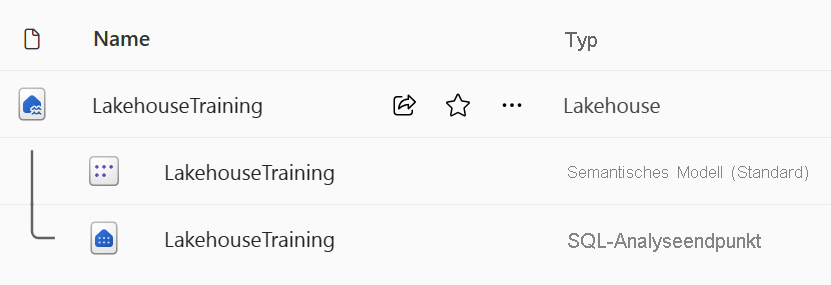
Sie erstellen und konfigurieren ein neues Lakehouse in der Datentechnik-Workload. Jedes Lakehouse erzeugt drei benannte Elemente im für Fabric aktivierten Arbeitsbereich:
- Lakehouse bezeichnet den Lakehouse-Speicher und die Metadaten, in denen Sie mit Dateien, Ordnern und Tabellendaten interagieren.
- Ein semantisches Modell (Standard) ist ein automatisch erstelltes Datenmodell, das auf den Tabellen im Lakehouse basiert. Aus dem Semantikmodell können Power BI-Berichte erstellt werden.
- Der SQL-Analyseendpunkt ist ein schreibgeschützter SQL-Analyse-Endpunkt, über den Sie eine Verbindung herstellen und Daten mit Transact-SQL abfragen können.
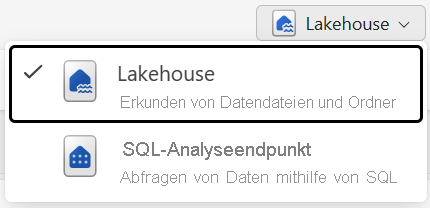
Sie können mit den Daten im Lakehouse in zwei Modi arbeiten:
- Mit Lakehouse können Sie Tabellen, Dateien und Ordner im Lakehouse hinzufügen und mit diesen interagieren.
- Mit dem SQL-Analyseendpunkt können Sie SQL verwenden, um die Tabellen im Lakehouse abzufragen und sein relationales semantisches Modell zu verwalten.
Erfassen von Daten in einem Lakehouse
Es gibt viele Möglichkeiten, Daten in ein Fabric-Lakehouse zu laden, einschließlich:
Hochladen: Laden Sie lokale Dateien oder Ordner in das Lakehouse hoch. Anschließend können Sie die Dateidaten untersuchen und verarbeiten und die Ergebnisse in Tabellen laden.
Dataflows (Gen2): Importieren und transformieren Sie Daten aus mehreren Quellen mithilfe von Power Query Online, und laden Sie sie direkt in eine Tabelle im Lakehouse.
Notebooks: Verwenden Sie Notebooks in Fabric, um Daten zu erfassen und zu transformieren und in Tabellen oder Dateien im Lakehouse zu laden.
Data Factory-Pipelines: Kopieren Sie Daten, orchestrieren Sie Datenverarbeitungsaktivitäten, und laden Sie die Ergebnisse in Tabellen oder Dateien im Lakehouse.
Datenzugriff über Verknüpfungen
Eine weitere Möglichkeit, auf Daten in Fabric zuzugreifen und diese zu verwenden, ist die Verwendung von Verknüpfungen. Mit Verknüpfungen können Sie Daten mit Ihr Lakehouse integrieren, während sie im externen Speicher gespeichert bleiben.
Verknüpfungen sind nützlich, wenn Sie Daten aus einem anderen Speicherkonto oder sogar von einem anderen Cloudanbieter beziehen müssen. In Ihrem Lakehouse können Sie Verknüpfungen erstellen, die auf verschiedene Speicherkonten und andere Fabric-Elemente wie Data Warehouses, KQL-Datenbanken und andere Lakehouses verweisen.
Quelldatenberechtigungen und Anmeldeinformationen werden alle von OneLake verwaltet. Beim Zugriff auf Daten über eine Verknüpfung mit einem anderen OneLake-Standort wird die Identität des aufrufenden Benutzers verwendet, um den Zugriff auf die Daten im Zielpfad der Verknüpfung zu autorisieren. Benutzer*innen müssen über Berechtigungen am Zielspeicherort verfügen, um die Daten lesen zu können.
Verknüpfungen können sowohl in Lakehouses als auch in KQL-Datenbanken erstellt werden und als Ordner im Lake angezeigt werden. Auf diese Weise können Spark, SQL, Echtzeitintelligenz und Analysis Services alle Verknüpfungen beim Abfragen von Daten nutzen.
Hinweis
Weitere Informationen zur Verwendung von Verknüpfungen finden Sie in der Dokumentation zu OneLake-Verknüpfungen in der Microsoft Fabric-Dokumentation.