Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Microsoft Foundry on Windows ist die führende Lösung für Entwickler, die lokale KI-Funktionen in ihre Windows Apps integrieren möchten.
Microsoft Foundry on Windows bietet Entwicklern...
- Einsatzbereite KI-Modelle und APIs über Windows AI APIs und Foundry Local
- KI-Ableitungsframework zum lokalen Ausführen eines Modells über Windows ML
Unabhängig davon, ob Sie neu in der KI sind oder ein erfahrener Machine Learning (ML)-Experte, hat Microsoft Foundry on Windows etwas für Sie.
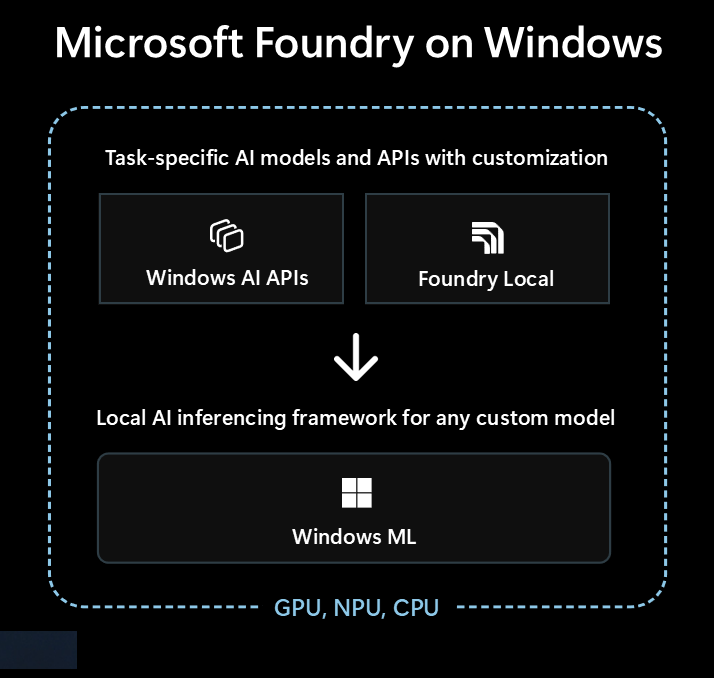
Einsatzbereite KI-Modelle und APIs
Ihre App kann die folgenden lokalen KI-Modelle und APIs in weniger als einer Stunde mühelos verwenden. Die Verteilung und Laufzeit der Modelldateien wird von Microsoft behandelt, und die Modelle werden für alle Apps freigegeben. Die Verwendung dieser Modelle und APIs erfordert nur eine Handvoll Codezeilen, 0 ML-Know-how erforderlich.
| Modelltyp oder API | Was ist es | Optionen und unterstützte Geräte |
|---|---|---|
| Große Sprachmodelle (LLMs) | Generative Textmodelle | Phi Silica via AI APIs (unterstützt Feinabstimmung) oder 20+ OSS LLM Modelle über Foundry Local Weitere Informationen finden Sie unter "Lokale LLMs ". |
| Bildbeschreibung | Abrufen einer Textbeschreibung in natürlicher Sprache eines Bilds | Bildbeschreibung mithilfe AI APIs (Copilot+ PCs) |
| Bild-Vordergrundextraktionsmodul | Segmentieren Sie den Vordergrund eines Bilds | Bildvordergrund-Extraktor durch AI APIs (Copilot+ PCs) |
| Bilderzeugung | Generieren von Bildern aus Text | Bilderzeugung über AI APIs (Copilot+ PCs) |
| Bildobjekt löschen | Löschen von Objekten aus Bildern | Image-Objekt löschen über AI APIs (Copilot+ PCs) |
| Bildobjektextraktion | Segmentierung spezifischer Objekte in einem Bild | Image-Objekt-Extraktor über AI APIs (Copilot+ PCs) |
| Superauflösung für Bilder | Erhöhen der Auflösung von Bildern | Bildsuperauflösung mit AI APIs (Copilot+ PCs) |
| Semantische Suche | Semantische Suche nach Text und Bildern | App-Inhaltssuche über AI APIs (Copilot+ PCs) |
| Spracherkennung | Konvertieren von Sprache in Text | Flüstern über Foundry Local oder Spracherkennung über Windows SDK Weitere Informationen finden Sie unter Spracherkennung . |
| Texterkennung (OCR) | Erkennen von Text aus Bildern | OCR über AI APIs (Copilot+ PCs) |
| Video Super Resolution (VSR) | Erhöhen der Auflösung von Videos | Video-Superauflösung über AI APIs (PCs mit Copilot+) |
Verwenden anderer Modelle mit Windows ML
Sie können eine Vielzahl von Modellen aus Hugging Face oder anderen Quellen verwenden oder sogar Eigene Modelle trainieren und diese lokal auf Windows 10 und späteren PCs mit Windows ML(Modellkompatibilität und -leistung basierend auf der Gerätehardware) ausführen.
Weitere Informationen finden Sie unter Finden oder Trainieren von Modellen zur Verwendung mit Windows ML.
Mit welcher Option beginnen soll
Befolgen Sie diese Entscheidungsstruktur, um den besten Ansatz für Ihre Anwendung und Ihr Szenario auszuwählen:
Überprüfen Sie, ob das integrierte Windows AI APIs Ihr Szenario abdeckt und ob Sie auf Copilot+ PCs abzielen. Dies ist der schnellste Weg zum Markt mit minimalem Entwicklungsaufwand.
Wenn Windows AI APIs nicht das haben, was Sie benötigen, oder Unterstützung für Windows 10 und höhere Versionen benötigt wird, sollten Sie Foundry Local für LLM- oder Spracherkennungsszenarien in Betracht ziehen.
Wenn Sie benutzerdefinierte Modelle benötigen, vorhandene Modelle von Hugging Face oder anderen Quellen nutzen möchten oder bestimmte Modellanforderungen haben, die nicht unter die oben genannten Optionen fallen, bietet Windows ML Ihnen die Flexibilität, Ihre eigenen Modelle zu finden oder zu trainieren (und unterstützt Windows 10 und höher).
Ihre App kann auch eine Kombination aller drei Technologien verwenden.
Verfügbare Technologien für lokale KI
Die folgenden Technologien sind in Microsoft Foundry on Windows verfügbar:
| Windows AI APIs | Foundry Local | Windows ML | |
|---|---|---|---|
| Was ist es | Einsatzbereite KI-Modelle und APIs für eine Vielzahl von Aufgabentypen, die für Copilot+ PCs optimiert sind | Einsatzbereite LLMs und Sprach-zu-Text-Modelle | ONNX Runtime Framework zum Ausführen von Modellen, die Sie finden oder trainieren |
| Unterstützte Geräte | Copilot+ PCs | Windows 10 und neuere PCs sowie plattformübergreifende Systeme (Die Leistung variiert je nach verfügbarer Hardware, nicht auf allen verfügbaren Modellen) |
Windows 10 und neuere PCs und plattformübergreifend über Open-Source-ONNX Runtime (Die Leistung variiert je nach verfügbarer Hardware) |
| Modelltypen und APIs verfügbar |
LLM Bildbeschreibung Bild-Vordergrundextraktionsmodul Bilderzeugung Bildobjekt löschen Bildobjektextraktion Superauflösung für Bilder Semantische Suche Texterkennung (OCR) Video-Superauflösung |
LLMs (mehrere) Sprach-zu-Text Durchsuchen von 20 verfügbaren Modellen |
Suchen oder Trainieren Eigener Modelle |
| Modellverteilung | Gehostet von Microsoft, während der Laufzeit erworben und zwischen Anwendungen freigegeben. | Gehostet von Microsoft, während der Laufzeit erworben und zwischen Anwendungen freigegeben. | Verteilung, die von Ihrer App verarbeitet wird (App-Bibliotheken können Modelle für alle Apps freigeben) |
| Weitere Informationen | Lesen der AI APIs Dokumente | Lesen der Foundry Local Dokumente | Lesen der Windows ML Dokumente |
Microsoft Foundry on Windows umfasst auch Entwicklertools wie Foundry Toolkit für Visual Studio Code und AI Dev Gallery die Ihnen helfen, KI-Funktionen erfolgreich zu erstellen.
Foundry Toolkit für Visual Studio Code ist eine VS-Codeerweiterung, mit der Sie KI-Modelle lokal herunterladen und ausführen können, einschließlich des Zugriffs auf hardwarebeschleunigung für eine bessere Leistung und Skalierung über DirectML. Das Foundry Toolkit kann Ihnen auch bei Folgendem helfen:
- Testen von Modellen in einem intuitiven Playground oder in Ihrer Anwendung mit einer REST-API.
- Optimieren Sie Ihr KI-Modell sowohl lokal als auch in der Cloud (auf einem virtuellen Computer), um neue Fähigkeiten zu erstellen, die Zuverlässigkeit der Antworten zu verbessern, den Ton und das Format der Antwort festzulegen.
- Feinabstimmung beliebter kleinsprachiger Modelle (SLMs), wie Phi-3 und Mistral.
- Stellen Sie Ihr KI-Feature entweder in der Cloud oder mit einer Anwendung bereit, die auf einem Gerät ausgeführt wird.
- Nutzen Sie Hardwarebeschleunigung, um die Leistung von KI-Funktionen mit DirectML zu verbessern. DirectML ist eine API mit niedriger Ebene, mit der Ihre Windows Gerätehardware die Leistung von ML-Modellen mithilfe der Geräte-GPU oder NPU beschleunigen kann. Das Koppeln von DirectML mit dem ONNX Runtime ist normalerweise die einfachste Vorgehensweise für Entwickler, hardwarebeschleunigte KI ihren Benutzern im großen Maßstab zur Verfügung zu stellen. Weitere Informationen: DirectML Overview.
- Quantisieren und Überprüfen eines Modells für die Verwendung auf NPU mithilfe der Modellkonvertierungsfunktionen
Ideen für die Nutzung lokaler KI
Einige Möglichkeiten, wie Windows Apps lokale KI nutzen können, um ihre Funktionalität und Benutzererfahrung zu verbessern:
- Apps können generative AI LLM-Modelle verwenden , um komplexe Themen zu verstehen, um komplexe Themen zusammenzufassen, neu zu schreiben, zu berichten oder zu erweitern.
- Apps können LLM-Modelle verwenden , um Freiforminhalte in ein strukturiertes Format zu transformieren, das Ihre App verstehen kann.
- Apps können Semantik-Suchmodelle verwenden , mit denen Benutzer nach Inhalten suchen können, indem sie bedeutungsbezogen und schnell verwandte Inhalte finden.
- Apps können Modelle zur Verarbeitung natürlicher Sprache verwenden, um über komplexe Anforderungen in natürlicher Sprache nachzudenken und Handlungen zu planen und auszuführen, um die Wünsche des Benutzers zu erfüllen.
- Apps können Bildbearbeitungsmodelle verwenden, um Bilder intelligent zu ändern, Bilder zu löschen oder Themen hinzuzufügen, hochskalieren oder neue Inhalte zu generieren.
- Apps können vorausschauende Diagnostikmodelle verwenden, um Probleme zu identifizieren und vorherzusagen und den Benutzer zu leiten oder die Aufgabe für ihn zu übernehmen.
Verwenden von Cloud AI-Modellen
Wenn die Verwendung lokaler KI-Features nicht der richtige Weg für Sie ist, können Cloud AI-Modelle und -Ressourcen eine Lösung sein.
Verwenden von verantwortungsvollen KI-Praktiken
Wann immer Sie KI-Features in Ihre Windows-App integrieren, highly empfehlen, die Anleitung Developing Responsible Generative AI Applications and Features on Windows zu befolgen.