What is Apache Flink® in Azure HDInsight on AKS? (Preview)
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
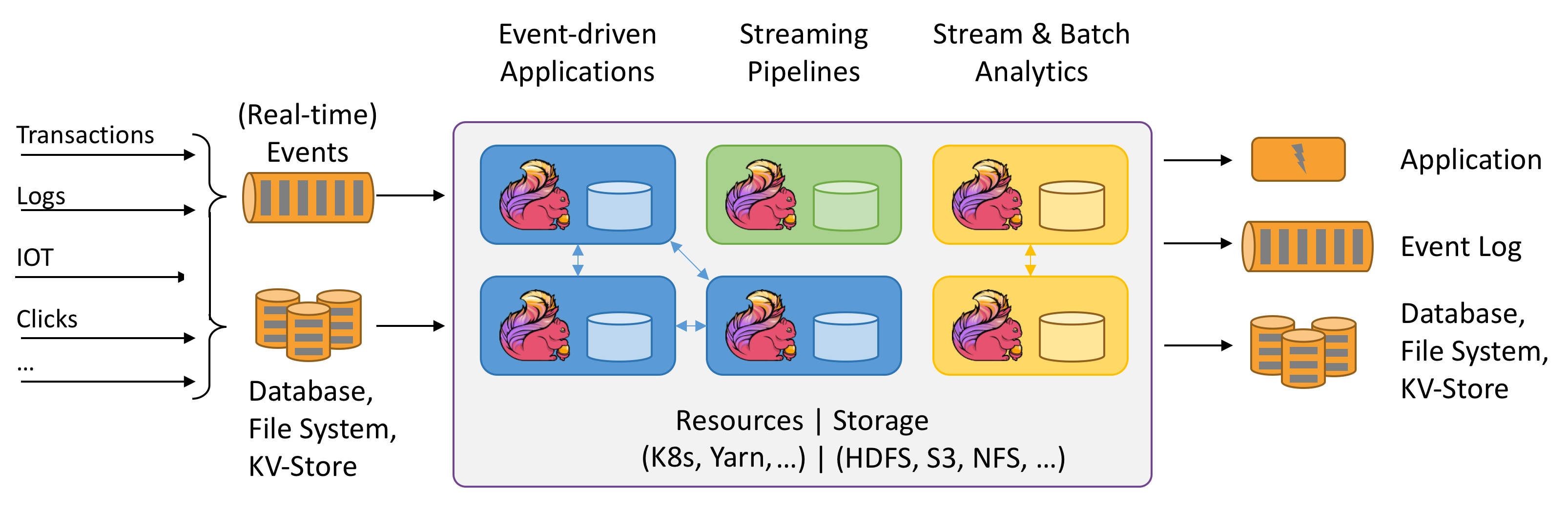
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations and stateful streaming applications at in-memory speed and at any scale. Applications are parallelized into possibly thousands of tasks that are distributed and concurrently executed in a cluster. Therefore, an application can use unlimited amounts of vCPUs, main memory, disk and network IO. Moreover, Flink easily maintains large application state. Its asynchronous and incremental checkpointing algorithm ensures minimal influence on processing latencies while guaranteeing exactly once state consistency.
Apache Flink is a massively scalable analytics engine for stream processing.
Some of the key features that Flink offers are:
- Operations on bounded and unbounded streams
- In memory performance
- Ability for both streaming and batch computations
- Low latency, high throughput operations
- Exactly once processing
- High Availability
- State and fault tolerance
- Fully compatible with Hadoop ecosystem
- Unified SQL APIs for both stream and batch
Why Apache Flink?
Apache Flink is an excellent choice to develop and run many different types of applications due to its extensive features set. Flink’s features include support for stream and batch processing, sophisticated state management, event-time processing semantics, and exactly once consistency guarantees for state. Flink doesn't have a single point of failure. Flink has been proven to scale to thousands of cores and terabytes of application state, delivers high throughput and low latency, and powers some of the world’s most demanding stream processing applications.
- Fraud detection: Flink can be used to detect fraudulent transactions or activities in real time by applying complex rules and machine learning models on streaming data.
- Anomaly detection: Flink can be used to identify outliers or abnormal patterns in streaming data, such as sensor readings, network traffic, or user behavior.
- Rule-based alerting: Flink can be used to trigger alerts or notifications based on predefined conditions or thresholds on streaming data, such as temperature, pressure, or stock prices.
- Business process monitoring: Flink can be used to track and analyze the status and performance of business processes or workflows in real time, such as order fulfillment, delivery, or customer service.
- Web application (social network): Flink can be used to power web applications that require real-time processing of user-generated data, such as messages, likes, comments, or recommendations.
Read more on common use cases described on Apache Flink Use cases
Apache Flink clusters in HDInsight on AKS are a fully managed service. Benefits of creating a Flink cluster in HDInsight on AKS are listed here.
| Feature | Description |
|---|---|
| Ease creation | You can create a new Flink cluster in HDInsight in minutes using the Azure portal, Azure PowerShell, or the SDK. See Get started with Apache Flink cluster in HDInsight on AKS. |
| Ease of use | Flink clusters in HDInsight on AKS include portal based configuration management, and scaling. In addition to this with job management API, you use the REST API or Azure portal for job management. |
| REST APIs | Flink clusters in HDInsight on AKS include Job management API, a REST API-based Flink job submission method to remotely submit and monitor jobs on Azure portal. |
| Deployment Type | Flink can execute applications in Session mode or Application mode. Currently HDInsight on AKS supports only Session clusters. You can run multiple Flink jobs on a Session cluster. App mode is on the roadmap for HDInsight on AKS clusters |
| Support for Metastore | Flink clusters in HDInsight on AKS can support catalogs with Hive Metastore in different open file formats with remote checkpoints to Azure Data Lake Storage Gen2. |
| Support for Azure Storage | Flink clusters in HDInsight can use Azure Data Lake Storage Gen2 as File sink. For more information on Data Lake Storage Gen2, see Azure Data Lake Storage Gen2. |
| Integration with Azure services | Flink cluster in HDInsight on AKS comes with an integration to Kafka along with Azure Event Hubs and Azure HDInsight. You can build streaming applications using the Event Hubs or HDInsight. |
| Adaptability | HDInsight on AKS allows you to scale the Flink cluster nodes based on schedule with the Autoscale feature. See Automatically scale Azure HDInsight on AKS clusters. |
| State Backend | HDInsight on AKS uses the RocksDB as default StateBackend. RocksDB is an embeddable persistent key-value store for fast storage. |
| Checkpoints | Checkpointing is enabled in HDInsight on AKS clusters by default. Default settings on HDInsight on AKS maintain the last five checkpoints in persistent storage. In case, your job fails, the job can be restarted from the latest checkpoint. |
| Incremental Checkpoints | RocksDB supports Incremental Checkpoints. We encourage the use of incremental checkpoints for large state, you need to enable this feature manually. Setting a default in your flink-conf.yaml: state.backend.incremental: true enables incremental checkpoints, unless the application overrides this setting in the code. This statement is true by default. You can alternatively configure this value directly in the code (overrides the config default) EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true); . By default, we preserve the last five checkpoints in the checkpoint dir configured. This value can be changed by changing the configuration on configuration management section state.checkpoints.num-retained: 5 |
Apache Flink clusters in HDInsight on AKS include the following components, they are available on the clusters by default.
Refer to the Roadmap on what's coming soon!
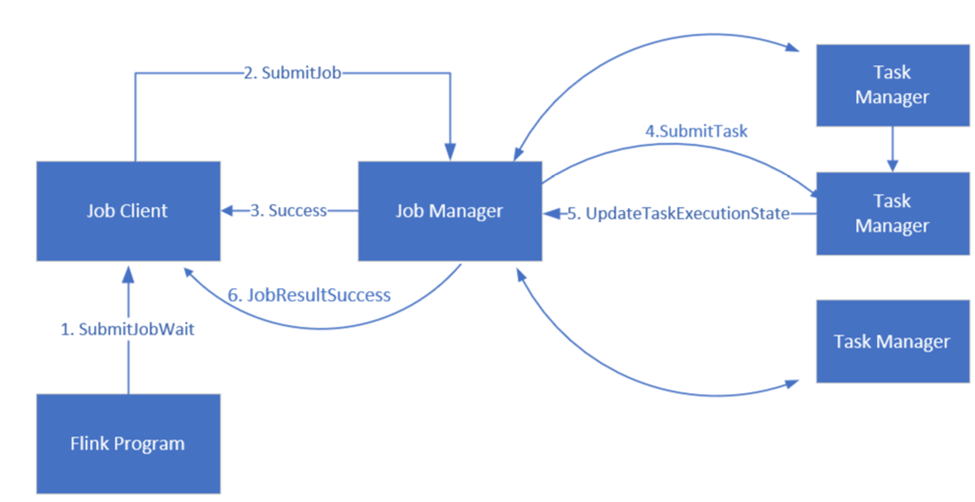
Apache Flink Job Management
Flink schedules jobs using three distributed components, Job manager, Task manager, and Job Client, which are set in a Leader-Follower pattern.
Flink Job: A Flink job or program consists of multiple tasks. Tasks are the basic unit of execution in Flink. Each Flink task has multiple instances depending on the level of parallelism and each instance is executed on a TaskManager.
Job manager: Job manager acts as a scheduler and schedules tasks on task managers.
Task manager: Task Managers come with one or more slots to execute tasks in parallel.
Job client: Job client communicates with job manager to submit Flink jobs
Flink Web UI: Flink features a web UI to inspect, monitor, and debug running applications.
Reference
- Apache Flink Website
- Apache, Apache Kafka, Kafka, Apache Flink, Flink, and associated open source project names are trademarks of the Apache Software Foundation (ASF).
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for