Developer technologies | Transact-SQL
A Microsoft extension to the ANSI SQL language that includes procedural programming, local variables, and various support functions.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAC%3C/text%3E%3C/svg%3E)
Hi,
ref. my Ms SQL script.
If(OBJECT_ID('tempdb..#StudProfileReviewer') Is Not Null)
Begin
Drop Table #StudProfileReviewer
End
create table #StudProfileReviewer
(
StudID [INT],
StudName Varchar(50),
StudProfileRemarks Varchar(Max),
RemarksDate DatetIme,
RemarksSplit_NameMistakes Varchar(100),
RemarksSplit_MobilePhoneMistakes Varchar(100),
RemarksSplit_DOBMistakes Varchar(100),
RemarksSplit_AddressMistakes Varchar(100),
RemarksSplit_OtherMistakes Varchar(100),
RemarksCount INT
)
Insert into [#StudProfileReviewer] (StudID,StudName,StudProfileRemarks,RemarksDate) Values(1001,'SriRaman','Mobile Phone No length mistake | AddressMistake', '2022/05/03')
Insert into [#StudProfileReviewer] (StudID,StudName,StudProfileRemarks,RemarksDate) Values(1007,'Janani','NameMistake | Mobile Phone No length mistake | AddressMistake', '2022/06/12')
Insert into [#StudProfileReviewer] (StudID,StudName,StudProfileRemarks,RemarksDate) Values(1003,'Guru','DOB Mistake | Pincode Wrong ', '2022/03/11')
Insert into [#StudProfileReviewer] (StudID,StudName,StudProfileRemarks,RemarksDate) Values(1002,'Sankaran','Vehile Reg. No is Wrong ', '2022/03/11')
Insert into [#StudProfileReviewer] (StudID,StudName,StudProfileRemarks,RemarksDate) Values(1004,'Zaheer','', '2021/01/08')
Select * from [#StudProfileReviewer]
Expected Result:

' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYK%3C/text%3E%3C/svg%3E)
While asking a question you need to provide a minimal reproducible example:
(1) DDL and sample data population, i.e. CREATE table(s) plus INSERT, T-SQL statements.
(2) What you need to do, i.e. logic, and your attempt implementation of it in T-SQL.
(3) Desired output based on the sample data in the #1 above.
(4) Your SQL Server version (SELECT @@version;)

You have intended structered data stored and this in an unstructured and in a messed way; now you expect to get it in a clean pivot way?
Please check it out my second answer.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBZ%3C/text%3E%3C/svg%3E)
Please try this,the code based on lijingyang:
;
with mycte as
(
select StudID,StudName,StudProfileRemarks, RemarksDate,trim(value) StudProfileRemark
FROM [#StudProfileReviewer]
cross apply openjson('["'+(replace(StudProfileRemarks,'|','","')+'"]'))
),mycte1 AS
(
select StudID,StudName,StudProfileRemarks, RemarksDate, StudProfileRemark,S.a.value('(/H/r)[1]', 'VARCHAR(100)') AS Remarksplit_item1
,S.a.value('(/H/r)[2]', 'VARCHAR(100)') AS Remarksplit_item2,S.a.value('(/H/r)[3]', 'VARCHAR(100)') AS Remarksplit_item3
FROM
(
SELECT *,CAST (N'<H><r>' + REPLACE(StudProfileRemarks, '|', '</r><r>') + '</r></H>' AS XML) AS [vals]
FROM mycte
) d
CROSS APPLY d.[vals].nodes('/H/r') S(a)
)
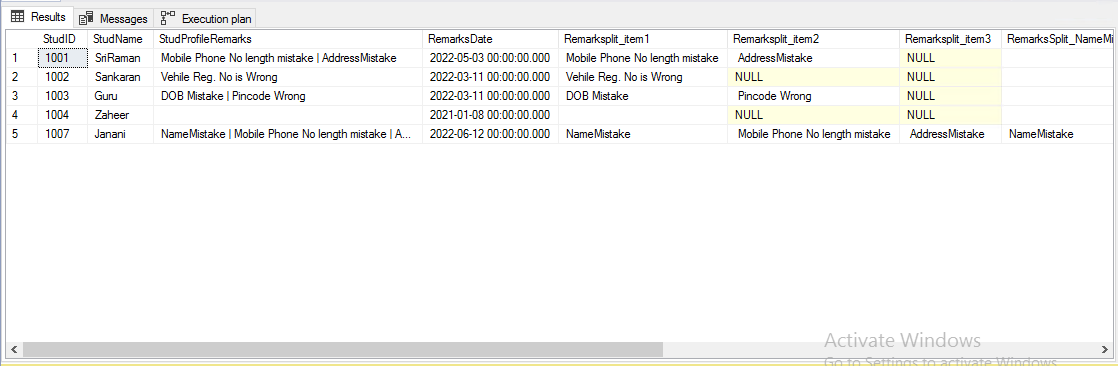
Select StudID, StudName, StudProfileRemarks, RemarksDate ,
Remarksplit_item1,Remarksplit_item2,Remarksplit_item3,
Max(Case when StudProfileRemark = 'NameMistake' then 'NameMistake' else '' end) RemarksSplit_NameMistakes
,Max(Case when StudProfileRemark = 'Mobile Phone No length mistake' then 'Mobile Phone No length mistake' else '' end) RemarksSplit_MobilePhoneMistakes
,Max(Case when StudProfileRemark = 'DOB Mistake' then 'DOB Mistake' else '' end) RemarksSplit_DOBMistakes
,Max(Case when StudProfileRemark = 'AddressMistake' then 'AddressMistake' else '' end) RemarksSplit_AddressMistakes
,Max(Case
when StudProfileRemark <> 'NameMistake'
and StudProfileRemark <> 'Mobile Phone No length mistake'
and StudProfileRemark <> 'DOB Mistake'
and StudProfileRemark <> 'AddressMistake'
and StudProfileRemark <>''
then StudProfileRemark else '' end) RemarksSplit_OtherMistakes
, Max(Case when StudProfileRemark = 'NameMistake' then 1 else 0 end)
+ Max(Case when StudProfileRemark = 'Mobile Phone No length mistake' then 1 else 0 end)
+ Max(Case when StudProfileRemark = 'DOB Mistake' then 1 else 0 end)
+ Max(Case when StudProfileRemark = 'AddressMistake' then 1 else 0 end)
+ Max(Case
when StudProfileRemark <> 'NameMistake'
and StudProfileRemark <> 'Mobile Phone No length mistake'
and StudProfileRemark <> 'DOB Mistake'
and StudProfileRemark <> 'AddressMistake'
and StudProfileRemark <>''
then 1 else 0 end) cnt
from mycte1 t
Group by StudID, StudName, StudProfileRemarks, RemarksDate ,Remarksplit_item1,Remarksplit_item2,Remarksplit_item3
Bert Zhou
Hi @Ayyappan CNN ,
Please try the following solution.
It is very easy to produce your second sequential output.
SQL
-- DDL and sample data population, start
DECLARE @tbl TABLE
(
StudID INT PRIMARY KEY,
StudName VARCHAR(50),
StudProfileRemarks VARCHAR(MAX),
RemarksDate DATE
);
INSERT @tbl (StudID,StudName,StudProfileRemarks,RemarksDate) VALUES
(1001,'SriRaman','Mobile Phone No length mistake | AddressMistake', '2022-05-03'),
(1007,'Janani','NameMistake | Mobile Phone No length mistake | AddressMistake', '2022-06-12'),
(1003,'Guru','DOB Mistake | Pincode Wrong ', '2022-03-11'),
(1002,'Sankaran','Vehile Reg. No is Wrong ', '2022-03-11'),
(1004,'Zaheer','', '2021-01-08');
-- DDL and sample data population, end
DECLARE @separator CHAR(3) = ' | ';
SELECT t.* --, c
, Remarksplit_item1 = COALESCE(c.value('(/root/r[1]/text())[1]', 'VARCHAR(100)'),'')
, Remarksplit_item2 = COALESCE(c.value('(/root/r[2]/text())[1]', 'VARCHAR(100)'),'')
, Remarksplit_item3 = COALESCE(c.value('(/root/r[3]/text())[1]', 'VARCHAR(100)'),'')
, Remarksplit_item4 = COALESCE(c.value('(/root/r[4]/text())[1]', 'VARCHAR(100)'),'')
, RemarksCount = c.value('count(/root/r[text()])', 'INT')
FROM @tbl AS t
CROSS APPLY (SELECT TRY_CAST('<root><r>' +
REPLACE(StudProfileRemarks, @separator, '</r><r>') +
'</r></root>' AS XML)) AS t2(c)
ORDER BY StudID;
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJL%3C/text%3E%3C/svg%3E)
Access Denied
You don't have permission to access "http://learn.microsoft.com/answers/answers/954960/post.html" on this server.
Reference #18.5cbc7768.1659716063.104c53f3