Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
For every source except Azure SQL Database, it's recommended that you keep Use current partitioning as the selected value. When you're reading from all other source systems, data flows automatically partitions data evenly based upon the size of the data. A new partition is created for about every 128 MB of data. As your data size increases, the number of partitions increase.
Any custom partitioning happens after Spark reads in the data and negatively affect your data flow performance. As the data is evenly partitioned on read, isn't recommended unless you understand the shape and cardinality of your data first.
Note
Read speeds can be limited by the throughput of your source system.
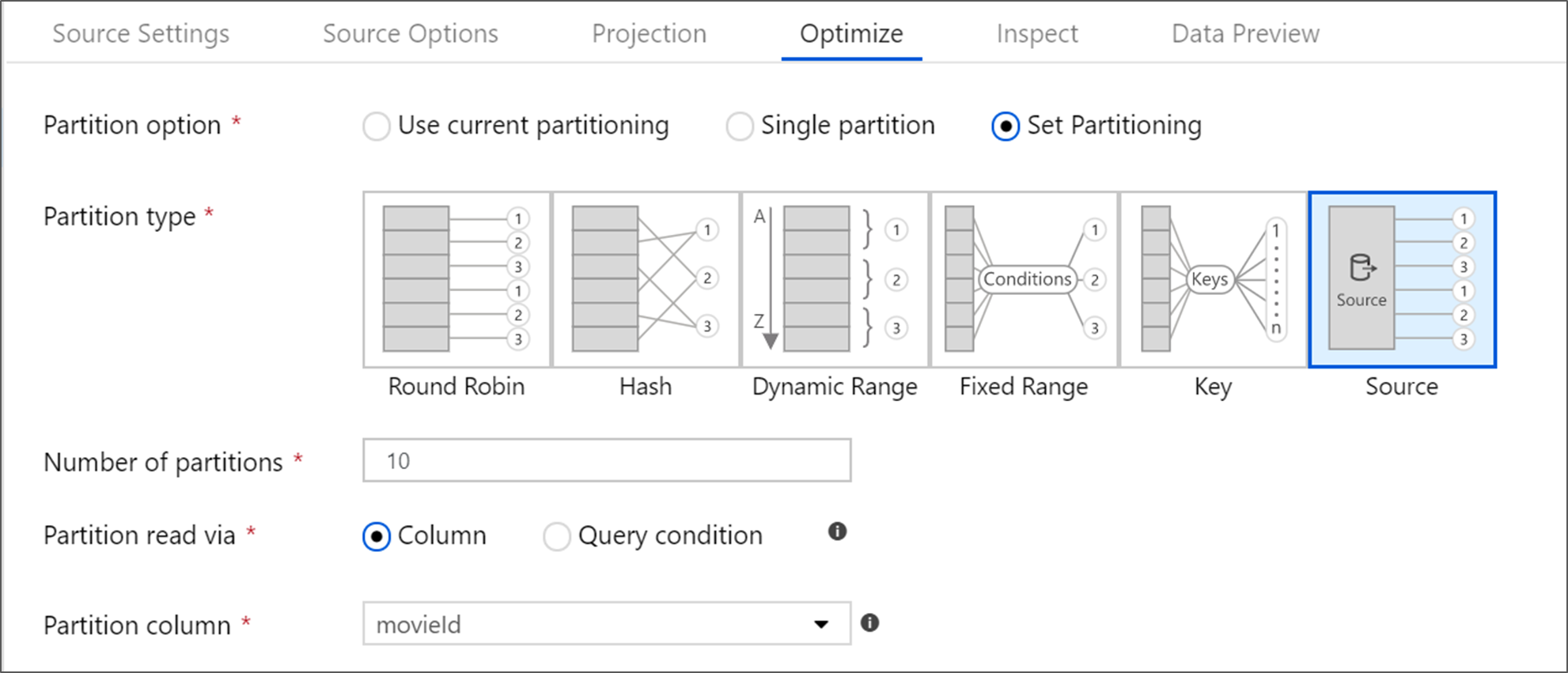
Azure SQL Database sources
Azure SQL Database has a unique partitioning option called 'Source' partitioning. Enabling source partitioning can improve your read times from Azure SQL Database by enabling parallel connections on the source system. Specify the number of partitions and how to partition your data. Use a partition column with high cardinality. You can also enter a query that matches the partitioning scheme of your source table.
Tip
For source partitioning, the I/O of the SQL Server is the bottleneck. Adding too many partitions may saturate your source database. Generally four or five partitions is ideal when using this option.
Isolation level
The isolation level of the read on an Azure SQL source system affects performance. Choosing 'Read uncommitted' provides the fastest performance and prevent any database locks. To learn more about SQL Isolation levels, see Understanding isolation levels.
Read using query
You can read from Azure SQL Database using a table or a SQL query. If you're executing a SQL query, the query must complete before transformation can start. SQL Queries can be useful to push down operations that might execute faster and reduce the amount of data read from a SQL Server such as SELECT, WHERE, and JOIN statements. When pushing down operations, you lose the ability to track lineage and performance of the transformations before the data comes into the data flow.
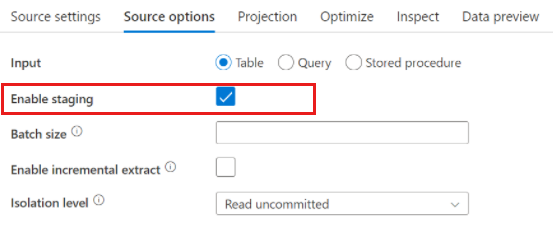
Azure Synapse Analytics sources
When using Azure Synapse Analytics, a setting called Enable staging exists in the source options. This allows the service to read from Synapse using Staging, which greatly improves read performance by using the most performant bulk loading capability such as CETAS and COPY command. Enabling Staging requires you to specify an Azure Blob Storage or Azure Data Lake Storage gen2 staging location in the data flow activity settings.
File-based sources
Parquet vs. delimited text
While data flows support various file types, the Spark-native Parquet format is recommended for optimal read and write times.
If you're running the same data flow on a set of files, we recommend reading from a folder, using wildcard paths or reading from a list of files. A single data flow activity run can process all of your files in batch. More information on how to configure these settings can be found in the Source transformation section of the Azure Blob Storage connector documentation.
If possible, avoid using the For-Each activity to run data flows over a set of files. This causes each iteration of the for-each to spin up its own Spark cluster, which is often not necessary and can be expensive.
Inline datasets vs. shared datasets
ADF and Synapse datasets are shared resources in your factories and workspaces. However, when you're reading large numbers of source folders and files with delimited text and JSON sources, you can improve the performance of data flow file discovery by setting the option "User projected schema" inside the Projection | Schema options dialog. This option turns off ADF's default schema autodiscovery and greatly improves the performance of file discovery. Before setting this option, make sure to import the projection so that ADF has an existing schema for projection. This option doesn't work with schema drift.
Related content
- Data flow performance overview
- Optimizing sinks
- Optimizing transformations
- Using data flows in pipelines
See other Data Flow articles related to performance: