Σημείωμα
Η πρόσβαση σε αυτήν τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να εισέλθετε ή να αλλάξετε καταλόγους.
Η πρόσβαση σε αυτήν τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να αλλάξετε καταλόγους.
Σε αυτή την εκμάθηση, θα μάθετε να εκπαιδεύετε πολλά μοντέλα εκμάθησης μηχανής για να επιλέγουν το καλύτερο, προκειμένου να προβλέψουν ποιοι πελάτες τραπεζών είναι πιθανό να αποχωρήσουν.
Σε αυτή την εκμάθηση, θα κάνετε τα εξής:
- Εκπαιδεύστε μοντέλα Random Forest και LightGBM.
- Χρησιμοποιήστε την εγγενή ενοποίηση του Microsoft Fabric με το πλαίσιο MLflow για να καταγράψετε τα εκπαιδευμένα μοντέλα εκμάθησης μηχανής, τα χρησιμοποιούμενα υπεραραμετρικά και τα μετρικά αξιολόγησης.
- Καταχωρήστε το εκπαιδευμένο μοντέλο εκμάθησης μηχανής.
- Αξιολογήστε τις επιδόσεις των εκπαιδευμένων μοντέλων εκμάθησης μηχανής στο σύνολο δεδομένων επικύρωσης.
Το MLflow είναι μια πλατφόρμα ανοιχτού κώδικα για τη διαχείριση του κύκλου ζωής της εκμάθησης μηχανής με δυνατότητες όπως η παρακολούθηση, τα μοντέλα και το μητρώο μοντέλων. Το MLflow είναι εγγενώς ενσωματωμένο στην εμπειρία Επιστήμη δεδομένων Fabric.
Προαπαιτούμενα στοιχεία
Λάβετε μια συνδρομή Microsoft Fabric. Εναλλακτικά, εγγραφείτε για μια δωρεάν δοκιμαστική έκδοση του Microsoft Fabric.
Εισέλθετε στο Microsoft Fabric.
Μεταβείτε στο Fabric χρησιμοποιώντας την εναλλαγή εμπειριών στην κάτω αριστερή πλευρά της αρχικής σελίδας σας.
Αυτό είναι το μέρος 3 από το 5 στη σειρά εκμάθησης. Για να ολοκληρώσετε αυτή την εκμάθηση, ολοκληρώστε πρώτα τα εξής:
- Μέρος 1: Πρόσληψη δεδομένων σε μια λίμνη Microsoft Fabric χρησιμοποιώντας Apache Spark.
- Μέρος 2: Εξερεύνηση και απεικόνιση δεδομένων με χρήση σημειωματάριων Microsoft Fabric για να μάθετε περισσότερα σχετικά με τα δεδομένα.
Παρακολούθηση στο σημειωματάριο
Το 3-train-evaluate.ipynb είναι το σημειωματάριο που συνοδεύει αυτό το πρόγραμμα εκμάθησης.
Για να ανοίξετε το σημειωματάριο που συνοδεύει αυτό το εκπαιδευτικό βοήθημα, ακολουθήστε τις οδηγίες στο Προετοιμασία του συστήματός σας για εκπαιδευτικά βοηθήματα επιστήμης δεδομένων, να εισαγάγετε το σημειωματάριο στον χώρο εργασίας σας.
Εάν προτιμάτε να αντιγράψετε και να επικολλήσετε τον κώδικα από αυτή τη σελίδα, μπορείτε να δημιουργήσετε ένα νέο σημειωματάριο.
Φροντίστε να επισυνάψετε ένα lakehouse στο σημειωματάριο προτού ξεκινήσετε την εκτέλεση κώδικα.
Σημαντικό
Επισυνάψτε το ίδιο lakehouse που χρησιμοποιήσατε στο μέρος 1 και στο μέρος 2.
Εγκατάσταση προσαρμοσμένων βιβλιοθηκών
Για αυτό το σημειωματάριο, θα εγκαταστήσετε το μη ισορροπημένες-πληροφορίες (που εισάγονται ως imblearn) χρησιμοποιώντας το %pip install. Η μη ισορροπημένη εκμάθηση είναι μια βιβλιοθήκη για την Συνθετική Τεχνική Υπερκατανάλωσης Μειονότητας (SMOTE), η οποία χρησιμοποιείται κατά την αντιμετώπιση μη ισορροπημένων συνόλων δεδομένων. Θα γίνει επανεκκίνηση του πυρήνα PySpark μετά %pip installτο , επομένως θα χρειαστεί να εγκαταστήσετε τη βιβλιοθήκη προτού εκτελέσετε οποιαδήποτε άλλα κελιά.
Θα έχετε πρόσβαση στο SMOTE μέσω της βιβλιοθήκης imblearn . Εγκαταστήστε την τώρα χρησιμοποιώντας τις δυνατότητες εγκατάστασης εντός γραμμής (π.χ., %pip, %conda).
# Install imblearn for SMOTE using pip
%pip install imblearn
%pip install scikit-learn==1.6.1
%pip install "mlflow==2.12.2"
Σημαντικό
Εκτελέστε αυτήν την εγκατάσταση κάθε φορά που επανεκκινείτε το σημειωματάριο.
Όταν εγκαθιστάτε μια βιβλιοθήκη σε ένα σημειωματάριο, είναι διαθέσιμη μόνο κατά τη διάρκεια της περιόδου λειτουργίας του σημειωματάριου και όχι στον χώρο εργασίας. Εάν κάνετε επανεκκίνηση του σημειωματάριου, θα χρειαστεί να εγκαταστήσετε ξανά τη βιβλιοθήκη.
Εάν έχετε μια βιβλιοθήκη που χρησιμοποιείτε συχνά και θέλετε να την καταστήσετε διαθέσιμη σε όλα τα σημειωματάρια στον χώρο εργασίας σας, μπορείτε να χρησιμοποιήσετε ένα περιβάλλον Fabric για αυτόν το σκοπό. Μπορείτε να δημιουργήσετε ένα περιβάλλον, να εγκαταστήσετε τη βιβλιοθήκη σε αυτό και, στη συνέχεια, ο διαχειριστής του χώρου εργασίας σας μπορεί να συνδέσει το περιβάλλον στον χώρο εργασίας ως το προεπιλεγμένο περιβάλλον του. Για περισσότερες πληροφορίες σχετικά με τον ορισμό ενός περιβάλλοντος ως προεπιλεγμένου χώρου εργασίας, ανατρέξτε στο θέμα Σύνολα διαχειριστών προεπιλεγμένων βιβλιοθηκών για τον χώρο εργασίας.
Για πληροφορίες σχετικά με τη μετεγκατάσταση υπαρχουσών βιβλιοθηκών χώρου εργασίας και ιδιοτήτων Spark σε ένα περιβάλλον, ανατρέξτε στο θέμα Μετεγκατάσταση βιβλιοθηκών χώρου εργασίας και ιδιοτήτων Spark σε ένα προεπιλεγμένο περιβάλλον.
Φόρτωση των δεδομένων
Πριν από την εκπαίδευση οποιουδήποτε μοντέλου εκμάθησης μηχανής, πρέπει να φορτώσετε τον πίνακα δέλτα από τη λίμνη για να διαβάσετε τα καθαρισμένους δεδομένα που δημιουργήσατε στο προηγούμενο σημειωματάριο.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Δημιουργία πειράματος για την παρακολούθηση και καταγραφή του μοντέλου με χρήση MLflow
Αυτή η ενότητα παρουσιάζει πώς μπορείτε να δημιουργήσετε ένα πείραμα, να καθορίσετε το μοντέλο εκμάθησης μηχανής και τις παραμέτρους εκπαίδευσης, καθώς και να βαθμολογήσετε μετρικά, να εκπαιδεύσετε τα μοντέλα εκμάθησης μηχανής, να τα καταγράψετε και να αποθηκεύσετε τα εκπαιδευμένα μοντέλα για μελλοντική χρήση.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment-SBM" # MLflow experiment name
Επεκτείνοντας τις δυνατότητες αυτόματης καταγραφής ροής MLflow, η αυτόματη καταγραφή λειτουργεί καταγράφοντας αυτόματα τις τιμές των παραμέτρων εισόδου και των μετρικών εξόδου ενός μοντέλου εκμάθησης μηχανής, καθώς εκπαιδεύεται. Στη συνέχεια, αυτές οι πληροφορίες καταγράφονται στον χώρο εργασίας σας, όπου είναι δυνατή η πρόσβαση και η απεικόνισή τους χρησιμοποιώντας τα API MLflow ή το αντίστοιχο πείραμα στον χώρο εργασίας σας.
Καταγράφονται όλα τα πειράματα με τα αντίστοιχα ονόματά τους και θα μπορείτε να παρακολουθείτε τις παραμέτρους και τα μετρικά απόδοσης. Για να μάθετε περισσότερα σχετικά με την αυτόματη καταχώρηση, ανατρέξτε στο θέμα Αυτόματη καταχώρηση στο Microsoft Fabric.
Ορισμός προδιαγραφών πειραμάτων και αυτόματης καταχώρησης σε αρχεία
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Εισαγωγή scikit-learn και LightGBM
Έχοντας τα δεδομένα σας έτοιμα, μπορείτε τώρα να ορίσετε τα μοντέλα εκμάθησης μηχανής. Θα εφαρμόσετε μοντέλα Random Forest και LightGBM σε αυτό το σημειωματάριο. Χρησιμοποιήστε scikit-learn και lightgbm να υλοποιήσετε τα μοντέλα μέσα σε λίγες γραμμές κώδικα.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Προετοιμασία συνόλων δεδομένων εκπαίδευσης, επικύρωσης και δοκιμής
Χρησιμοποιήστε τη συνάρτηση από train_test_split το scikit-learn για να διαιρέσετε τα δεδομένα σε εκπαιδευτικά σύνολα, επικύρωση και σύνολα δοκιμών.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Αποθήκευση δεδομένων δοκιμής σε έναν πίνακα δέλτα
Αποθηκεύστε τα δεδομένα δοκιμής στον πίνακα δέλτα για χρήση στο επόμενο σημειωματάριο.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Εφαρμόστε το SMOTE στα δεδομένα εκπαίδευσης για να συνθέσετε νέα δείγματα για την κλάση μειονότητας
Η εξερεύνηση δεδομένων στο μέρος 2 έδειξε ότι από τα 10.000 σημεία δεδομένων που αντιστοιχούν σε 10.000 πελάτες, μόνο 2.037 πελάτες (περίπου 20%) έχουν αποχωρήσει από την τράπεζα. Αυτό υποδεικνύει ότι το σύνολο δεδομένων είναι εξαιρετικά μη ισορροπημένες. Το πρόβλημα με την μη ισορροπημένη ταξινόμηση είναι ότι υπάρχουν πολύ λίγα παραδείγματα της μειονοτικής κλάσης για να μάθει ένα μοντέλο αποτελεσματικά τα όρια της απόφασης. Η SMOTE είναι η πλέον ευρέως χρησιμοποιούμενη προσέγγιση για τη σύνθεση νέων δειγμάτων της μειονοτικής τάξης. Μάθετε περισσότερα για την SMOTE εδώ και εδώ.
Φιλοδώρημα
Σημειώστε ότι ο SMOTE θα πρέπει να εφαρμόζεται μόνο στο σύνολο δεδομένων εκπαίδευσης. Πρέπει να αφήσετε το σύνολο δεδομένων δοκιμής στην αρχική μη ισορροπημένη κατανομή του προκειμένου να λάβετε μια έγκυρη προσέγγιση του τρόπου εκτέλεσης του μοντέλου εκμάθησης μηχανής στα αρχικά δεδομένα, το οποίο αντιπροσωπεύει την κατάσταση στην παραγωγή.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Φιλοδώρημα
Μπορείτε να αγνοήσετε με ασφάλεια το προειδοποιητικό μήνυμα MLflow που εμφανίζεται όταν εκτελείτε αυτό το κελί.
Εάν δείτε ένα μήνυμα ModuleNotFoundError , δεν εκτελέσατε το πρώτο κελί σε αυτό το σημειωματάριο, το οποίο εγκαθιστά τη imblearn βιβλιοθήκη. Πρέπει να εγκαταστήσετε αυτή τη βιβλιοθήκη κάθε φορά που επανεκκινείτε το σημειωματάριο. Επιστρέψτε και εκτελέστε ξανά όλα τα κελιά, ξεκινώντας με το πρώτο κελί σε αυτό το σημειωματάριο.
Εκπαίδευση μοντέλου
- Εκπαίδευση του μοντέλου με χρήση της δυνατότητας Random Forest με μέγιστο βάθος 4 και 4 δυνατότητες
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Εκπαίδευση του μοντέλου με χρήση της δυνατότητας Random Forest με μέγιστο βάθος 8 και 6 δυνατότητες
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- Εκπαίδευση του μοντέλου με χρήση lightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Πειραματίζεται τεχνουργήματα για την παρακολούθηση των επιδόσεων του μοντέλου
Οι εκτελέσεις του πειράματος αποθηκεύονται αυτόματα στο αντικείμενο σχεδίασης πειράματος που μπορείτε να βρείτε από τον χώρο εργασίας. Ονομάζονται με βάση το όνομα που χρησιμοποιείται για τη ρύθμιση του πειράματος. Καταγράφονται όλα τα εκπαιδευμένα μοντέλα εκμάθησης μηχανής, οι εκτελέσεις τους, τα μετρικά επιδόσεων και οι παράμετροι μοντέλου.
Για να δείτε τα πειράματά σας:
Στον αριστερό πίνακα, επιλέξτε τον χώρο εργασίας σας.
Στην επάνω δεξιά γωνία, φιλτράρετε για να εμφανίσετε μόνο τα πειράματα, ώστε να είναι πιο εύκολο να βρείτε το πείραμα που αναζητάτε.
Βρείτε και επιλέξτε το όνομα του πειράματος, σε αυτή την περίπτωση πείραμα-απώλειας τράπεζας. Εάν δεν βλέπετε το πείραμα στον χώρο εργασίας σας, ανανεώστε το πρόγραμμα περιήγησης.
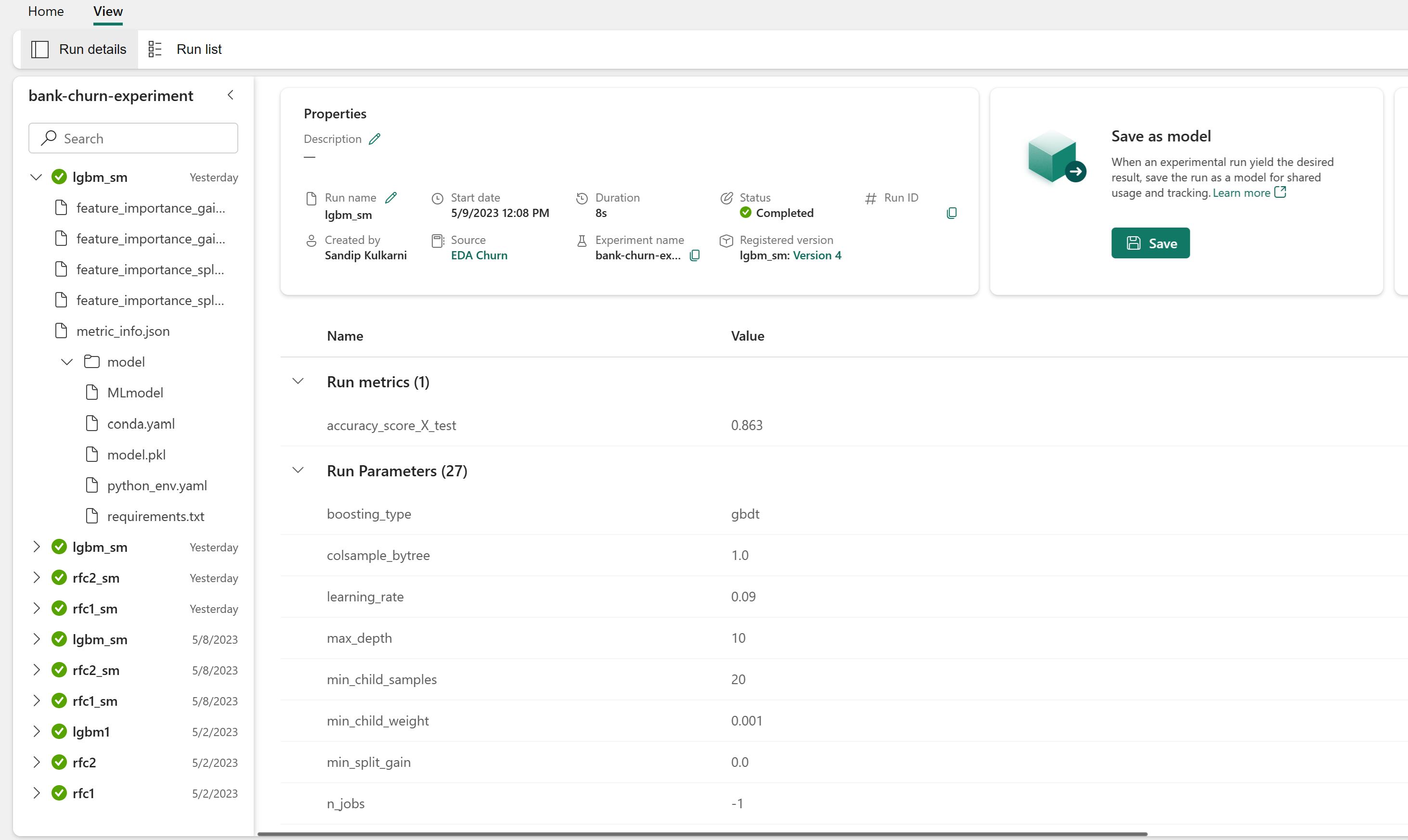


Αξιολόγηση των επιδόσεων των εκπαιδευμένων μοντέλων στο σύνολο δεδομένων επικύρωσης
Αφού ολοκληρώσετε την εκπαίδευση του μοντέλου εκμάθησης μηχανής, μπορείτε να αξιολογήσετε την απόδοση των εκπαιδευμένων μοντέλων με δύο τρόπους.
Ανοίξτε το αποθηκευμένο πείραμα από τον χώρο εργασίας, φορτώστε τα μοντέλα εκμάθησης μηχανής και, στη συνέχεια, αξιολογήστε τις επιδόσεις των φορτωμένων μοντέλων στο σύνολο δεδομένων επικύρωσης.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMΑξιολογήστε απευθείας τις επιδόσεις των εκπαιδευμένων μοντέλων εκμάθησης μηχανής στο σύνολο δεδομένων επικύρωσης.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
Ανάλογα με την προτίμησή σας, οποιαδήποτε προσέγγιση είναι καλή και θα πρέπει να προσφέρει πανομοιότυπες επιδόσεις. Σε αυτό το σημειωματάριο, θα επιλέξετε την πρώτη προσέγγιση προκειμένου να επιδείξετε καλύτερα τις δυνατότητες αυτόματης καταχώρησης ροής ML στο Microsoft Fabric.
Εμφάνιση Αληθώς/Ψευδώς θετικών/αρνητικών με χρήση της μήτρας σύγχυσης
Στη συνέχεια, θα αναπτύξετε μια δέσμη ενεργειών για να σχεδιάσετε τη μήτρα σύγχυσης, προκειμένου να αξιολογήσετε την ακρίβεια της ταξινόμησης χρησιμοποιώντας το σύνολο δεδομένων επικύρωσης. Η μήτρα σύγχυσης μπορεί να σχεδιαστεί επίσης με χρήση εργαλείων SynapseML, το οποίο εμφανίζεται στο δείγμα εντοπισμού απάτης που είναι διαθέσιμο εδώ.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
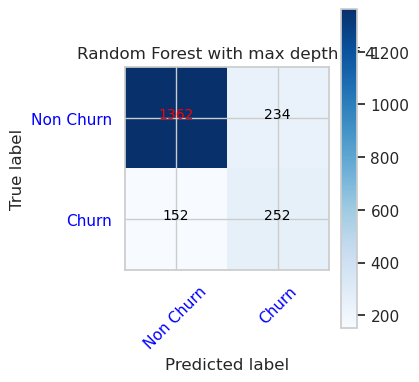
- Μήτρα σύγχυσης για τον αλγόριθμο ταξινόμησης τυχαίου δάσους με μέγιστο βάθος 4 και 4 δυνατότητες
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
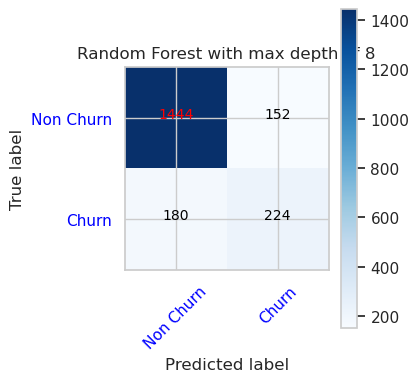
- Μήτρα σύγχυσης για τον αλγόριθμο ταξινόμησης τυχαίου δάσους με μέγιστο βάθος 8 και 6 δυνατότητες
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
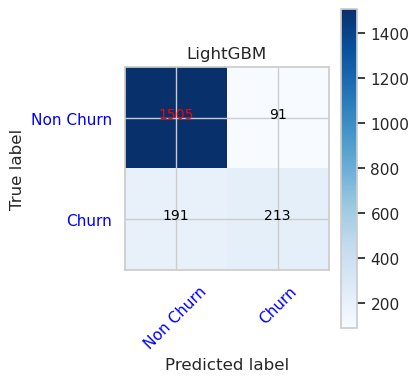
- Μήτρα σύγχυσης για LightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()