Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
A data lake is a storage repository that holds a large amount of data in its native, raw format. Data lake stores are designed to scale cost-effectively to terabytes and petabytes data, making them suitable for handling massive and diverse datasets. The data typically comes from multiple diverse sources and can include structured data (like relational tables), semi-structured data (like JSON, XML, or logs), and unstructured data (like images, audio, or video).
A data lake helps you store everything in its original, untransformed state, deferring transformation until the data is needed. This is a concept known as schema-on-read. This contrasts with a data warehouse, which enforces structure and applies transformations as data is ingested, known as schema-on-write.
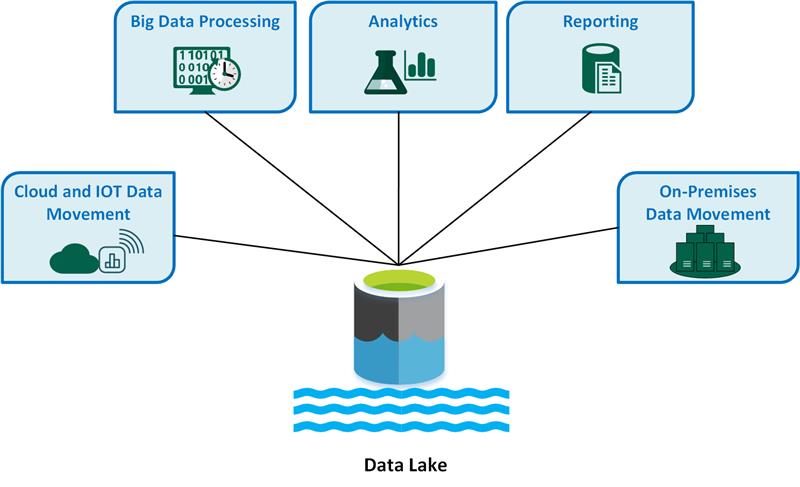
Common data lake use cases include:
- Data ingestion and movement: Collect and consolidate data from cloud services, IoT devices, on-premises systems, and streaming sources into a single repository.
- Big data processing: Handle high-volume, high-velocity data at scale using distributed processing frameworks.
- Analytics and machine learning: Support exploratory analysis, advanced analytics, and AI model training and fine-tuning on large, diverse datasets.
- Business intelligence and reporting: Enable dashboards and reports by integrating curated subsets of lake data into warehouses or BI tools.
- Data archiving and compliance: Store historical or raw datasets for long-term retention, auditability, and regulatory needs.
Advantages of a data lake
- Retains raw data for future use: A data lake is designed to retain data in its raw format, ensuring long-term availability for future use. This capability is particularly valuable in a big data environment, where the potential insights from the data might not be known in advance. Data can also be archived as needed without losing its raw state.
- Self-service exploration: Analysts and data scientists can query data directly, encouraging experimentation and discovery.
- Flexible data support: Unlike warehouses that require structured formats, lakes can natively handle structured, semi-structured, and unstructured data.
- Scalable and performant: In distributed architectures, data lakes enable parallel ingestion and distributed execution at scale, frequently outperforming traditional ETL pipelines in high-volume workloads. The performance benefits stem from:
- Parallelism: Distributed compute engines (e.g., Spark) partition data and execute transformations across multiple nodes concurrently, while traditional ETL frameworks often rely on sequential or limited multi-threaded execution.
- Scalability: Distributed systems scale horizontally by elastically adding compute and storage nodes, whereas traditional ETL pipelines typically depend on vertical scaling of a single host, which quickly hits resource limits.
- Foundation for hybrid architectures: Data lakes often coexist with warehouses in a lakehouse approach, combining raw storage with structured query performance.
A modern data lake solution comprises two core elements:
- Storage: Built for durability, fault tolerance, infinite scalability, and high-throughput ingestion of diverse data types.
- Processing: Powered by engines such as Apache Spark in Azure Databricks, Microsoft Fabric, enabling large-scale transformations, analytics, and machine learning.
Additionally, mature solutions incorporate metadata management, security, and governance to ensure data quality, discoverability, and compliance.
When you should use a data lake
We recommend using a data lake for exploratory analytics, advanced data science, and machine learning workloads. Because lakes retain data in its raw state and support schema-on-read, they allow teams to experiment with diverse data types and uncover insights that traditional warehouses might not capture.
Data lake as a source for data warehouses
A data lake can act as the upstream source for a data warehouse, where raw data is ingested from source systems into the lake (Extract and Load), and modern warehouses like the Fabric Warehouse use built-in Massively Parallel Processing (MPP) SQL engines to handle transformations, converting the raw data into a structured format extract, load, transform (ELT). This differs from traditional ETL pipelines, where data is both extracted and transformed within the ETL engine before being loaded into the warehouse. Both approaches provide flexibility depending on the use case, balancing factors such as data quality, performance, and resource utilization while ensuring the warehouse is optimized for analytics.
Event streaming and IoT scenarios
Data lakes are effective for event streaming and IoT use cases, where high-velocity data must be persisted at scale without upfront schema constraints. They can ingest and store both relational and non-relational event streams, handle high volumes of small writes with low latency, and support massive parallel throughput. This makes them well suited for applications such as real-time monitoring, predictive maintenance, and anomaly detection.
The following table compares data lakes and data warehouses.
| Feature | Data Lake | Data Warehouse |
|---|---|---|
| Data type | Raw, unstructured, semi-structured, and structured | Structured and highly organized |
| Query performance | Slower, especially for complex queries; depends on data format and tools | Fast and optimized for analytical queries |
| Latency | Higher latency due to on-the-fly processing | Low latency with pre-processed, structured data |
| Data transformation stage | Transformation happens at query time, affecting overall processing time | Transformation happens during the ETL or ELT process |
| Scalability | Highly scalable and cost-effective for large volumes of diverse data | Scalable but more expensive, especially at large scale |
| Cost | Lower storage costs; compute costs vary based on usage | Higher storage and compute costs due to performance optimizations |
| Use case fit | Best for big data, machine learning, and exploratory analytics. In medallion architectures, the Gold layer is leveraged for reporting purposes | Ideal for business intelligence, reporting, and structured data analysis |
Challenges of data lakes
Scalability and complexity: Managing petabytes of raw, unstructured, and semi-structured data requires robust infrastructure, distributed processing, and careful cost management.
Processing bottlenecks: As data volume and diversity increase, transformation and query workloads can introduce latency, requiring careful pipeline design and workload orchestration.
Data integrity risks: Without strong validation and monitoring, errors or incomplete ingestions can compromise the reliability of the lake's contents.
Data quality and governance: The variety of sources and formats makes it difficult to enforce consistent standards. Implementing metadata management, cataloging, and governance frameworks is critical.
Performance at scale: Query performance and storage efficiency can degrade as the lake grows, requiring optimization strategies such as partitioning, indexing, and caching.
Security and access control: Ensuring appropriate permissions and auditing across diverse datasets to prevent misuse of sensitive data requires planning.
Discoverability: Without proper cataloging, lakes can devolve into "data swamps" where valuable information is present but inaccessible or misunderstood.
Technology choices
When you build a comprehensive data lake solution on Azure, consider the following technologies:
Azure Data Lake Storage combines Azure Blob Storage with data lake capabilities, which provides Apache Hadoop-compatible access, hierarchical namespace capabilities, and enhanced security for efficient big data analytics. It's designed to handle massive amounts of structured, semi-structured, and unstructured data.
Azure Databricks is a cloud-based data analytics and machine learning platform that combines the best of Apache Spark with deep integration into the Microsoft Azure ecosystem. It provides a collaborative environment where data engineers, data scientists, and analysts can work together to ingest, process, analyze, and model large volumes of data.
Azure Data Factory is a Microsoft Azure's cloud-based data integration and ETL (Extract, Transform, Load) service. You use it to move, transform, and orchestrate data workflows across different sources, whether in the cloud or on-premises.
Microsoft Fabric is Microsoft's end-to-end data analytics platform that unifies data movement, data science, real-time analytics, and business intelligence into a single software-as-a-service (SaaS) experience.
Each Microsoft Fabric tenant is automatically provisioned with a single logical data lake, known as OneLake. Built on Azure Data Lake Storage (ADLS) Gen2, OneLake provides a unified storage layer capable of handling both structured and unstructured data formats.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
- Avijit Prasad | Cloud Consultant
Contributors:
- Raphael Sayegh | Cloud Solution Architect
To see non-public LinkedIn profiles, sign in to LinkedIn.
Next steps
- What is OneLake?
- Introduction to Data Lake Storage
- Azure Data Lake Analytics documentation
- Training: Introduction to Data Lake Storage
- Integration of Hadoop and Azure Data Lake Storage
- Connect to Data Lake Storage and Blob Storage
- Load data into Data Lake Storage with Azure Data Factory