Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
OneLake is a single, unified, logical data lake for your whole organization. Like OneDrive, OneLake comes automatically with every Microsoft Fabric tenant and is designed to be the single place for all your analytics data.
OneLake brings customers:
- One data lake for the entire organization
- One copy of data for use with multiple analytical engines
- Built-in data protection with automatic soft delete and disaster recovery options
One data lake for the entire organization
Before OneLake, many organizations created multiple lakes for different business groups, which led to extra overhead for managing multiple resources. OneLake removes these challenges by improving collaboration:
- Every Fabric tenant automatically gets one OneLake
- You can't create multiple OneLakes or delete your OneLake
- No extra resources to provision or manage
This simplicity helps your organization collaborate on a single, unified data lake.
Governed by default with distributed ownership for collaboration
The top level of organization and governance for Fabric data is the tenant. Any data that lands in OneLake is automatically protected by tenant-level policies for security, compliance, and data management.
Within a tenant, collaboration happens within workspaces. You can create any number of workspaces to organize your data. Workspaces enable different parts of the organization to distribute ownership and access policies. Each workspace is part of a capacity that's tied to a specific region and billed separately.
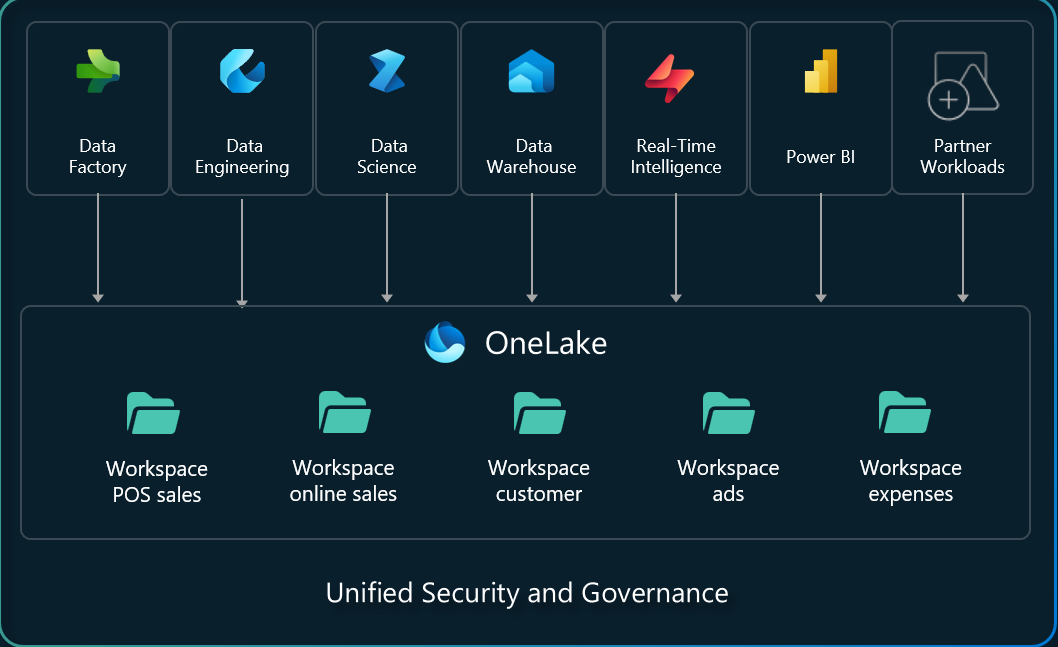
Within a workspace, you create and access all data through data items. Similar to how Office stores Word, Excel, and PowerPoint files in OneDrive, Fabric stores lakehouses, warehouses, and other items in OneLake. Each item type provides tailored experiences for different personas, such as the Apache Spark developer experience in a lakehouse.
Built on open standards and formats
OneLake is built on top of Azure Data Lake Storage (ADLS) Gen2 and can support any type of file, structured or unstructured. All Fabric data items like data warehouses and lakehouses store their data automatically in OneLake in Delta Parquet format. If a data engineer loads data into a lakehouse using Apache Spark, and then a SQL developer uses T-SQL to load data in a fully transactional data warehouse, both are contributing to the same data lake. OneLake stores all tabular data in Delta Parquet format.
OneLake supports the same ADLS Gen2 APIs and SDKs to be compatible with existing ADLS Gen2 applications, including Azure Databricks. You can address data in OneLake as if it's one big ADLS storage account for the entire organization. Every workspace appears as a container within that storage account, and different data items appear as folders within those containers.

For more information on APIs and endpoints, see OneLake access and APIs.
For examples of OneLake integrations with Azure, see:
- Azure Synapse Analytics
- Azure storage explorer
- Azure Databricks
- Use OneLake files in Microsoft Foundry
OneLake file explorer for Windows
You can explore OneLake data from Windows using the OneLake file explorer for Windows. You can navigate all your workspaces and data items, easily uploading, downloading, or modifying files just like you do in Office. The OneLake file explorer simplifies working with data lakes, allowing even nontechnical business users to use them.
For more information, see OneLake file explorer.
One copy of data
OneLake aims to give you the most value possible from a single copy of data without data movement or duplication. You don't need to copy data just to use it with another engine or to analyze data from multiple sources.
Shortcuts connect data across domains without data movement
A shortcut is a reference to data stored in other file locations. These file locations can be within the same workspace or across different workspaces, within OneLake or external to OneLake like ADLS, S3, or Dataverse. No matter the location, shortcuts make files and folders look like you have them stored locally.
Shortcuts allow your organization to share data between users and applications without having to move and duplicate information unnecessarily. When teams work independently in separate workspaces, shortcuts enable you to combine data across different business groups and domains into a virtual data product to fit a user’s specific needs.

For more information on how to use shortcuts, see OneLake shortcuts.
Connect data to multiple analytical engines
Data is often optimized for a single engine, which makes it difficult to reuse the same data for multiple applications. With Fabric, the different analytical engines (T-SQL, Apache Spark, Analysis Services, and others) store data in the open Delta Parquet format to allow you to use the same data across multiple engines.
You don't need to copy data just to use it with another engine or feel stuck with using a particular engine because that's where your data is. For example, imagine a team of SQL engineers building a fully transactional data warehouse. They can use the T-SQL engine and all the power of T-SQL to create tables, transform data, and load the data to tables. If a data scientist wants to make use of this data, they don't need to go through a special Spark/SQL driver. OneLake stores all data in Delta Parquet format. The data scientist can use the full power of the Spark engine and its open-source libraries directly over the data.
Business users can build Power BI reports directly on top of OneLake using the Direct Lake mode in the Analysis Services engine. The Analysis Services engine powers Power BI semantic models, and it has always offered two modes of accessing data: import and direct query. This third mode, Direct Lake mode, gives users all the speed of import without needing to copy the data, combining the best of import and direct query. For more information, see Direct Lake.

Built-in data protection
OneLake automatically protects your data with built-in features that help you recover from accidental deletions and prepare for regional outages.
Soft delete for file recovery
When you delete files in OneLake, they aren't immediately removed. OneLake retains deleted files for seven days, giving you time to recover from accidental deletions or user errors. You can restore soft-deleted files using Azure Storage Explorer or PowerShell.
For step-by-step instructions, see Recover deleted files in OneLake.
Disaster recovery
OneLake uses zone-redundant storage (ZRS) where available to protect against datacenter failures. You can also enable business continuity and disaster recovery (BCDR) for a capacity to replicate your data to a secondary geographic region.
For more information, see Plan for disaster recovery and data protection.
Next steps
Ready to start using OneLake? Here's how to get started: