Σημείωση
Η πρόσβαση σε αυτή τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να συνδεθείτε ή να αλλάξετε καταλόγους.
Η πρόσβαση σε αυτή τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να αλλάξετε καταλόγους.
Σε αυτήν την εκμάθηση, βασίζεστε στην εργασία ενός αναλυτή Power BI που αποθηκεύεται ως σημασιολογικά μοντέλα (σύνολα δεδομένων Power BI). Χρησιμοποιώντας SemPy (προεπισκόπηση) στην εμπειρία επιστήμης δεδομένων συνάψεων στο Microsoft Fabric, μπορείτε να αναλύσετε λειτουργικές εξαρτήσεις σε στήλες DataFrame. Αυτή η ανάλυση σάς βοηθά να ανακαλύψετε λεπτά ζητήματα ποιότητας δεδομένων για να λάβετε πιο ακριβείς πληροφορίες.
Σε αυτή την εκμάθηση, θα μάθετε πώς μπορείτε να κάνετε τα εξής:
- Εφαρμόστε γνώσεις τομέα σε υποθέσεις τύπων σχετικά με λειτουργικές εξαρτήσεις σε ένα μοντέλο σημασιολογίας.
- Εξοικειωθείτε με στοιχεία της βιβλιοθήκης Python του Semantic Link (SemPy) που ενοποιούνται με το Power BI και βοηθούν στην αυτοματοποίηση της ανάλυσης ποιότητας δεδομένων. Αυτά τα στοιχεία περιλαμβάνουν:
- FabricDataFrame—δομή τύπου πάντα ενισχυμένη με πρόσθετες σημασιολογικές πληροφορίες
- Συναρτήσεις που αντλούν σημασιολογικά μοντέλα από ένα χώρο εργασίας Fabric στο σημειωματάριό σας
- Συναρτήσεις που αξιολογούν υποθέσεις λειτουργικής εξάρτησης και εντοπίζουν παραβιάσεις σχέσεων στα σημασιολογικά σας μοντέλα
Προϋποθέσεις
Λάβετε μια συνδρομής Microsoft Fabric . Εναλλακτικά, εγγραφείτε για μια δωρεάν δοκιμαστική έκδοση microsoft Fabric.
Εισέλθετε για να το Microsoft Fabric.
Μεταβείτε στο Fabric χρησιμοποιώντας την εναλλαγή εμπειριών στην κάτω αριστερή πλευρά της αρχικής σελίδας σας.
Επιλέξτε Χώροι εργασίας από το παράθυρο περιήγησης για να βρείτε και να επιλέξετε τον χώρο εργασίας σας. Αυτός ο χώρος εργασίας γίνεται ο τρέχων χώρος εργασίας σας.
Κάντε λήψη του αρχείου Customer Profitability Sample.pbix από το αποθετήριο δειγμάτων υφασμάτων GitHub.
Στον χώρο εργασίας σας, επιλέξτε
Εισαγωγή Αναφορά ή Σελιδοποιημένη αναφορά Από αυτόν τον υπολογιστή για να αποστείλετε το αρχείο Δείγμα κερδοφορίας πελάτη.pbix στον χώρο εργασίας σας.
Ακολουθήστε τις οδηγίες στο σημειωματάριο
Το σημειωματάριο
Για να ανοίξετε το σημειωματάριο που συνοδεύει αυτό το εκπαιδευτικό βοήθημα, ακολουθήστε τις οδηγίες στο Προετοιμασία του συστήματός σας για εκπαιδευτικά βοηθήματα επιστήμης δεδομένων, να εισαγάγετε το σημειωματάριο στον χώρο εργασίας σας.
Εάν προτιμάτε να αντιγράψετε και να επικολλήσετε τον κώδικα από αυτήν τη σελίδα, μπορείτε να δημιουργήσετε ένα νέο σημειωματάριο.
Βεβαιωθείτε ότι επισυνάψετε μια λίμνη στο σημειωματάριο προτού ξεκινήσετε την εκτέλεση κώδικα.
Ρύθμιση του σημειωματάριου
Ρυθμίστε ένα περιβάλλον σημειωματαρίου με τις λειτουργικές μονάδες και τα δεδομένα που χρειάζεστε.
Χρησιμοποιήστε το
%pipγια να εγκαταστήσετε το SemPy από το PyPI στο σημειωματάριο.%pip install semantic-linkΕισαγάγετε τις λειτουργικές μονάδες που χρειάζεστε.
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
Φόρτωση και προεπεξεργασία των δεδομένων
Αυτό το εκπαιδευτικό βοήθημα χρησιμοποιεί ένα τυπικό δείγμα σημασιολογικού μοντέλου δείγμα κερδοφορίας πελάτη.pbix. Για μια περιγραφή του μοντέλου σημασιολογίας, ανατρέξτε στο θέμα δείγμα κερδοφορίας πελάτη για το Power BI.
Φορτώστε δεδομένα Power BI σε ένα
FabricDataFrameχρησιμοποιώντας τηfabric.read_tableσυνάρτηση.dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()Τοποθετήστε τον
Stateπίνακα σε έναFabricDataFrameαρχείο .state = fabric.read_table(dataset, "State") state.head()Αν και η έξοδος μοιάζει με ένα pandas DataFrame, αυτός ο κώδικας προετοιμάζει μια δομή δεδομένων που ονομάζεται a
FabricDataFrameκαι προσθέτει λειτουργίες πάνω από τα πάντα.Ελέγξτε τον τύπο δεδομένων .
customertype(customer)Η έξοδος δείχνει ότι
customerείναιsempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.Ενώστε τα
customerαντικείμενα andstateDataFrame.customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
Προσδιορισμός λειτουργικών εξαρτήσεων
Μια συναρτησιακή εξάρτηση είναι μια σχέση ένα-προς-πολλά μεταξύ τιμών σε δύο ή περισσότερες στήλες σε ένα DataFrameαρχείο . Χρησιμοποιήστε αυτές τις σχέσεις για να εντοπίσετε αυτόματα προβλήματα ποιότητας δεδομένων.
Εκτελέστε τη συνάρτηση SemPy
find_dependenciesστο συγχωνευμένοDataFrameγια να προσδιορίσετε συναρτησιακές εξαρτήσεις μεταξύ τιμών στηλών.dependencies = customer_state_df.find_dependencies() dependenciesΟπτικοποιήστε τις εξαρτήσεις χρησιμοποιώντας τη συνάρτηση SemPy
plot_dependency_metadata.plot_dependency_metadata(dependencies)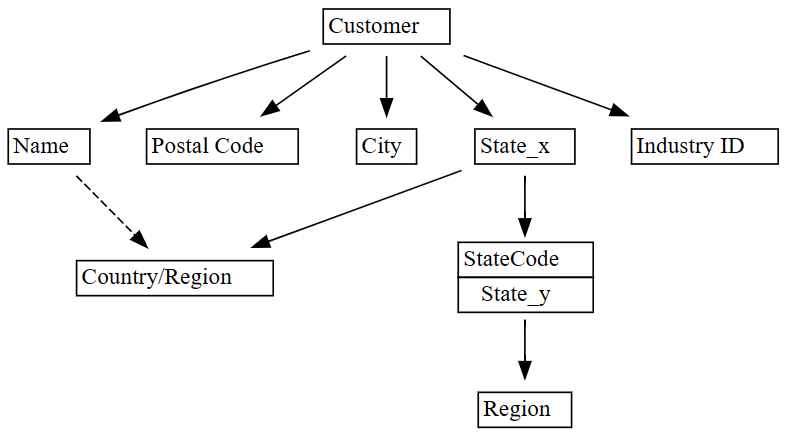
Το γράφημα συναρτησιακών εξαρτήσεων δείχνει ότι η
Customerστήλη καθορίζει στήλες όπωςCity,Postal Code, καιName.Το γράφημα δεν εμφανίζει λειτουργική εξάρτηση μεταξύ
CityκαιPostal Code, πιθανώς επειδή υπάρχουν πολλές παραβιάσεις στη σχέση μεταξύ των στηλών. Χρησιμοποιήστε τη λειτουργία τουplot_dependency_violationsSemPy για να απεικονίσετε παραβιάσεις εξάρτησης μεταξύ συγκεκριμένων στηλών.

Εξερεύνηση των δεδομένων για ποιοτικά προβλήματα
Σχεδιάστε ένα γράφημα με τη συνάρτηση
plot_dependency_violationsαπεικόνισης του SemPy.customer_state_df.plot_dependency_violations('Postal Code', 'City')
Η πλοκή των παραβιάσεων εξάρτησης εμφανίζει τιμές για
Postal Codeστην αριστερή πλευρά και τιμές γιαCityστη δεξιά πλευρά. Ένα άκρο συνδέει έναPostal Codeστην αριστερή πλευρά με έναCityστη δεξιά πλευρά, εάν υπάρχει μια γραμμή που περιέχει αυτές τις δύο τιμές. Τα άκρα επισημαίνονται με το πλήθος αυτών των γραμμών. Για παράδειγμα, υπάρχουν δύο γραμμές με ταχυδρομικό κώδικα 20004, η μία με την πόλη "Βόρειος Πύργος" και η άλλη με την πόλη "Ουάσιγκτον".Η πλοκή δείχνει επίσης μερικές παραβιάσεις και πολλές κενές τιμές.
Επιβεβαιώστε τον αριθμό των κενών τιμών για
Postal Code:customer_state_df['Postal Code'].isna().sum()50 σειρές έχουν NA για
Postal Code.Αποθέστε γραμμές με κενές τιμές. Στη συνέχεια, βρείτε τις εξαρτήσεις χρησιμοποιώντας τη συνάρτηση
find_dependencies. Παρατηρήστε ότι η επιπλέον παράμετροςverbose=1που προσφέρει μια ματιά στις εσωτερικές λειτουργίες του SemPy:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)Η εντροπία υπό όρους για
Postal CodeκαιCityείναι 0,049. Αυτή η τιμή υποδεικνύει ότι υπάρχουν παραβιάσεις λειτουργικής εξάρτησης. Πριν διορθώσετε τις παραβιάσεις, αυξήστε το όριο στην εντροπία υπό όρους από την προεπιλεγμένη τιμή του0.01σε0.05, απλώς για να δείτε τις εξαρτήσεις. Τα χαμηλότερα όρια έχουν ως αποτέλεσμα λιγότερες εξαρτήσεις (ή υψηλότερη επιλεκτικότητα).Αυξήστε το όριο στην εντροπία υπό όρους από την προεπιλεγμένη τιμή του
0.01σε0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))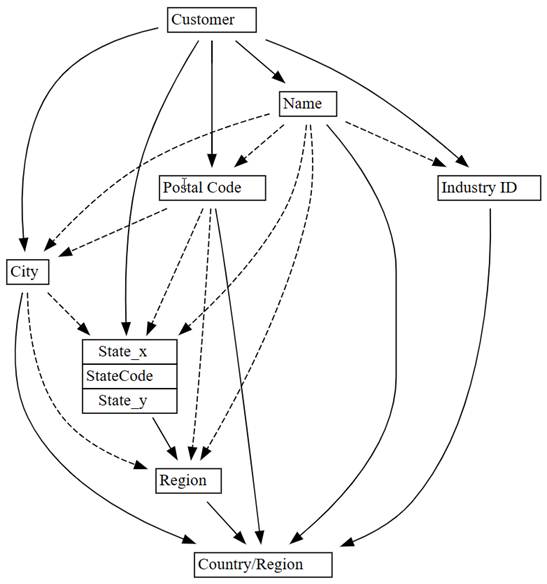
Εάν εφαρμόσετε γνώση τομέα για το ποια οντότητα καθορίζει τις τιμές άλλων οντοτήτων, αυτό το γράφημα εξάρτησης φαίνεται ακριβές.
Εξερευνήστε περισσότερα προβλήματα ποιότητας δεδομένων που εντοπίστηκαν. Για παράδειγμα, ένα διακεκομμένη βέλος συνδέει
CityκαιRegion, το οποίο υποδεικνύει ότι η εξάρτηση είναι μόνο κατά προσέγγιση. Αυτή η κατά προσέγγιση σχέση μπορεί να σημαίνει ότι υπάρχει μια μερική λειτουργική εξάρτηση.customer_state_df.list_dependency_violations('City', 'Region')Ρίξτε μια πιο προσεκτική ματιά σε κάθε μία από τις περιπτώσεις όπου μια μη
Regionτιμή προκαλεί παραβίαση:customer_state_df[customer_state_df.City=='Downers Grove']Το αποτέλεσμα δείχνει την πόλη Downers Grove στο Ιλινόις και τη Νεμπράσκα. Ωστόσο, το Downers Grove είναι μια πόλη στο Ιλινόις, όχι στη Νεμπράσκα.
Ρίξτε μια ματιά στην πόλη του Fremont:
customer_state_df[customer_state_df.City=='Fremont']Υπάρχει μια πόλη που λέγεται Φρεμόντ στην Καλιφόρνια. Ωστόσο, για το Τέξας, η μηχανή αναζήτησης επιστρέφει Premont, όχι στο Fremont.
Είναι επίσης ύποπτο να δείτε παραβιάσεις της εξάρτησης μεταξύ
NameκαιCountry/Region, όπως υποδεικνύεται από τη διάστικτη γραμμή στο αρχικό γράφημα παραβιάσεων εξάρτησης (πριν από την πτώση των γραμμών με κενές τιμές).customer_state_df.list_dependency_violations('Name', 'Country/Region')Ένας πελάτης, η SDI Design, εμφανίζεται σε δύο περιοχές—Ηνωμένες Πολιτείες και Καναδάς. Αυτή η περίπτωση μπορεί να μην είναι σημασιολογική παραβίαση, απλώς ασυνήθιστη. Ωστόσο, αξίζει μια προσεκτική ματιά:
Ρίξτε μια πιο προσεκτική ματιά στοσχεδίασης SDI
πελάτη: customer_state_df[customer_state_df.Name=='SDI Design']Περαιτέρω επιθεώρηση δείχνει δύο διαφορετικούς πελάτες από διαφορετικούς κλάδους με το ίδιο όνομα.

Η διερευνητική ανάλυση δεδομένων και ο καθαρισμός δεδομένων είναι επαναληπτικοί. Αυτό που βρίσκετε εξαρτάται από τις ερωτήσεις και την προοπτική σας. Το Semantic Link σάς παρέχει νέα εργαλεία για να αξιοποιήσετε περισσότερο τα δεδομένα σας.
Σχετικό περιεχόμενο
Δείτε άλλα σεμινάρια για σημασιολογική σύνδεση και SemPy:
- Εκμάθηση : Καθαρισμός δεδομένων με λειτουργικές εξαρτήσεις
- Εκμάθηση : Εξαγωγή και υπολογισμός μετρήσεων Power BI από ένα σημειωματάριο Jupyter
- Εκμάθηση : Εντοπισμός σχέσεων σε ένα μοντέλο σημασιολογίας, χρησιμοποιώντας σημασιολογική σύνδεση
- Πρόγραμμα εκμάθησης: Ανακαλύψτε σχέσεις στο σύνολο δεδομένων Synthea, χρησιμοποιώντας σημασιολογική σύνδεση
- Εκμάθηση : Επικύρωση δεδομένων με χρήση των SemPy και Μεγάλων προσδοκιών (GX)