Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Hinweis
Dieser Artikel bezieht sich in erster Linie auf Benutzeroberflächen, die in Windows 10 (Version 1909 und früher) bereitgestellt werden. Weitere Informationen finden Sie unter Ende des Supports für Cortana.
Cortana, die Windows-Sprachplattform, unterstützt alle Sprachfunktionen in Windows 10, z. B. Cortana und Diktat. Die Sprachaktivierung ist ein Feature, mit dem Benutzer ein Spracherkennungsmodul aus verschiedenen Gerätestromzuständen aufrufen können, indem sie einen bestimmten Ausdruck sagen: "Hey Cortana". Wenn Sie Hardware erstellen möchten, die Die Sprachaktivierungstechnologie unterstützt, lesen Sie die Informationen in diesem Artikel.
Hinweis
Die Implementierung der VoIP-Aktivierung ist ein wichtiges Projekt und eine Aufgabe, die von SoC-Anbietern abgeschlossen wird. OEMs können sich an ihren SoC-Anbieter wenden, um Informationen zur Implementierung der Sprachaktivierung zu erhalten.
Cortana-Endbenutzererfahrung
Lesen Sie diese Artikel, um die in Windows verfügbare Sprachinteraktion zu verstehen.
| Artikel | Description |
|---|---|
| Was ist Cortana? | Bietet Übersicht und Verwendungsrichtung für Cortana |
Einführung in die Sprachaktivierung "Hey Cortana" und "Meine Stimme lernen"
Hey Cortana" Sprachaktivierung
Mit der Funktion "Hey Cortana" Voice Activation (VA) können Benutzer die Cortana-Erfahrung außerhalb ihres aktiven Kontexts (d. h. was derzeit auf dem Bildschirm ist) schnell mit ihrer Stimme nutzen. Benutzer möchten häufig sofort auf eine Oberfläche zugreifen können, ohne physisch interagieren oder ein Gerät berühren zu müssen. Telefonbenutzer fahren möglicherweise im Auto und sind mit der Bedienung des Fahrzeugs beschäftigt. Ein Xbox-Benutzer möchte möglicherweise keinen Controller suchen und verbinden. PC-Benutzer möchten möglicherweise schnell auf eine Oberfläche zugreifen, ohne mehrere Maus-, Touch- oder Tastaturaktionen ausführen zu müssen. Zum Beispiel ein Computer in der Küche, der beim Kochen verwendet wird.
Die Sprachaktivierung bietet immer Spracheingaben über vordefinierte Schlüsselsätze oder Aktivierungssätze. Schlüsselausdrücke können für sich allein stehend verwendet werden ("Hey Cortana") als eigenständiger Befehl oder gefolgt von einer Sprachaktion, z. B. "Hey Cortana, wo ist meine nächste Besprechung?", ein verketteter Befehl.
Der Begriff Schlüsselworterkennung beschreibt die Erkennung des Schlüsselworts entweder durch Hardware oder Software.
Nur Schlüsselwort-Aktivierung tritt ein, wenn nur das Cortana-Schlüsselwort gesagt wird. Cortana startet und spielt den EarCon-Sound ab, um anzuzeigen, dass es in den Hörmodus gewechselt ist.
Ein verketteter Befehl beschreibt die Möglichkeit, sofort nach dem Schlüsselwort einen Befehl wie "Hey Cortana, rufe John an" auszustellen, wodurch Cortana gestartet wird (falls noch nicht gestartet) und dem Befehl folgt, indem sie einen Telefonanruf mit John startet.
In diesem Diagramm werden nur die Verkettung und die Schlüsselwortaktivierung veranschaulicht.
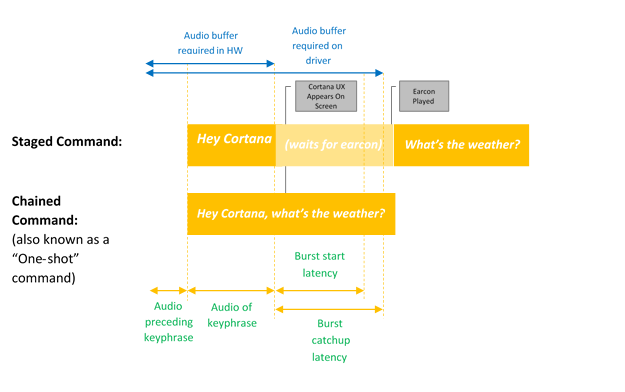
Microsoft stellt einen Standard-Schlüsselwort-Spotter (Software-Schlüsselwort-Detektor) bereit, der verwendet wird, um die Qualität der Hardwareschlüsselwort-Erkennung sicherzustellen und die Hey-Cortana-Erfahrung bereitzustellen, wenn die Hardwareschlüsselwort-Erkennung fehlt oder nicht verfügbar ist.
Die Funktion "Meine Stimme lernen"
Mit der Funktion "Meine Stimme lernen" kann der Benutzer Cortana trainieren, um seine eindeutige Stimme zu erkennen. Dazu wählt der Benutzer " Erfahren Sie, wie ich "Hey Cortana" im Cortana-Einstellungsbildschirm sage. Der Benutzer wiederholt dann sechs sorgfältig ausgewählte Ausdrücke, die eine ausreichende Vielfalt an phonetischen Mustern bereitstellen, um die eindeutigen Attribute der Stimme des Benutzers zu identifizieren.
Wenn die Sprachaktivierung mit "Meine Stimme lernen" gekoppelt ist, arbeiten die beiden Algorithmen zusammen, um falsche Aktivierungen zu reduzieren. Dies ist besonders nützlich für das Besprechungsraumszenario, in dem eine Person "Hey Cortana" in einem Raum mit allen Geräten sagt. Dieses Feature ist nur für Windows 10, Version 1903 und früher verfügbar.
Die Sprachaktivierung wird durch einen Schlüsselwort-Spotter (KWS) unterstützt, der reagiert, wenn der Schlüsselbegriff erkannt wird. Wenn der KWS das Gerät aus einem stromsparendem Zustand reaktivieren soll, wird dies als Wake on Voice (WoV) bezeichnet. Weitere Informationen finden Sie unter Wake on Voice.
Glossar der Begriffe
In diesem Glossar werden Begriffe im Zusammenhang mit der Sprachaktivierung zusammengefasst.
| Begriff | Beispiel/Definition |
|---|---|
| Mehrstufiger Befehl | Beispiel: Hey Cortana <pause, warten Sie auf EarCon-Sound> Was ist das Wetter? Dies wird manchmal als "Two-shot-Befehl" oder "Nur-Stichwort" bezeichnet. |
| Kettenbefehl | Beispiel: Hey Cortana was ist das Wetter? Dies wird manchmal als "Einschussbefehl" bezeichnet. |
| Sprachaktivierung | Das Szenario der Bereitstellung der Schlüsselworterkennung eines vordefinierten Aktivierungsschlüsselausdrucks. Beispielsweise ist "Hey Cortana" das Microsoft Voice Activation-Szenario. |
| WoV | Wake-on-Voice – Technologie, die es ermöglicht, ein Gerät von einem ausgeschalteten Bildschirm im niedrigen Energiezustand durch Sprachaktivierung in den eingeschalteten Vollbetriebszustand zu versetzen. |
| WoV aus Modern Standby | Wake-on-Voice von einem Modernen Standby-Bildschirm (S0ix) in einen Bildschirm im Vollbetriebszustand (S0). |
| Moderner Standbymodus | Windows Low Power Idle-Infrastruktur – Nachfolger von Connected Standby (CS) in Windows 10. Der erste Status des modernen Standbymodus ist, wenn der Bildschirm deaktiviert ist. Der tiefste Schlafzustand wird bei DRIPS/Resilienz erreicht. Weitere Informationen finden Sie unter Modern Standby |
| KWS | Stichwort-Spotter – der Algorithmus, der die Erkennung von "Hey Cortana" bereitstellt |
| SW KWS | Software-Schlüsselwort-Spotter – eine Implementierung von KWS, die auf dem Host (CPU) ausgeführt wird. Für "Hey Cortana" ist SW KWS im Rahmen von Windows enthalten. |
| HW KWS | Hardware-offloaded Keyword Spotter – eine Implementierung von KWS, die auf Hardware ausgelagert ausgeführt wird. |
| Burst Buffer | Ein Kreispuffer, der zum Speichern von PCM-Daten verwendet wird, die bei einer KWS-Erkennung "aufbrechen" können, sodass alle Audiodaten, die eine KWS-Erkennung ausgelöst haben, enthalten sind. |
| Schlüsselwortdetektor-OEM-Adapter | Ein Shim auf Treiberebene, mit dem die WoV-fähige Hardware mit Windows und dem Cortana-Stack kommunizieren kann. |
| Model | Die vom KWS-Algorithmus verwendete Akustikmodelldatendatei. Die Datendatei ist statisch. Modelle werden lokalisiert, eine pro Standort. |
Integrieren eines Hardware-Schlüsselwort-Spotters
Führen Sie die folgenden Aufgaben aus, um einen Hardwareschlüsselwort-Spotter (HW KWS) zu implementieren.
- Erstellen Sie einen benutzerdefinierten Schlüsselwortdetektor basierend auf dem sysVAD-Beispiel, das weiter unten in diesem Artikel beschrieben wird. Sie implementieren diese Methoden in einer COM-DLL, die unter Keyword Detector OEM Adapter Interface beschrieben wird.
- Implementieren Sie WAVE RT-Verbesserungen, die in DEN WAVERT-Verbesserungen beschrieben sind.
- Stellen Sie INF-Dateieinträge bereit, um benutzerdefinierte APOs zu beschreiben, die für die Schlüsselworterkennung verwendet werden.
- PKEY_FX_KeywordDetector_StreamEffectClsid
- PKEY_FX_KeywordDetector_ModeEffectClsid
- PKEY_FX_KeywordDetector_EndpointEffectClsid
- PKEY_SFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_MFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_EFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- Überprüfen Sie die Hardwareempfehlungen und Testanleitungen in der Empfehlung für Audiogeräte. Dieser Artikel enthält Anleitungen und Empfehlungen für das Design und die Entwicklung von Audioeingabegeräten, die für die Verwendung mit der Sprachplattform von Microsoft vorgesehen sind.
- Es werden sowohl mehrstufige als auch verkettete Befehle unterstützt.
- Unterstützen Sie "Hey Cortana" für jede der unterstützten Cortana-Sprachversionen.
- Die APOs (Audio Processing Objects) müssen die folgenden Effekte bereitstellen:
- AEC
- AGC
- NS
- Effekte für den Sprachverarbeitungsmodus müssen vom MFX-APO gemeldet werden.
- Das APO kann die Formatkonvertierung als MFX durchführen.
- Das APO muss das folgende Format ausgeben:
- 16 kHz, Mono, FLOAT.
- Entwerfen Sie optional alle benutzerdefinierten APOs, um den Audioaufnahmeprozess zu verbessern. Weitere Informationen finden Sie unter Windows Audio Processing Objects.
Hardware-offloaded keyword spotter (HW KWS) WoV-Anforderungen
- HW KWS WoV wird während des S0-Betriebszustands und des S0-Ruhezustands unterstützt, der auch als Modern Standby bezeichnet wird.
- HW KWS WoV wird von S3 nicht unterstützt.
AEC-Anforderungen für HW KWS
Für Windows Version 1709
- Zur Unterstützung von HW KWS WoV für den S0-Schlafzustand (Modern Standby) ist AEC nicht erforderlich.
- HW KWS WoV im S0-Betriebszustand wird in Windows Version 1709 nicht unterstützt.
Für Windows Version 1803
- HW KWS WoV für den S0-Betriebszustand wird unterstützt.
- Um HW KWS WoV für den Arbeitszustand S0 zu aktivieren, muss die APO AEC unterstützen.
Beispielcodeübersicht
Es gibt Beispielcode für einen Audiotreiber, der die Sprachaktivierung auf GitHub als Teil des virtuellen SYSVAD-Audioadapterbeispiels implementiert. Es wird empfohlen, diesen Code als Ausgangspunkt zu verwenden. Der Code ist an diesem Speicherort verfügbar.
https://github.com/Microsoft/Windows-driver-samples/tree/main/audio/sysvad/
Weitere Informationen zum SYSVAD-Beispielaudiotreiber finden Sie unter Beispielaudiotreiber.
Informationen zum Schlüsselworterkennungssystem
Unterstützung für Audiostack bei der Sprachaktivierung
Die externen Schnittstellen des Audio-Stacks zur Aktivierung der Sprachaktivierung dienen als Kommunikationspipeline für die Sprachplattform und die Audiotreiber. Die externen Schnittstellen sind in drei Teile unterteilt.
- Schlüsselwortdetektor Device Driver Interface (DDI) Die Schlüsselwortdetektorgerätetreiberschnittstelle ist für die Konfiguration und Armierung des HW Keyword Spotter (KWS) verantwortlich. Es wird auch vom Treiber verwendet, um das System über ein Erkennungsereignis zu benachrichtigen.
- Schlüsselwortdetektor OEM Adapter DLL. Diese DLL implementiert eine COM-Schnittstelle, um die treiberspezifischen undurchsichtigen Daten zur Verwendung durch das Betriebssystem anzupassen, um die Schlüsselworterkennung zu unterstützen.
- WaveRT-Streamingverbesserungen. Mit den Verbesserungen kann der Audiotreiber die gepufferten Audiodaten aus der Schlüsselworterkennung im Burst-Verfahren streamen.
Audioendpunkteigenschaften
Das Erstellen von Audioendpunktdiagrammen erfolgt normal. Das Diagramm ist darauf vorbereitet, schneller als die Echtzeiterfassung zu verarbeiten. Zeitstempel der erfassten Puffer bleiben korrekt. Insbesondere spiegeln die Zeitstempel daten, die in der Vergangenheit erfasst und gepuffert wurden, korrekt wider und sind nun aufgebrochen.
Theorie der Bluetooth-Umgehung von Audiostreaming
Der Treiber macht einen KS-Filter für sein Aufnahmegerät wie gewohnt verfügbar. Dieser Filter unterstützt mehrere KS-Eigenschaften und ein KS-Ereignis zum Konfigurieren, Aktivieren und Signalisieren eines Erkennungsereignisses. Der Filter enthält auch eine weitere Pin-Factory, die als Schlüsselwort-Erkenner (KWS)-Pin identifiziert wird. Dieser Pin wird verwendet, um Audio aus dem Schlüsselwort-Spotter zu streamen.
Die Eigenschaften sind:
- Unterstützte Schlüsselworttypen – KSPROPERTY_SOUNDDETECTOR_PATTERNS. Das Betriebssystem legt diese Eigenschaft fest, um die zu erkennenden Schlüsselwörter zu konfigurieren.
- Liste der Schlüsselwortmuster-GUIDs – KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. Diese Eigenschaft wird verwendet, um eine Liste von GUIDs abzurufen, die die Typen unterstützter Muster identifizieren.
- Bewaffnet - KSPROPERTY_SOUNDDETECTOR_ARMED. Diese Lese-/Schreibeigenschaft ist ein boolescher Status, der angibt, ob der Detektor bewaffnet ist. Das Betriebssystem legt dies so fest, dass der Schlüsselwortdetektor verwendet wird. Das Betriebssystem kann dies löschen, um dies zu deaktivieren. Der Treiber löscht dies automatisch, wenn Schlüsselwortmuster festgelegt werden, und auch nach der Erkennung eines Schlüsselworts. (Das Betriebssystem muss neu gestartet werden.)
- Übereinstimmungsergebnis - KSPROPERTY_SOUNDDETECTOR_MATCHRESULT. Diese Leseeigenschaft enthält die Ergebnisdaten, nachdem die Erkennung aufgetreten ist.
Das Ereignis, das ausgelöst wird, wenn ein Schlüsselwort erkannt wird, ist ein KSEVENT_SOUNDDETECTOR_MATCHDETECTED Ereignis.
Abfolge des Vorgangs
Systemstart
- Das Betriebssystem liest die unterstützten Schlüsselworttypen vor, um sicherzustellen, dass es Schlüsselwörter in diesem Format enthält.
- Das Betriebssystem registriert sich für das Detektorstatusänderungsereignis.
- Das Betriebssystem legt die Schlüsselwortmuster fest.
- Das Betriebssystem aktiviert den Detektor.
Beim Empfangen des KS-Ereignisses
- Der Fahrer entwaffnet den Detektor.
- Das Betriebssystem liest den Schlüsselwortdetektorstatus, analysiert die zurückgegebenen Daten und bestimmt, welches Muster erkannt wurde.
- Das Betriebssystem setzt den Detektor zurück.
Interner Treiber- und Hardwarebetrieb
Während der Detektor bewaffnet ist, kann die Hardware kontinuierlich Audiodaten in einem kleinen FIFO-Puffer erfassen und puffern. (Die Größe dieses FIFO-Puffers wird durch Anforderungen außerhalb dieses Dokuments bestimmt, kann jedoch in der Regel Hunderte von Millisekunden bis mehrere Sekunden betragen.) Der Erkennungsalgorithmus arbeitet mit dem Datenstreaming über diesen Puffer. Der Entwurf von Treiber und Hardware ist so, dass im aktivierten Zustand keine Interaktion zwischen Treiber und Hardware stattfindet und keine Interrupts für die Anwendungsprozessoren ausgeführt werden, bis ein Schlüsselwort erkannt wird. Dadurch kann das System einen niedrigeren Leistungszustand erreichen, wenn keine andere Aktivität vorhanden ist.
Wenn die Hardware ein Schlüsselwort erkennt, wird ein Interrupt generiert. Während sie warten, bis der Treiber den Interrupt bedient, erfasst die Hardware weiterhin Audio im Puffer, wobei sichergestellt wird, dass keine Daten nach dem Verlust des Schlüsselworts innerhalb von Puffergrenzwerten verloren gehen.
Schlüsselwort-Zeitstempel
Nach dem Erkennen eines Schlüsselworts müssen alle Sprachaktivierungslösungen alle gesprochenen Schlüsselworte puffern, einschließlich 250 ms vor dem Start des Schlüsselworts. Der Audiotreiber muss Zeitstempel bereitstellen, die den Anfang und das Ende des Schlüsselausdrucks im Datenstrom identifizieren.
Um die Schlüsselwort-Start-/Endzeitstempel zu unterstützen, muss die DSP-Software möglicherweise Ereignisse intern mit einem Zeitstempel versehen, basierend auf einer DSP-Uhr. Sobald ein Schlüsselwort erkannt wurde, interagiert die DSP-Software mit dem Treiber, um ein KS-Ereignis vorzubereiten. Der Treiber und die DSP-Software müssen den DSP-Zeitstempel einem Windows-Leistungsindikatorwert zuordnen. Die Methode hierfür ist spezifisch für das Hardwaredesign. Eine mögliche Lösung ist, dass der Treiber den aktuellen Leistungsindikator liest, den aktuellen DSP-Zeitstempel abfragt, den aktuellen Leistungsindikator erneut liest und dann eine Korrelation zwischen Leistungsindikator und DSP-Zeit schätzt. Nachdem die Korrelation gegeben ist, kann der Treiber die zu einem Schlüsselwort gehörigen DSP-Zeitstempel den Zeitstempeln des Windows-Leistungsindikators zuordnen.
Schlüsselwortdetektor-OEM-Adapterschnittstelle
Der OEM stellt eine COM-Objektimplementierung bereit, die als Vermittler zwischen dem Betriebssystem und dem Treiber fungiert und dabei hilft, die undurchsichtigen Daten zu berechnen oder zu analysieren, die über KSPROPERTY_SOUNDDETECTOR_PATTERNS und KSPROPERTY_SOUNDDETECTOR_MATCHRESULT in den Audiotreiber geschrieben und gelesen werden.
Die CLSID des COM-Objekts ist eine Detektormustertyp-GUID, die vom KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS zurückgegeben wird. Das Betriebssystem ruft CoCreateInstance auf, indem die Mustertyp-GUID übergeben wird, um das entsprechende COM-Objekt zu instanziieren, das mit dem Schlüsselwortmustertyp kompatibel ist, und ruft Methoden auf der IKeywordDetectorOemAdapter-Schnittstelle des Objekts auf.
COM-Threading-Modellanforderungen
Die Implementierung des OEM kann eines der COM-Threading-Modelle auswählen.
IKeywordDetectorOemAdapter
Der Schnittstellenentwurf versucht, die Objektimplementierung zustandslos zu halten. Mit anderen Worten, die Implementierung sollte keinen Zustand zwischen Methodenaufrufen speichern. In der Tat benötigen interne C++-Klassen wahrscheinlich keine Membervariablen, die über diejenigen hinausgehen, die zum Implementieren eines COM-Objekts im Allgemeinen erforderlich sind.
Methodik
Implementieren Sie die folgenden Methoden.
- IKeywordDetectorOemAdapter::BuildArmingPatternData
- IKeywordDetectorOemAdapter::ComputeAndAddUserModelData
- IKeywordDetectorOemAdapter::GetCapabilities
- IKeywordDetectorOemAdapter::ParseDetectionResultData
- IKeywordDetectorOemAdapter::VerifyUserKeyword
KEYWORDID
Die KEYWORDID-Aufzählung identifiziert den Ausdruckstext/die Funktion eines Schlüsselworts und wird auch in den Windows-Biometrischen Dienstadaptern verwendet. Weitere Informationen finden Sie in der Übersicht über biometrisches Framework – Kernplattformkomponenten
typedef enum {
KwInvalid = 0,
KwHeyCortana = 1,
KwSelect = 2
} KEYWORDID;
KEYWORDSELECTOR
Die KEYWORDSELECTOR-Struktur ist eine Reihe von IDs, die ein bestimmtes Schlüsselwort und eine bestimmte Sprache eindeutig auswählen.
typedef struct
{
KEYWORDID KeywordId;
LANGID LangId;
} KEYWORDSELECTOR;
Behandeln von Modelldaten
Statisches, benutzerunabhängiges Modell – Die OEM-DLL enthält in der Regel einige statische, benutzerunabhängige Modelldaten, die entweder in die DLL integriert sind, oder in einer separaten Datendatei, die in der DLL enthalten ist. Die von der GetCapabilities-Routine zurückgegebenen unterstützten Schlüsselwortkennungen hängen von diesen Daten ab. Wenn beispielsweise die Liste der unterstützten Schlüsselwort-IDs, die von GetCapabilities zurückgegeben werden, KwHeyCortana enthält, enthalten die statischen, benutzerunabhängigen Modelldaten Daten für "Hey Cortana" (oder die Übersetzung) für alle unterstützten Sprachen.
Dynamisches benutzerabhängiges Modell – IStream bietet ein Speichermodell für zufälligen Zugriff. Das Betriebssystem übergibt einen IStream-Schnittstellenzeiger an viele der Methoden auf der IKeywordDetectorOemAdapter-Schnittstelle. Das Betriebssystem sichert die IStream-Implementierung mit entsprechendem Speicher für bis zu 1 MB Daten.
Der Inhalt und die Struktur der Daten innerhalb dieses Speichers wird vom OEM definiert. Der beabsichtigte Zweck ist die dauerhafte Speicherung von benutzerabhängigen Modelldaten, die von der OEM-DLL berechnet oder abgerufen werden.
Das Betriebssystem kann die Schnittstellenmethoden mit einem leeren IStream aufrufen, insbesondere, wenn der Benutzer nie ein Schlüsselwort trainiert hat. Das Betriebssystem erstellt einen separaten IStream-Speicher für jeden Benutzer. Mit anderen Worten, ein bestimmter IStream speichert Modelldaten für einen und nur einen Benutzer.
Der OEM DLL-Entwickler entscheidet, wie die benutzerunabhängigen und benutzerabhängigen Daten verwaltet werden. Benutzerdaten dürfen jedoch niemals außerhalb des IStream gespeichert werden. Ein möglicher OEM DLL-Entwurf würde intern zwischen dem Zugriff auf den IStream und den statischen benutzerunabhängigen Daten wechseln, abhängig von den Parametern der aktuellen Methode. Ein alternatives Design überprüft möglicherweise den IStream am Anfang jedes Methodenaufrufs und fügt die statischen benutzerunabhängigen Daten zum IStream hinzu, falls noch nicht vorhanden, sodass die restliche Methode nur auf den IStream für alle Modelldaten zugreifen kann.
Schulungs- und Betriebsaudioverarbeitung
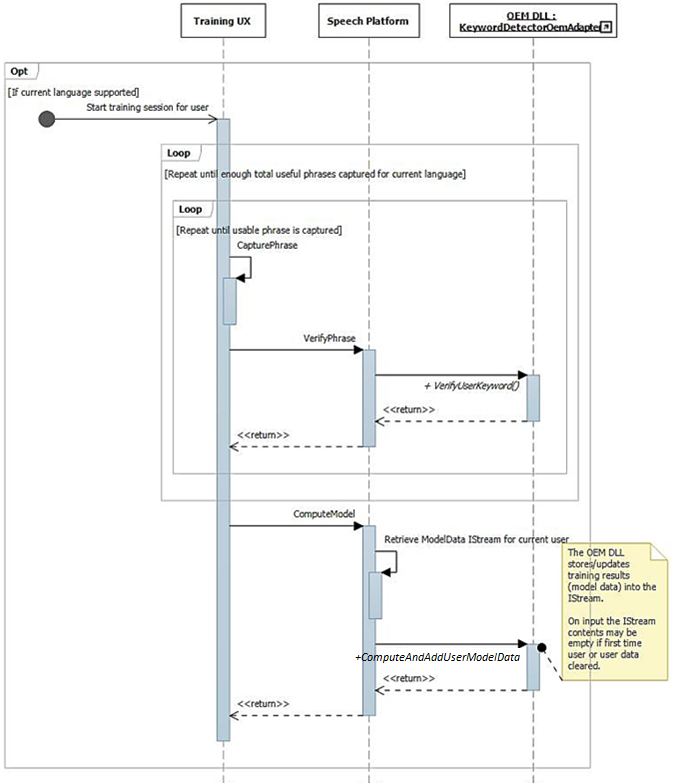
Wie bereits beschrieben, führt der Schulungs-UI-Fluss zu vollständig phonetisch reichhaltigen Sätzen, die im Audiodatenstrom verfügbar sind. Jeder Satz wird einzeln an IKeywordDetectorOemAdapter::VerifyUserKeyword übergeben, um sicherzustellen, dass er das erwartete Schlüsselwort enthält und über eine akzeptable Qualität verfügt. Nachdem alle Sätze von der Benutzeroberfläche gesammelt und überprüft wurden, werden sie alle in einem Aufruf von IKeywordDetectorOemAdapter::ComputeAndAddUserModelData übergeben.
Audio wird auf einzigartige Weise für Sprachaktivierungsschulungen verarbeitet. In der folgenden Tabelle sind die Unterschiede zwischen der Sprachaktivierungsschulung und der regulären Spracherkennungsverwendung zusammengefasst.
| Sprachschulung | Spracherkennung | |
|---|---|---|
| Modus | Roh | Rohesignal oder Sprache |
| Pin | Normal | KWS |
| Audioformat | 32-Bit-Float (Typ = Audio, Untertyp = IEEE_FLOAT, Samplingrate = 16 kHz, Bits = 32) | Vom Betriebssystem-Audiostapel verwaltet |
| Mikrofon | Mikrofon 0 | Alle Mikrofone in Array oder Mono |
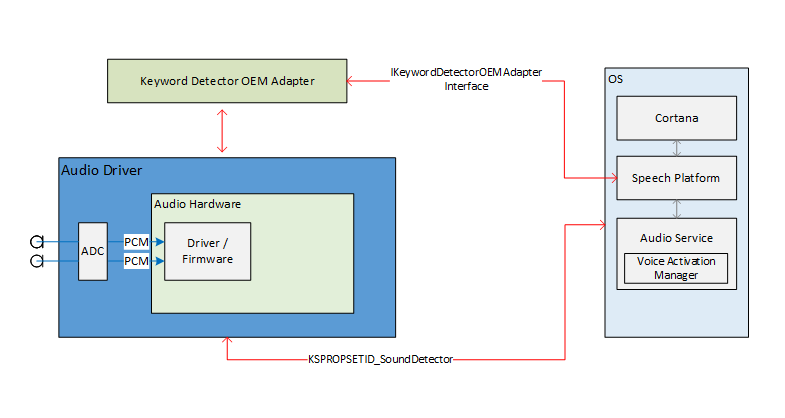
Übersicht über das Schlüsselworterkennungssystem
Dieses Diagramm bietet eine Übersicht über das Schlüsselworterkennungssystem.
Schlüsselworterkennungssequenzdiagramme
In diesen Diagrammen wird das Sprachlaufzeitmodul als Sprachplattform angezeigt. Wie bereits erwähnt, wird die Windows-Sprachplattform verwendet, um alle Sprachfunktionen in Windows 10 wie Cortana und Diktieren zu unterstützen.
Während des Starts werden Funktionen mithilfe von IKeywordDetectorOemAdapter::GetCapabilities gesammelt.
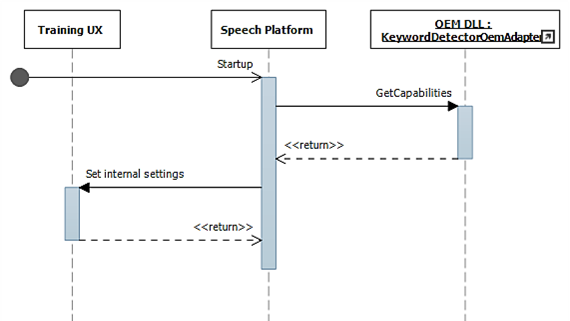
Wenn der Benutzer später "Meine Stimme lernen" auswählt, wird der Schulungsfluss aufgerufen.
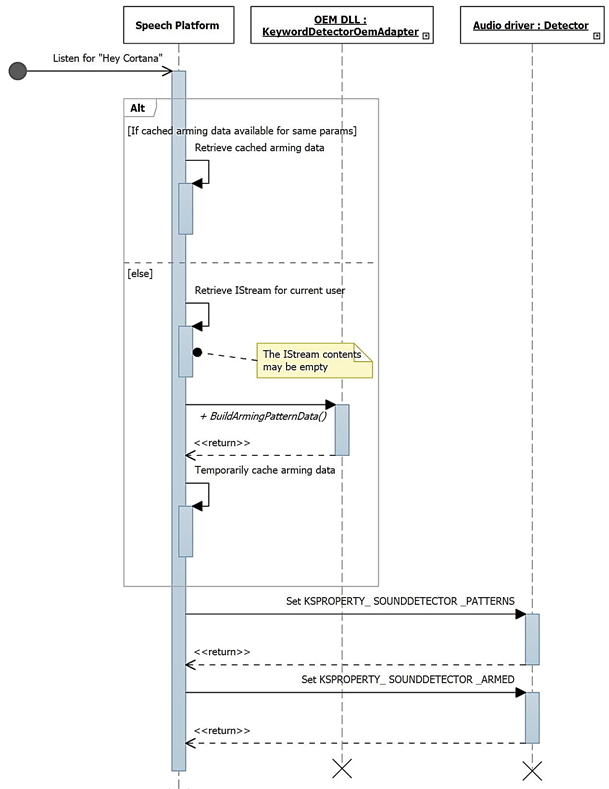
In diesem Diagramm wird der Prozess der Aktivierung zur Schlüsselworterkennung beschrieben.
WAVERT-Verbesserungen
Miniport-Schnittstellen werden definiert, die von WaveRT-Miniporttreibern implementiert werden sollen. Diese Schnittstellen bieten Methoden, um den Audiotreiber zu vereinfachen, die Leistung und Zuverlässigkeit der Betriebssystem-Audiopipeline zu verbessern oder neue Szenarien zu unterstützen. Eine neue PnP-Geräteschnittstelleneigenschaft wird definiert, sodass der Treiber einen statischen Ausdruck seiner Puffergrößeneinschränkungen für das Betriebssystem bereitstellt.
Puffergrößen
Ein Treiber arbeitet unter verschiedenen Einschränkungen beim Verschieben von Audiodaten zwischen dem Betriebssystem, dem Treiber und der Hardware. Diese Einschränkungen können auf den physischen Hardwaretransport zurückzuführen sein, der Daten zwischen Speicher und Hardware verschiebt, und/oder aufgrund der Signalverarbeitungsmodule innerhalb der Hardware oder zugeordneten DSP.
HW-KWS Lösungen müssen Audioaufnahmegrößen von mindestens 100 ms und bis zu 200 ms unterstützen.
Der Treiber gibt die Einschränkungen für die Puffergröße an, indem er die Geräteeigenschaft DEVPKEY_KsAudio_PacketSize_Constraints auf der KSCATEGORY_AUDIO PnP-Geräteschnittstelle des KS-Filters mit den KS-Streaming-Pins festlegt. Diese Eigenschaft sollte gültig und stabil bleiben, während die KS-Filterschnittstelle aktiviert ist. Das Betriebssystem kann diesen Wert jederzeit lesen, ohne einen Handle für den Treiber öffnen und den Treiber aufrufen zu müssen.
DEVPKEY_KsAudio_PacketSize_Constraints
Der wert der DEVPKEY_KsAudio_PacketSize_Constraints-Eigenschaft enthält eine KSAUDIO_PACKETSIZE_CONSTRAINTS Struktur, die die physischen Hardwareeinschränkungen beschreibt (d. a. aufgrund der Mechanik der Übertragung von Daten vom WaveRT-Puffer an die Audiohardware). Die Struktur enthält ein Array von 0 oder mehr KSAUDIO_PACKETSIZE_PROCESSINGMODE_CONSTRAINT Strukturen, die Einschränkungen beschreiben, die für beliebige Signalverarbeitungsmodi spezifisch sind. Der Treiber legt diese Eigenschaft fest, bevor PcRegisterSubdevice aufgerufen wird oder die KS-Filterschnittstelle für seine Streaming-Pins aktiviert wird.
IMiniportWaveRTInputStream
Ein Treiber implementiert diese Schnittstelle zur besseren Koordination des Audiodatenflusses vom Treiber zum Betriebssystem. Wenn diese Schnittstelle in einem Aufnahmedatenstrom verfügbar ist, verwendet das Betriebssystem Methoden auf dieser Schnittstelle, um auf Daten im WaveRT-Puffer zuzugreifen. Weitere Informationen finden Sie unter IMiniportWaveRTInputStream::GetReadPacket
IMiniportWaveRTOutputStream
Ein WaveRT-Miniport implementiert optional diese Schnittstelle, um über den Fortschritt des Schreibvorgangs vom Betriebssystem informiert zu werden und die präzise Stream-Position zurückzumelden. Weitere Informationen finden Sie unter "IMiniportWaveRTOutputStream::SetWritePacket", "IMiniportWaveRTOutputStream::GetOutputStreamPresentationPosition " und "IMiniportWaveRTOutputStream::GetPacketCount".
Leistungszähler-Zeitstempel
Einige der Treiberroutinen geben Zeitstempel des Windows-Leistungsindikators zurück, die den Zeitpunkt widerspiegeln, zu dem Beispiele erfasst oder vom Gerät dargestellt werden.
Bei Geräten mit komplexen DSP-Pipelines und Signalverarbeitung kann die Berechnung eines genauen Zeitstempels eine Herausforderung darstellen und sorgfältig durchgeführt werden. Die Zeitstempel sollten nicht die Uhrzeit widerspiegeln, zu der Beispiele an das Betriebssystem oder vom Betriebssystem an den DSP übertragen wurden.
- Verfolgen Sie innerhalb des DSP Probendaten-Zeitstempel mithilfe einer internen DSP-Uhr.
- Berechnen Sie zwischen treiber und DSP eine Korrelation zwischen dem Windows-Leistungsindikator und der DSP-Wanduhr. Verfahren hierfür können von einfachen (aber weniger präzisen) bis hin zu ziemlich komplexen oder neuartigen (aber präziseren) Reichen.
- Berücksichtigen Sie jede konstante Verzögerung aufgrund von Signalverarbeitungsalgorithmen oder Pipeline- oder Hardwaretransporten, es sei denn, diese Verzögerungen werden auf andere Weise berücksichtigt.
Burst-Lesevorgang
In diesem Abschnitt werden die Interaktionen zwischen Betriebssystem und Treiber bei Burst-Lesevorgängen beschrieben. Platzlesevorgänge können außerhalb des Sprachaktivierungsszenarios erfolgen, solange der Treiber das paketbasierte Streaming WaveRT-Modell unterstützt, einschließlich der IMiniportWaveRTInputStream::GetReadPacket-Funktion .
Es werden zwei Burst-Beispiel-Leseszenarien erörtert. In einem Szenario, falls der Miniport einen Pin mit der Pinkategorie KSNODETYPE_AUDIO_KEYWORDDETECTOR unterstützt, beginnt der Treiber, Daten zu erfassen und intern zu puffern, sobald ein Schlüsselwort erkannt wird. In einem anderen Szenario kann der Treiber Daten intern außerhalb des WaveRT-Puffers puffern, wenn das Betriebssystem daten nicht schnell genug liest, indem IMiniportWaveRTInputStream::GetReadPacket aufgerufen wird.
Um Daten freizugeben, die vor dem Übergang in den Zustand KSSTATE_RUN erfasst wurden, muss der Treiber genaue Sample-Zeitstempelinformationen zusammen mit den erfassten Daten aufbewahren. Die Zeitstempel identifizieren den Abtastzeitpunkt der erfassten Proben.
Nachdem der Datenstrom zu KSSTATE_RUN übergeht, legt der Treiber sofort das Pufferbenachrichtigungsereignis fest, da bereits Daten verfügbar sind.
Bei diesem Ereignis ruft das Betriebssystem GetReadPacket() auf, um Informationen zu den verfügbaren Daten abzurufen.
Der Treiber gibt die Paketnummer der gültigen erfassten Daten zurück (0 für das erste Paket nach dem Übergang von KSSTATE_STOP zu KSSTATE_RUN), von dem das Betriebssystem die Paketposition innerhalb des WaveRT-Puffers und die Paketposition relativ zum Start des Datenstroms ableiten kann.
Der Treiber gibt auch den Leistungszählerwert zurück, der dem Abtastzeitpunkt des ersten Abtastwerts im Paket entspricht. Dieser Leistungsindikatorwert kann relativ alt sein, je nachdem, wie viel Erfassungsdaten innerhalb der Hardware oder des Treibers (außerhalb des WaveRT-Puffers) gepuffert wurden.
Wenn noch mehr ungelesene gepufferte Daten verfügbar sind, kann der Treiber entweder:
- Diese Daten werden sofort in den verfügbaren Bereich des WaveRT-Puffers übertragen (d. h. speicherplatz, der nicht vom Paket verwendet wird, das von GetReadPacket zurückgegeben wird), gibt "true" für MoreData zurück und legt das Pufferbenachrichtigungsereignis fest, bevor es von dieser Routine zurückgegeben wird. Oder
- Programmeert Hardware, um das nächste Paket in den verfügbaren Speicherplatz des WaveRT-Puffers zu übertragen, gibt "false" für MoreData zurück und setzt das Puffereignis, wenn der Transfer abgeschlossen ist.
Das Betriebssystem liest Daten aus dem WaveRT-Puffer mithilfe der von GetReadPacket() zurückgegebenen Informationen vor.
Das Betriebssystem wartet auf das nächste Pufferbenachrichtigungsereignis. Die Wartezeit wird möglicherweise sofort beendet, wenn der Treiber die Pufferbenachrichtigung in Schritt (2c) festgelegt hat.
Wenn der Treiber das Ereignis in Schritt (2c) nicht sofort festgelegt hat, legt der Treiber das Ereignis fest, nachdem es mehr erfasste Daten in den WaveRT-Puffer überträgt und es dem Betriebssystem zum Lesen zur Verfügung stellt.
Wechsel zu (2). Für KSNODETYPE_AUDIO_KEYWORDDETECTOR-Schlüsselwortdetektor-Pins sollten von Treibern genügend interner Burst-Puffer für mindestens 5000 ms Audiodaten zugeordnet werden. Wenn das Betriebssystem keinen Datenstrom auf dem Pin erstellt, bevor der Pufferüberlauf erfolgt, kann der Treiber die interne Pufferaktivität beenden und zugeordnete Ressourcen freigeben.
Sprachaktivierung
Wake On Voice (WoV) ermöglicht es dem Benutzer, eine Spracherkennungs-Engine aus einem niedrigen Energiemodus in einen vollen Leistungszustand zu versetzen und sie zu nutzen, indem der Benutzer ein bestimmtes Schlüsselwort wie "Hey Cortana" sagt.
Mit diesem Feature kann das Gerät immer auf die Stimme des Benutzers lauschen, während sich das Gerät in einem Energiesparmodus befindet, einschließlich des Zustands, wenn der Bildschirm ausgeschaltet ist und das Gerät im Leerlauf ist. Dies geschieht mithilfe eines Hörmodus, der im Vergleich zum höheren Stromverbrauch bei normaler Mikrofonaufnahme niedriger ist. Die Spracherkennung mit niedrigem Energieverbrauch ermöglicht es einem Benutzer, einen vordefinierten Schlüsselausdruck wie "Hey Cortana" zu sagen, gefolgt von einem weiteren Sprachbefehl wie "Wann ist mein nächster Termin," um freihändig Sprachbefehle zu initiieren. Dies funktioniert unabhängig davon, ob das Gerät in Gebrauch oder im Leerlauf ist, wenn der Bildschirm ausgeschaltet ist.
Der Audiostapel ist für die Kommunikation der Wake-Daten (Lautsprecher-ID, Schlüsselworttrigger, Konfidenzniveau) verantwortlich und benachrichtigt interessierte Clients, dass das Schlüsselwort erkannt wird.
Validierung auf modernen Standby-Systemen
WoV aus einem System-Leerlaufzustand kann auf Modern Standby-Systemen mit dem Modern Standby Wake on Voice Basic Test auf AC-Stromquelle und dem Modern Standby Wake on Voice Basic Test auf DC-Stromquelle im HLK überprüft werden. Diese Tests überprüfen, ob das System über einen Hardware-Schlüsselwort-Erkenner (HW-KWS) verfügt, in der Lage ist, in den Deepest Runtime Idle Platform State (DRIPS) zu wechseln und aus dem modernen Standby über einen Sprachbefehl mit einer Reaktivierungslatenz des Systems von weniger als oder gleich einer Sekunde zu erwachen.