How to convert a SEG-Y file to ZGY
In this article, you learn how to convert SEG-Y formatted data to the ZGY format. Seismic data stored in industry standard SEG-Y format can be converted to ZGY for use in applications such as Petrel via the Seismic DMS. See here for ZGY Conversion FAQ's and more background can be found in the OSDU™ community here: SEG-Y to ZGY conversation. This tutorial is a step by step guideline how to perform the conversion. Note the actual production workflow may differ and use as a guide for the required set of steps to achieve the conversion.
Prerequisites
- An Azure subscription
- An instance of Azure Data Manager for Energy created in your Azure subscription.
- A SEG-Y File
- You may use any of the following files from the Volve dataset as a test. The Volve data set itself is available from Equinor.
Get your Azure Data Manager for Energy instance details
The first step is to get the following information from your Azure Data Manager for Energy instance in the Azure portal:
| Parameter | Value | Example |
|---|---|---|
| client_id | Application (client) ID | 3dbbbcc2-f28f-44b6-a5ab-xxxxxxxxxxxx |
| client_secret | Client secrets | _fl****************** |
| tenant_id | Directory (tenant) ID | 72f988bf-86f1-41af-91ab-xxxxxxxxxxxx |
| base_url | URL | https://<instance>.energy.azure.com |
| data-partition-id | Data Partition(s) | <data-partition-name> |
You use this information later in the tutorial.
Set up Postman
Next, set up Postman:
Download and install the Postman desktop app.
Import the following files in Postman:
To import the files:
- Select Import in Postman.
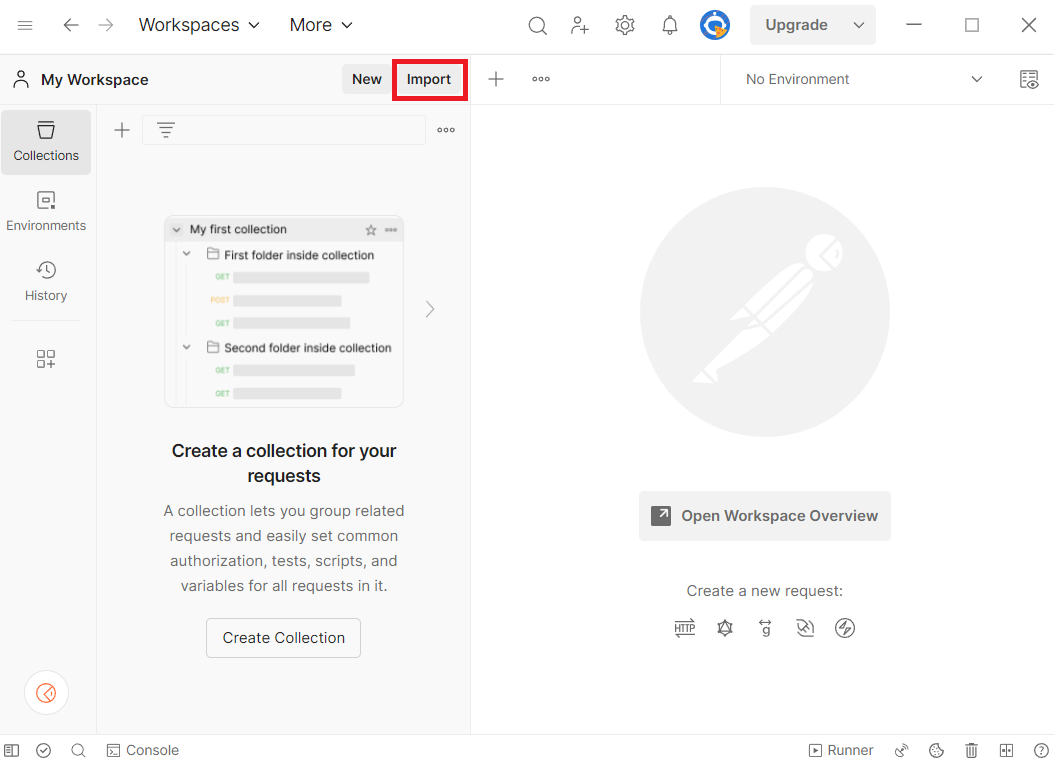
- Paste the URL of each file into the search box.
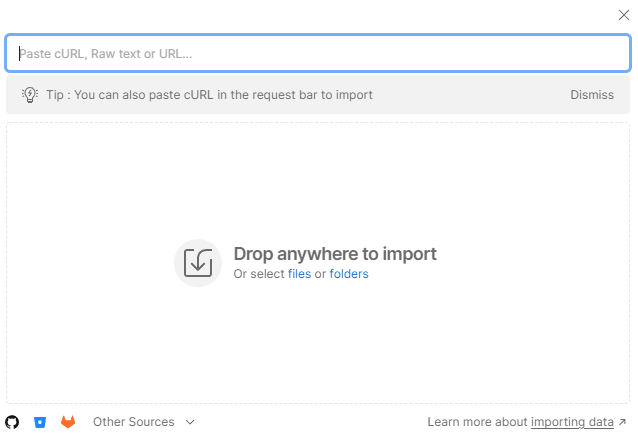
In the Postman environment, update CURRENT VALUE with the information from your Azure Data Manager for Energy instance details
In Postman, in the left menu, select Environments, and then select SEGYtoZGY Environment.
In the CURRENT VALUE column, enter the information that's described in the table in 'Get your Azure Data Manager for Energy instance details'.




Step by Step Process to convert SEG-Y file to ZGY file
The Postman collection provided has all of the sample calls to serve as a guide. You can also retrieve the equivalent cURL command for a Postman call by clicking the Code button.

Create a Legal Tag

Prepare dataset files
Prepare the metadata / manifest file / records file for the dataset. The manifest file includes:
- WorkProduct
- SeismicBinGrid
- FileCollection
- SeismicTraceData
Conversion uses a manifest file that you upload to your storage account later in order to run the conversion. This manifest file is created by using multiple JSON files and running a script. The JSON files for this process are stored here for the Volve Dataset. For more information on Volve, such as where the dataset definitions come from, visit their website. Complete the following steps in order to create the manifest file:
- Clone the repo and navigate to the folder
doc/sample-records/volve - Edit the values in the
prepare-records.shbash script. Recall that the format of the legal tag is prefixed with the Azure Data Manager for Energy instance name and data partition name, so it looks like<instancename>-<datapartitionname>-<legaltagname>.
DATA_PARTITION_ID=<your-partition-id>
ACL_OWNER=data.default.owners@<your-partition-id>.<your-tenant>.com
ACL_VIEWER=data.default.viewers@<your-partition-id>.<your-tenant>.com
LEGAL_TAG=<legal-tag-created>
- Run the
prepare-records.shscript. - The output is a JSON array with all objects and is saved in the
all_records.jsonfile. - Save the
filecollection_segy_idand thework_product_idvalues in that JSON file to use in the conversion step. That way the converter knows where to look for this contents of yourall_records.json.
Note
The all_records.json file must also contain appropriate data for each element.
Example: The following parameters are used when calculating the ZGY coordinates for SeismicBinGrid:
P6BinGridOriginEastingP6BinGridOriginIP6BinGridOriginJP6BinGridOriginNorthingP6ScaleFactorOfBinGridP6BinNodeIncrementOnIaxisP6BinNodeIncrementOnJaxisP6BinWidthOnIaxisP6BinWidthOnJaxisP6MapGridBearingOfBinGridJaxisP6TransformationMethodpersistableReferenceCrsfrom theasIngestedCoordinatesblock If theSeismicBinGridhas the P6 parameters and the CRS specified underAsIngestedCoordinates, the conversion itself should be able to complete successfully, but Petrel will not understand the survey geometry of the file unless it also gets the 5 corner points underSpatialArea,AsIngestedCoordinates,SpatialArea, andWgs84Coordinates.
User Access
The user needs to be part of the users.datalake.admins group. Validate the current entitlements for the user using the following call:

Later in this tutorial, you need at least one owner and at least one viewer. These user groups look like data.default.owners and data.default.viewers. Make sure to note one of each in your list.
If the user isn't part of the required group, you can add the required entitlement using the following sample call: email-id: Is the value "ID" returned from the call above.

If you haven't yet created entitlements groups, follow the directions as outlined in How to manage users. If you would like to see what groups you have, use Get entitlements groups for a given user. Data access isolation is achieved with this dedicated ACL (access control list) per object within a given data partition.
Prepare Subproject
1. Register Data Partition to Seismic

2. Create Subproject
Use your previously created entitlement groups that you would like to add as ACL (Access Control List) admins and viewers. Data partition entitlements don't necessarily translate to the subprojects within it, so it is important to be explicit about the ACLs for each subproject, regardless of what data partition it is in.

3. Create dataset
Note
This step is only required if you are not using sdutil for uploading the seismic files.

Upload the File
There are two ways to upload a SEGY file. One option is used the sasurl through Postman / curl call. You need to download Postman or setup Curl on your OS.
The second method is to use SDUTIL. To log in to your instance for ADME via the tool, you need to generate a refresh token for the instance. See How to generate auth token. Alternatively, you can modify the code of SDUTIL to use client credentials instead to log in. If you have not already, you need to setup SDUTIL. Download the codebase and edit the config.yaml at the root. Replace the contents of this config file with the following yaml.
seistore:
service: '{"azure": {"azureEnv":{"url": "<instance url>/seistore-svc/api/v3", "appkey": ""}}}'
url: '<instance url>/seistore-svc/api/v3'
cloud_provider: azure
env: glab
auth-mode: JWT Token
ssl_verify: false
auth_provider:
azure: '{
"provider": "azure",
"authorize_url": "https://login.microsoftonline.com/", "oauth_token_host_end": "/oauth2/v2.0/token",
"scope_end":"/.default openid profile offline_access",
"redirect_uri":"http://localhost:8080",
"login_grant_type": "refresh_token",
"refresh_token": "<RefreshToken acquired earlier>"
}'
azure:
empty: none
Method 1: Postman
Get the sasurl:

Upload the file:
You need to select the file to upload in the Body section of the API call.


Verify upload

Method 2: SDUTIL
sdutil is an OSDU desktop utility to access seismic service. We use it to upload/download files. Use the azure-stable tag from SDUTIL.
Note
When running python sdutil config init, you don't need to enter anything when prompted with Insert the azure (azureGlabEnv) application key:.
python sdutil config init
python sdutil auth login
python sdutil ls sd://<data-partition-id>/<subproject>/
Upload your seismic file to your Seismic Store. Here's an example with a SEGY-format file called source.segy:
python sdutil cp <local folder>/source.segy sd://<data-partition-id>/<subproject>/destination.segy
For example:
python sdutil cp ST10010ZC11_PZ_PSDM_KIRCH_FULL_T.MIG_FIN.POST_STACK.3D.JS-017536.segy sd://<data-partition-id>/<subproject>/destination.segy
Create Storage Records
Insert the contents of your all_records.json file in storage for work-product, seismic trace data, seismic grid, and file collection. Copy and paste the contents of that file to the request body of the API call.

Run Converter
Trigger the ZGY Conversion DAG to convert your data using the execution context values you had saved above.
Fetch the ID token from sdutil for the uploaded file or use an access/bearer token from Postman.
python sdutil auth idtoken

- Let the DAG run to the
succeededstate. You can check the status using the workflow status call. The run ID is in the response of the above call

You can see if the converted file is present using the following command in sdutil or in the Postman API call:
python sdutil ls sd://<data-partition-id>/<subproject>

You can download and inspect the file using the sdutil
cpcommand:python sdutil cp sd://<data-partition-id>/<subproject>/<filename.zgy> <local/destination/path>
OSDU™ is a trademark of The Open Group.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for