Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Business continuity and disaster recovery in Azure Data Explorer enables your business to continue operating in the face of a disruption. This article details multiple disaster recovery configurations depending on recoverability requirements (RPO and RTO), needed effort, and cost.
For more information about the reliability options available for Azure Data Explorer, including availabilitry zone support, backup, and protection against some types of human error, see Reliability in Azure Data Explorer.
Disaster recovery configurations
Recovery time objective (RTO) refers to the time to recover from a disruption. For example, RTO of 2 hours means the application has to be up and running within two hours of a disruption. Recovery point objective (RPO) refers to the interval of time that might pass during a disruption before the quantity of data lost during that period is greater than the allowable threshold. For example, if the RPO is 24 hours, and an application has data beginning from 15 years ago, they're still within the parameters of the agreed-upon RPO.
Ingestion, processing, and curation processes need diligent design upfront when planning for disaster recovery. Ingestion refers to data integrated into Azure Data Explorer from various sources; processing refers to transformations and similar activities; curation refers to materialized views, exports to the data lake, and so on.
The following are popular disaster recovery configurations:
- Active-Active-Active (always-on) configuration
- Active-Active configuration
- Active-Hot standby configuration
- On-demand data recovery cluster configuration
Active-active-active configuration
This configuration is also called always-on. For critical application deployments with no tolerance for outages, you should use multiple Azure Data Explorer clusters across Azure paired regions. Set up ingestion, processing, and curation in parallel to all of the clusters. The cluster SKU must be the same across regions. Azure ensures that updates are rolled out and staggered across Azure paired regions. An Azure region outage doesn't cause an application outage. You might experience some latency or performance degradation.
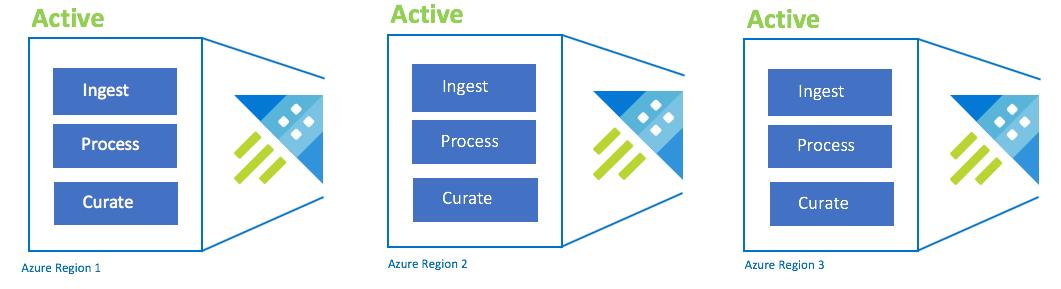
| Configuration | RPO | RTO | Effort | Cost |
|---|---|---|---|---|
| Active-Active-Active-n | 0 hours | 0 hours | Lower | Highest |
Active-Active configuration
This configuration is identical to the active-active-active configuration, but only involves two Azure paired regions. Configure dual ingestion, processing, and curation. Users are routed to the nearest region. The cluster SKU must be the same across regions.
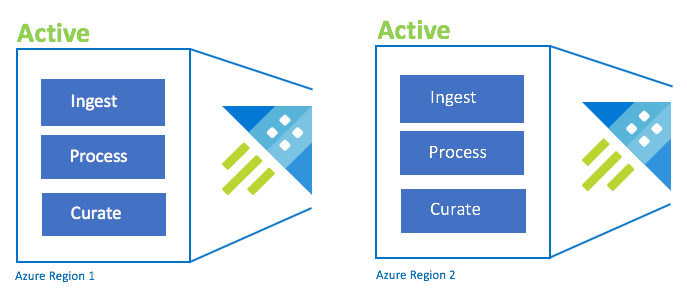
| Configuration | RPO | RTO | Effort | Cost |
|---|---|---|---|---|
| Active-Active | 0 hours | 0 hours | Lower | High |
Active-Hot standby configuration
The Active-Hot configuration is similar to the Active-Active configuration in dual ingest, processing, and curation. While the standby cluster is online for ingestion, process, and curation, it isn't available to query. The standby cluster doesn't need to be in the same SKU as the primary cluster. It can be of a smaller SKU and scale, which might result in it being less performant. In a disaster scenario, users are redirected to the standby cluster, which can optionally be scaled up to increase performance.
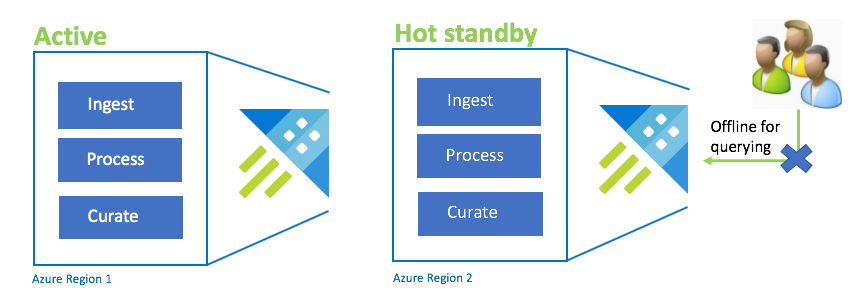
| Configuration | RPO | RTO | Effort | Cost |
|---|---|---|---|---|
| Active-Hot Standby | 0 hours | Low | Medium | Medium |
On-demand data recovery configuration
This solution offers the least recoverability (highest RPO and RTO), is the lowest in cost and highest in effort. In this configuration, there's no data recovery cluster. Configure continuous export of curated data (unless raw and intermediate data is also required) to a storage account that is configured GRS (Geo Redundant Storage). A data recovery cluster is spun up if there's a disaster recovery scenario. At that time, DDLs, configuration, policies, and processes are applied. Data is ingested from storage with the ingestion property kustoCreationTime to override the ingestion time that defaults to system time.
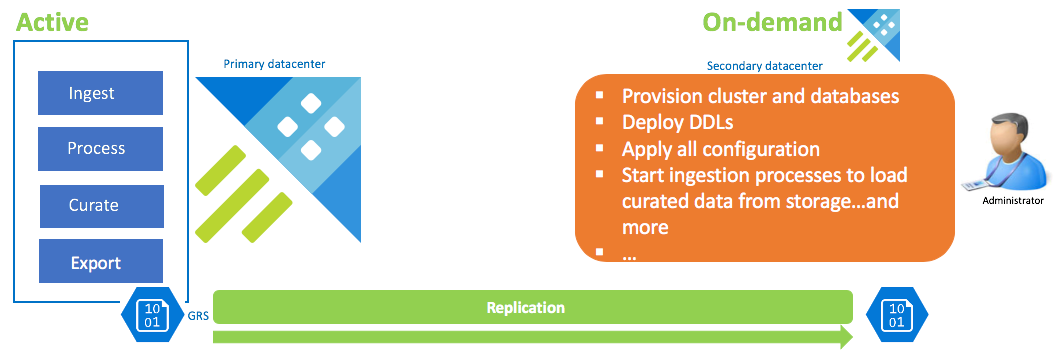
| Configuration | RPO | RTO | Effort | Cost |
|---|---|---|---|---|
| On-demand data recovery cluster | Highest | Highest | Highest | Lowest |
Summary of disaster recovery configuration options
| Configuration | Recoverability | RPO | RTO | Effort | Cost |
|---|---|---|---|---|---|
| Active-Active-Active-n | Highest | 0 hours | 0 hours | Lower | Highest |
| Active-Active | High | 0 hours | 0 hours | Lower | High |
| Active-Hot Standby | Medium | 0 hours | Low | Medium | Medium |
| On-demand data recovery cluster | Lowest | Highest | Highest | Highest | Lowest |
Best practices
Regardless of which disaster recovery configuration is chosen, follow these best practices:
- All database objects, policies, and configurations should be persisted in source control so they can be released to the cluster from your release automation tool. For more information, see Azure DevOps support for Azure Data Explorer.
- Design, develop, and implement validation routines to ensure all clusters are in-sync from a data perspective. Azure Data Explorer supports cross cluster joins. A simple count or rows across tables can help validate.
- Release procedures should involve governance checks and balances that ensure mirroring of the clusters.
- Be fully cognizant of what it takes to build a cluster from scratch.
- Create a checklist of deployment units. Your list is unique to your needs, but should include: deployment scripts, ingestion connections, BI tools, and other important configurations.