Troubleshoot connector and format issues in mapping data flows in Azure Data Factory
This article explores troubleshooting methods related to connector and format for mapping data flows in Azure Data Factory (ADF).
Azure Blob Storage
Account Storage type (general purpose v1) doesn't support service principal and MI authentication
Symptoms
In data flows, if you use Azure Blob Storage (general purpose v1) with the service principal or MI authentication, you might encounter the following error message:
com.microsoft.dataflow.broker.InvalidOperationException: ServicePrincipal and MI auth are not supported if blob storage kind is Storage (general purpose v1)
Cause
When you use the Azure Blob linked service in data flows, the managed identity or service principal authentication isn't supported when the account kind is empty or Storage. This situation is shown in Image 1 and Image 2 below.
Image 1: The account kind in the Azure Blob Storage linked service
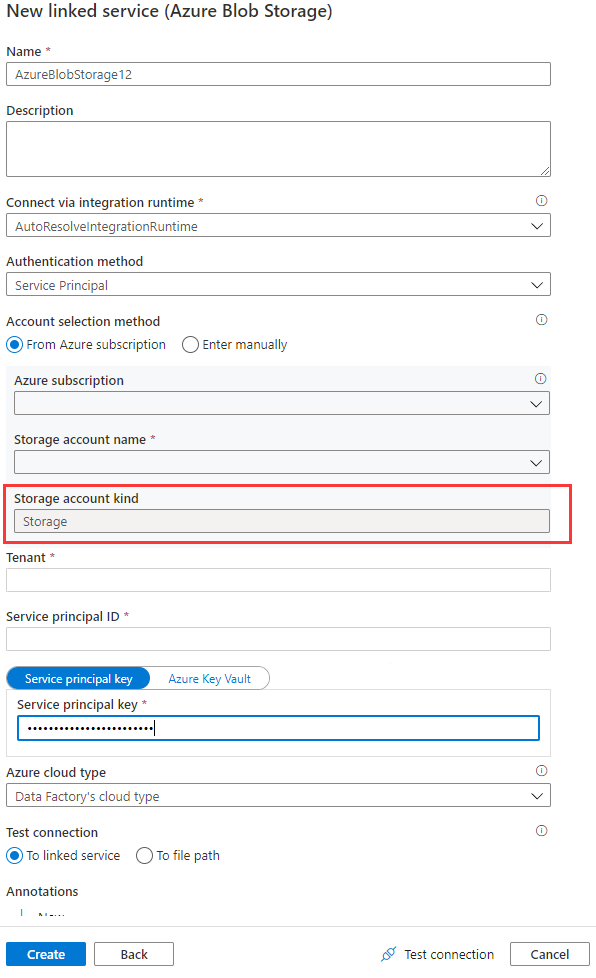
Image 2: Storage account page

Recommendation
To solve this issue, refer to the following recommendations:
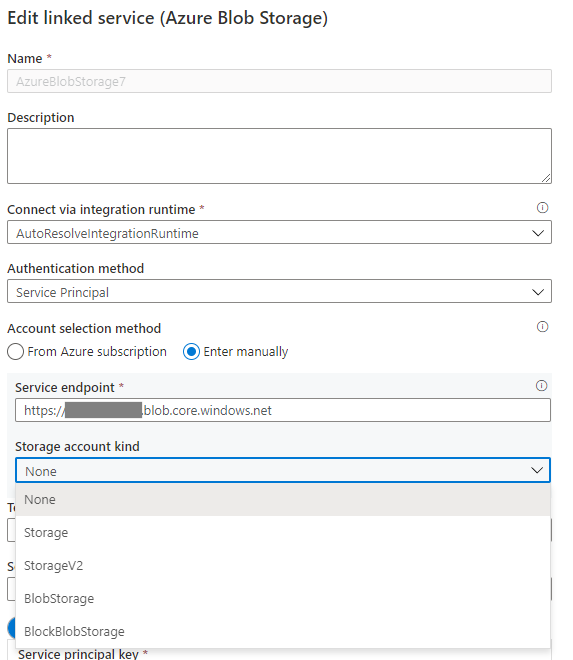
If the storage account kind is None in the Azure Blob linked service, specify the proper account kind, and refer to Image 3 that follows to accomplish it. Furthermore, refer to Image 2 to get the storage account kind, and check and confirm the account kind isn't Storage (general purpose v1).
Image 3: Specify the storage account kind in the Azure Blob Storage linked service
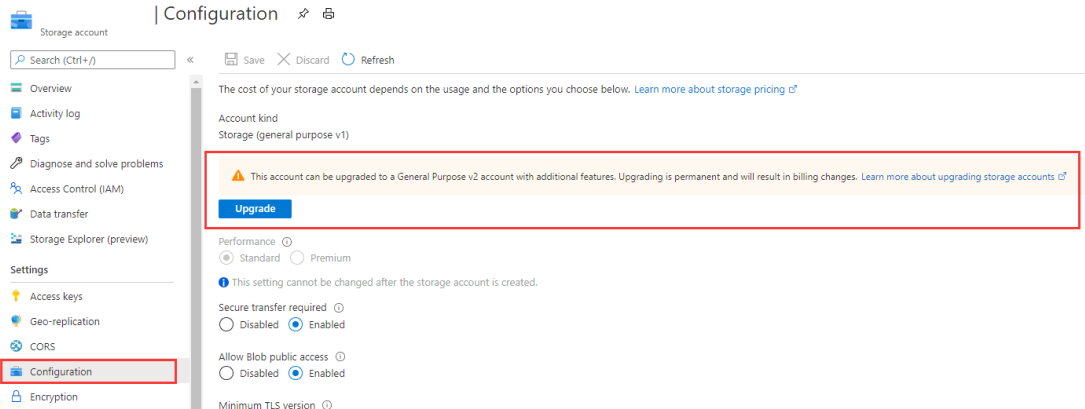
If the account kind is Storage (general purpose v1), upgrade your storage account to the general purpose v2 or choose a different authentication.
Image 4: Upgrade the storage account to general purpose v2

Azure Cosmos DB and JSON format
Support customized schemas in the source
Symptoms
When you want to use the ADF data flow to move or transfer data from Azure Cosmos DB/JSON into other data stores, some columns of the source data might be missed.
Cause
For the schema-free connectors (the column number, column name and column data type of each row can be different when comparing with others), by default, ADF uses sample rows (for example, top 100 or 1,000 rows data) to infer the schema, and the inferred result are used as a schema to read data. So if your data stores have extra columns that don't appear in sample rows, the data of these extra columns aren't read, moved, or transferred into sink data stores.
Recommendation
To overwrite the default behavior and bring in other fields, ADF provides options for you to customize the source schema. You can specify additional/missing columns that could be missing in schema-infer-result in the data flow source projection to read the data, and you can apply one of the following options to set the customized schema. Usually, Option-1 is more preferred.
Option-1: Compared with the original source data that might be one large file, table, or container that contains millions of rows with complex schemas, you can create a temporary table/container with a few rows that contain all the columns you want to read, and then move on to the following operation:
Use the data flow source Debug Settings to have Import projection with sample files/tables to get the complete schema. You can follow the steps in the following picture:
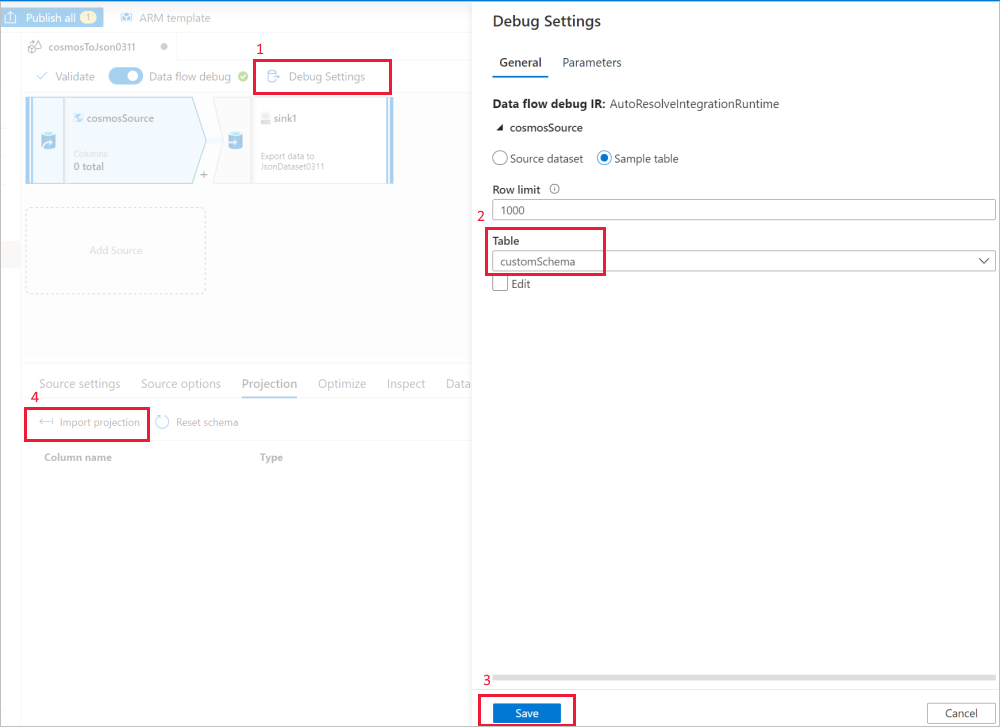
- Select Debug settings in the data flow canvas.
- In the pop-up pane, select Sample table under the cosmosSource tab, and enter the name of your table in the Table block.
- Select Save to save your settings.
- Select Import projection.
Change the Debug Settings back to use the source dataset for the remaining data movement/transformation. You can move on with the steps in the following picture:
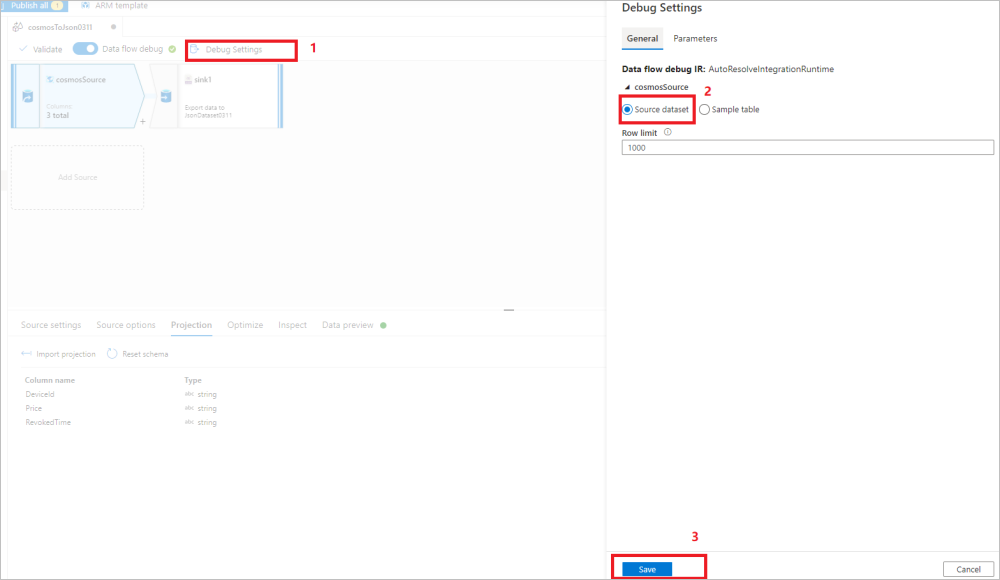
- Select Debug settings in the data flow canvas.
- In the pop-up pane, select Source dataset under the cosmosSource tab.
- Select Save to save your settings.
Afterwards, the ADF data flow runtime will honor and use the customized schema to read data from the original data store.
Option-2: If you're familiar with the schema and DSL language of the source data, you can manually update the data flow source script to add additional/missed columns to read the data. An example is shown in the following picture:
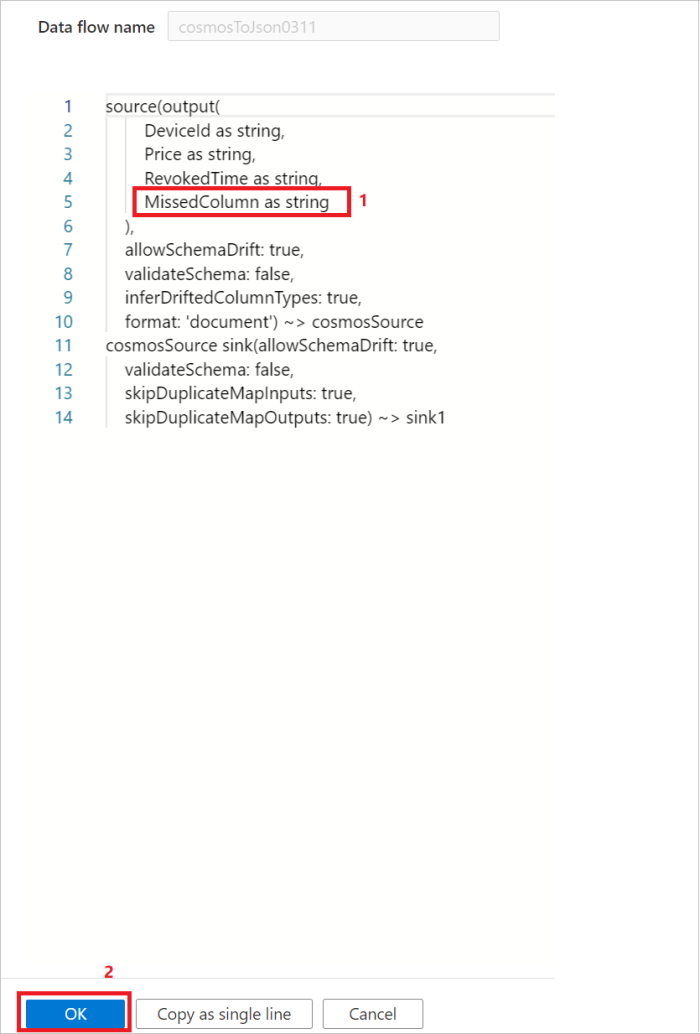
Support map type in the source
Symptoms
In ADF data flows, map data type can't be directly supported in Azure Cosmos DB or JSON source, so you can't get the map data type under "Import projection".
Cause
For Azure Cosmos DB and JSON, they're schema-free connectivity and related spark connector uses sample data to infer the schema, and then that schema is used as the Azure Cosmos DB/JSON source schema. When inferring the schema, the Azure Cosmos DB/JSON Spark connector can only infer object data as a struct rather than a map data type, and that's why map type can't be directly supported.
Recommendation
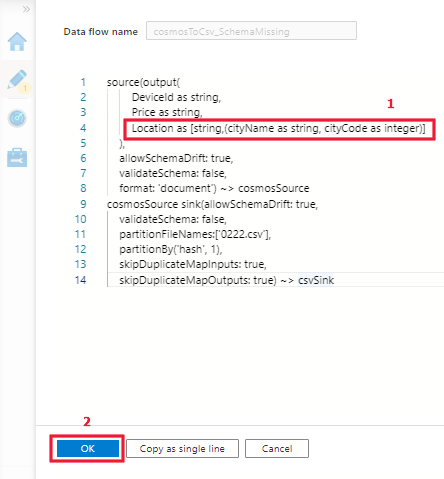
To solve this issue, refer to the following examples and steps to manually update the script (DSL) of the Azure Cosmos DB/JSON source to get the map data type support.
Examples:

Step-1: Open the script of the data flow activity.

Step-2: Update the DSL to get the map type support by referring to the examples above.
The map type support:
| Type | Is the map type supported? | Comments |
|---|---|---|
| Excel, CSV | No | Both are tabular data sources with the primitive type, so there's no need to support the map type. |
| Orc, Avro | Yes | None. |
| JSON | Yes | The map type can't be directly supported. Follow the recommendation part in this section to update the script (DSL) under the source projection. |
| Azure Cosmos DB | Yes | The map type can't be directly supported. Follow the recommendation part in this section to update the script (DSL) under the source projection. |
| Parquet | Yes | Today the complex data type isn't supported on the parquet dataset, so you need to use the "Import projection" under the data flow parquet source to get the map type. |
| XML | No | None. |
Consume JSON files generated by copy activities
Symptoms
If you use the copy activity to generate some JSON files, and then try to read these files in data flows, you fail with the error message: JSON parsing error, unsupported encoding or multiline
Cause
There are following limitations on JSON for copy and data flows respectively:
For Unicode encodings (utf-8, utf-16, utf-32) JSON files, copy activities always generate the JSON files with BOM.
The data flow JSON source with "Single document" enabled doesn't support Unicode encoding with BOM.
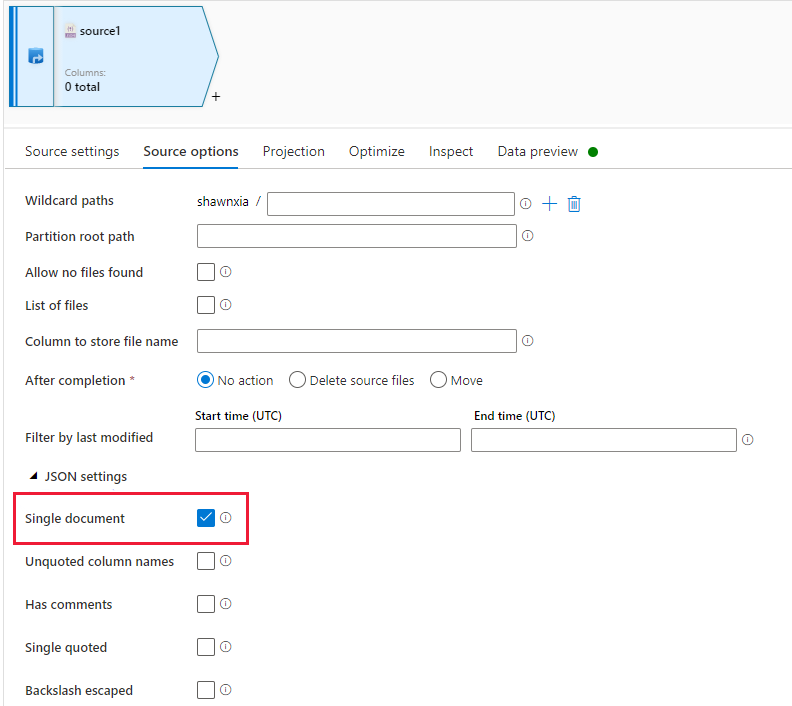
So you might experience issues if the following criteria are met:
The sink dataset used by the copy activity is set to Unicode encoding (utf-8, utf-16, utf-16be, utf-32, utf-32be) or the default is used.
The copy sink is set to use "Array of objects" file pattern as shown in the following picture, no matter whether "Single document" is enabled or not in the data flow JSON source.
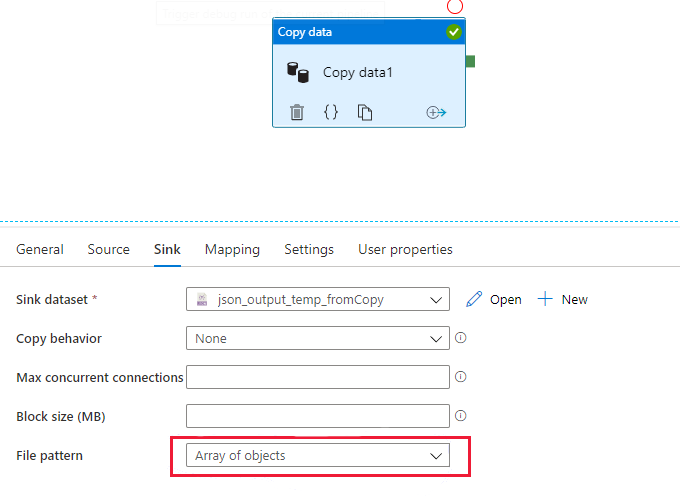
Recommendation
- Always use the default file pattern or explicit "Set of objects" pattern in the copy sink if the generated files are used in data flows.
- Disable the "Single document" option in the data flow JSON source.
Note
Using "Set of objects" is also the recommended practice from the performance perspective. As the "Single document" JSON in the data flow can't enable parallel reading for single large files, this recommendation does not have any negative impact.
The query with parameters doesn't work
Symptoms
Mapping data flows in Azure Data Factory supports the use of parameters. The parameter values are set by the calling pipeline via the Execute Data Flow activity, and using parameters is a good way to make your data flow general-purpose, flexible, and reusable. You can parameterize data flow settings and expressions with these parameters: Parameterizing mapping data flows.
After setting parameters and using them in the query of data flow source, they do not take effective.
Cause
You encounter this error due to your wrong configuration.
Recommendation
Use the following rules to set parameters in the query, and for more detailed information, refer to Build expressions in mapping data flow.
- Apply double quotes at the beginning of the SQL statement.
- Use single quotes around the parameter.
- Use lowercase letters for all CLAUSE statements.
For example:
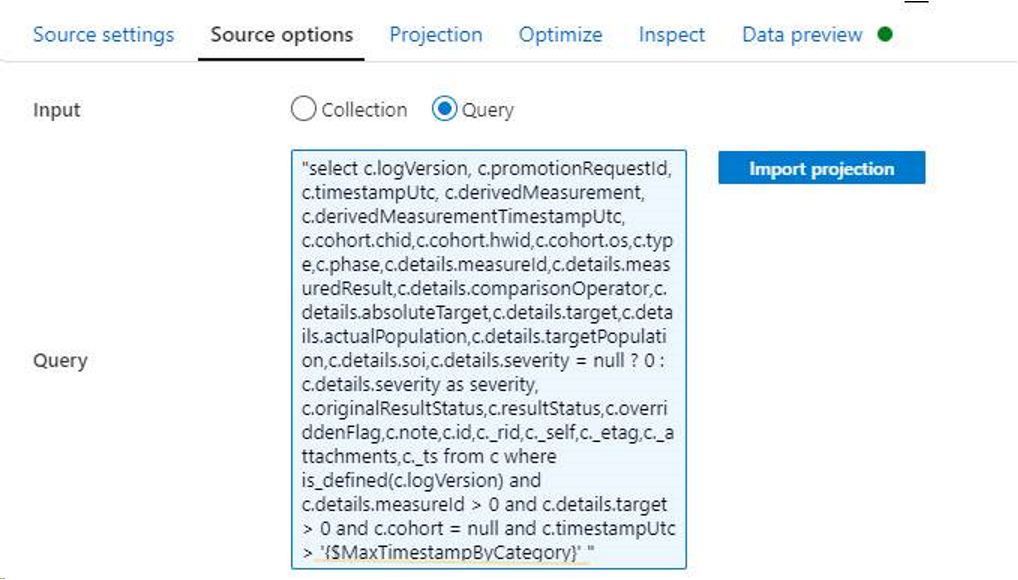
Azure Data Lake Storage Gen1
Fail to create files with service principle authentication
Symptoms
When you try to move or transfer data from different sources into the ADLS gen1 sink, if the linked service's authentication method is service principle authentication, your job might fail with the following error message:
org.apache.hadoop.security.AccessControlException: CREATE failed with error 0x83090aa2 (Forbidden. ACL verification failed. Either the resource does not exist or the user is not authorized to perform the requested operation.). [2b5e5d92-xxxx-xxxx-xxxx-db4ce6fa0487] failed with error 0x83090aa2 (Forbidden. ACL verification failed. Either the resource does not exist or the user is not authorized to perform the requested operation.)
Cause
The RWX permission or the dataset property isn't set correctly.
Recommendation
If the target folder doesn't have correct permissions, refer to this document to assign the correct permission in Gen1: Use service principal authentication.
If the target folder has the correct permission and you use the file name property in the data flow to target to the right folder and file name, but the file path property of the dataset isn't set to the target file path (usually leave not set), as the example shown in the following pictures, you encounter this failure because the backend system tries to create files based on the file path of the dataset, and the file path of the dataset doesn't have the correct permission.
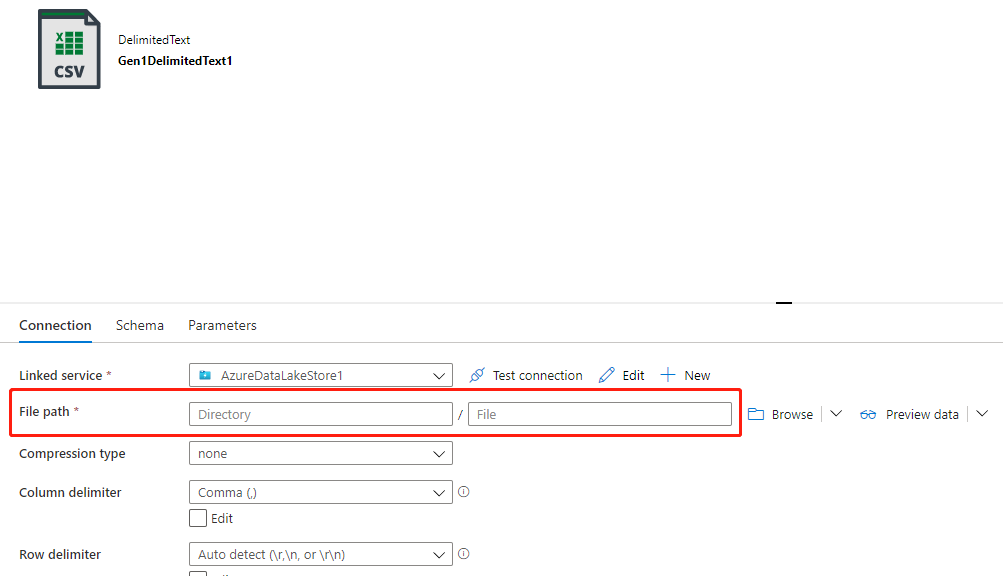
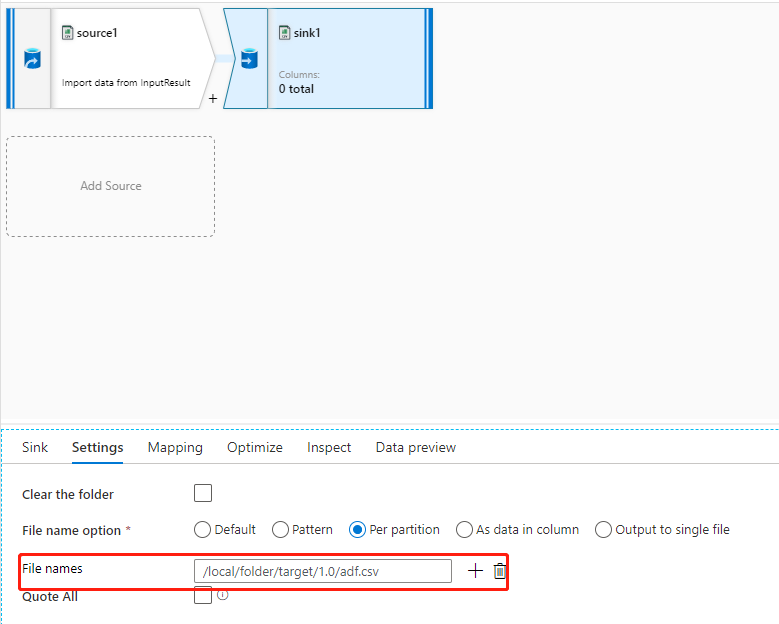
There are two methods to solve this issue:
- Assign the WX permission to the file path of the dataset.
- Set the file path of the dataset as the folder with WX permission, and set the rest folder path and file name in data flows.
Azure Data Lake Storage Gen2
Failed with an error: "Error while reading file XXX. It's possible the underlying files have been updated."
Symptoms
When you use the ADLS Gen2 as a sink in the data flow (to preview data, debug/trigger run, etc.) and the partition setting in Optimize tab in the Sink stage isn't default, you might find the job fails with the following error message:
Job failed due to reason: Error while reading file abfss:REDACTED_LOCAL_PART@prod.dfs.core.windows.net/import/data/e3342084-930c-4f08-9975-558a3116a1a9/part-00000-tid-7848242374008877624-5df7454e-7b14-4253-a20b-d20b63fe9983-1-1-c000.csv. It is possible the underlying files have been updated. You can explicitly invalidate the cache in Spark by running 'REFRESH TABLE tableName' command in SQL or by recreating the Dataset/DataFrame involved.
Cause
- You don't assign a proper permission to your MI/SP authentication.
- You might have a customized job to handle files that you don't want, which will affect the data flow's middle output.
Recommendation
- Check if your linked service has the R/W/E permission for Gen2. If you use the MI auth/SP authentication, at least grant the Storage Blob Data Contributor role in the Access control (IAM).
- Confirm if you have specific jobs that move/delete files to other place whose name doesn't match your rule. Because data flows write down partition files into the target folder firstly and then do the merge and rename operations, the middle file's name might not match your rule.
Azure Database for PostgreSQL
Encounter an error: Failed with exception: handshake_failure
Symptoms
You use Azure PostgreSQL as a source or sink in the data flow such as previewing data and debugging/triggering run, and you might find the job fails with following error message:
PSQLException: SSL error: Received fatal alert: handshake_failure
Caused by: SSLHandshakeException: Received fatal alert: handshake_failure.
Cause
If you use the flexible server or Hyperscale (Citus) for your Azure PostgreSQL server, since the system is built via Spark upon Azure Databricks cluster, there's a limitation in Azure Databricks blocks our system to connect to the Flexible server or Hyperscale (Citus). You can review the following two links as references.
Handshake fails trying to connect from Azure Databricks to Azure PostgreSQL with SSL
MCW-Real-time-data-with-Azure-Database-for-PostgreSQL-Hyperscale
Refer to the content in the following picture in this article: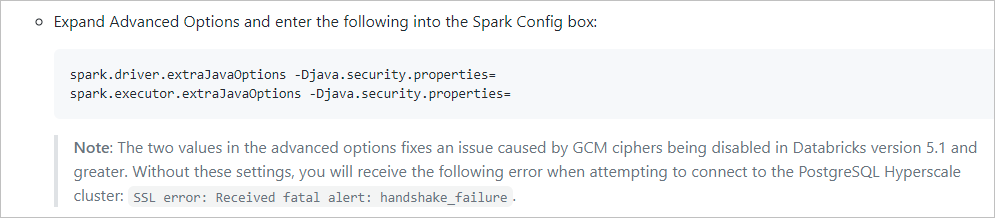
Recommendation
You can try to use copy activities to unblock this issue.
Azure SQL Database
Unable to connect to the SQL Database
Symptoms
Your Azure SQL Database can work well in the data copy, dataset preview-data, and test-connection in the linked service, but it fails when the same Azure SQL Database is used as a source or sink in the data flow with error like Cannot connect to SQL database: 'jdbc:sqlserver://powerbasenz.database.windows.net;..., Please check the linked service configuration is correct, and make sure the SQL database firewall allows the integration runtime to access.'
Cause
There are wrong firewall settings on your Azure SQL Database server, so that it can't be connected by the data flow runtime. Currently, when you try to use the data flow to read/write Azure SQL Database, Azure Databricks is used to build spark cluster to run the job, but it doesn't support fixed IP ranges. For more details, please refer to Azure Integration Runtime IP addresses.
Recommendation
Check the firewall settings of your Azure SQL Database and set it as "Allow access to Azure services" rather than set the fixed IP range.

Syntax error when using queries as input
Symptoms
When you use queries as input in the data flow source with the Azure SQL, you fail with the following error message:
at Source 'source1': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: Incorrect syntax XXXXXXXX.

Cause
The query used in the data flow source should be able to run as a sub query. The reason of the failure is that either the query syntax is incorrect or it can't be run as a sub query. You can run the following query in the SSMS to verify it:
SELECT top(0) * from ($yourQuery) as T_TEMP
Recommendation
Provide a correct query and test it in the SSMS firstly.
Failed with an error: "SQLServerException: 111212; Operation can't be performed within a transaction."
Symptoms
When you use the Azure SQL Database as a sink in the data flow to preview data, debug/trigger run and do other activities, you might find your job fails with following error message:
{"StatusCode":"DFExecutorUserError","Message":"Job failed due to reason: at Sink 'sink': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: 111212;Operation cannot be performed within a transaction.","Details":"at Sink 'sink': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: 111212;Operation cannot be performed within a transaction."}
Cause
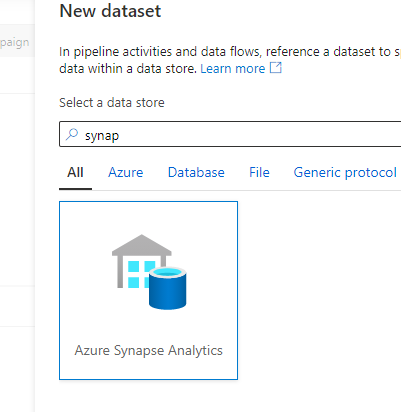
The error "111212;Operation cannot be performed within a transaction." only occurs in the Synapse dedicated SQL pool. But you mistakenly use the Azure SQL Database as the connector instead.
Recommendation
Confirm if your SQL Database is a Synapse dedicated SQL pool. If so, use Azure Synapse Analytics as a connector shown in the following image.
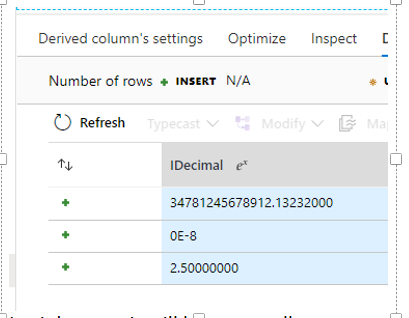
Data with the decimal type become null
Symptoms
You want to insert data into a table in the SQL database. If the data contains the decimal type and need to be inserted into a column with the decimal type in the SQL database, the data value might be changed to null.
If you do the preview, in previous stages, it shows the value like the following picture:
In the sink stage, it becomes null, which is shown in the following image.
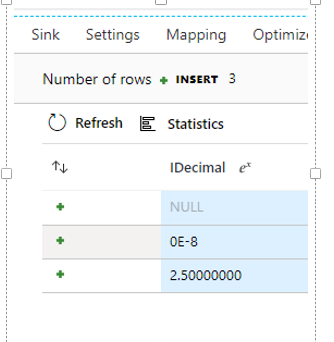
Cause
The decimal type has scale and precision properties. If your data type doesn't match that in the sink table, the system validates that the target decimal is wider than the original decimal, and the original value doesn't overflow in the target decimal. Therefore, the value is cast to null.
Recommendation
Check and compare the decimal type between data and table in the SQL database, and alter the scale and precision to the same.
You can use toDecimal (IDecimal, scale, precision) to figure out if the original data can be cast to the target scale and precision. If it returns null, it means that the data can't be cast and furthered when inserting.
Azure Synapse Analytics
Serverless pool (SQL on-demand) related issues
Symptoms
You use the Azure Synapse Analytics and the linked service actually is a Synapse serverless pool. Its former name is SQL on-demand pool, and you can distinguish it by finding the server name that contains ondemand, for example, space-ondemand.sql.azuresynapse.net. You might face with several unique failures such as these:
- When you want to use Synapse serverless pool as a Sink, you face the following error:
Sink results in 0 output columns. Please ensure at least one column is mapped - When you select 'enable staging' in the Source, you face the following error:
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: Incorrect syntax near 'IDENTITY'. - When you want to fetch data from an external table, you face the following error:
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: External table 'dbo' is not accessible because location does not exist or it is used by another process. - When you want to fetch data from Azure Cosmos DB through Serverless pool by query/from view, you face the following error:
Job failed due to reason: Connection reset. - When you want to fetch data from a view, you might face with different errors.
Cause
Causes of the symptoms are stated respectively here:
- Serverless pool can't be used as a sink. It doesn't support write data into the database.
- Serverless pool doesn't support staged data loading, so 'enable staging' isn't supported.
- The authentication method that you use doesn't have a correct permission to the external data source where the external table referring to.
- There's a known limitation in Synapse serverless pool, blocking you to fetch Azure Cosmos DB data from data flows.
- View is a virtual table based on an SQL statement. The root cause is inside the statement of the view.
Recommendation
You can apply the following steps to solve your issues correspondingly.
You should better not use serverless pool as a sink.
Don't use 'enable staging' in Source for serverless pool.
Only service principal/managed identity that has the permission to the external table data can query it. Grant 'Storage Blob Data Contributor' permission to the external data source for the authentication method that you use in the ADF.
Note
The user-password authentication can not query external tables. For more information, see Security model.
You can use copy activity to fetch Azure Cosmos DB data from the serverless pool.
You can provide the SQL statement that creates the view to the engineering support team, and they can help analyze if the statement hits an authentication issue or something else.
Load small size data to Data Warehouse without staging is slow
Symptoms
When you load small data to Data Warehouse without staging, it takes a long time to finish. For example, the data size 2 MB but it takes more than 1 hour to finish.
Cause
The row count rather than the size causes this issue. The row count has few thousand, and each insert needs to be packaged into an independent request, go to the control node, start a new transaction, get locks, and go to the distribution node repeatedly. Bulk load gets the lock once, and each distribution node performs the insert by batching into memory efficiently.
If 2 MB is inserted as just a few records, it would be fast. For example, it would be fast if each record is 500 kb * 4 rows.
Recommendation
You need to enable staging to improve the performance.
Read empty string value ("") as NULL with the enable staging
Symptoms
When you use Synapse as a source in the data flow such as previewing data and debugging/triggering run and enable staging to use the PolyBase, if your column value contains empty string value (""), it is changed to null.
Cause
The data flow back end uses Parquet as the PolyBase format, and there's a known limitation in the Synapse SQL pool gen2, which automatically changes the empty string value to null.
Recommendation
You can try to solve this issue by the following methods:
- If your data size isn't huge, you can disable Enable staging in the Source, but the performance is affected.
- If you need to enable staging, you can use iifNull() function to manually change the specific column from null to empty string value.
Managed service identity error
Symptoms
When you use the Synapse as a source/sink in the data flow to preview data, debug/trigger run, etc. and enable staging to use the PolyBase, and the staging store's linked service (Blob, Gen2, etc.) is created to use the Managed Identity (MI) authentication, your job could fail with the following error shown in the picture:
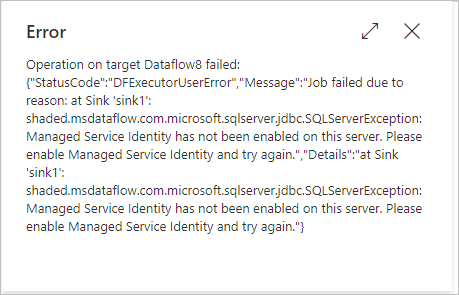
Error message
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: Managed Service Identity has not been enabled on this server. Please enable Managed Service Identity and try again.
Cause
- If the SQL pool is created from Synapse workspace, MI authentication on staging store with the PolyBase isn't supported for the old SQL pool.
- If the SQL pool is the old Data Warehouse (DWH) version, MI of the SQL server isn't assigned to the staging store.
Recommendation
Confirm the SQL pool was created from the Azure Synapse workspace.
- If the SQL pool was created from the Azure Synapse workspace, no extra steps are necessary. You no longer need to re-register the Managed Identity (MI) of the workspace. The system assigned managed identity (SA-MI) of the workspace is a member of the Synapse Administrator role and thus has elevated privileges on the dedicated SQL pools of the workspace.
- If the SQL pool is a dedicated SQL pool (formerly SQL DW) predating Azure Synapse, only enable MI for your SQL server and assign the permission of the staging store to the MI of your SQL Server. You can refer to the steps in this article as an example: Use virtual network service endpoints and rules for servers in Azure SQL Database.
Failed with an error: "SQLServerException: Not able to validate external location because the remote server returned an error: (403)"
Symptoms
When you use SQLDW as a sink to trigger and run data flow activities, the activity might fail with error like: "SQLServerException: Not able to validate external location because the remote server returned an error: (403)"
Cause
- When you use the managed identity in the authentication method in the ADLS Gen2 account as staging, you might not set the authentication configuration correctly.
- With the virtual network integration runtime, you need to use the managed identity in the authentication method in the ADLS Gen2 account as staging. If your staging Azure Storage is configured with the virtual network service endpoint, you must use managed identity authentication with "allow trusted Microsoft service" enabled on the storage account.
- Check whether your folder name contains the space character or other special characters, for example:
Space " < > # % |. Currently folder names that contain certain special characters aren't supported in the Data Warehouse copy command.
Recommendation
For Cause 1, you can refer to the following document: Use virtual network service endpoints and rules for servers in Azure SQL Database-Steps to solve this issue.
For Cause 2, work around it with one of the following options:
Option-1: If you use the virtual network integration runtime, you need to use the managed identity in the authentication method in the ADLS GEN 2 account as staging.
Option-2: If your staging Azure Storage is configured with the virtual network service endpoint, you must use managed identity authentication with "allow trusted Microsoft service" enabled on the storage account. You can refer to this doc: Staged copy by using PolyBase for more information.
For Cause 3, work around it with one of the following options:
Option-1: Rename the folder and avoid using special characters in the folder name.
Option-2: Remove the property
allowCopyCommand:truein the data flow script, for example:
Failed with an error: "shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: User doesn't have permission to perform this action."
Symptoms
When you use Azure Synapse Analytics as a source/sink and use PolyBase staging in data flows, you meet the following error:
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: User does not have permission to perform this action.
Cause
PolyBase requires certain permissions in your Synapse SQL server to work.
Recommendation
Grant these permissions in your Synapse SQL server when you use PolyBase:
ALTER ANY SCHEMA
ALTER ANY EXTERNAL DATA SOURCE
ALTER ANY EXTERNAL FILE FORMAT
CONTROL DATABASE
Common Data Model format
Model.json files with special characters
Symptoms
You might encounter an issue that the final name of the model.json file contains special characters.
Error message
at Source 'source1': java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: PPDFTable1.csv@snapshot=2020-10-21T18:00:36.9469086Z.
Recommendation
Replace the special chars in the file name, which works in the synapse but not in ADF.
No data output in the data preview or after running pipelines
Symptoms
When you use the manifest.json for CDM, no data is shown in the data preview or shown after running a pipeline. Only headers are shown. You can see this issue in the picture below.

Cause
The manifest document describes the CDM folder, for example, what entities that you have in the folder, references of those entities and the data that corresponds to this instance. Your manifest document misses the dataPartitions information that indicates ADF where to read the data, and since it's empty, it returns zero data.
Recommendation
Update your manifest document to have the dataPartitions information, and you can refer to this example manifest document to update your document: Common Data Model metadata: Introducing manifest-Example manifest document.
JSON array attributes are inferred as separate columns
Symptoms
You might encounter an issue where one attribute (string type) of the CDM entity has a JSON array as data. When this data is encountered, ADF infers the data as separate columns incorrectly. As you can see from the following pictures, a single attribute presented in the source (msfp_otherproperties) is inferred as a separate column in the CDM connector's preview.
In the CSV source data (refer to the second column):

In the CDM source data preview:
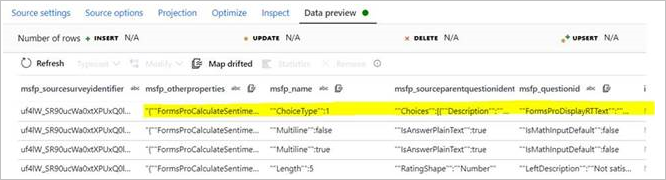
You might also try to map drifted columns and use the data flow expression to transform this attribute as an array. But since this attribute is read as a separate column when reading, transforming to an array does not work.
Cause
This issue is likely caused by the commas within your JSON object value for that column. Since your data file is expected to be a CSV file, the comma indicates that it's the end of a column's value.
Recommendation
To solve this problem, you need to double quote your JSON column and avoid any of the inner quotes with a backslash (\). In this way, the contents of that column's value can be read in as a single column entirely.
Note
The CDM doesn't inform that the data type of the column value is JSON, yet it informs that it is a string and parsed as such.
Unable to fetch data in the data flow preview
Symptoms
You use CDM with model.json generated by Power BI. When you preview the CDM data using the data flow preview, you encounter an error: No output data.
Cause
The following code exists in the partitions in the model.json file generated by the Power BI data flow.
"partitions": [
{
"name": "Part001",
"refreshTime": "2020-10-02T13:26:10.7624605+00:00",
"location": "https://datalakegen2.dfs.core.windows.net/powerbi/salesEntities/salesPerfByYear.csv @snapshot=2020-10-02T13:26:10.6681248Z"
}
For this model.json file, the issue is the naming schema of the data partition file has special characters, and supporting file paths with '@' do not exist currently.
Recommendation
Remove the @snapshot=2020-10-02T13:26:10.6681248Z part from the data partition file name and the model.json file, and then try again.
The corpus path is null or empty
Symptoms
When you use CDM in the data flow with the model format, you can't preview the data, and you encounter the error: DF-CDM_005 The corpus path is null or empty. The error is shown in the following picture:
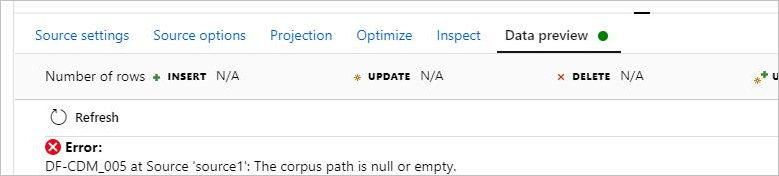
Cause
Your data partition path in the model.json is pointing to a blob storage location and not your data lake. The location should have the base URL of .dfs.core.windows.net for the ADLS Gen2.
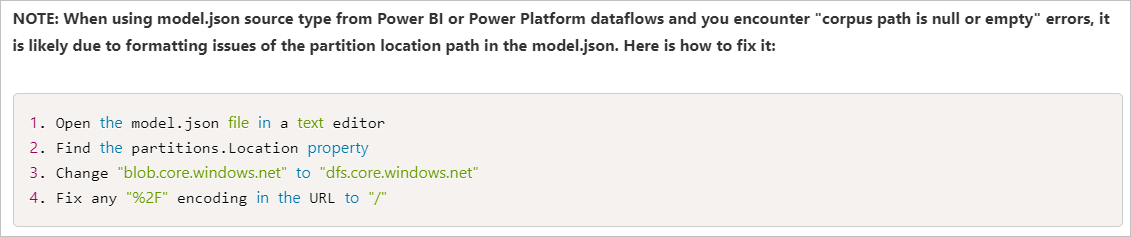
Recommendation
To solve this issue, you can refer to this article: ADF Adds Support for Inline Datasets and Common Data Model to Data Flows, and the following picture shows the way to fix the corpus path error in this article.
Unable to read CSV data files
Symptoms
You use the inline dataset as the common data model with manifest as a source, and you provided the entry manifest file, root path, entity name, and path. In the manifest, you have the data partitions with the CSV file location. Meanwhile, the entity schema and csv schema are identical, and all validations were successful. However, in the data preview, only the schema rather than the data gets loaded and the data is invisible, which is shown in the following picture:
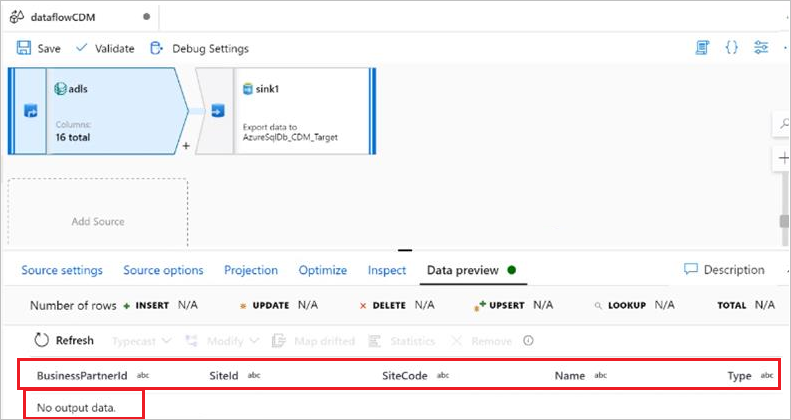
Cause
Your CDM folder isn't separated into logical and physical models, and only physical models exist in the CDM folder. The following two articles describe the difference: Logical definitions and Resolving a logical entity definition.
Recommendation
For the data flow using CDM as a source, try to use a logical model as your entity reference, and use the manifest that describes the location of the physical resolved entities and the data partition locations. You can see some samples of logical entity definitions within the public CDM GitHub repository: CDM-schemaDocuments
A good starting point to forming your corpus is to copy the files within the schema documents folder (just that level inside the GitHub repository), and put those files into a folder. Afterwards, you can use one of the predefined logical entities within the repository (as a starting or reference point) to create your logical model.
Once the corpus is set up, you're recommended to use CDM as a sink within data flows, so that a well-formed CDM folder can be properly created. You can use your CSV dataset as a source and then sink it to your CDM model that you created.
CSV and Excel format
Set the quote character to 'no quote char' isn't supported in the CSV
Symptoms
There are several issues that aren't supported in the CSV when the quote character is set to 'no quote char':
- When the quote character is set to 'no quote char', multi-char column delimiter can't start and end with the same letters.
- When the quote character is set to 'no quote char', multi-char column delimiter can't contain the escape character:
\. - When the quote character is set to 'no quote char', column value can't contain row delimiter.
- The quote character and the escape character can't both be empty (no quote and no escape) if the column value contains a column delimiter.
Cause
Causes of the symptoms are stated below with examples respectively:
Start and end with the same letters.
column delimiter: $*^$*
column value: abc$*^ def
csv sink: abc$*^$*^$*def
will be read as "abc" and "^&*def"The multi-char delimiter contains escape characters.
column delimiter: \x
escape char:\
column value: "abc\\xdef"
The escape character either escapes the column delimiter or the escape the character.The column value contains the row delimiter.
We need quote character to tell if row delimiter is inside column value or not.The quote character and the escape character both be empty and the column value contains column delimiters.
Column delimiter: \t
column value: 111\t222\t33\t3
It will be ambigious if it contains 3 columns 111,222,33\t3 or 4 columns 111,222,33,3.
Recommendation
The first symptom and the second symptom can't be solved currently. For the third and fourth symptoms, you can apply the following methods:
- For Symptom 3, don't use the 'no quote char' for a multiline csv file.
- For Symptom 4, set either the quote character or the escape character as nonempty, or you can remove all column delimiters inside your data.
Read files with different schemas error
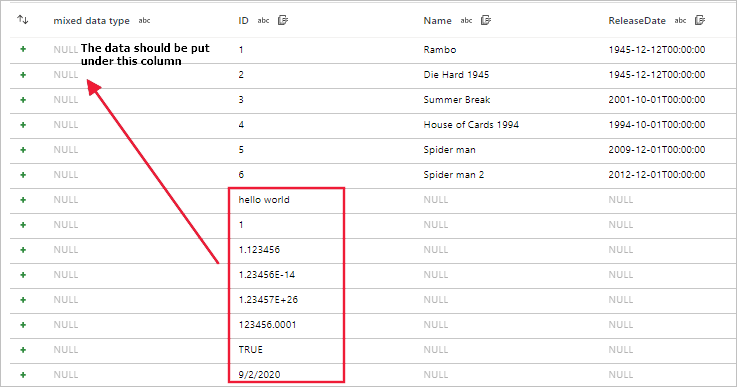
Symptoms
When you use data flows to read files such as CSV and Excel files with different schemas, the data flow debug, sandbox, or activity run fails.
For CSV, the data misalignment exists when the schema of files is different.
For Excel, an error occurs when the schema of the file is different.

Cause
Reading files with different schemas in the data flow isn't supported.
Recommendation
If you still want to transfer files such as CSV and Excel files with different schemas in the data flow, you can use these ways to work around:
For CSV, you need to manually merge the schema of different files to get the full schema. For example, file_1 has columns
c_1,c_2,c_3while file_2 has columnsc_3,c_4, ...c_10, so the merged and the full schema isc_1,c_2, ...c_10. Then make other files also have the same full schema even though it doesn't have data, for example, file_x only has columnsc_1,c_2,c_3,c_4, add columnsc_5,c_6, ...c_10in the file to make them consistent with the other files.For Excel, you can solve this issue by applying one of the following options:
- Option-1: You need to manually merge the schema of different files to get the full schema. For example, file_1 has columns
c_1,c_2,c_3while file_2 has columnsc_3,c_4, ...c_10, so the merged and full schema isc_1,c_2, ...c_10. Then make other files also have the same schema even though it doesn't have data, for example, file_x with sheet "SHEET_1" only has columnsc_1,c_2,c_3,c_4, please add columnsc_5,c_6, ...c_10in the sheet too, and then it can work. - Option-2: Use range (for example, A1:G100) + firstRowAsHeader=false, and then it can load data from all Excel files even though the column name and count is different.
- Option-1: You need to manually merge the schema of different files to get the full schema. For example, file_1 has columns
Snowflake
Unable to connect to the Snowflake linked service
Symptoms
You encounter the following error when you create the Snowflake linked service in the public network, and you use the autoresolve integration runtime.
ERROR [HY000] [Microsoft][Snowflake] (4) REST request for URL https://XXXXXXXX.east-us- 2.azure.snowflakecomputing.com.snowflakecomputing.com:443/session/v1/login-request?requestId=XXXXXXXXXXXXXXXXXXXXXXXXX&request_guid=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
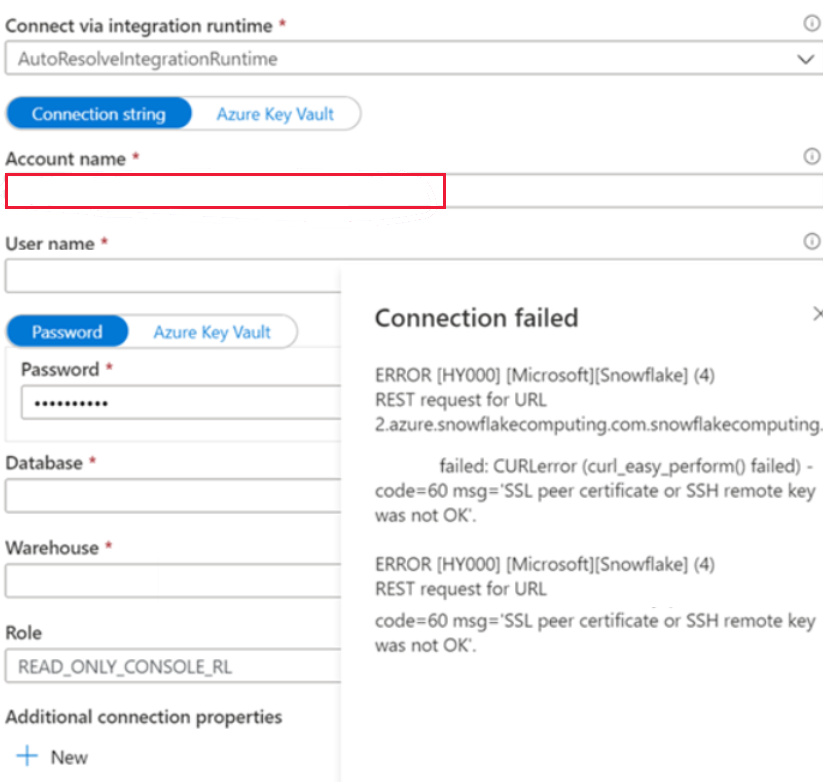
Cause
You haven't applied the account name in the format that is given in the Snowflake account document (including extra segments that identify the region and cloud platform), for example, XXXXXXXX.east-us-2.azure. You can refer to this document: Linked service properties for more information.
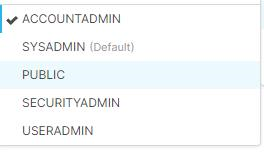
Recommendation
To solve the issue, change the account name format. The role should be one of the roles shown in the following picture, but the default one is Public.
SQL access control error: "Insufficient privileges to operate on schema"
Symptoms
When you try to use "import projection", "data preview", etc. in the Snowflake source of data flows, you meet errors like net.snowflake.client.jdbc.SnowflakeSQLException: SQL access control error: Insufficient privileges to operate on schema.
Cause
You meet this error because of the wrong configuration. When you use the data flow to read Snowflake data, the runtime Azure Databricks (ADB) isn't directly select the query to Snowflake. Instead, a temporary stage are created, and data are pulled from tables to the stage and then compressed and pulled by ADB. This process is shown in the picture below.
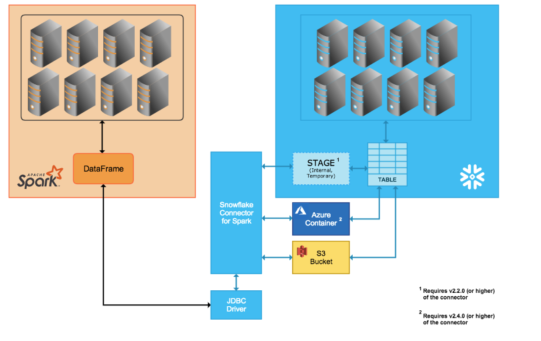
So the user/role used in ADB should have necessary permission to do this in the Snowflake. But usually the user/role don't have the permission since the database is created on the share.
Recommendation
To solve this issue, you can create different database and create views on the top of the shared DB to access it from ADB. For more details, please refer to Snowflake.
Failed with an error: "SnowflakeSQLException: IP x.x.x.x isn't allowed to access Snowflake. Contact your local security administrator"
Symptoms
When you use snowflake in Azure Data Factory, you can successfully use test-connection in the Snowflake linked service, preview-data/import-schema on Snowflake dataset and run copy/lookup/get-metadata or other activities with it. But when you use Snowflake in the data flow activity, you might see an error like SnowflakeSQLException: IP 13.66.58.164 is not allowed to access Snowflake. Contact your local security administrator.
Cause
The Azure Data Factory data flow doesn't support the use of fixed IP ranges. For more information, see Azure Integration Runtime IP addresses.
Recommendation
To solve this issue, you can change the Snowflake account firewall settings with the following steps:
You can get the IP range list of service tags from the "service tags IP range download link": Discover service tags by using downloadable JSON files.
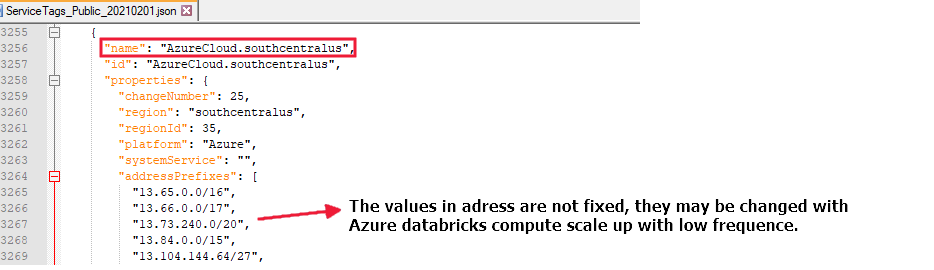
If you run a data flow in the "southcentralus" region, you need to allow the access from all addresses with name "AzureCloud.southcentralus", for example:
Queries in the source doesn't work
Symptoms
When you try to read data from Snowflake with query, you might see an error like these:
SQL compilation error: error line 1 at position 7 invalid identifier 'xxx'SQL compilation error: Object 'xxx' does not exist or not authorized.
Cause
You encounter this error because of your wrong configuration.
Recommendation
For Snowflake, it applies the following rules for storing identifiers at creation/definition time and resolving them in queries and other SQL statements:
When an identifier (table name, schema name, column name, etc.) is unquoted, it's stored and resolved in uppercase by default, and it's case-in-sensitive. For example:

Because it's case-in-sensitive, so you can feel free to use following query to read snowflake data while the result is the same:
Select MovieID, title from Public.TestQuotedTable2Select movieId, title from Public.TESTQUOTEDTABLE2Select movieID, TITLE from PUBLIC.TESTQUOTEDTABLE2
When an identifier (table name, schema name, column name, etc.) is double-quoted, it's stored and resolved exactly as entered, including case as it is case-sensitive, and you can see an example in the following picture. For more details, please refer to this document: Identifier Requirements.

Because the case-sensitive identifier (table name, schema name, column name, etc.) has lowercase character, you must quote the identifier during data reading with the query, for example:
- Select "movieId", "title" from Public."testQuotedTable2"
If you meet up error with the Snowflake query, check whether some identifiers (table name, schema name, column name, etc.) are case-sensitive with the following steps:
Sign in to the Snowflake server (
https://{accountName}.azure.snowflakecomputing.com/, replace {accountName} with your account name) to check the identifier (table name, schema name, column name, etc.).Create worksheets to test and validate the query:
- Run
Use database {databaseName}, replace {databaseName} with your database name. - Run a query with table, for example:
select "movieId", "title" from Public."testQuotedTable2"
- Run
After the SQL query of Snowflake is tested and validated, you can use it in the data flow Snowflake source directly.
The expression type doesn't match the column data type, expecting VARIANT but got VARCHAR
Symptoms
When you try to write data into the Snowflake table, you might meet the following error:
java.sql.BatchUpdateException: SQL compilation error: Expression type does not match column data type, expecting VARIANT but got VARCHAR
Cause
The column type of input data is string, which is different from the VARIANT type of the related column in the Snowflake sink.
When you store data with complex schemas (array/map/struct) in a new Snowflake table, the data flow type is automatically converted into its physical type VARIANT.

The related values are stored as JSON strings, showing in the picture below.

Recommendation
For the Snowflake VARIANT, it can only accept the data flow value that is struct or map or array type. If the value of your input data column is JSON or XML or other strings, use one of the following options to solve this issue:
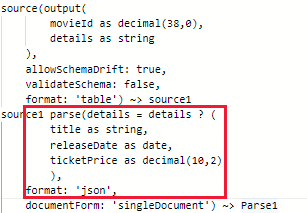
Option-1: Use parse transformation before using Snowflake as a sink to covert the input data column value into struct or map or array type, for example:
Note
The value of the Snowflake column with VARIANT type is read as string in Spark by default.
Option-2: Sign in to your Snowflake server (
https://{accountName}.azure.snowflakecomputing.com/, replace {accountName} with your account name) to change the schema of your Snowflake target table. Apply the following steps by running the query under each step.Create one new column with VARCHAR to store the values.
alter table tablename add newcolumnname varchar;Copy the value of VARIANT into the new column.
update tablename t1 set newcolumnname = t1."details"Delete the unused VARIANT column.
alter table tablename drop column "details";Rename the new column to the old name.
alter table tablename rename column newcolumnname to "details";
Related content
For more help with troubleshooting, see these resources: