Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
This article explores common troubleshooting methods for mapping data flows in Azure Data Factory.
General troubleshooting guidance
- Check the status of your dataset connections. In each source and sink transformation, go to the linked service for each dataset that you're using and test the connections.
- Check the status of your file and table connections in the data flow designer. In debug mode, select Data Preview on your source transformations to ensure that you can access your data.
- If everything looks correct in data preview, go into the Pipeline designer and put your data flow in a Pipeline activity. Debug the pipeline for an end-to-end test.
Internal server errors
Specific scenarios that can cause internal server errors are shown as follows.
Scenario 1: Not choosing the appropriate compute size/type and other factors
Successful execution of data flows depends on many factors, including the compute size/type, numbers of source/sinks to process, the partition specification, transformations involved, sizes of datasets, the data skewness and so on.
For more information, see Integration Runtime performance.
Scenario 2: Using debug sessions with parallel activities
When you trigger a run using the data flow debug session with constructs like ForEach in the pipeline, multiple parallel runs can be submitted to the same cluster. This situation can lead to cluster failure problems while running because of resource issues, such as being out of memory.
To submit a run with the appropriate integration runtime configuration defined in the pipeline activity after publishing the changes, select Trigger Now or Debug > Use Activity Runtime.
Scenario 3: Transient issues
Transient issues with microservices involved in the execution can cause the run to fail.
Configuring retries in the pipeline activity can resolve the problems caused by transient issues. For more information, see Activity Policy.
Common error codes and messages
This section lists common error codes and messages reported by mapping data flows in Azure Data Factory, along with their associated causes and recommendations.
Error code: DF-AdobeIntegration-InvalidMapToFilter
- Message: Custom resource can only have one Key/Id mapped to filter.
- Cause: Invalid configurations are provided.
- Recommendation: In your AdobeIntegration settings, make sure that the custom resource can only have one Key/Id mapped to filter.
Error code: DF-AdobeIntegration-InvalidPartitionConfiguration
- Message: Only single partition is supported. Partition schema may be RoundRobin or Hash.
- Cause: Invalid partition configurations are provided.
- Recommendation: In AdobeIntegration settings, confirm that only the single partition is set and partition schemas may be RoundRobin or Hash.
Error code: DF-AdobeIntegration-InvalidPartitionType
- Message: Partition type has to be roundRobin.
- Cause: Invalid partition types are provided.
- Recommendation: Update AdobeIntegration settings to make your partition type is RoundRobin.
Error code: DF-AdobeIntegration-InvalidPrivacyRegulation
- Message: Only currently supported privacy regulation is 'GDPR'.
- Cause: Invalid privacy configurations are provided.
- Recommendation: Update AdobeIntegration settings while only privacy 'GDPR' is supported.
Error code: DF-AdobeIntegration-KeyColumnMissed
- Message: Key must be specified for non-insertable operations.
- Cause: Key columns are missed.
- Recommendation: Update AdobeIntegration settings to ensure key columns are specified for non-insertable operations.
Error code: DF-AzureDataExplorer-InvalidOperation
- Message: Blob operation is not supported on older storage accounts. Creating a new storage account may fix the issue.
- Cause: Operation isn't supported.
- Recommendation: Change Update method configuration as delete, update, and upsert are not supported in Azure Data Explorer.
Error code: DF-AzureDataExplorer-ReadTimeout
- Message: Operation timeout while reading data.
- Cause: Operation times out while reading data.
- Recommendation: Increase the value in Timeout option in source transformation settings.
Error code: DF-AzureDataExplorer-WriteTimeout
- Message: Operation timeout while writing data.
- Cause: Operation times out while writing data.
- Recommendation: Increase the value in Timeout option in sink transformation settings.
Error code: DF-Blob-FunctionNotSupport
- Message: This endpoint does not support BlobStorageEvents, SoftDelete, or AutomaticSnapshot. Disable these account features if you would like to use this endpoint.
- Cause: Azure Blob Storage events, soft delete or automatic snapshot isn't supported in data flows if the Azure Blob Storage linked service is created with service principal or managed identity authentication.
- Recommendation: Disable Azure Blob Storage events, soft delete, or automatic snapshot feature on the Azure Blob account, or use key authentication to create the linked service.
Error code: DF-Blob-InvalidAccountConfiguration
- Message: Either one of account key or sas token should be specified.
- Cause: An invalid credential is provided in the Azure Blob linked service.
- Recommendation: Use either account key or SAS token for the Azure Blob linked service.
Error code: DF-Blob-InvalidAuthConfiguration
- Message: Only one of the two auth methods (Key, SAS) can be specified.
- Cause: An invalid authentication method is provided in the linked service.
- Recommendation: Use key or SAS authentication for the Azure Blob linked service.
Error code: DF-Blob-InvalidCloudType
- Message: Cloud type is invalid.
- Cause: An invalid cloud type is provided.
- Recommendation: Check the cloud type in your related Azure Blob linked service.
Error code: DF-Cosmos-DeleteDataFailed
- Message: Failed to delete data from Azure Cosmos DB after 3 times retry.
- Cause: The throughput on the Azure Cosmos DB collection is small and leads to meeting throttling or row data not existing in Azure Cosmos DB.
- Recommendation: To solve this problem, take the following actions:
- If the error is 404, make sure that the related row data exists in the Azure Cosmos DB collection.
- If the error is throttling, increase the Azure Cosmos DB collection throughput or set it to the automatic scale.
- If the error is request timed out, set 'Batch size' in the Azure Cosmos DB sink to smaller value, for example 1000.
Error code: DF-Cosmos-FailToResetThroughput
- Message: Azure Cosmos DB throughput scale operation cannot be performed because another scale operation is in progress, retry after sometime.
- Cause: The throughput scale operation of the Azure Cosmos DB can't be performed because another scale operation is in progress.
- Recommendation: Log in to Azure Cosmos DB account, and manually change container throughput to be auto scale or add a custom activity after mapping data flows to reset the throughput.
Error code: DF-Cosmos-IdPropertyMissed
- Message: 'id' property should be mapped for delete and update operations.
- Cause: The
idproperty is missed for update and delete operations. - Recommendation: Make sure that the input data has an
idcolumn in Azure Cosmos DB sink transformation settings. If not, use a select or derived column transformation to generate this column before the sink transformation.
Error code: DF-Cosmos-InvalidAccountConfiguration
- Message: Either accountName or accountEndpoint should be specified.
- Cause: Invalid account information is provided.
- Recommendation: In the Azure Cosmos DB linked service, specify the account name or account endpoint.
Error code: DF-Cosmos-InvalidAccountKey
- Message: The input authorization token can't serve the request. Check that the expected payload is built as per the protocol, and check the key being used.
- Cause: There's no enough permission to read/write Azure Cosmos DB data.
- Recommendation: Use the read-write key to access Azure Cosmos DB.
Error code: DF-Cosmos-InvalidConnectionMode
- Message: Invalid connection mode.
- Cause: An invalid connection mode is provided.
- Recommendation: Confirm that the supported mode is Gateway and DirectHttps in Azure Cosmos DB settings.
Error code: DF-Cosmos-InvalidPartitionKey
- Message: Partition key path cannot be empty for update and delete operations.
- Cause: The partition key path is empty for update and delete operations.
- Recommendation: Use the providing partition key in the Azure Cosmos DB sink settings.
- Message: Partition key is not mapped in sink for delete and update operations.
- Cause: An invalid partition key is provided.
- Recommendation: In Azure Cosmos DB sink settings, use the right partition key that is same as your container's partition key.
Error code: DF-Cosmos-InvalidPartitionKeyContent
- Message: partition key should start with /.
- Cause: An invalid partition key is provided.
- Recommendation: Ensure that the partition key start with
/in Azure Cosmos DB sink settings, for example:/movieId.
Error code: DF-Cosmos-PartitionKeyMissed
- Message: Partition key path should be specified for update and delete operations.
- Cause: The partition key path is missing in the Azure Cosmos DB sink.
- Recommendation: Provide the partition key in the Azure Cosmos DB sink settings.
Error code: DF-Cosmos-ResourceNotFound
- Message: Resource not found.
- Cause: Invalid configuration is provided (for example, the partition key with invalid characters) or the resource doesn't exist.
- Recommendation: To solve this issue, refer to Diagnose and troubleshoot Azure Cosmos DB not found exceptions.
Error code: DF-Cosmos-ShortTypeNotSupport
- Message: Short data type is not supported in Azure Cosmos DB.
- Cause: The short data type isn't supported in the Azure Cosmos DB instance.
- Recommendation: Add a derived column transformation to convert related columns from short to integer before using them in the Azure Cosmos DB sink transformation.
Error code: DF-CSVWriter-InvalidQuoteSetting
- Message: Job failed while writing data with error: Quote character and escape character cannot be empty if column value contains column delimiter
- Cause: Both quote characters and escape characters are empty when the column value contains column delimiter.
- Recommendation: Set your quote character or escape character.
Error code: DF-Delimited-ColumnDelimiterMissed
- Message: Column delimiter is required for parse.
- Cause: The column delimiter is missed.
- Recommendation: In your CSV settings, confirm that you have the column delimiter, which is required for parse.
Error code: DF-Delimited-InvalidConfiguration
- Message: Either one of empty lines or custom header should be specified.
- Cause: An invalid delimited configuration is provided.
- Recommendation: Update the CSV settings to specify one of empty lines or the custom header.
Error code: DF-DELTA-InvalidConfiguration
- Message: Timestamp and version can't be set at the same time.
- Cause: The timestamp and version can't be set at the same time.
- Recommendation: Set the timestamp or version in the delta settings.
Error code: DF-Delta-InvalidProtocolVersion
- Message: Unsupported Delta table protocol version, Refer https://docs.delta.io/latest/versioning.html#-table-version for versioning information.
- Cause: Data flows don't support this version of the Delta table protocol.
- Recommendation: Use a lower version of the Delta table protocol.
Error code: DF-DELTA-InvalidTableOperationSettings
- Message: Recreate and truncate options can't be both specified.
- Cause: Recreate and truncate options can't be specified simultaneously.
- Recommendation: Update delta settings to have either recreate or truncate operation.
Error code: DF-DELTA-KeyColumnMissed
- Message: Key columns should be specified for non-insertable operations.
- Cause: Key columns are missed for non-insertable operations.
- Recommendation: To have non-insertable operations, specify key columns on delta sink.
Error code: DF-Dynamics-InvalidNullAlternateKeyColumn
- Message: Any column value of alternate Key can't be NULL.
- Cause: Your alternate key column value can't be null.
- Recommendation: Confirm that your column value of your alternate key isn't NULL.
Error code: DF-Dynamics-TooMuchAlternateKey
- Cause: One lookup field with more than one alternate key reference isn't valid.
- Recommendation: Check your schema mapping and confirm that each lookup field has a single alternate key.
Error code: DF-Excel-DifferentSchemaNotSupport
- Message: Read excel files with different schema is not supported now.
- Cause: Reading excel files with different schemas is not supported now.
- Recommendation: Apply one of following options to solve this problem:
- Use ForEach + data flow activity to read Excel worksheets one by one.
- Update each worksheet schema to have the same columns manually before reading data.
Error code: DF-Excel-InvalidDataType
- Message: Data type is not supported.
- Cause: The data type is not supported.
- Recommendation: Change the data type to 'string' for related input data columns.
Error code: DF-Excel-InvalidFile
- Message: Invalid excel file is provided while only .xlsx and .xls are supported.
- Cause: Invalid Excel files are provided.
- Recommendation: Use the wildcard to filter, and get
.xlsand.xlsxExcel files before reading data.
Error code: DF-Excel-InvalidRange
- Message: Invalid range is provided.
- Cause: An invalid range is provided.
- Recommendation: Check the parameter value and specify the valid range by the following reference: Excel format in Azure Data Factory-Dataset properties.
Error code: DF-Excel-InvalidWorksheetConfiguration
- Message: Excel sheet name and index cannot exist at the same time.
- Cause: The Excel sheet name and index are provided at the same time.
- Recommendation: To read the Excel data, check the parameter value and specify the sheet name or index.
Error code: DF-Excel-WorksheetConfigMissed
- Message: Excel sheet name or index is required.
- Cause: An invalid Excel worksheet configuration is provided.
- Recommendation: To read the Excel data, check the parameter value and specify the sheet name or index.
Error code: DF-Excel-WorksheetNotExist
- Message: Excel worksheet does not exist.
- Cause: An invalid worksheet name or index is provided.
- Recommendation: To read the Excel data, check the parameter value and specify a valid sheet name or index.
Error code: DF-Executor-AcquireStorageMemoryFailed
- Message: Transferring unroll memory to storage memory failed. Cluster ran out of memory during execution. Retry using an integration runtime with more cores and/or memory optimized compute type.
- Cause: The cluster has insufficient memory.
- Recommendation: Use an integration runtime with more cores and/or the memory optimized compute type.
Error code: DF-Executor-BlockCountExceedsLimitError
- Message: The uncommitted block count cannot exceed the maximum limit of 100,000 blocks. Check blob configuration.
- Cause: The maximum number of uncommitted blocks in a blob is 100,000.
- Recommendation: Contact the Microsoft product team for more details about this problem.
Error code: DF-Executor-BroadcastFailure
Message: Dataflow execution failed during broadcast exchange. Potential causes include misconfigured connections at sources or a broadcast join timeout error. To ensure the sources are configured correctly, test the connection or run a source data preview in a Dataflow debug session. To avoid the broadcast join timeout, you can choose the 'Off' broadcast option in the Join/Exists/Lookup transformations. If you intend to use the broadcast option to improve performance then make sure broadcast streams can produce data within 60 secs for debug runs and within 300 secs for job runs. If problem persists, contact customer support.
Cause:
- The source connection/configuration error could lead to a broadcast failure in join/exists/lookup transformations.
- Broadcast has a default timeout of 60 seconds in debug runs and 300 seconds in job runs. On the broadcast join, the stream chosen for the broadcast seems too large to produce data within this limit. If a broadcast join is not used, the default broadcast done by a data flow can reach the same limit.
Recommendation:
- Do data preview at sources to confirm the sources are well configured.
- Turn off the broadcast option or avoid broadcasting large data streams where the processing can take more than 60 seconds. Instead, choose a smaller stream to broadcast.
- Large SQL/Data Warehouse tables and source files are typically bad candidates.
- In the absence of a broadcast join, use a larger cluster if the error occurs.
- If the problem persists, contact the customer support.
Error code: DF-Executor-BroadcastTimeout
Message: Broadcast join timeout error. Make sure broadcast stream produces data within 60 secs in debug runs and 300 secs in job runs.
Cause: Broadcast has a default timeout of 60 seconds on debug runs and 300 seconds on job runs. The stream chosen for broadcast is too large to produce data within this limit.
Recommendation: Check the Optimize tab on your data flow transformations for join, exists, and lookup. The default option for broadcast is Auto. If Auto is set, or if you're manually setting the left or right side to broadcast under Fixed, you can either set a larger Azure integration runtime (IR) configuration or turn off broadcast. For the best performance in data flows, we recommend that you allow Spark to broadcast by using Auto and use a memory-optimized Azure IR.
If you're running the data flow in a debug test execution from a debug pipeline run, you might run into this condition more frequently. The more frequent occurrence of the error is because Azure Data Factory throttles the broadcast timeout to 60 seconds to maintain a faster debugging experience. You can extend the timeout to the 300-second timeout of a triggered run. To do so, you can use the Debug > Use Activity Runtime option to use the Azure IR defined in your Execute Data Flow pipeline activity.
Message: Broadcast join timeout error. You can choose 'Off' of broadcast option in join/exists/lookup transformation to avoid this issue. If you intend to broadcast join option to improve performance, then make sure broadcast stream can produce data within 60 secs in debug runs and 300 secs in job runs.
Cause: Broadcast has a default timeout of 60 seconds in debug runs and 300 seconds in job runs. On the broadcast join, the stream chosen for broadcast is too large to produce data within this limit. If a broadcast join isn't used, the default broadcast by dataflow can reach the same limit.
Recommendation: Turn off the broadcast option or avoid broadcasting large data streams for which the processing can take more than 60 seconds. Choose a smaller stream to broadcast. Large Azure SQL Data Warehouse tables and source files aren't typically good choices. In the absence of a broadcast join, use a larger cluster if this error occurs.
Error code: DF-Executor-ColumnNotFound
- Message: Column name used in expression is unavailable or invalid.
- Cause: An invalid or unavailable column name is used in an expression.
- Recommendation: Check the column names used in expressions.
Error code: DF-Executor-Conversion
- Message: Converting to a date or time failed due to an invalid character
- Cause: Data isn't in the expected format.
- Recommendation: Use the correct data type.
Error code: DF-Executor-DriverError
- Message: INT96 is a legacy timestamp type, which is not supported by ADF Dataflow. Consider upgrading the column type to the latest types.
- Cause: Driver error.
- Recommendation: INT96 is a legacy timestamp type that's Azure Data Factory data flow doesn't support. Consider upgrading the column type to the latest type.
Error code: DF-Executor-FieldNotExist
- Message: Field in struct does not exist.
- Cause: Invalid or unavailable field names are used in expressions.
- Recommendation: Check field names used in expressions.
Error code: DF-Executor-illegalArgument
- Message: Make sure that the access key in your Linked Service is correct
- Cause: The account name or access key is incorrect.
- Recommendation: Ensure that the account name or access key specified in your linked service is correct.
Error code: DF-Executor-IncorrectLinkedServiceConfiguration
- Message: Possible causes are,
- The linked service is incorrectly configured as type 'Azure Blob Storage' instead of 'Azure DataLake Storage Gen2' and it has 'Hierarchical namespace' enabled. Create a new linked service of type 'Azure DataLake Storage Gen2' for the storage account in question.
- Certain scenarios with any combinations of 'Clear the folder', nondefault 'File name option', 'Key' partitioning may fail with a Blob linked service on a 'Hierarchical namespace' enabled storage account. You can disable these dataflow settings (if enabled) and try again in case you do not want to create a new Gen2 linked service.
- Cause: Delete operation on the Azure Data Lake Storage Gen2 account failed since its linked service is incorrectly configured as Azure Blob Storage.
- Recommendation: Create a new Azure Data Lake Storage Gen2 linked service for the storage account. If that's not feasible, some known scenarios like Clear the folder, nondefault File name option, Key partitioning in any combinations may fail with an Azure Blob Storage linked service on a hierarchical namespace enabled storage account. You can disable these data flow settings if you enabled them and try again.
Error code: DF-Executor-InternalServerError
- Message: Failed to execute dataflow with internal server error, retry later. If issue persists, contact Microsoft support for further assistance.
- Cause: The data flow execution is failed because of the system error.
- Recommendation: To solve this issue, refer to Internal server errors.
Error code: DF-Executor-InvalidColumn
- Message: Column name needs to be specified in the query, set an alias if using a SQL function.
- Cause: No column name is specified.
- Recommendation: Set an alias if you're using a SQL function like min() or max().
Error code: DF-Executor-InvalidInputColumns
- Message: The column in source configuration cannot be found in source data's schema.
- Cause: Invalid columns are provided on the source.
- Recommendation: Check columns in the source configuration and make sure that it's the subset of the source data's schemas.
Error code: DF-Executor-InvalidOutputColumns
- Message: The result has 0 output columns. Ensure at least one column is mapped.
- Cause: No column is mapped.
- Recommendation: Check the sink schema to ensure that at least one column is mapped.
Error code: DF-Executor-InvalidPartitionFileNames
- Message: File names cannot have empty values while file name option is set as per partition.
- Cause: Invalid partition file names are provided.
- Recommendation: Check your sink settings to have the right value of file names.
Error code: DF-Executor-InvalidPath
- Message: Path does not resolve to any files. Make sure the file/folder exists and is not hidden.
- Cause: An invalid file/folder path is provided, which can't be found or accessed.
- Recommendation: Check the file/folder path, and make sure it is existed and can be accessed in your storage.
Error code: DF-Executor-InvalidStageConfiguration
- Message: Storage with user assigned managed identity authentication in staging is not supported.
- Cause: An exception is happened because of invalid staging configuration.
- Recommendation: The user-assigned managed identity authentication is not supported in staging. Use a different authentication to create an Azure Data Lake Storage Gen2 or Azure Blob Storage linked service, then use it as staging in mapping data flows.
Error code: DF-Executor-InvalidType
- Message: Please make sure that the type of parameter matches with type of value passed in. Passing float parameters from pipelines isn't currently supported.
- Cause: Data types are incompatible between the declared type and the actual parameter value.
- Recommendation: Check that the parameter values passed into the data flow match the declared type.
Error code: DF-Executor-OutOfDiskSpaceError
- Message: Internal server error
- Cause: The cluster is running out of disk space.
- Recommendation: Retry the pipeline. If doing so doesn't resolve the problem, contact customer support.
Error code: DF-Executor-OutOfMemoryError
- Message: Cluster ran into out of memory issue during execution, please retry using an integration runtime with bigger core count and/or memory optimized compute type
- Cause: The cluster is running out of memory.
- Recommendation: Debug clusters are meant for development. Use data sampling and an appropriate compute type and size to run the payload. For performance tips, see Mapping data flow performance guide.
Error code: DF-Executor-OutOfMemorySparkBroadcastError
- Message: Explicitly broadcasted dataset using left/right option should be small enough to fit in node's memory. You can choose broadcast option 'Off' in join/exists/lookup transformation to avoid this issue or use an integration runtime with higher memory.
- Cause: The size of the broadcasted table far exceeds the limits of the node memory.
- Recommendation: The broadcast left/right option should only be used for smaller dataset sizes, which can fit into the node's memory. Make sure to configure the node size appropriately or turn off the broadcast option.
Error code: DF-Executor-OutOfMemorySparkError
- Message: The data may be too large to fit in the memory.
- Cause: The size of the data far exceeds the limit of the node memory.
- Recommendation: Increase the core count and switch to the memory optimized compute type.
Error code: DF-Executor-ExpressionParseError
- Message: Expression cannot be parsed.
- Cause: An expression generated parsing errors because of incorrect formatting.
- Recommendation: Check the formatting in the expression.
Error code: DF-Executor-PartitionDirectoryError
- Message: The specified source path has either multiple partitioned directories (for example, <Source Path>/<Partition Root Directory 1>/a=10/b=20, <Source Path>/<Partition Root Directory 2>/c=10/d=30) or partitioned directory with other file or non-partitioned directory (for example <Source Path>/<Partition Root Directory 1>/a=10/b=20, <Source Path>/Directory 2/file1), remove partition root directory from source path and read it through separate source transformation.
- Cause: The source path has either multiple partitioned directories or a partitioned directory that has another file or non-partitioned directory.
- Recommendation: Remove the partitioned root directory from the source path and read it through separate source transformation.
Error code: DF-Executor-RemoteRPCClientDisassociated
- Message: Job aborted due to stage failure. Remote RPC client disassociated. Likely due to containers exceeding thresholds, or network issues.
- Cause: Data flow activity run failed because of transient network issues or one node in spark cluster ran out of memory.
- Recommendation: Use the following options to solve this problem:
Option-1: Use a powerful cluster (both drive and executor nodes have enough memory to handle big data) to run data flow pipelines with setting "Compute type" to "Memory optimized". The settings are shown in the following picture.
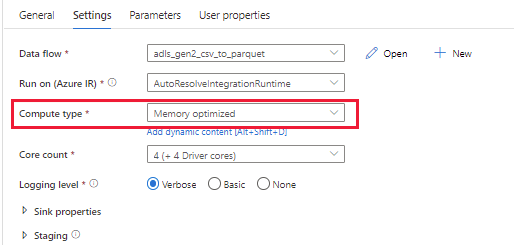
Option-2: Use larger cluster size (for example, 48 cores) to run your data flow pipelines. You can learn more about cluster size through this document: Cluster size.
Option-3: Repartition your input data. For the task running on the data flow spark cluster, one partition is one task and runs on one node. If data in one partition is too large, the related task running on the node needs to consume more memory than the node itself, which causes failure. So you can use repartition to avoid data skew, and ensure that data size in each partition is average while the memory consumption isn't too heavy.
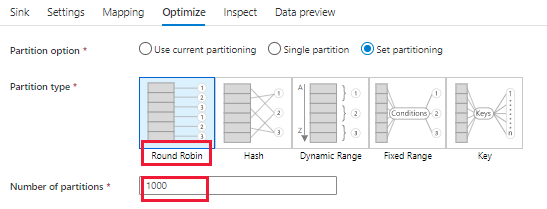
Note
You need to evaluate the data size or the partition number of input data, then set reasonable partition number under "Optimize". For example, the cluster that you use in the data flow pipeline execution is 8 cores and the memory of each core is 20GB, but the input data is 1000GB with 10 partitions. If you directly run the data flow, it will meet the OOM issue because 1000GB/10 > 20GB, so it is better to set repartition number to 100 (1000GB/100 < 20GB).
Option-4: Tune and optimize source/sink/transformation settings. For example, try to copy all files in one container, and don't use the wildcard pattern. For more detailed information, reference Mapping data flows performance and tuning guide.
Error code: DF-Executor-SourceInvalidPayload
- Message: Data preview, debug, and pipeline data flow execution failed because container does not exist.
- Cause: A dataset contains a container that doesn't exist in storage.
- Recommendation: Make sure that the container referenced in your dataset exists and can be accessed.
Error code: DF-Executor-StoreIsNotDefined
- Message: The store configuration isn't defined. This error can be caused by invalid parameter assignment in the pipeline.
- Cause: Invalid store configuration is provided.
- Recommendation: Check the parameter value assignment in the pipeline. A parameter expression may contain invalid characters.
Error code: DF-Executor-StringValueNotInQuotes
- Message: Column operands are not allowed in literal expressions.
- Cause: The value for a string parameter or an expected string value isn't enclosed in single quotes.
- Recommendation: Near the mentioned line numbers in the data flow script, ensure the value for a string parameter or an expected string value is enclosed in single quotes.
Error code: DF-Executor-SystemImplicitCartesian
- Message: Implicit cartesian product for INNER join isn't supported. Use CROSS JOIN instead. Columns used in join should create a unique key for rows.
- Cause: Implicit cartesian products for INNER joins between logical plans aren't supported. If you're using columns in the join, create a unique key.
- Recommendation: For non-equality based joins, use CROSS JOIN.
Error code: DF-Executor-SystemInvalidJson
- Message: JSON parsing error, unsupported encoding or multiline
- Cause: Possible problems with the JSON file: unsupported encoding, corrupt bytes, or using JSON source as a single document on many nested lines.
- Recommendation: Verify that the JSON file's encoding is supported. On the source transformation that's using a JSON dataset, expand JSON Settings and turn on Single Document.
Error code: DF-Executor-UnauthorizedStorageAccess
Cause: You are not permitted to access the storage account either due to missing roles for managed identity/service principal authentication or network firewall settings.
Recommendation: When using managed identity/service principal authentication,
- For source: In Storage Explorer, grant the managed identity/service principal at least Execute permission for ALL upstream folders and the file system, along with Read permission for the files to copy. Alternatively, in Access control (IAM), grant the managed identity/service principal at least the Storage Blob Data Reader role.
- For sink: In Storage Explorer, grant the managed identity/service principal at least Execute permission for ALL upstream folders and the file system, along with Write permission for the sink folder. Alternatively, in Access control (IAM), grant the managed identity/service principal at least the Storage Blob Data Contributor role.
Also ensure that the network firewall settings in the storage account are configured correctly, as turning on firewall rules for your storage account blocks incoming requests for data by default, unless the requests originate from a service operating within an Azure Virtual Network (VNet) or from allowed public IP addresses.
Error code: DF-Executor-UnreachableStorageAccount
- Message: System is not able to resolve the IP address of the host. Please verify that your host name is correct or check if your DNS server is able to resolve the host to an IP address successfully
- Cause: Unable to reach the given storage account.
- Recommendation: Check the name of the storage account and make sure the storage account exists.
Error code: DF-Executor-UserError
- Message: Job Failed due to reason: GetjobStatus, Job Failed - com.microsoft.dataflow.issues: DF-MICROSOFT365-CONSENTPENDING
- Cause: Privileged access approval is needed to copy data. It's a user configuration issue.
- Recommendation: Ask the tenant admin to approve your Data Access Request in Office365 in privileged access management (PAM) module.
Error code: DF-Executor-DSLParseError
- Message: Data flow script cannot be parsed.
- Cause: The data flow script has parsing errors.
- Recommendation: Check for errors (example: missing symbols, unwanted symbols) near mentioned line numbers in the data flow script.
Error code: DF-Executor-IncorrectQuery
- Message: Incorrect syntax. SQL Server error encountered while reading from the given table or while executing the given query.
- Cause: The query submitted was syntactically incorrect.
- Recommendation: Check the syntactical correctness of the given query. Ensure to have a non-quoted query string when it is referenced as a pipeline parameter.
Error code: DF-Executor-ParameterParseError
- Message: Parameter stream has parsing errors. Not honoring the datatype of parameters could be one of the causes.
- Cause: Parsing errors in given parameters.
- Recommendation: Check the parameters having errors, ensure the usage of appropriate functions, and honor the datatypes given.
Error code: DF-File-InvalidSparkFolder
- Message: Failed to read footer for file.
- Cause: Folder _spark_metadata is created by the structured streaming job.
- Recommendation: Delete _spark_metadata folder if it exists.
Error code: DF-GEN2-InvalidAccountConfiguration
- Message: Either one of account key or SAS token or tenant/spnId/spnCredential/spnCredentialType or userAuth or miServiceUri/miServiceToken should be specified.
- Cause: An invalid credential is provided in the Azure Data Lake Storage (ADLS) Gen2 linked service.
- Recommendation: Update the ADLS Gen2 linked service to have the right credential configuration.
Error code: DF-GEN2-InvalidAuthConfiguration
- Message: Only one of the three auth methods (Key, ServicePrincipal and MI) can be specified.
- Cause: Invalid auth method is provided in ADLS gen2 linked service.
- Recommendation: Update the ADLS Gen2 linked service to have one of three authentication methods that are Key, ServicePrincipal and MI.
Error code: DF-GEN2-InvalidCloudType
- Message: Cloud type is invalid.
- Cause: An invalid cloud type is provided.
- Recommendation: Check the cloud type in your related ADLS Gen2 linked service.
Error code: DF-GEN2-InvalidServicePrincipalCredentialType
- Message: Service principal credential type is invalid.
- Cause: The service principal credential type is invalid.
- Recommendation: Update the ADLS Gen2 linked service to set the right service principal credential type.
Error code: DF-GEN2-InvalidStorageAccountConfiguration
- Message: Blob operation is not supported on older storage accounts. Creating a new storage account may fix the issue.
- Cause: The storage account is too old.
- Recommendation: Create a new storage account.
Error code: DF-Github-WriteNotSupported
- Message: GitHub store does not allow writes.
- Cause: The GitHub store is read only.
- Recommendation: The store entity definition is in some other place.
Error code: DF-Hive-InvalidBlobStagingConfiguration
- Message: Blob storage staging properties should be specified.
- Cause: An invalid staging configuration is provided in the Hive.
- Recommendation: Check if the account key, account name and container are set properly in the related Blob linked service, which is used as staging.
Error code: DF-Hive-InvalidDataType
- Message: Unsupported Columns.
- Cause: Unsupported Columns are provided.
- Recommendation: Update the column of input data to match the data type supported by the Hive.
Error code: DF-Hive-InvalidGen2StagingConfiguration
Message: ADLS Gen2 storage staging only support service principal key credential.
Cause: An invalid staging configuration is provided in the Hive.
Recommendation: Update the related ADLS Gen2 linked service that is used as staging. Currently, only the service principal key credential is supported.
Message: ADLS Gen2 storage staging properties should be specified. Either one of key or tenant/spnId/spn Credential/spnCredentialType or miServiceUri/miServiceToken is required.
Cause: An invalid staging configuration is provided in the Hive.
Recommendation: Update the related ADLS Gen2 linked service with right credentials that are used as staging in the Hive.
Error code: DF-Hive-InvalidStorageType
- Message: Storage type can either be blob or gen2.
- Cause: Only Azure Blob or ADLS Gen2 storage type is supported.
- Recommendation: Choose the right storage type from Azure Blob or ADLS Gen2.
Error code: DF-JSON-WrongDocumentForm
- Message: Malformed records are detected in schema inference. Parse Mode: FAILFAST. It could be because of a wrong selection in document form to parse json files. Please try a different 'Document form' (Single document/Document per line/Array of documents) on the json source.
- Cause: Wrong document form is selected to parse JSON files.
- Recommendation: Try different Document form (Single document/Document per line/Array of documents) in JSON settings. Most cases of parsing errors are caused by wrong configuration.
Error code: DF-MICROSOFT365-CONSENTPENDING
- Message: Admin Consent is pending.
- Cause: Admin Consent is missing.
- Recommendation: Provide the consent and then rerun the pipeline. To provide consent, refer to PAM requests.
Error code: DF-MSSQL-ErrorRowsFound
- Cause: Error/Invalid rows were found while writing to Azure SQL Database sink.
- Recommendation: Find the error rows in the rejected data storage location if configured.
Error code: DF-MSSQL-ExportErrorRowFailed
- Message: Exception is happened while writing error rows to storage.
- Cause: An exception happened while writing error rows to the storage.
- Recommendation: Check your rejected data linked service configuration.
Error code: DF-MSSQL-InvalidAuthConfiguration
- Message: Only one of the three auth methods (Key, ServicePrincipal, and MI) can be specified.
- Cause: An invalid authentication method is provided in the MSSQL linked service.
- Recommendation: You can only specify one of the three authentication methods (Key, ServicePrincipal and MI) in the related MSSQL linked service.
Error code: DF-MSSQL-InvalidCloudType
- Message: Cloud type is invalid.
- Cause: An invalid cloud type is provided.
- Recommendation: Check your cloud type in the related MSSQL linked service.
Error code: DF-MSSQL-InvalidCredential
- Message: Either one of user/pwd or tenant/spnId/spnKey or miServiceUri/miServiceToken should be specified.
- Cause: An invalid credential is provided in the MSSQL linked service.
- Recommendation: Update the related MSSQL linked service with right credentials, and one of user/pwd or tenant/spnId/spnKey or miServiceUri/miServiceToken should be specified.
Error code: DF-MSSQL-InvalidDataType
- Message: Unsupported fields.
- Cause: Unsupported fields are provided.
- Recommendation: Modify the input data column to match the data type supported by MSSQL.
Error code: DF-MSSQL-InvalidFirewallSetting
- Message: The TCP/IP connection to the host has failed. Make sure that an instance of SQL Server is running on the host and accepting TCP/IP connections at the port. Make sure that TCP connections to the port are not blocked by a firewall.
- Cause: The SQL database's firewall setting blocks the data flow to access.
- Recommendation: Check the firewall setting for your SQL database, and allow Azure services and resources to access this server.
Error code: DF-MSSQL-InvalidCertificate
- Message: SQL server configuration error, please either install a trusted certificate on your server or change 'encrypt' connection string setting to false and 'trustServerCertificate' connection string setting to true.
- Cause: SQL server configuration error.
- Recommendations: Install a trusted certificate on your SQL server, or change
encryptconnection string setting to false andtrustServerCertificateconnection string setting to true.
Error code: DF-PGSQL-InvalidCredential
- Message: User/password should be specified.
- Cause: The User/password is missed.
- Recommendation: Make sure that you have right credential settings in the related PostgreSQL linked service.
Error code: DF-SAPODATA-InvalidRunMode
- Message: Failed to execute dataflow with invalid run mode.
- Cause: Possible causes are:
- Only the read mode
fullLoadcan be specified whenenableCdcis false. - Only the run modes
incrementalLoadorfullAndIncrementalLoadcan be specified whenenableCdcis true. - Only
fullLoad,incrementalLoadorfullAndIncrementalLoadcan be specified.
- Only the read mode
- Recommendation: Reconfigure the activity and run again. If the issue persists, contact Microsoft support for further assistance.
Error code: DF-SAPODATA-StageLinkedServiceMissed
- Message: Failed to execute dataflow when Staging Linked Service is not existed in DSL. Please reconfigure the activity and run again. If issue persists, please contact Microsoft support for further assistance.
- Cause: The staging linked service doesn't exist in DSL.
- Recommendation: Reconfigure the activity and run again. If the issue persists, contact Microsoft support for further assistance.
Error code: DF-SAPOODATA-StageContainerMissed
- Message: Container or file system is required for staging storage.
- Cause: No container or file system is specified for the staging storage.
- Recommendation: Specify the container and file system for your staging storage.
Error code: DF-SAPODATA-StageFolderPathMissed
- Message: Folder path is required for staging storage.
- Cause: No folder path is specified for the staging storage.
- Recommendation: Specify the folder path for the staging storage.
Error code: DF-SAPODATA-ODataServiceOrEntityMissed
- Message: Both SAP servicePath and entityName are required in import-schema, preview-data and read data operation.
- Cause: Service path and Entity name can't be null when importing schema, previewing data or reading data.
- Recommendation: Specify the Service path and Entity name when importing schema, previewing data or reading data.
Error code: DF-SAPODATA-TimeoutInvalid
- Message: Timeout is invalid, it should be no more than 7 days.
- Cause: The timeout can't exceed 7 days.
- Recommendation: Specify the valid timeout.
Error code: DF-SAPODATA-ODataServiceMissed
- Message: SAP servicePath is required when browsing entity name.
- Cause: The Service path can't be null when browsing the entity name.
- Recommendation: Specify the Service path.
Error code: DF-SAPODATA-SystemError
- Message: System Error: Failed to get deltaToken from SAP. Please contact Microsoft support for further assistance.
- Cause: Failed to get the delta token from SAP.
- Recommendation: Contact Microsoft support for further assistance.
Error code: DF-SAPODATA-StageAuthInvalid
- Message: Invalid client secret provided
- Cause: The service principal credential of the staging storage is incorrect.
- Recommendation: Test connection in your staging storage linked service, and confirm that the authentication settings in your staging storage are correct.
Error code: DF-SAPODATA-NotReached
Causes and recommendations: Failed to create OData connection to the request URL. Different causes may lead to this issue. Check the list below for possible causes and related recommendations.
Cause analysis Recommendation Your SAP server is shut down. Check if your SAP server is started. Self-hosted integration runtime proxy issue. Check your self-hosted integration runtime proxy. Incorrect parameters input (for example, wrong SAP server name or password) Check your input parameters: SAP server name, password.
Error code: DF-SAPODATA-NoneODPService
- Message: Current odata service doesn't support extracting ODP data, please enable ODP for the service
- Cause: The current OData service doesn't support extracting ODP data.
- Recommendation: Enable ODP for the service.
Error code: DF-SAPODP-AuthInvalid
- Message: SapOdp Name or Password incorrect
- Cause: Your input name or password is incorrect.
- Recommendation: Confirm your input name or password is correct.
Error code: DF-SAPODP-ContextInvalid
- Cause: The context value doesn't exist in SAP OPD.
- Recommendation: Check the context value and make sure it's valid.
Error code: DF-SAPODP-ContextMissed
Message: Context is required
Causes and recommendations: Different causes may lead to this error. Check below list for possible cause analysis and related recommendation.
Cause analysis Recommendation Your context value can't be empty when reading data. Specify the context. Your context value can't be empty when browsing object names. Specify the context.
Error code: DF-SAPODP-DataflowSystemError
- Recommendation: Reconfigure the activity and run it again. If the issue persists, you can contact Microsoft support for further assistance.
Error code: DF-SAPODP-DataParsingFailed
- Cause: Mostly you have hidden column settings in your SAP table. When you use SAP mapping data flow to read data from SAP server, it returns all the schema (columns, including hidden ones), but returned data do not contain related values. So, data misalignment happened and led to parse value issue or wrong data value issue.
- Recommendation: There are two recommendations for this issue:
- Remove hidden settings from the related columns through the SAP user interface.
- If you want to keep existed SAP settings unchanged, use hidden feature (manually add DSL property
enableProjection:truein script) in SAP mapping data flow to filter the hidden columns and continue to read data.
Error code: DF-SAPODP-ObjectInvalid
- Cause: The object name isn't found or not released.
- Recommendation: Check the object name and make sure it is valid and already released.
Error code: DF-SAPODP-ObjectNameMissed
- Message: 'objectName' (SAP object name) is required
- Cause: Object names must be defined when reading data from SAP ODP.
- Recommendation: Specify the SAP ODP object name.
Error code: DF-SAPODP-SAPSystemError
- Cause: This is an SAP system error:
user id locked. - Recommendation: Contact SAP admin for assistance.
Error code: DF-SAPODP-SessionTerminate
- Message: Internal session terminated with a runtime error RAISE_EXCEPTION (see ST22)
- Cause: Transient issues for SLT objects.
- Recommendation: Rerun the data flow activity.
Error code: DF-SAPODP-SHIROFFLINE
- Cause: Your self-hosted integration runtime is offline.
- Recommendation: Check your self-hosted integration runtime status and confirm it's online.
Error code: DF-SAPODP-SLT-LIMITATION
- Message: Preview is not supported in SLT system
- Cause: Your context or object is in SLT system that doesn't support preview. This is an SAP ODP SLT system limitation.
- Recommendation: Directly run the data flow activity.
Error code: DF-SAPODP-StageAuthInvalid
- Message: Invalid client secret provided
- Cause: The service principal certificate credential of the staging storage isn't correct.
- Recommendation: Check whether the test connection is successful in your staging storage linked service, and confirm the authentication setting of your staging storage is correct.
- Message: Failed to authenticate the request to storage
- Cause: The key of your staging storage isn't correct.
- Recommendation: Check whether the test connection is successful in your staging storage linked service, and confirm the key of your staging Azure Blob Storage is correct.
Error code: DF-SAPODP-StageBlobPropertyInvalid
- Message: Read from staging storage failed: Staging blob storage auth properties not valid.
- Cause: Staging Blob storage properties aren't valid.
- Recommendation: Check the authentication setting in your staging linked service.
Error code: DF-SAPODP-StageContainerInvalid
- Message: Unable to create Azure Blob container
- Cause: The input container doesn't exist in your staging storage.
- Recommendation: Input a valid container name for the staging storage. Reselect another existed container name or create a new container manually with your input name.
Error code: DF-SAPODP-StageContainerMissed
- Message: Container or file system is required for staging storage.
- Cause: Your container or file system isn't specified for staging storage.
- Recommendation: Specify the container or file system for the staging storage.
Error code: DF-SAPODP-StageFolderPathMissed
- Message: Folder path is required for staging storage
- Cause: Your staging storage folder path isn't specified.
- Recommendation: Specify the staging storage folder.
Error code: DF-SAPODP-StageGen2PropertyInvalid
- Message: Read from staging storage failed: Staging Gen2 storage auth properties not valid.
- Cause: Authentication properties of your staging Azure Data Lake Storage Gen2 aren't valid.
- Recommendation: Check the authentication setting in your staging linked service.
Error code: DF-SAPODP-StageStorageServicePrincipalCertNotSupport
- Message: Read from staging storage failed: Staging storage auth doesn't support service principal cert.
- Cause: The service principal certificate credential isn't supported for the staging storage.
- Recommendation: Change your authentication to not use the service principal certificate credential.
Error code: DF-SAPODP-StageStorageTypeInvalid
- Message: Your staging storage type of SapOdp is invalid
- Cause: Only Azure Blob Storage and Azure Data Lake Storage Gen2 are supported for SAP ODP staging.
- Recommendation: Select Azure Blob Storage or Azure Data Lake Storage Gen2 as your staging storage.
Error code: DF-SAPODP-SubscriberNameMissed
- Message: 'subscriberName' is required while option 'enable change data capture' is selected
- Cause: The SAP linked service property
subscriberNameis required while option 'enable change data capture' is selected. - Recommendation: Specify the
subscriberNamein SAP ODP linked service.
Error code: DF-SAPODP-SystemError
- Cause: This error is a data flow system error or SAP server system error.
- Recommendation: Check the error message. If it contains SAP server related error stacktrace, contact SAP admin for assistance. Otherwise, contact Microsoft support for further assistance.
Error code: DF-SAPODP-NotReached
Message: partner '.*' not reached
Causes and recommendations: This is a connectivity issue. Different causes may lead to this issue. Check below list for possible cause analysis and related recommendation.
Cause analysis Recommendation Your SAP server is shut down. Check your SAP server is started. Your IP or port of the self-hosted integration runtime isn't in SAP network security rule. Check your IP or port of self-hosted integration runtime is in your SAP network security rule. Self-hosted integration runtime proxy issue. Check your self-hosted integration runtime proxy. Incorrect parameters input (e.g. wrong SAP server name or IP). Check your input parameters: SAP server name, IP.
Error code: DF-SAPODP-DependencyNotFound
- Message: Could not load file or assembly 'sapnco, Version=*
- Cause: You don't download and install SAP .NET connector on the machine of the self-hosted integration runtime.
- Recommendation: Follow Set up a self-hosted integration runtime to set up the self-hosted integration runtime for the SAP Change Data Capture (CDC) connector.
Error code: DF-SAPODP-NoAuthForFunctionModule
- Message: No REF authorization for function module RODPS_REPL_CONTEXT_GET_LIST
- Cause: Lack of authorization to execute the related function module.
- Recommendation: Follow this SAP notes to add the required authorization profile to your SAP account.
Error code: DF-SAPODP-OOM
- Message: No more memory available to add rows to an internal table
- Cause: SAP Table connector has its limitation for big table extraction. SAP Table underlying relies on an RFC which will read all the data from the table into the memory of SAP system, so out of memory (OOM) issue will happen when extracting big tables.
- Recommendation: Use SAP CDC connector to do full load directly from your source system, then move delta to SAP Landscape Transformation Replication Server (SLT) after init without delta is released.
Error code: DF-SAPODP-SourceNotSupportDelta
- Message: Source .* does not support deltas
- Cause: The ODP context/ODP name you specified doesn't support delta.
- Recommendation: Enable delta mode for your SAP source, or select Full on every run as run mode in data flow. For more information, see this document.
Error code: DF-SAPODP-SAPI-LIMITATION
- Message: Error Number 518, Source .* not found, not released or not authorized
- Cause: Check if your context is the SAP Service API (SAPI). If so, in SAPI context, you can only extract the relevant extractors for SAP tables.
- Recommendations: Refer to this document.
Error code: DF-SAPODP-KeyColumnsNotSpecified
- Message: Key columns should be specified for non-insertable operations (updates/deletes)
- Cause: This error occurs when you skip selecting Key Columns in the sink table.
- Recommendations: Allowing delete, upsert and update options requires a key column to be specified. Specify one or more columns for the row matching in sink.
Error code: DF-SAPODP-InsufficientResource
- Message: A short dump has occurred in a database operation
- Cause: SAP system ran out of resources, which resulted in short dump in SAP server.
- Recommendations: Contact your SAP administrator to address the problem in SAP instance and retry.
Error code: DF-SAPODP-ExecuteFuncModuleWithPointerFailed
- Message: Execute function module .* with pointer .* failed
- Cause: SAP system issue.
- Recommendations: Go to SAP instance, and check ST22 (short dump, similar to windows dump) and review the code where the error happened. In most cases, SAP offers hints on various possibilities for further troubleshooting.
Error code: DF-Snowflake-IncompatibleDataType
- Message: Expression type does not match column data type, expecting VARIANT but got VARCHAR.
- Cause: The column's type of input data which is string is different from the related column's type in the Snowflake sink transformation which is VARIANT.
- Recommendation: For the snowflake VARIANT, it can only accept data flow value which is struct, map or array type. If the value of your input data columns is JSON or XML or other string, use a parse transformation before the Snowflake sink transformation to covert value into struct, map or array type.
Error code: DF-Snowflake-InvalidDataType
- Message: The spark type is not supported in snowflake.
- Cause: An invalid data type is provided in the Snowflake.
- Recommendation: Use the derive transformation before applying the Snowflake sink to update the related column of the input data into the string type.
Error code: DF-Snowflake-InvalidStageConfiguration
Message: Only blob storage type can be used as stage in snowflake read/write operation.
Cause: An invalid staging configuration is provided in the Snowflake.
Recommendation: Update Snowflake staging settings to ensure that only Azure Blob linked service is used.
Message: Snowflake stage properties should be specified with Azure Blob + SAS authentication.
Cause: An invalid staging configuration is provided in the Snowflake.
Recommendation: Ensure that only the Azure Blob + SAS authentication is specified in the Snowflake staging settings.
Error code: DF-SQLDW-ErrorRowsFound
- Cause: Error/invalid rows are found when writing to the Azure Synapse Analytics sink.
- Recommendation: Find the error rows in the rejected data storage location if it is configured.
Error code: DF-SQLDW-ExportErrorRowFailed
- Message: Exception is happened while writing error rows to storage.
- Cause: An exception happened while writing error rows to the storage.
- Recommendation: Check your rejected data linked service configuration.
Error code: DF-SQLDW-IncorrectLinkedServiceConfiguration
- Message: The linked service is incorrectly configured as type 'Azure Synapse Analytics' instead of 'Azure SQL Database'. Please create a new linked service of type 'Azure SQL Database'
Note: Please check that the given database is of type 'Dedicated SQL pool (formerly SQL Data Warehouse)' for linked service type 'Azure Synapse Analytics'. - Cause: The linked service is incorrectly configured as type Azure Synapse Analytics instead of Azure SQL Database.
- Recommendation: Create a new linked service of type Azure SQL Database, and check that the given database is of type Dedicated SQL pool (formerly SQL DW) for linked service type Azure Synapse Analytics.
Error code: DF-SQLDW-InternalErrorUsingMSI
- Message: An internal error occurred while authenticating against Managed Service Identity in Azure Synapse Analytics instance. Please restart the Azure Synapse Analytics instance or contact Azure Synapse Analytics Dedicated SQL Pool support if this problem persists.
- Cause: An internal error occurred in Azure Synapse Analytics.
- Recommendation: Restart the Azure Synapse Analytics instance or contact Azure Synapse Analytics Dedicated SQL Pool support if this problem persists.
Error code: DF-SQLDW-InvalidBlobStagingConfiguration
- Message: Blob storage staging properties should be specified.
- Cause: Invalid blob storage staging settings are provided
- Recommendation: Check if the Blob linked service used for staging has correct properties.
Error code: DF-SQLDW-InvalidConfiguration
- Message: ADLS Gen2 storage staging properties should be specified. Either one of key or tenant/spnId/spnCredential/spnCredentialType or miServiceUri/miServiceToken is required.
- Cause: Invalid ADLS Gen2 staging properties are provided.
- Recommendation: Update ADLS Gen2 storage staging settings to have one of key or tenant/spnId/spnCredential/spnCredentialType or miServiceUri/miServiceToken.
Error code: DF-SQLDW-InvalidGen2StagingConfiguration
- Message: ADLS Gen2 storage staging only support service principal key credential.
- Cause: An invalid credential is provided for the ADLS gen2 storage staging.
- Recommendation: Use the service principal key credential of the Gen2 linked service used for staging.
Error code: DF-SQLDW-InvalidStorageType
- Message: Storage type can either be blob or gen2.
- Cause: An invalid storage type is provided for staging.
- Recommendation: Check the storage type of the linked service used for staging and make sure that it's Blob or Gen2.
Error code: DF-SQLDW-StagingStorageNotSupport
- Message: Staging Storage with partition DNS enabled is not supported if enable staging. Please uncheck enable staging in sink using Synapse Analytics.
- Cause: Staging storage with partition DNS enabled isn't supported if you enable staging.
- Recommendations: Uncheck Enable staging in sink when using Azure Synapse Analytics.
Error code: DF-SQLDW-DataTruncation
- Message: Your target table has a column with (n)varchar or (n)varbinary type that has a smaller column length limitation than real data, please either adjust the column definition in your target table or change the source data.
- Cause: Your target table has a column with varchar or varbinary type that has a smaller column length limitation than real data.
- Recommendations: Adjust the column definition in your target table or change the source data.
Error code: DF-Synapse-DBNotExist
- Cause: The database doesn't exist.
- Recommendation: Check if the database exists.
Error code: DF-Synapse-InvalidDatabaseType
- Message: Database type is not supported.
- Cause: The database type isn't supported.
- Recommendation: Check the database type and change it to the proper one.
Error code: DF-Synapse-InvalidFormat
- Message: Format is not supported.
- Cause: The format isn't supported.
- Recommendation: Check the format and change it to the proper one.
Error code: DF-Synapse-InvalidOperation
- Cause: The operation isn't supported.
- Recommendation: Change Update method configuration as delete, update and upsert are not supported in Workspace DB.
Error code: DF-Synapse-InvalidTableDBName
- Message: The table/database name is not a valid name for tables/databases. Valid names only contain alphabet characters, numbers and _.
- Cause: The table/database name isn't valid.
- Recommendation: Change a valid name for the table/database. Valid names only contain alphabet characters, numbers and
_.
Error code: DF-Synapse-StoredProcedureNotSupported
- Message: Use 'Stored procedure' as Source is not supported for serverless (on-demand) pool.
- Cause: The serverless pool has limitations.
- Recommendation: Retry using 'query' as the source or saving the stored procedure as a view, and then use 'table' as the source to read from view directly.
Error code: DF-Xml-InvalidDataField
- Message: The field for corrupt records must be string type and nullable.
- Cause: An invalid data type of the column
\"_corrupt_record\"is provided in the XML source. - Recommendation: Make sure that the column
\"_corrupt_record\"in the XML source has a string data type and nullable.
Error code: DF-Xml-InvalidElement
- Message: XML Element has sub elements or attributes which can't be converted.
- Cause: The XML element has sub elements or attributes which can't be converted.
- Recommendation: Update the XML file to make the XML element has right sub elements or attributes.
Error code: DF-Xml-InvalidReferenceResource
- Message: Reference resource in xml data file cannot be resolved.
- Cause: The reference resource in the XML data file can't be resolved.
- Recommendation: Check the reference resource in the XML data file.
Error code: DF-Xml-InvalidSchema
- Message: Schema validation failed.
- Cause: The invalid schema is provided on the XML source.
- Recommendation: Check the schema settings on the XML source to make sure that it's the subset schema of the source data.
Error code: DF-Xml-InvalidValidationMode
- Message: Invalid xml validation mode is provided.
- Cause: An invalid XML validation mode is provided.
- Recommendation: Check the parameter value and specify the right validation mode.
Error code: DF-Xml-MalformedFile
- Message: Malformed xml with path in FAILFAST mode.
- Cause: Malformed XML with path exists in the FAILFAST mode.
- Recommendation: Update the content of the XML file to the right format.
Error code: DF-Xml-UnsupportedExternalReferenceResource
- Message: External reference resource in xml data file is not supported.
- Cause: The external reference resource in the XML data file isn't supported.
- Recommendation: Update the XML file content when the external reference resource isn't supported now.
Error code: GetCommand OutputAsync failed
- Message: During Data Flow debug and data preview: GetCommand OutputAsync failed with ...
- Cause: This error is a back-end service error.
- Recommendation: Retry the operation and restart your debugging session. If retrying and restarting doesn't resolve the problem, contact customer support.
Error code: InvalidTemplate
- Message: The pipeline expression cannot be evaluated.
- Cause: The pipeline expression passed in the Data Flow activity isn't being processed correctly because of a syntax error.
- Recommendation: Check data flow activity name. Check expressions in activity monitoring to verify the expressions. For example, data flow activity name can't have a space or a hyphen.
Error code: 127
- Message: The spark job of Dataflow completed, but the runtime state is either null or still InProgress..
- Cause: Transient issue with microservices involved in the execution can cause the run to fail.
- Recommendation: Refer to scenario 3 transient issues.
Error code: 2011
- Message: The activity was running on Azure Integration Runtime and failed to decrypt the credential of data store or compute connected via a Self-hosted Integration Runtime. Please check the configuration of linked services associated with this activity, and make sure to use the proper integration runtime type.
- Cause: Data flow doesn't support linked services on self-hosted integration runtimes.
- Recommendation: Configure data flow to run on a Managed Virtual Network integration runtime.
Error code: 4502
- Message: There are substantial concurrent MappingDataflow executions that are causing failures due to throttling under Integration Runtime.
- Cause: A large number of Data Flow activity runs are occurring concurrently on the integration runtime. For more information, see Azure Data Factory limits.
- Recommendation: If you want to run more Data Flow activities in parallel, distribute them across multiple integration runtimes.
Error code: 4503
- Message: There are substantial concurrent MappingDataflow executions which is causing failures due to throttling under subscription '%subscriptionId;', ActivityId: '%activityId;'.
- Cause: Throttling threshold was reached.
- Recommendation: Retry the request after a wait period.
Error code: 4506
- Message: Failed to provision cluster for '%activityId;' because the request computer exceeds the maximum concurrent count of 200. Integration Runtime '%IRName;'
- Cause: Transient error
- Recommendation: Retry the request after a wait period.
Error code: 4507
- Message: Unsupported compute type and/or core count value.
- Cause: Unsupported compute type and/or core count value was provided.
- Recommendation: Use one of the supported compute type and/or core count values given on this document.
Error code: 4508
- Message: Spark cluster not found.
- Recommendation: Restart the debug session.
Error code: 4509
- Message: Hit unexpected failure while allocating compute resources, please retry. If the problem persists, please contact Azure Support
- Cause: Transient error
- Recommendation: Retry the request after a wait period.
Error code: 4510
- Message: Unexpected failure during execution.
- Cause: Since debug clusters work differently from job clusters, excessive debug runs could wear the cluster over time, which could cause memory issues and abrupt restarts.
- Recommendation: Restart Debug cluster. If you are running multiple dataflows during debug session, use activity runs instead because activity level run creates separate session without taxing main debug cluster.
Error code: 4511
- Message: java.sql.SQLTransactionRollbackException. Deadlock found when trying to get lock; try restarting transaction. If the problem persists, please contact Azure Support
- Cause: Transient error
- Recommendation: Retry the request after a wait period.
Error code: SystemErrorSynapseSparkJobFailed (Ongoing)
- Message: Job failed during run time with state=[dead]. Credentials were not provided for the WASB URI.
- Cause: Data flow is unsupported in Synapse workspaces using Spark version 3.4 when DEP (Data Exfiltration Protection) is enabled by selecting "Allow outbound data traffic only to approved targets" during workspace network configuration.
- Recommendation: Disable the above settings during workspace creation. For more information, see this document
Miscellaneous troubleshooting tips
Issue: Unexpected exception occurred and execution failed.
- Message: During Data Flow activity execution: Hit unexpected exception and execution failed.
- Cause: This error is a back-end service error. Retry the operation and restart your debugging session.
- Recommendation: If retrying and restarting doesn't resolve the problem, contact customer support.
Issue: No output data on join during debug data preview.
- Message: There are a high number of null values or missing values which may be caused by having too few rows sampled. Try updating the debug row limit and refreshing the data.
- Cause: The join condition either didn't match any rows or resulted in a large number of null values during the data preview.
- Recommendation: In Debug Settings, increase the number of rows in the source row limit. Be sure to select an Azure IR that has a data flow cluster that's large enough to handle more data.
Issue: Validation error at source with multiline CSV files.
- Message: You might see one of these error messages:
- The last column is null or missing.
- Schema validation at source fails.
- Schema import fails to show correctly in the UX and the last column has a new line character in the name.
- Cause: In the Mapping data flow, multiline CSV source files don't currently work when \r\n is used as the row delimiter. Sometimes extra lines at carriage returns can cause errors.
- Recommendation: Generate the file at the source by using \n as the row delimiter rather than \r\n. Or use the Copy activity to convert the CSV file to use \n as a row delimiter.
- Message: You might see one of these error messages:
Improvement on CSV/CDM format in Data Flow
If you use the Delimited Text or CDM formatting for mapping data flow in Azure Data Factory V2, you may face the behavior changes to your existing pipelines because of the improvement for Delimited Text/CDM in data flow starting from 1 May 2021.
You may encounter the following issues before the improvement, but after the improvement, the issues were fixed. Read the following content to determine whether this improvement affects you.
Scenario 1: Encounter the unexpected row delimiter issue
You are affected if you are in the following conditions:
- Using the Delimited Text with the Multiline setting set to True or CDM as the source.
- The first row has more than 128 characters.
- The row delimiter in data files isn't
\n.
Before the improvement, the default row delimiter \n may be unexpectedly used to parse delimited text files, because when Multiline setting is set to True, it invalidates the row delimiter setting, and the row delimiter is automatically detected based on the first 128 characters. If you fail to detect the actual row delimiter, it would fall back to \n.
After the improvement, any one of the three-row delimiters: \r, \n, \r\n should have worked.
The following example shows you one pipeline behavior change after the improvement:
Example:
For the following column:
C1, C2, {long first row}, C128\r\n
V1, V2, {values………………….}, V128\r\n
Before the improvement, \r is kept in the column value. The parsed column result is:
C1 C2 {long first row} C128\r
V1 V2 {values………………….} V128\r
After the improvement, the parsed column result should be:
C1 C2 {long first row} C128
V1 V2 {values………………….} V128
Scenario 2: Encounter an issue of incorrectly reading column values containing '\r\n'
You are affected if you are in the following conditions:
- Using the Delimited Text with the Multiline setting set to True or CDM as a source.
- The row delimiter is
\r\n.
Before the improvement, when reading the column value, the \r\n in it may be incorrectly replaced by \n.
After the improvement, \r\n in the column value will not be replaced by \n.
The following example shows you one pipeline behavior change after the improvement:
Example:
For the following column:
"A\r\n", B, C\r\n
Before the improvement, the parsed column result is:
A\n B C
After the improvement, the parsed column result should be:
A\r\n B C
Scenario 3: Encounter an issue of incorrectly writing column values containing '\n'
You are affected if you are in the following conditions:
- Using the Delimited Text as a sink.
- The column value contains
\n. - The row delimiter is set to
\r\n.
Before the improvement, when writing the column value, the \n in it may be incorrectly replaced by \r\n.
After the improvement, \n in the column value will not be replaced by \r\n.
The following example shows you one pipeline behavior change after the improvement:
Example:
For the following column:
A\n B C
Before the improvement, the CSV sink is:
"A\r\n", B, C\r\n
After the improvement, the CSV sink should be:
"A\n", B, C\r\n
Scenario 4: Encounter an issue of incorrectly reading empty string as NULL
You are affected if you are in the following conditions:
- Using the Delimited Text as a source.
- NULL value is set to non-empty value.
- The column value is empty string and is unquoted.
Before the improvement, the column value of unquoted empty string is read as NULL.
After the improvement, empty string will not be parsed as NULL value.
The following example shows you one pipeline behavior change after the improvement:
Example:
For the following column:
A, ,B,
Before the improvement, the parsed column result is:
A null B null
After the improvement, the parsed column result should be:
A "" (empty string) B "" (empty string)
Related content
For more help with troubleshooting, see these resources: