What's new in SQL Server Analysis Services
Applies to:  SQL Server Analysis Services
SQL Server Analysis Services  Azure Analysis Services
Fabric/Power BI Premium
Azure Analysis Services
Fabric/Power BI Premium
This article summarizes new features, improvements, deprecated and discontinued features, and behavior and breaking changes in the most recent versions of SQL Server Analysis Services (SSAS).
SQL Server 2022 Analysis Services
Cumulative Update 1 (CU1)
Encryption upgrade
This update includes enhancement to the schema write operation encryption algorithm. This enhancement may require you to upgrade tabular and multidimensional model databases to ensure proper encryption. To learn more, see Upgrade encryption.
Generally Available (GA)
Horizontal fusion
This version introduces Horizontal Fusion, a query execution plan optimization aimed at reducing the number of data source queries required to generate and return results. Multiple smaller data source queries are fused together into a larger data source query. Fewer data source queries mean fewer round trips and fewer expensive scans over large data sources, which results in sizeable DAX performance gains and reduced processing demand at the data source. DAX queries run faster with Horizontal Fusion, especially in DirectQuery mode. In addition, scalability also increases.
Parallel Execution Plans for DirectQuery
This improvement enables the Analysis Services engine to analyze DAX queries against a DirectQuery data source and identify independent storage engine operations. The engine can then execute those operations against the data source in parallel. By executing operations in parallel, the Analysis Services engine can improve query performance by taking advantage of scalability large data sources may be able to provide. To ensure query processing does not overburden your data source, use the MaxParallelism property setting to specify a fixed number of threads that can be used for parallel operations.
Support for Power BI DirectQuery semantic models
This version introduces support for Power BI models with DirectQuery connections to SQL Server 2022 Analysis Services models. Data modelers and report authors using the May 2022 and later versions of Power BI Desktop can now combine other imported and DirectQuery data from Power BI models, Azure Analysis Services, and now SSAS 2022.
To learn more, see Using DirectQuery for semantic models and Analysis Services | Power BI Documentation.
MDX query performance
First introduced in Power BI and now in SSAS 2022, MDX Fusion includes Formula Engine (FE) optimization reducing the number of Storage Engine (SE) queries per MDX query. Client applications that use Multidimensional Expressions (MDX) to query model/dataset data such as Microsoft Excel will see improved query performance. Common MDX query patterns now require fewer SE queries where previously numerous SE queries were necessary to support different granularity. Fewer SE queries mean fewer expensive scans over large models, which results in significant performance gains, especially when connecting to a tabular models in Direct Query mode.
To learn more, see Announcing improved MDX query performance in Power BI | Microsoft Power BI Blog.
Resource governance
This version includes improved accuracy for the QueryMemoryLimit server memory property and DbpropMsmdRequestMemoryLimit connection string property.
First introduced in SSAS 2019, the QueryMemoryLimit server memory property applied only to memory spools where intermediate DAX query results are created during query processing. Now in SSAS 2022, it also applies to MDX queries, effectively covering all queries. You can better control process expensive queries that result in significant materialization. If the query hits the limit specified, the engine cancels the query and returns an error to the caller, reducing impact on other concurrent users.
Client applications can further reduce the memory allowed per query by specifying the DbpropMsmdRequestMemoryLimit connection string property. Specified in Kilobytes, this property overrides the QueryMemoryLimit server memory property value for a connection.
Query interleaving - Short query bias with fast cancellation
This version introduces a new value that specifies Short query bias with fast cancellation for the Threadpool\SchedulingBehavior property setting. This property setting improves user query response times in high-concurrency scenarios. To learn more, see Query interleaving - Configure.
Tabular model 1600 compatibility level
This version introduces the 1600 compatibility level for tabular models. The 1600 compatibility level coincides with the latest functionality in Power BI and Azure Analysis Services.
Deprecated features in SSAS 2022
There are no deprecated features announced with this version.
Discontinued features in SSAS 2022
The following features are discontinued in this version:
| Mode/Category | Feature |
|---|---|
| Tabular | 1100 and 1103 Compatibility levels |
| Multidimensional | Data Mining |
| Power Pivot mode | Power Pivot for SharePoint |
Breaking changes in SSAS 2022
Tabular model 1100 and 1103 compatibility levels are discontinued in this version. To prevent a breaking change, upgrade models to the 1200 compatibility level prior to upgrading an earlier SSAS version to SSAS 2022.
Behavior changes in SSAS 2022
There are no behavior changes in this version.
SQL Server 2019 Analysis Services
SQL Server 2019 Analysis Services CU 5
SQL Server Analysis Services cumulative updates are included with SQL Server cumulative updates. To learn more about and download the latest cumulative update, see SQL Server 2019 latest cumulative update. Cumulative update KB pages summarize known issues, improvements, and fixes for all SQL Server features, including SSAS. Additional details for major feature updates for SSAS are described here.
SuperDAX for multidimensional models (SuperDAXMD)
With CU5, DAX-based clients can now use SuperDAX functions and query patterns against multidimensional models, providing improved performance when querying model data. SuperDAX first introduced DAX query optimizations for tabular models with Power BI and SQL Server Analysis Services 2016. SuperDAXMD now brings these improvements to multidimensional models.
A separate announcement on the Power BI blog highlights how Power BI users can benefit from this multidimensional model performance improvement by downloading the latest version of Power BI Desktop. Existing interactive reports in the Power BI Service can benefit without any additional steps, as Power BI generates the optimized SuperDAX queries automatically. Power BI automatically detects connections to multidimensional models with SuperDAX support and uses the same optimized DAX functions and query patterns that it already uses against tabular models. While Power BI can automatically switch to SuperDAXMD, in your own business intelligence solutions, you might have to optimize DAX query patterns manually.
Optimized query patterns should use SUMMARIZECOLUMNS function to replace the less efficient standard SUMMARIZE function. Use DAX variables, VAR, to calculate expressions only once at the place of definition, and then reuse the results in any other DAX expressions without having to perform the calculation again. Other, and perhaps less common SuperDAX functions are SUBSTITUTEWITHINDEX, ADDMISSINGITEMS, as well as NATURALLEFTOUTERJOIN and NATURALINNERJOIN, ISONORAFTER, and GROUPBY. SELECTCOLUMNS and UNION are also SuperDAX functions.
To learn more about how DAX works with multidimensional models, and important patterns and constraints to be aware of, be sure to see DAX for multidimensional models.
SQL Server 2019 Analysis Services GA (Generally Available)
Tabular model compatibility level
This release introduces the 1500 compatibility level for tabular models.
Query interleaving
Query interleaving is a tabular mode system configuration that can improve user query response times in high-concurrency scenarios. Query interleaving with short query bias allows concurrent queries to share CPU resources. To learn more, see Query interleaving.
Calculation groups in tabular models
Calculation groups can significantly reduce the number of redundant measures by grouping common measure expressions as calculation items. Calculation groups are shown in reporting clients as a table with a single column. Each value in the column represents a reusable calculation, or calculation item, that can be applied to any of the measures. A calculation group can have any number of calculation items. Each calculation item is defined by a DAX expression. To learn more, see Calculation groups.
Governance setting for Power BI cache refreshes
The ClientCacheRefreshPolicy property setting is now supported in SSAS 2019 and later. This property setting is already available for Azure Analysis Services. The Power BI service caches dashboard tile data and report data for initial load of Live Connect report, causing an excessive number of cache queries being submitted to the engine, and in extreme cases overload the server. The ClientCacheRefreshPolicy property allows you to override this behavior at the server level. To learn more, see General Properties.
Online attach
This feature provides the ability to attach a tabular model as an online operation. Online attach can be used for synchronization of read-only replicas in on-premises query scale-out environments. To perform an online-attach operation, use the AllowOverwrite option of the Attach XMLA command.

This operation may require double the model memory to keep the old version online while loading the new version.
A typical usage pattern could be as follows:
DB1 (version 1) is already attached on read-only server B.
DB1 (version 2) is processed on the write server A.
DB1 (version 2) is detached and placed on a location accessible to server B (either via a shared location, or using robocopy, etc.).
The <Attach> command with AllowOverwrite=True is executed on server B with the new location of DB1 (version 2).
Without this feature, admins are first required to detach the database and then attach the new version of the database. This leads to downtime when the database is unavailable to users, and queries against it will fail.
When this new flag is specified, version 1 of the database is deleted atomically within the same transaction with no downtime. However, it comes at the cost of having both databases loaded into memory simultaneously.
Many-to-many relationships in tabular models
This improvement allows many-to-many relationships between tables where both columns are non-unique. A relationship can be defined between a dimension and fact table at a granularity higher than the key column of the dimension. This avoids having to normalize dimension tables and can improve the user experience because the resulting model has a smaller number of tables with logically grouped columns.
Many-to-many relationships require models be at the 1500 and higher compatibility level. You can create many-to-many relationships by using Visual Studio 2019 with Analysis Services projects VSIX update 2.9.2 and higher, the Tabular Object Model (TOM) API, Tabular Model Scripting Language (TMSL), and the open-source Tabular Editor tool.
Memory settings for resource governance
The following property settings provide improved resource governance:
- Memory\QueryMemoryLimit - This memory property can be used to limit memory spools built by DAX queries submitted to the model.
- DbpropMsmdRequestMemoryLimit - This XMLA property can be used to override the Memory\QueryMemoryLimit server property value for a connection.
- OLAP\Query\RowsetSerializationLimit - This server property limits the number of rows returned in a rowset, protecting server resources from extensive data export usage. This property applies to both applies to both DAX and MDX queries.
These properties can be set by using the latest version of SQL Server Management Studio (SSMS). These settings are already available for Azure Analysis Services.
Deprecated features in SSAS 2019
There are no deprecated features announced with this release.
Discontinued features in SSAS 2019
There are no discontinued features announced with this release.
Breaking changes in SSAS 2019
There are no breaking changes in this release.
Behavior changes in SSAS 2019
There are no behavior changes in this release.
SQL Server 2017 Analysis Services
SQL Server 2017 Analysis Services see some of the most important enhancements since SQL Server 2012. Building on the success of Tabular mode (first introduced in SQL Server 2012 Analysis Services), this release makes tabular models more powerful than ever.
Multidimensional mode and Power Pivot for SharePoint mode are a staple for many Analysis Services deployments. In the Analysis Services product lifecycle, these modes are mature. There are no new features for either of these modes in this release. However, bug fixes and performance improvements are included.
The features described here are included in SQL Server 2017 Analysis Services. But in order to take advantage of them, you must also use the latest versions of Visual Studio with Analysis Services projects and SQL Server Management Studio (SSMS). Analysis Services projects and SSMS are updated monthly with new and improved features that typically coincide with new functionality in SQL Server.
While it's important to learn about all the new features, it's also important to know what is being deprecated and discontinued in this release and future releases. To learn more, see Deprecated features in SSAS 2017.
Let's take a look at some of the key new features in this release.
1400 Compatibility level for tabular models
To take advantage of many of the new features and functionality described here, new or existing tabular models must be set or upgraded to the 1400 compatibility level. Models at the 1400 compatibility level cannot be deployed to SQL Server 2016 SP1 or earlier, or downgraded to lower compatibility levels. To learn more, see Compatibility level for Analysis Services tabular models.
In Visual Studio, you can select the new 1400 compatibility level when creating new tabular model projects.
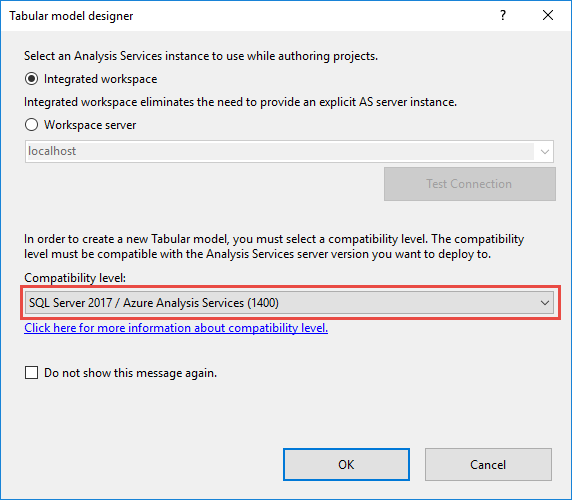
To upgrade an existing tabular model in Visual Studio, in Solution Explorer, right-click Model.bim, and then in Properties, set the Compatibility Level property to SQL Server 2017 (1400).
It's important to keep in mind, once you upgrade an existing model to 1400, you can't downgrade. Be sure to keep a backup of your 1200 model database.
Modern Get Data experience
When it comes to importing data from data sources into your tabular models, SSDT introduces the modern Get Data experience for models at the 1400 compatibility level. This new feature is based on similar functionality in Power BI Desktop and Microsoft Excel 2016. The modern Get Data experience provides immense data transformation and data mashup capabilities by using the Get Data query builder and M expressions.
The modern Get Data experience provides support for a wide range of data sources. Going forward, updates will include support for even more.
A powerful and intuitive user interface makes selecting your data and data transformation/mashup capabilities easier than ever.

The modern Get Data experience and M mashup capabilities do not apply to existing tabular models upgraded from the 1200 compatibility level to 1400. The new experience only applies to new models created at the 1400 compatibility level.
Encoding hints
This release introduces encoding hints, an advanced feature used to optimize processing (data refresh) of large in-memory tabular models. To better understand encoding, see Performance Tuning of Tabular Models in SQL Server 2012 Analysis Services whitepaper to better understand encoding.
Value encoding provides better query performance for columns that are typically only used for aggregations.
Hash encoding is preferred for group-by columns (often dimension-table values) and foreign keys. String columns are always hash encoded.
Numeric columns can use either of these encoding methods. When Analysis Services starts processing a table, if either the table is empty (with or without partitions) or a full-table processing operation is being performed, samples values are taken for each numeric column to determine whether to apply value or hash encoding. By default, value encoding is chosen when the sample of distinct values in the column is large enough - otherwise hash encoding usually provides better compression. It is possible for Analysis Services to change the encoding method after the column is partially processed based on further information about the data distribution, and restart the encoding process; however, this increases processing time and is inefficient. The performance-tuning whitepaper discusses re-encoding in more detail and describes how to detect it using SQL Server Profiler.
Encoding hints allow the modeler to specify a preference for the encoding method given prior knowledge from data profiling and/or in response to re-encoding trace events. Since aggregation over hash-encoded columns is slower than over value-encoded columns, value encoding may be specified as a hint for such columns. It is not guaranteed that the preference is applied. It is a hint as opposed to a setting. To specify an encoding hint, set the EncodingHint property on the column. Possible values are "Default", "Value" and "Hash". The following snippet of JSON-based metadata from the Model.bim file specifies value encoding for the Sales Amount column.
{
"name": "Sales Amount",
"dataType": "decimal",
"sourceColumn": "SalesAmount",
"formatString": "\\$#,0.00;(\\$#,0.00);\\$#,0.00",
"sourceProviderType": "Currency",
"encodingHint": "Value"
}
Ragged hierarchies
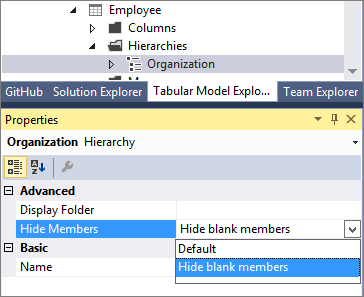
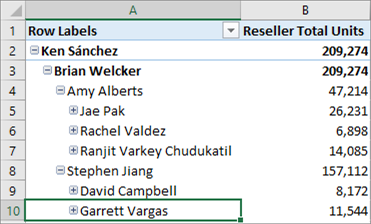
In tabular models, you can model parent-child hierarchies. Hierarchies with a differing number of levels are often referred to as ragged hierarchies. By default, ragged hierarchies are displayed with blanks for levels below the lowest child. Here's an example of a ragged hierarchy in an organizational chart:

This release introduces the Hide Members property. You can set the Hide Members property for a hierarchy to Hide blank members.
Note
Blank members in the model are represented by a DAX blank value, not an empty string.
When set to Hide blank members, and the model deployed, an easier to read version of the hierarchy is shown in reporting clients like Excel.
Detail Rows
You can now define a custom row set contributing to a measure value. Detail Rows is similar to the default drillthrough action in multidimensional models. This allows end-users to view information in more detail than the aggregated level.
The following PivotTable shows Internet Total Sales by year from the Adventure Works sample tabular model. You can right-click a cell with an aggregated value from the measure and then click Show Details to view the detail rows.
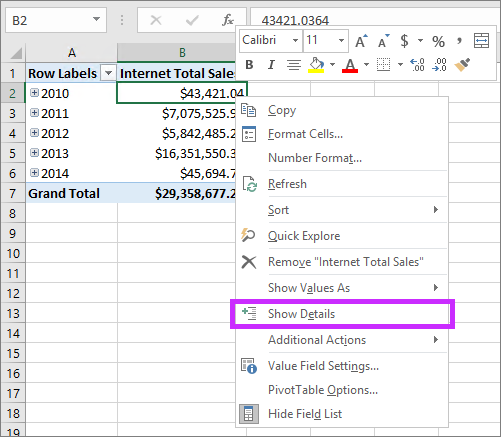
By default, the associated data in the Internet Sales table is displayed. This limited behavior is often not meaningful for the user because the table may not have the necessary columns to show useful information such as customer name and order information. With Detail Rows, you can specify a Detail Rows Expression property for measures.
Detail Rows Expression property for measures
The Detail Rows Expression property for measures allows model authors to customize the columns and rows returned to the end-user.
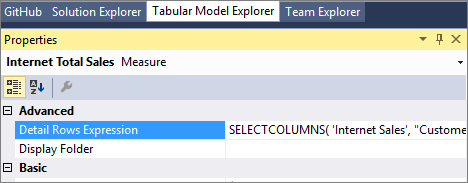
The SELECTCOLUMNS DAX function is commonly used in a Detail Rows Expression. The following example defines the columns to be returned for rows in the Internet Sales table in the sample Adventure Works tabular model:
SELECTCOLUMNS(
'Internet Sales',
"Customer First Name", RELATED( Customer[Last Name]),
"Customer Last Name", RELATED( Customer[First Name]),
"Order Date", 'Internet Sales'[Order Date],
"Internet Total Sales", [Internet Total Sales]
)
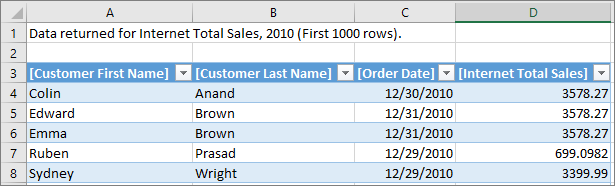
With the property defined and the model deployed, a custom row set is returned when the user selects Show Details. It automatically honors the filter context of the cell that was selected. In this example, only the rows for 2010 value are displayed:
Default Detail Rows Expression property for tables
In addition to measures, tables also have a property to define a detail rows expression. The Default Detail Rows Expression property acts as the default for all measures within the table. Measures that do not have their own expression defined inherits the expression from the table and show the row set defined for the table. This allows reuse of expressions, and new measures added to the table later automatically inherits the expression.
DETAILROWS DAX Function
Included in this release is a new DETAILROWS DAX function that returns the row set defined by the detail rows expression. It works similarly to the DRILLTHROUGH statement in MDX, which is also compatible with detail rows expressions defined in tabular models.
The following DAX query returns the row set defined by the detail rows expression for the measure or its table. If no expression is defined, the data for the Internet Sales table is returned because it's the table containing the measure.
EVALUATE DETAILROWS([Internet Total Sales])
Object-level security
This release introduces object-level security for tables and columns. In addition to restricting access to table and column data, sensitive table and column names can be secured. This helps prevent a malicious user from discovering such a table exists.
Object-level security must be set using the JSON-based metadata, Tabular Model Scripting Language (TMSL), or Tabular Object Model (TOM).
For example, the following code helps secure the Product table in the sample Adventure Works tabular model by setting the MetadataPermission property of the TablePermission class to None.
//Find the Users role in Adventure Works and secure the Product table
ModelRole role = db.Model.Roles.Find("Users");
Table productTable = db.Model.Tables.Find("Product");
if (role != null && productTable != null)
{
TablePermission tablePermission;
if (role.TablePermissions.Contains(productTable.Name))
{
tablePermission = role.TablePermissions[productTable.Name];
}
else
{
tablePermission = new TablePermission();
role.TablePermissions.Add(tablePermission);
tablePermission.Table = productTable;
}
tablePermission.MetadataPermission = MetadataPermission.None;
}
db.Update(UpdateOptions.ExpandFull);
Dynamic Management Views (DMVs)
DMVs are queries in SQL Server Profiler that return information about local server operations and server health. This release includes improvements to Dynamic Management Views (DMV) for tabular models at the 1200 and 1400 compatibility levels.
DISCOVER_CALC_DEPENDENCY Now works with tabular 1200 and higher models. Tabular 1400 and higher models show dependencies between M partitions, M expressions and structured data sources. To learn more, see the Analysis Services blog.
MDSCHEMA_MEASUREGROUP_DIMENSIONS Improvements are included for this DMV, which is used by various client tools to show measure dimensionality. For example, the Explore feature in Excel Pivot Tables allows the user to cross-drill to dimensions related to the selected measures. This release corrects the cardinality columns, which were previously showing incorrect values.
DAX enhancements
One of the most important pieces of new DAX functionality is the new IN Operator / CONTAINSROW Function for DAX expressions. This is similar to the TSQL IN operator commonly used to specify multiple values in a WHERE clause.
Previously, it was common to specify multi-value filters using the logical OR operator, like in the following measure expression:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
'Product'[Color] = "Red"
|| 'Product'[Color] = "Blue"
|| 'Product'[Color] = "Black"
)
This is simplified using the IN operator:
Filtered Sales:=CALCULATE (
[Internet Total Sales], 'Product'[Color] IN { "Red", "Blue", "Black" }
)
In this case, the IN operator refers to a single-column table with 3 rows; one for each of the specified colors. Note the table constructor syntax uses curly braces.
The IN operator is functionally equivalent to the CONTAINSROW function:
Filtered Sales:=CALCULATE (
[Internet Total Sales], CONTAINSROW({ "Red", "Blue", "Black" }, 'Product'[Color])
)
The IN operator can also be used effectively with table constructors. For example, the following measure filters by combinations of product color and category:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
FILTER( ALL('Product'),
( 'Product'[Color] = "Red" && Product[Product Category Name] = "Accessories" )
|| ( 'Product'[Color] = "Blue" && Product[Product Category Name] = "Bikes" )
|| ( 'Product'[Color] = "Black" && Product[Product Category Name] = "Clothing" )
)
)
By using the new IN operator, the measure expression above is now equivalent to the one below:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
FILTER( ALL('Product'),
('Product'[Color], Product[Product Category Name]) IN
{ ( "Red", "Accessories" ), ( "Blue", "Bikes" ), ( "Black", "Clothing" ) }
)
)
Additional improvements
In addition to all the new features, Analysis Services, SSDT, and SSMS also include the following improvements:
- Hierarchy and column reuse surfaced in more helpful locations in the Power BI field list.
- Date relationships to easily create relationships to date dimensions based on date fields.
- Default installation option for Analysis Services is now for tabular mode.
- New Get Data (Power Query) data sources.
- DAX Editor for SSDT.
- Existing DirectQuery data sources support for M queries.
- SSMS improvements, such as viewing, editing, and scripting support for structured data sources.
Deprecated features in SSAS 2017
The following features are deprecated in this release:
| Mode/Category | Feature |
|---|---|
| Multidimensional | Data Mining |
| Multidimensional | Remote linked measure groups |
| Tabular | Models at the 1100 and 1103 compatibility level |
| Tabular | Tabular Object Model properties - Column.TableDetailPosition, Column.IsDefaultLabel, Column.IsDefaultImage |
| Tools | SQL Server Profiler for Trace Capture The replacement is to use Extended Events Profiler embedded in SQL Server Management Studio. See Monitor Analysis Services with SQL Server Extended Events. |
| Tools | Server Profiler for Trace Replay Replacement. There is no replacement. |
| Trace Management Objects and Trace APIs | Microsoft.AnalysisServices.Trace objects (contains the APIs for Analysis Services Trace and Replay objects). The replacement is multi-part: - Trace Configuration: Microsoft.SqlServer.Management.XEvent - Trace Reading: Microsoft.SqlServer.XEvent.Linq - Trace Replay: None |
Discontinued features in SSAS 2017
The following features are discontinued in this release:
| Mode/Category | Feature |
|---|---|
| Tabular | VertiPaqPagingPolicy memory property value (2), enable paging to disk using memory mapped files. |
| Multidimensional | Remote partitions |
| Multidimensional | Remote linked measure groups |
| Multidimensional | Dimensional writeback |
| Multidimensional | Linked dimensions |
Breaking changes in SSAS 2017
There are no breaking changes in this release.
Behavior changes in SSAS 2017
Changes to MDSCHEMA_MEASUREGROUP_DIMENSIONS and DISCOVER_CALC_DEPENDENCY, detailed in the What's new in SQL Server 2017 CTP 2.1 for Analysis Services announcement.
SQL Server 2016 Analysis Services
SQL Server 2016 Analysis Services includes many new enhancements providing improved performance, easier solution authoring, automated database management, enhanced relationships with bi-directional cross filtering, parallel partition processing, and much more. At the heart of most enhancements for this release is the new 1200 compatibility level for tabular model databases.
SQL Server 2016 Service Pack 1 (SP1) Analysis Services
SQL Server 2016 Service SP1 Analysis Services provides improved performance and scalability through Non-Uniform Memory Access (NUMA) awareness and optimized memory allocation based on Intel Threading Building Blocks (Intel TBB). This new functionality helps lower Total Cost of Ownership (TCO) by supporting more users on fewer, more powerful enterprise servers.
In particular, SQL Server 2016 SP1 Analysis Services features improvements in these key areas:
- NUMA awareness - For better NUMA support, the in-memory (VertiPaq) engine inside Analysis Services now maintains a separate job queue on each NUMA node. This guarantees the segment scan jobs run on the same node where the memory is allocated for the segment data. Note, NUMA awareness is only enabled by default on systems with at least four NUMA nodes. On two-node systems, the costs of accessing remote allocated memory generally doesn't warrant the overhead of managing NUMA specifics.
- Memory allocation - Analysis Services has been accelerated with Intel Threading Building Blocks, a scalable allocator that provides separate memory pools for every core. As the number of cores increases, the system can scale almost linearly.
- Heap fragmentation - The Intel TBB-based scalable allocator also helps to mitigate performance problems due to heap fragmentation that have been shown to occur with the Windows Heap.
Performance and scalability testing showed significant gains in query throughput when running SQL Server 2016 SP1 Analysis Services on large multi-node enterprise servers.
While most enhancements in this release are specific to tabular models, a number of enhancements have been made to multidimensional models; for example, distinct count ROLAP optimization for data sources like DB2 and Oracle, drill-through multi-selection support with Excel 2016, and Excel query optimizations.
SQL Server 2016 General Availability (GA) Analysis Services
Modeling
Improved modeling performance for tabular 1200 models
For tabular 1200 models, metadata operations in SSDT are much faster than tabular 1100 or 1103 models. By comparison, on the same hardware, creating a relationship on a model set to the SQL Server 2014 compatibility level (1103) with 23 tables takes 3 seconds, whereas the same relationship on a model created set to compatibility level 1200 takes just under a second.
Project templates added for tabular 1200 models in SSDT
With this release, you no longer need two versions of SSDT for building relational and BI projects. SQL Server Data Tools for Visual Studio 2015 adds project templates for Analysis Services solutions, including Analysis Services Tabular Projects used for building models at the 1200 compatibility level. Other Analysis Services project templates for multidimensional and data mining solutions are also included, but at the same functional level (1100 or 1103) as in previous releases.
Display folders
Display folders are now available for tabular 1200 models. Defined in SQL Server Data Tools and rendered in client applications like Excel or Power BI Desktop, display folders help you organize large numbers of measures into individual folders, adding a visual hierarchy for easier navigation in field lists.
Bi-directional cross filtering
New in this release is a built-in approach for enabling bi-directional cross filters in tabular models, eliminating the need for hand-crafted DAX workarounds for propagating filter context across table relationships. Filters are only auto-generated when the direction can be established with a high degree of certainty. If there is ambiguity in the form of multiple query paths across table relationships, a filter won't be created automatically. See Bi-directional cross filters for tabular models in SQL Server 2016 Analysis Services for details.
Translations
You can now store translated metadata in a tabular 1200 model. Metadata in the model includes fields for Culture, translated captions, and translated descriptions. To add translations, use the Model > Translations command in SQL Server Data Tools. See Translations in tabular models (Analysis Services) for details.
Pasted tables
You can now upgrade an 1100 or 1103 tabular model to 1200 when the model contains pasted tables. We recommend using SQL Server Data Tools. In SSDT, set CompatibilityLevel to 1200 and then deploy to a SQL Server 2017 instance of SQL Server Analysis Services. See Compatibility Level for Tabular models in Analysis Services for details.
Calculated tables in SSDT
A calculated table is a model-only construction based on a DAX expression or query in SSDT. When deployed in a database, a calculated table is indistinguishable from regular tables.
There are several uses for calculated tables, including the creation of new tables to expose an existing table in a specific role. The classic example is a Date table that operates in multiple contexts (order date, ship date, and so forth). By creating a calculated table for a given role, you can now activate a table relationship to facilitate queries or data interaction using the calculated table. Another use for calculated tables is to combine parts of existing tables into an entirely new table that exists only in the model. See Create a Calculated Table to learn more.
Formula fixup
With formula fixup on a tabular 1200 model, SSDT will automatically update any measures that is referencing a column or table that was renamed.
Support for Visual Studio configuration manager
To support multiple environments, like Test and Pre-production environments, Visual Studio allows developers to create multiple project configurations using the configuration manager. Multidimensional models already leverage this but tabular models did not. With this release, you can now use configuration manager to deploy to different servers.
Instance management
Administer Tabular 1200 models in SSMS
In this release, an Analysis Services instance in Tabular server mode can run tabular models at any compatibility level (1100, 1103, 1200). The latest SQL Server Management Studio is updated to display properties and provide database model administration for tabular models at the 1200 compatibility level.
Parallel processing for multiple table partitions in tabular models
This release includes new parallel processing functionality for tables with two or more partitions, increasing processing performance. There are no configuration settings for this feature. For more information about configuring partitions and processing tables, see Tabular model partitions.
Add computer accounts as Administrators in SSMS
SQL Server Analysis Services administrators can now use SQL Server Management Studio to configure computer accounts to be members of the SQL Server Analysis Services administrators group. In the Select Users or Groups dialog, set the Locations for the computers domain and then add the Computers object type. For more information, see Grant server admin rights to an Analysis Services instance.
DBCC for Analysis Services
Database Consistency Checker (DBCC) runs internally to detect potential data corruption issues on database load, but can also be run on demand if you suspect problems in your data or model. DBCC runs different checks depending on whether the model is tabular or multidimensional. See Database Consistency Checker (DBCC) for Analysis Services tabular and multidimensional databases for details.
Extended Events updates
This release adds a graphical user interface to SQL Server Management Studio to configure and manage SQL Server Analysis Services Extended Events. You can set up live data streams to monitor server activity in real time, keep session data loaded in memory for faster analysis, or save data streams to a file for offline analysis. For more information, see Monitor Analysis Services with SQL Server Extended Events.
Scripting
PowerShell for Tabular models
This release includes PowerShell enhancements for tabular models at compatibility level 1200. You can use all of the applicable cmdlets, plus cmdlets specific to Tabular mode: Invoke-ProcessASDatabase and Invoke-ProcessTable cmdlet.
SSMS scripting database operations
In the latest SQL Server Management Studio (SSMS), script is now enabled for database commands, including Create, Alter, Delete, Backup, Restore, Attach, Detach. Output is Tabular Model Scripting Language (TMSL) in JSON. See Tabular Model Scripting Language (TMSL) Reference for more information.
Analysis Services Execute DDL Task
Analysis Services Execute DDL Task now also accepts Tabular Model Scripting Language (TMSL) commands.
SSAS PowerShell cmdlet
SSAS PowerShell cmdlet Invoke-ASCmd now accepts Tabular Model Scripting Language (TMSL) commands. Other SSAS PowerShell cmdlets may be updated in a future release to use the new tabular metadata (exceptions will be called out in the release notes). See Analysis Services PowerShell Reference for details.
Tabular Model Scripting Language (TMSL) supported in SSMS
Using the latest version of SSMS, you can now create scripts to automate most administrative tasks for tabular 1200 models. Currently, the following tasks can be scripted: Process at any level, plus CREATE, ALTER, DELETE at the database level.
Functionally, TMSL is equivalent to the XMLA ASSL extension that provides multidimensional object definitions, except that TMSL uses native descriptors like model, table, and relationship to describe tabular metadata. See Tabular Model Scripting Language (TMSL) Reference for details about the schema.
A generated JSON-based script for a tabular model might look like the following:
{
"create": {
"database": {
"name": "AdventureWorksTabular1200",
"id": "AdventureWorksTabular1200",
"compatibilityLevel": 1200,
"readWriteMode": "readWrite",
"model": {}
}
}
}
The payload is a JSON document that can be as minimal as the example shown above, or highly embellished with the full set of object definitions. Tabular Model Scripting Language (TMSL) Reference describes the syntax.
At the database level, CREATE, ALTER, and DELETE commands will output TMSL script in the familiar XMLA window. Other commands, such as Process, can also be scripted in this release. Script support for many other actions may be added in a future release.
| Scriptable commands | Description |
|---|---|
| create | Adds a database, connection, or partition. The ASSL equivalent is CREATE. |
| createOrReplace | Updates an existing object definition (database, connection, or partition) by overwriting a previous version. The ASSL equivalent is ALTER with AllowOverwrite set to true and ObjectDefinition to ExpandFull. |
| delete | Removes an object definition. ASSL equivalent is DELETE. |
| refresh | Processes the object. ASSL equivalent is PROCESS. |
DAX
Improved DAX formula editing
Updates to the formula bar help you write formulas with more ease by differentiating functions, fields and measures using syntax coloring, it provides intelligent function and field suggestions and tells you if parts of your DAX expression are wrong using error squiggles. It also allows you to use multiple lines (Alt + Enter) and indentation (Tab). The formula bar now also allows you to write comments as part of your measures, just type "//" and everything after these characters on the same line will be considered a comment.
DAX variables
This release now includes support for variables in DAX. Variables can now store the result of an expression as a named variable, which can then be passed as an argument to other measure expressions. Once resultant values have been calculated for a variable expression, those values do not change, even if the variable is referenced in another expression. For more information, see VAR Function.
New DAX functions
With this release, DAX introduces over fifty new functions to support faster calculations and enhanced visualizations in Power BI. To learn more, see New DAX Functions.
Save incomplete measures
You can now save incomplete DAX measures directly in a tabular 1200 model project and pick it up again when you are ready to continue.
Additional DAX enhancements
- Non empty calculation - Reduces the number of scans needed for non empty.
- Measure Fusion - Multiple measures from the same table will be combined into a single storage engine - query.
- Grouping sets - When a query asks for measures at multiple granularities (Total/Year/Month), a single - query is sent at the lowest level and the rest of the granularities are derived from the lowest level.
- Redundant join elimination - A single query to the storage engine returns both the dimension columns and the measure values.
- Strict evaluation of IF/SWITCH - A branch whose condition is false will no longer result in storage engine queries. Previously, branches were eagerly evaluated but results discarded later on.
Developer
Microsoft.AnalysisServices.Tabular namespace for Tabular 1200 programmability in AMO
Analysis Services Management Objects (AMO) is updated to include a new tabular namespace for managing a Tabular Mode instance of SQL Server 2016 Analysis Services, as well as provide the data definition language for creating or modifying tabular 1200 models programmatically. Visit Microsoft.AnalysisServices.Tabular to read up on the API.
Analysis Services Management Objects (AMO) updates
Analysis Services Management Objects (AMO) has been re-factored to include a second assembly, Microsoft.AnalysisServices.Core.dll. The new assembly separates out common classes like Server, Database, and Role that have broad application in Analysis Services, irrespective of server mode. Previously, these classes were part of the original Microsoft.AnalysisServices assembly. Moving them to a new assembly paves the way for future extensions to AMO, with clear division between generic and context-specific APIs. Existing applications are unaffected by the new assemblies. However, should you choose to rebuild applications using the new AMO assembly for any reason, be sure to add a reference to Microsoft.AnalysisServices.Core. Similarly, PowerShell scripts that load and call into AMO must now load Microsoft.AnalysisServices.Core.dll. Be sure to update any scripts.
JSON editor for BIM files
Code View in Visual Studio 2015 now renders the BIM file in JSON format for tabular 1200 models. The version of Visual Studio determines whether the BIM file is rendered in JSON via the built-in JSON Editor, or as simple text.
To use the JSON editor, with the ability to expand and collapse sections of the model, you will need the latest version of SQL Server Data Tools plus Visual Studio 2015 (any edition, including the free Community edition). For all other versions of SSDT or Visual Studio, the BIM file is rendered in JSON as simple text. At a minimum, an empty model will contain the following JSON:
{
"name": "SemanticModel",
"id": "SemanticModel",
"compatibilityLevel": 1200,
"readWriteMode": "readWrite",
"model": {}
}
Warning
Avoid editing the JSON directly. Doing so can corrupt the model.
New elements in MS-CSDLBI 2.0 schema
The following elements have been added to the TProperty complex type defined in the [MS-CSDLBI] 2.0 schema:
| Element | Definition |
|---|---|
| DefaultValue | A property that specifies the value used when evaluating the query. The DefaultValue property is optional, but it is automatically selected if the values from the member cannot be aggregated. |
| Statistics | A set of statistics from the underlying data that is associated with the column. These statistics are defined by the TPropertyStatistics complex type and are provided only if they are not computationally expensive to generate, as described in section 2.1.13.5 of the Conceptual Schema Definition File Format with Business Intelligence Annotations document. |
DirectQuery
New DirectQuery implementation
This release sees significant enhancements in DirectQuery for tabular 1200 models. Here's a summary:
- DirectQuery now generates simpler queries that provide better performance.
- Extra control over defining sample datasets used for model design and testing.
- Row level security (RLS) is now supported for tabular 1200 models in DirectQuery mode. Previously, the presence of RLS prevented deploying a tabular model in DirectQuery mode.
- Calculated columns are now supported for tabular 1200 models in DirectQuery mode. Previously, the presence of calculated columns prevented deploying a tabular model in DirectQuery mode.
- Performance optimizations include redundant join elimination for VertiPaq and DirectQuery.
New data sources for DirectQuery mode
Data sources supported for tabular 1200 models in DirectQuery mode now include Oracle, Teradata and Microsoft Analytics Platform (formerly known as Parallel Data Warehouse). To learn more, see DirectQuery Mode.
Deprecated features in SSAS 2016
The following features are deprecated in this release:
| Mode/Category | Feature |
|---|---|
| Multidimensional | Remote partitions |
| Multidimensional | Remote linked measure groups |
| Multidimensional | Dimensional writeback |
| Multidimensional | Linked dimensions |
| Multidimensional | SQL Server table notifications for proactive caching. The replacement is to use polling for proactive caching. See Proactive Caching (Dimensions) and Proactive Caching (Partitions). |
| Multidimensional | Session cubes. There is no replacement. |
| Multidimensional | Local cubes. There is no replacement. |
| Tabular | Tabular model 1100 and 1103 compatibility levels will not be supported in a future release. The replacement is to set models at compatibility level 1200 or higher, converting model definitions to tabular metadata. See Compatibility Level for Tabular models in Analysis Services. |
| Tools | SQL Server Profiler for Trace Capture The replacement is to use Extended Events Profiler embedded in SQL Server Management Studio. See Monitor Analysis Services with SQL Server Extended Events. |
| Tools | Server Profiler for Trace Replay Replacement. There is no replacement. |
| Trace Management Objects and Trace APIs | Microsoft.AnalysisServices.Trace objects (contains the APIs for Analysis Services Trace and Replay objects). The replacement is multi-part: - Trace Configuration: Microsoft.SqlServer.Management.XEvent - Trace Reading: Microsoft.SqlServer.XEvent.Linq - Trace Replay: None |
Discontinued features in SSAS 2016
The following features are discontinued in this release:
| Feature | Replacement or workaround |
|---|---|
| CalculationPassValue (MDX) | None. This feature was deprecated in SQL Server 2005. |
| CalculationCurrentPass (MDX) | None. This feature was deprecated in SQL Server 2005. |
| NON_EMPTY_BEHAVIOR query optimizer hint | None. This feature was deprecated in SQL Server 2008. |
| COM assemblies | None. This feature was deprecated in SQL Server 2008. |
| CELL_EVALUATION_LIST intrinsic cell property | None. This feature was deprecated in SQL Server 2005. |
Breaking changes in SSAS 2016
.NET 4.0 version upgrade
Analysis Services Management Objects (AMO), ADOMD.NET, and Tabular Object Model (TOM) client libraries now target the .NET 4.0 runtime. This can be a breaking change for applications that target .NET 3.5. Applications using newer versions of these assemblies must now target .NET 4.0 or later.
AMO version upgrade
This release is a version upgrade for Analysis Services Management Objects (AMO) and is a breaking change under certain circumstances. Existing code and scripts that call into AMO will continue to run as before if you upgrade from a previous version. However, if you need to recompile your application and you are targeting a SQL Server 2016 Analysis Services instance, you must add the following namespace to make your code or script operational:
using Microsoft.AnalysisServices;
using Microsoft.AnalysisServices.Core;
The Microsoft.AnalysisServices.Core namespace is now required whenever you reference the Microsoft.AnalysisServices assembly in your code. Objects that were previously only in the Microsoft.AnalysisServices namespace are moved to the Core namespace in this release if the object is used the same way in both tabular and multidimensional scenarios. For example, server-related APIs are relocated to the Core namespace.
Although there are now multiple namespaces, both exist in the same assembly (Microsoft.AnalysisServices.dll).
XEvent DISCOVER changes
To better support XEvent DISCOVER streaming in SSMS for SQL Server 2016 Analysis Services, DISCOVER_XEVENT_TRACE_DEFINITION is replaced with the following XEvent traces:
DISCOVER_XEVENT_PACKAGES
DISCOVER_XEVENT_OBJECT
DISCOVER_XEVENT_OBJECT_COLUMNS
DISCOVER_XEVENT_SESSION_TARGETS
Behavior changes in SSAS 2016
Analysis Services in SharePoint mode
Running the Power Pivot Configuration wizard is no longer required as a post-installation task. This is true for all supported versions of SharePoint that load models from the current SQL Server 2016 Analysis Services.
DirectQuery mode for Tabular models
DirectQuery is a data access mode for tabular models, where query execution is performed on a backend relational database, retrieving a result set in real time. It's often used for very large datasets that cannot fit in memory or when data is volatile and you want the most recent data returned in queries against a tabular model.
DirectQuery has existed as a data access mode for the last several releases. In SQL Server 2016 Analysis Services, the implementation has been slightly revised, assuming the tabular model is at compatibility level 1200 or higher. DirectQuery has fewer restrictions than before. It also has different database properties.
If you are using DirectQuery in an existing tabular model, you can keep the model at its currently compatibility level of 1100 or 1103 and continue to use DirectQuery as its implemented for those levels. Alternatively, you can upgrade to 1200 or higher to benefit from enhancements made to DirectQuery.
There is no in-place upgrade of a DirectQuery model because the settings from older compatibility levels do not have exact counterparts in the newer 1200 and higher compatibility levels. If you have an existing tabular model that runs in DirectQuery mode, you should open the model in SQL Server Data Tools, turn DirectQuery off, set the Compatibility Level property to 1200 or higher, and then reconfigure the DirectQuery properties. See DirectQuery Mode for details.
Definitions
A deprecated feature will be discontinued from the product in a future release, but is still supported and included in the current release to maintain backward compatibility. It's recommended you discontinue using deprecated features in new and existing projects to maintain compatibility with future releases. Documentation is not updated for deprecated features.
A discontinued feature was deprecated in an earlier release. It may continue to be included in the current release, but is no longer supported. Discontinued features may be removed entirely in the stated or future release.
A breaking change causes a feature, data model, application code, or script to no longer function after upgrading to the current release.
A behavior change affects how the same feature works in the current release as compared to the previous release. Only significant behavior changes are described. Changes in user interface are not included. Changes to default values, manual configuration required to complete an upgrade or restore functionality, or a new implementation of an existing feature are all examples of a behavior change.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for