Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Use the following strategies to optimize performance of transformations in mapping data flows in Azure Data Factory and Azure Synapse Analytics pipelines.
Optimizing Joins, Exists, and Lookups
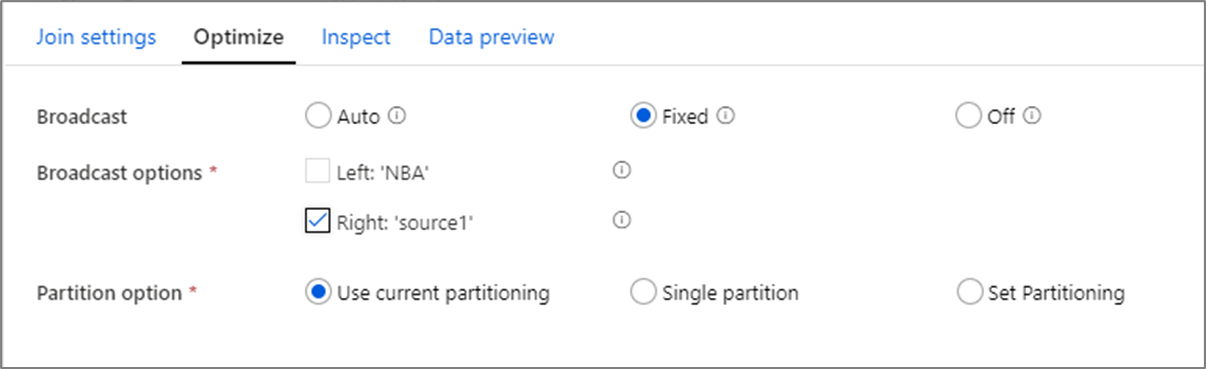
Broadcasting
In joins, lookups, and exists transformations, if one or both data streams are small enough to fit into worker node memory, you can optimize performance by enabling Broadcasting. Broadcasting is when you send small data frames to all nodes in the cluster. This allows for the Spark engine to perform a join without reshuffling the data in the large stream. By default, the Spark engine automatically decides whether or not to broadcast one side of a join. If you're familiar with your incoming data and know that one stream is smaller than the other, you can select Fixed broadcasting. Fixed broadcasting forces Spark to broadcast the selected stream.
If the size of the broadcasted data is too large for the Spark node, you might get an out of memory error. To avoid out of memory errors, use memory optimized clusters. If you experience broadcast timeouts during data flow executions, you can switch off the broadcast optimization. However, this results in slower performing data flows.
When working with data sources that can take longer to query, like large database queries, it's recommended to turn broadcast off for joins. Source with long query times can cause Spark timeouts when the cluster attempts to broadcast to compute nodes. Another good choice for turning off broadcast is when you have a stream in your data flow that is aggregating values for use in a lookup transformation later. This pattern can confuse the Spark optimizer and cause timeouts.
Cross joins
If you use literal values in your join conditions or have multiple matches on both sides of a join, Spark runs the join as a cross join. A cross join is a full cartesian product that then filters out the joined values. This is slower than other join types. Ensure that you have column references on both sides of your join conditions to avoid the performance impact.
Sorting before joins
Unlike merge join in tools like SSIS, the join transformation isn't a mandatory merge join operation. The join keys don't require sorting prior to the transformation. Using Sort transformations in mapping data flows isn't recommended.
Window transformation performance
The Window transformation in mapping data flow partitions your data by value in columns that you select as part of the over() clause in the transformation settings. There are many popular aggregate and analytical functions that are exposed in the Windows transformation. However, if your use case is to generate a window over your entire dataset for ranking rank() or row number rowNumber(), it's recommended that you instead use the Rank transformation and the Surrogate Key transformation. Those transformations perform better again full dataset operations using those functions.
Repartitioning skewed data
Certain transformations such as joins and aggregates reshuffle your data partitions and can occasionally lead to skewed data. Skewed data means that data isn't evenly distributed across the partitions. Heavily skewed data can lead to slower downstream transformations and sink writes. You can check the skewness of your data at any point in a data flow run by clicking on the transformation in the monitoring display.
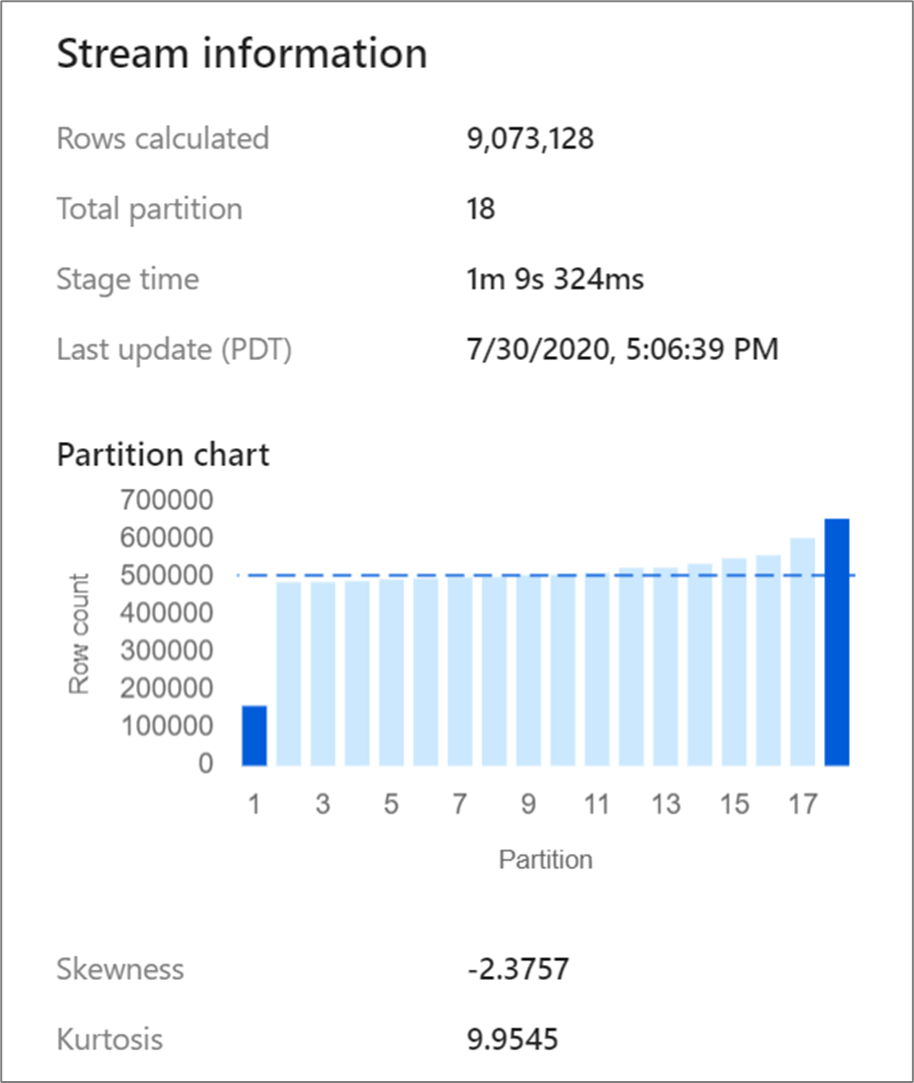
The monitoring display shows how the data is distributed across each partition along with two metrics, skewness and kurtosis. Skewness is a measure of how asymmetrical the data is and can have a positive, zero, negative, or undefined value. Negative skew means the left tail is longer than the right. Kurtosis is the measure of whether the data is heavy-tailed or light-tailed. High kurtosis values aren't desirable. Ideal ranges of skewness lie between -3 and 3 and ranges of kurtosis are less than 10. An easy way to interpret these numbers is looking at the partition chart and seeing if 1 bar is larger than the rest.
If your data isn't evenly partitioned after a transformation, you can use the optimize tab to repartition. Reshuffling data takes time and might not improve your data flow performance.
Tip
If you repartition your data, but have downstream transformations that reshuffle your data, use hash partitioning on a column used as a join key.
Note
Transformations inside your data flow (with the exception of the Sink transformation) do not modify the file and folder partitioning of data at rest. Partitioning in each transformation repartitions data inside the data frames of the temporary serverless Spark cluster that ADF manages for each of your data flow executions.
Related content
See other Data Flow articles related to performance: