Change Data Capture of SQL Server with Apache Flink® DataStream API and DataStream Source on HDInsight on AKS
Important
Azure HDInsight on AKS retired on January 31, 2025. Learn more with this announcement.
You need to migrate your workloads to Microsoft Fabric or an equivalent Azure product to avoid abrupt termination of your workloads.
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
Change Data Capture (CDC) is a technique you can use to track row-level changes in database tables in response to create, update, and delete operations. In this article, we use CDC Connectors for Apache Flink®, which offer a set of source connectors for Apache Flink. The connectors integrate Debezium® as the engine to capture the data changes.
In this article, learn how to perform Change Data Capture of SQL Server using Datastream API. The SQLServer CDC connector can also be a DataStream source.
Prerequisites
- Apache Flink cluster on HDInsight on AKS
- Apache Kafka cluster on HDInsight
- You're required to ensure the network settings are taken care as described on Using HDInsight Kafka; that's to make sure HDInsight on AKS and HDInsight clusters are in the same VNet
- Azure SQLServer
- Install IntelliJ IDEA for development on an Azure VM, which locates in HDInsight VNet
SQLServer CDC Connector
The SQLServer CDC connector is a Flink source connector, which reads database snapshot first and then continues to read change events with exactly once processing even failures happen. The SQLServer CDC connector can also be a DataStream source.
Single Thread Reading
The SQLServer CDC source can’t work in parallel reading, because there's only one task, which can receive change events. For more information, refer SQLServer CDC Connector.
DataStream Source
The SQLServer CDC connector can also be a DataStream source. You can create a SourceFunction.
How the SQLServer CDC connector works?
To optimize, configure and run a Debezium SQL Server connector. It's helpful to understand how the connector performs snapshots, streams change events, determines Kafka topic names, and uses metadata.
- Snapshots : SQL Server CDC isn't designed to store a complete history of database changes. For the Debezium SQL Server connector, to establish a baseline for the current state of the database, it uses a process called snapshotting.
Apache Flink on HDInsight on AKS
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Apache Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
For more information, refer
Apache Kafka on HDInsight
Apache Kafka is an open-source distributed streaming platform that can be used to build real-time streaming data pipelines and applications. Kafka also provides message broker functionality similar to a message queue, where you can publish and subscribe to named data streams.
For more information, refer Apache Kafka in Azure HDInsight
Perform a test
Prepare DB and table on Sqlserver
CREATE DATABASE inventory;
GO
CDC is enabled on the SQL Server database
USE inventory;
EXEC sys.sp_cdc_enable_db;
GO
Verify that the user has access to the CDC table
USE inventory
GO
EXEC sys.sp_cdc_help_change_data_capture
GO
Note
The query returns configuration information for each table in the database that is enabled for CDC and that contains change data that the caller is authorized to access. If the result is empty, verify that the user has privileges to access both the capture instance and the CDC tables.
Create and populate products with single insert with many rows
CREATE TABLE products (
id INTEGER IDENTITY(101,1) NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
description VARCHAR(512),
weight FLOAT
);
INSERT INTO products(name,description,weight)
VALUES ('scooter','Small 2-wheel scooter',3.14);
INSERT INTO products(name,description,weight)
VALUES ('car battery','12V car battery',8.1);
INSERT INTO products(name,description,weight)
VALUES ('12-pack drill bits','12-pack of drill bits with sizes ranging from #40 to #3',0.8);
INSERT INTO products(name,description,weight)
VALUES ('hammer','12oz carpenter''s hammer',0.75);
INSERT INTO products(name,description,weight)
VALUES ('hammer','14oz carpenter''s hammer',0.875);
INSERT INTO products(name,description,weight)
VALUES ('hammer','16oz carpenter''s hammer',1.0);
INSERT INTO products(name,description,weight)
VALUES ('rocks','box of assorted rocks',5.3);
INSERT INTO products(name,description,weight)
VALUES ('jacket','water resistant black wind breaker',0.1);
INSERT INTO products(name,description,weight)
VALUES ('spare tire','24 inch spare tire',22.2);
EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'products', @role_name = NULL, @supports_net_changes = 0;
-- Create some very simple orders
CREATE TABLE orders (
id INTEGER IDENTITY(10001,1) NOT NULL PRIMARY KEY,
order_date DATE NOT NULL,
purchaser INTEGER NOT NULL,
quantity INTEGER NOT NULL,
product_id INTEGER NOT NULL,
FOREIGN KEY (product_id) REFERENCES products(id)
);
INSERT INTO orders(order_date,purchaser,quantity,product_id)
VALUES ('16-JAN-2016', 1001, 1, 102);
INSERT INTO orders(order_date,purchaser,quantity,product_id)
VALUES ('17-JAN-2016', 1002, 2, 105);
INSERT INTO orders(order_date,purchaser,quantity,product_id)
VALUES ('19-FEB-2016', 1002, 2, 106);
INSERT INTO orders(order_date,purchaser,quantity,product_id)
VALUES ('21-FEB-2016', 1003, 1, 107);
EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'orders', @role_name = NULL, @supports_net_changes = 0;
GO
Maven source code on IdeaJ
Based on your usage, update the version of Kafka on <kafka.version>.
maven pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>FlinkDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version> //
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-base -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-elasticsearch7 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-elasticsearch7</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.ververica/flink-sql-connector-sqlserver-cdc -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-sql-connector-sqlserver-cdc</artifactId>
<version>2.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-common -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</project>
mssqlSinkToKafka.java
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.connectors.sqlserver.SqlServerSource;
public class mssqlSinkToKafka {
public static void main(String[] args) throws Exception {
// 1: Stream execution environment, update the kafka brokers below.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); //use parallelism 1 for sink to keep message ordering
String kafka_brokers = "wn0-sampleka:9092,wn1-sampleka:9092,wn2-sampleka:9092";
// 2. sql server source - Update your sql server name, username, password
SourceFunction<String> sourceFunction = SqlServerSource.<String>builder()
.hostname("<samplehilosqlsever>.database.windows.net")
.port(1433)
.database("inventory") // monitor sqlserver database
.tableList("dbo.orders") // monitor products table
.username("username") // username
.password("password") // password
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
DataStream<String> stream = env.addSource(sourceFunction);
stream.print();
// 3. sink order table transaction to kafka
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(kafka_brokers)
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("mssql_order")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute();
}
}
Submit job to Flink
On Webssh pod
bin/flink run -c contoso.example.mssqlSinkToKafka -j FlinkSQLServerCDCDemo-1.0-SNAPSHOT.jar Job has been submitted with JobID abccf644ae13a8028d7e232b85bd507fOn Flink UI make the following change.

Validation
Insert four rows into table order on sqlserver, then check on Kafka

Insert more rows on sqlserver

Check changes on Kafka

Update
product_id=107on sqlserver
Check changes on Kafka for the updated ID 107

Delete
product_id=107on
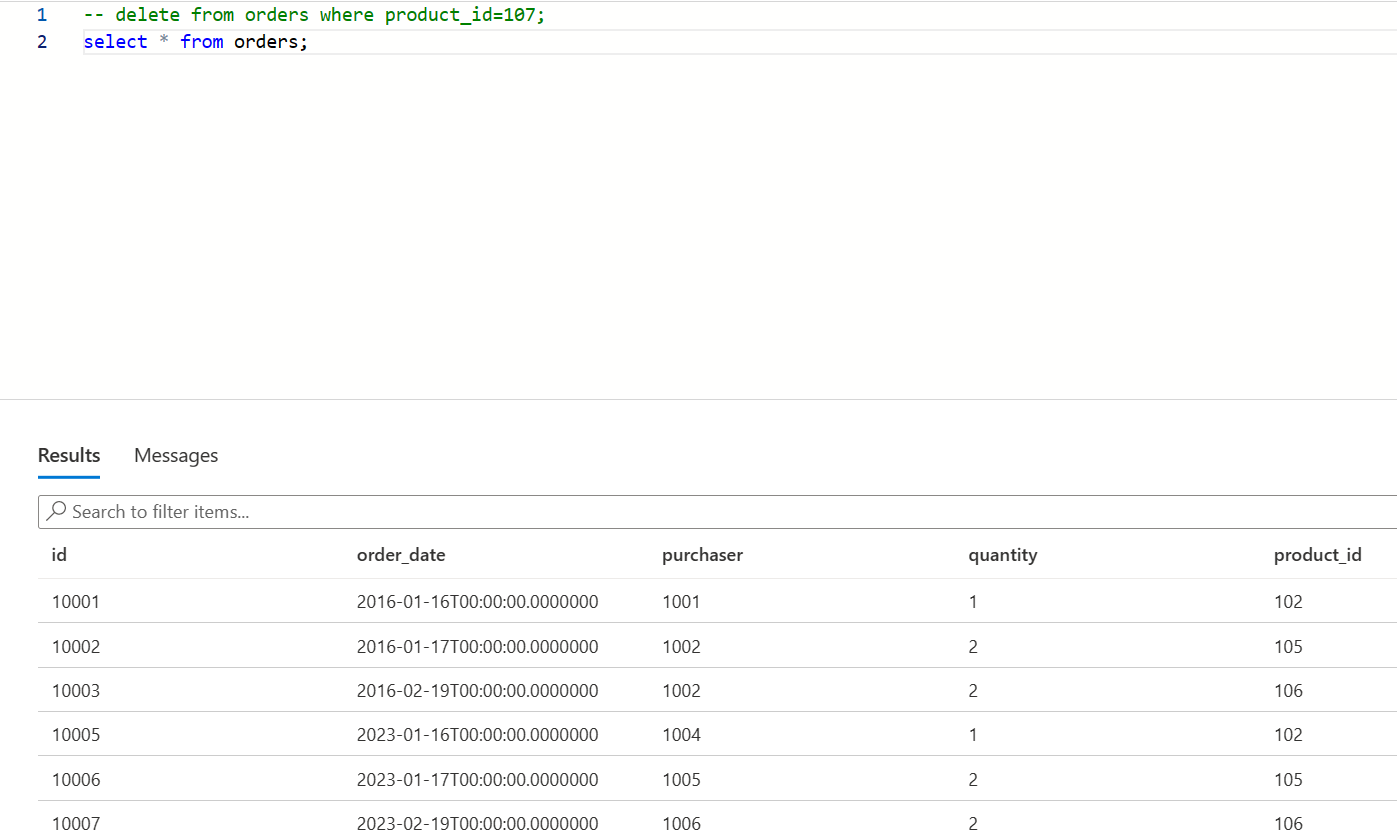
Check changes on Kafka for the deleted
product_id=107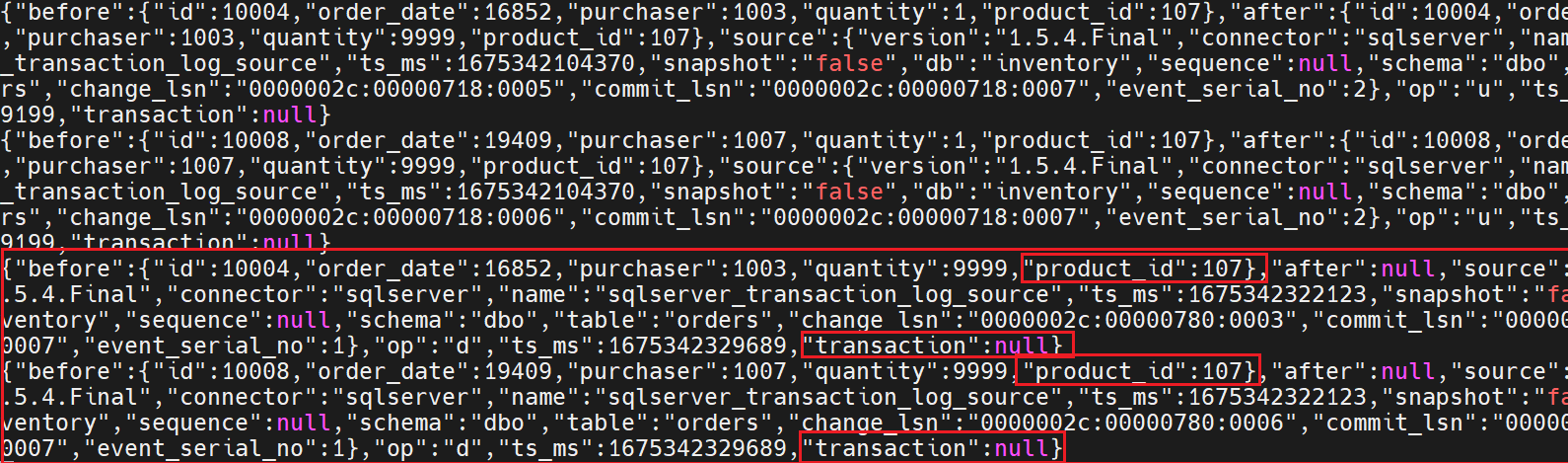
The following JSON message on Kafka shows the change event in JSON format.

Reference
- SQLServer CDC Connector is licensed under Apache 2.0 License
- Apache Kafka in Azure HDInsight
- Kafka Connector
- Apache, Apache Kafka, Kafka, Apache Flink, Flink, and associated open source project names are trademarks of the Apache Software Foundation (ASF).