APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
In this article, you see how to deploy a new version of a machine learning model in production without causing any disruption. You use a blue-green deployment strategy, which is also known as a safe rollout strategy, to introduce a new version of a web service to production. When you use this strategy, you can roll out your new version of the web service to a small subset of users or requests before rolling it out completely.
This article assumes you use online endpoints, or endpoints that are used for online (real-time) inferencing. There are two types of online endpoints: managed online endpoints and Kubernetes online endpoints. For more information about endpoints and the differences between endpoint types, see Managed online endpoints vs. Kubernetes online endpoints.
This article uses managed online endpoints for deployment. But it also includes notes that explain how to use Kubernetes endpoints instead of managed online endpoints.
In this article, you see how to:
- Define an online endpoint with a deployment called
blue to serve the first version of a model.
- Scale the
blue deployment so that it can handle more requests.
- Deploy the second version of the model, which is called the
green deployment, to the endpoint, but send the deployment no live traffic.
- Test the
green deployment in isolation.
- Mirror a percentage of live traffic to the
green deployment to validate it.
- Send a small percentage of live traffic to the
green deployment.
- Send all live traffic to the
green deployment.
- Delete the unused
blue deployment.
Prerequisites
The Azure CLI and the ml extension to the Azure CLI, installed and configured. For more information, see Install and set up the CLI (v2).
A Bash shell or a compatible shell, for example, a shell on a Linux system or Windows Subsystem for Linux. The Azure CLI examples in this article assume that you use this type of shell.
An Azure Machine Learning workspace. For instructions to create a workspace, see Set up.
A user account that has at least one of the following Azure role-based access control (Azure RBAC) roles:
- An Owner role for the Azure Machine Learning workspace
- A Contributor role for the Azure Machine Learning workspace
- A custom role that has
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* permissions
For more information, see Manage access to Azure Machine Learning workspaces.
Optionally, Docker Engine, installed and running locally. This prerequisite is highly recommended. You need it to deploy a model locally, and it's helpful for debugging.
APPLIES TO:
Python SDK azure-ai-ml v2 (current)
An Azure Machine Learning workspace. For steps for creating a workspace, see Create the workspace.
The Azure Machine Learning SDK for Python v2. To install the SDK, use the following command:
pip install azure-ai-ml azure-identity
To update an existing installation of the SDK to the latest version, use the following command:
pip install --upgrade azure-ai-ml azure-identity
For more information, see Azure Machine Learning Package client library for Python.
A user account that has at least one of the following Azure role-based access control (Azure RBAC) roles:
- An Owner role for the Azure Machine Learning workspace
- A Contributor role for the Azure Machine Learning workspace
- A custom role that has
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* permissions
For more information, see Manage access to Azure Machine Learning workspaces.
Optionally, Docker Engine, installed and running locally. This prerequisite is highly recommended. You need it to deploy a model locally, and it's helpful for debugging.
An Azure subscription. If you don't have an Azure subscription, create a free account before you begin.
An Azure Machine Learning workspace. For instructions for creating a workspace, see Create the workspace.
A user account that has at least one of the following Azure role-based access control (Azure RBAC) roles:
- An Owner role for the Azure Machine Learning workspace
- A Contributor role for the Azure Machine Learning workspace
- A custom role that has
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* permissions
For more information, see Manage access to Azure Machine Learning workspaces.
Prepare your system
Set environment variables
You can configure default values to use with the Azure CLI. To avoid passing in values for your subscription, workspace, and resource group multiple times, run the following code:
az account set --subscription <subscription-ID>
az configure --defaults workspace=<Azure-Machine-Learning-workspace-name> group=<resource-group-name>
Clone the examples repository
To follow along with this article, first clone the examples repository (azureml-examples). Then go to the repository's cli/ directory:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
cd cli
Tip
Use --depth 1 to clone only the latest commit to the repository, which reduces the time that's needed to complete the operation.
The commands in this tutorial are in the deploy-safe-rollout-online-endpoints.sh file in the cli directory, and the YAML configuration files are in the endpoints/online/managed/sample/ subdirectory.
Note
The YAML configuration files for Kubernetes online endpoints are in the endpoints/online/kubernetes/ subdirectory.
Clone the examples repository
To run the training examples, first clone the examples repository (azureml-examples). Then go to the azureml-examples/sdk/python/endpoints/online/managed directory:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
Tip
Use --depth 1 to clone only the latest commit to the repository, which reduces the time that's needed to complete the operation.
The information in this article is based on the online-endpoints-safe-rollout.ipynb notebook. This article contains the same content as the notebook, but the order of the code blocks differs slightly between the two documents.
Connect to an Azure Machine Learning workspace
The workspace is the top-level resource for Azure Machine Learning. A workspace provides a centralized place to work with all the artifacts you create when you use Azure Machine Learning. In this section, you connect to your workspace, where you perform deployment tasks. To follow along, open your online-endpoints-safe-rollout.ipynb notebook.
Import the required libraries:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration,
)
from azure.identity import DefaultAzureCredential
Note
If you're using a Kubernetes online endpoint, import the KubernetesOnlineEndpoint and KubernetesOnlineDeployment class from the azure.ai.ml.entities library.
Configure workspace settings and get a handle to the workspace:
To connect to a workspace, you need identifier parameters—a subscription, a resource group, and a workspace name. You use this information in the MLClient class from the azure.ai.ml module to get a handle to the required Azure Machine Learning workspace. This example uses the default Azure authentication.
# enter details of your AML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
If you have Git installed on your local machine, you can follow the instructions to clone the examples repository. Otherwise, follow the instructions to download files from the examples repository.
Clone the examples repository
To follow along with this article, clone the azureml-examples repository, and then go to the azureml-examples/cli/endpoints/online/model-1 folder.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
Tip
Use --depth 1 to clone only the latest commit to the repository, which reduces the time that's needed to complete the operation.
Download files from the examples repository
Instead of cloning the examples repository, you can download the repository to your local machine:
- Go to https://github.com/Azure/azureml-examples/.
- Select <> Code, and then go to the Local tab and select Download ZIP.
Define the endpoint and deployment
Online endpoints are used for online (real-time) inferencing. Online endpoints contain deployments that are ready to receive data from clients and send responses back in real time.
Define an endpoint
The following table lists key attributes to specify when you define an endpoint.
| Attribute |
Required or optional |
Description |
| Name |
Required |
The name of the endpoint. It must be unique in its Azure region. For more information about naming rules, see Azure Machine Learning online endpoints and batch endpoints. |
| Authentication mode |
Optional |
The authentication method for the endpoint. You can choose between key-based authentication, key, and Azure Machine Learning token-based authentication, aml_token. A key doesn't expire, but a token does expire. For more information about authentication, see Authenticate clients for online endpoints. |
| Description |
Optional |
The description of the endpoint. |
| Tags |
Optional |
A dictionary of tags for the endpoint. |
| Traffic |
Optional |
Rules on how to route traffic across deployments. You represent the traffic as a dictionary of key-value pairs, where the key represents the deployment name and the value represents the percentage of traffic to that deployment. You can set the traffic only after the deployments under an endpoint are created. You can also update the traffic for an online endpoint after the deployments are created. For more information about how to use mirrored traffic, see Allocate a small percentage of live traffic to the new deployment. |
| Mirror traffic |
Optional |
The percentage of live traffic to mirror to a deployment. For more information about how to use mirrored traffic, see Test the deployment with mirrored traffic. |
To see a full list of attributes that you can specify when you create an endpoint, see CLI (v2) online endpoint YAML schema. For version 2 of the Azure Machine Learning SDK for Python, see ManagedOnlineEndpoint Class.
Define a deployment
A deployment is a set of resources that are required for hosting the model that does the actual inferencing. The following table describes key attributes to specify when you define a deployment.
| Attribute |
Required or optional |
Description |
| Name |
Required |
The name of the deployment. |
| Endpoint name |
Required |
The name of the endpoint to create the deployment under. |
| Model |
Optional |
The model to use for the deployment. This value can be either a reference to an existing versioned model in the workspace or an inline model specification. In this article's examples, a scikit-learn model does regression. |
| Code path |
Optional |
The path to the folder on the local development environment that contains all the Python source code for scoring the model. You can use nested directories and packages. |
| Scoring script |
Optional |
Python code that executes the model on a given input request. This value can be the relative path to the scoring file in the source code folder.
The scoring script receives data submitted to a deployed web service and passes it to the model. The script then executes the model and returns its response to the client. The scoring script is specific to your model and must understand the data that the model expects as input and returns as output.
This article's examples use a score.py file. This Python code must have an init function and a run function. The init function is called after the model is created or updated. You can use it to cache the model in memory, for example. The run function is called at every invocation of the endpoint to do the actual scoring and prediction. |
| Environment |
Required |
The environment to host the model and code. This value can be either a reference to an existing versioned environment in the workspace or an inline environment specification. The environment can be a Docker image with Conda dependencies, a Dockerfile, or a registered environment. |
| Instance type |
Required |
The virtual machine size to use for the deployment. For a list of supported sizes, see Managed online endpoints SKU list. |
| Instance count |
Required |
The number of instances to use for the deployment. You base the value on the workload you expect. For high availability, we recommend that you use at least three instances. Azure Machine Learning reserves an extra 20 percent for performing upgrades. For more information, see Azure Machine Learning online endpoints and batch endpoints. |
To see a full list of attributes that you can specify when you create a deployment, see CLI (v2) managed online deployment YAML schema. For version 2 of the Python SDK, see ManagedOnlineDeployment Class.
Create an online endpoint
You first set the endpoint name and then configure it. In this article, you use the endpoints/online/managed/sample/endpoint.yml file to configure the endpoint. That file contains the following lines:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
The following table describes keys that the endpoint YAML format uses. To see how to specify these attributes, see CLI (v2) online endpoint YAML schema. For information about limits related to managed online endpoints, see Azure Machine Learning online endpoints and batch endpoints.
| Key |
Description |
$schema |
(Optional) The YAML schema. To see all available options in the YAML file, you can view the schema in the preceding code block in a browser. |
name |
The name of the endpoint. |
auth_mode |
The authentication mode. Use key for key-based authentication. Use aml_token for Azure Machine Learning token-based authentication. To get the most recent token, use the az ml online-endpoint get-credentials command. |
To create an online endpoint:
Set your endpoint name by running the following Unix command. Replace YOUR_ENDPOINT_NAME with a unique name.
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
Important
Endpoint names must be unique within an Azure region. For example, in the Azure westus2 region, there can be only one endpoint with the name my-endpoint.
Create the endpoint in the cloud by running the following code. This code uses the endpoint.yml file to configure the endpoint:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Create the blue deployment
You can use the endpoints/online/managed/sample/blue-deployment.yml file to configure the key aspects of a deployment named blue. That file contains the following lines:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
To use the blue-deployment.yml file to create the blue deployment for your endpoint, run the following command:
az ml online-deployment create --name blue --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml --all-traffic
Important
The --all-traffic flag in the az ml online-deployment create command allocates 100 percent of the endpoint traffic to the newly created blue deployment.
In the blue-deployment.yaml file, the path line specifies where to upload files from. The Azure Machine Learning CLI uses this information to upload the files and register the model and environment. As a best practice for production, you should register the model and environment and specify the registered name and version separately in the YAML code. Use the format model: azureml:<model-name>:<model-version> for the model, for example, model: azureml:my-model:1. For the environment, use the format environment: azureml:<environment-name>:<environment-version>, for example, environment: azureml:my-env:1.
For registration, you can extract the YAML definitions of model and environment into separate YAML files and use the commands az ml model create and az ml environment create. To find out more about these commands, run az ml model create -h and az ml environment create -h.
For more information about registering your model as an asset, see Register a model by using the Azure CLI or Python SDK. For more information about creating an environment, see Create a custom environment.
Create an online endpoint
To create a managed online endpoint, use the ManagedOnlineEndpoint class. This class provides a way for you to configure the key aspects of the endpoint.
Configure the endpoint:
# Creating a unique endpoint name with current datetime to avoid conflicts
import random
online_endpoint_name = "endpt-moe-" + str(random.randint(0, 10000))
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is a sample online endpoint",
auth_mode="key",
tags={"foo": "bar"},
)
Note
To create a Kubernetes online endpoint, use the KubernetesOnlineEndpoint class.
Create the endpoint:
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Create the blue deployment
To create a deployment for your managed online endpoint, use the ManagedOnlineDeployment class. This class provides a way for you to configure the key aspects of the deployment.
Configure the blue deployment:
# create blue deployment
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
In this example, the path parameter specifies where to upload files from. The Python SDK uses this information to upload the files and register the model and environment. As a best practice for production, you should register the model and environment and specify the registered name and version separately in the code.
For more information about registering your model as an asset, see Register a model by using the Azure CLI or Python SDK.
For more information about creating an environment, see Create a custom environment.
Note
To create a deployment for a Kubernetes online endpoint, use the KubernetesOnlineDeployment class.
Create the deployment:
ml_client.online_deployments.begin_create_or_update(blue_deployment).result()
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
When you create a managed online endpoint in Azure Machine Learning studio, you must define an initial deployment for the endpoint. Before you can define a deployment, you must have a registered model in your workspace. The following section shows you how to register a model to use for the deployment.
Register your model
A model registration is a logical entity in the workspace. This entity can contain a single model file or a directory of multiple files. As a best practice for production, you should register your model and environment.
To register the example model, take the steps in the following sections.
Upload the model files
Go to Azure Machine Learning studio.
Select Models.
Select Register, and then select From local files.
Under Model type, select Unspecified type.
Select Browse, and then select Browse folder.
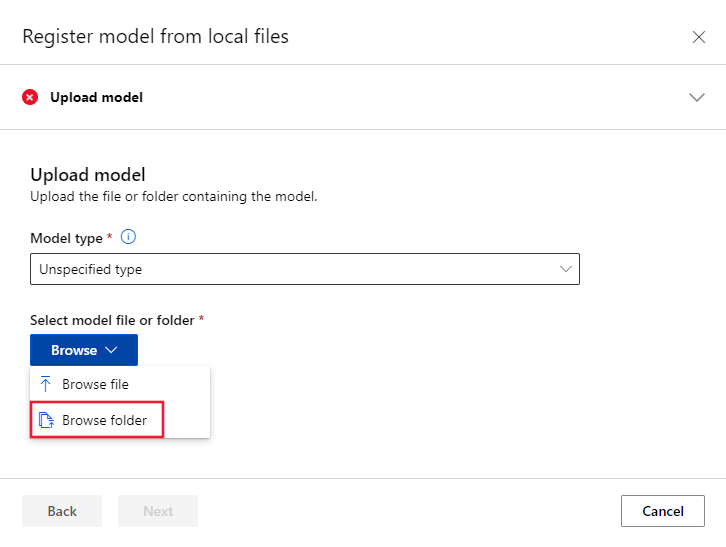
Go to the local copy of the repository you cloned or downloaded earlier, and then select \azureml-examples\cli\endpoints\online\model-1\model. When prompted, select Upload and wait for the upload to finish.
Select Next.
On the Model settings page, under Name, enter a friendly name for the model. The steps in this article assume the model is named model-1.
Select Next, and then select Register to complete the registration.
For later examples in this article, you also need to register a model from the \azureml-examples\cli\endpoints\online\model-2\model folder in your local copy of the repository. To register that model, repeat the steps in the previous two sections, but name the model model-2.
For more information about working with registered models, see Work with registered models in Azure Machine Learning.
For information about creating an environment in the studio, see Create an environment.
Create a managed online endpoint and the blue deployment
You can use Azure Machine Learning studio to create a managed online endpoint directly in your browser. When you create a managed online endpoint in the studio, you must define an initial deployment. You can't create an empty managed online endpoint.
One way to create a managed online endpoint in the studio is from the Models page. This method also provides an easy way to add a model to an existing managed online deployment. To deploy the model named model-1 that you registered previously in the Register your model section, take the steps in the following sections.
Select a model
Go to Azure Machine Learning studio, and then select Models.
In the list, select the model-1 model.
Select Deploy > Real-time endpoint.
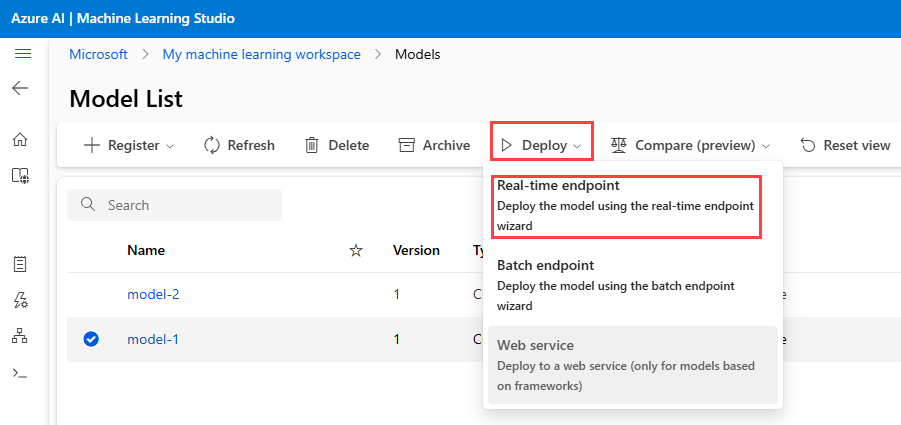
A window opens that you can use to specify detailed information about your endpoint.
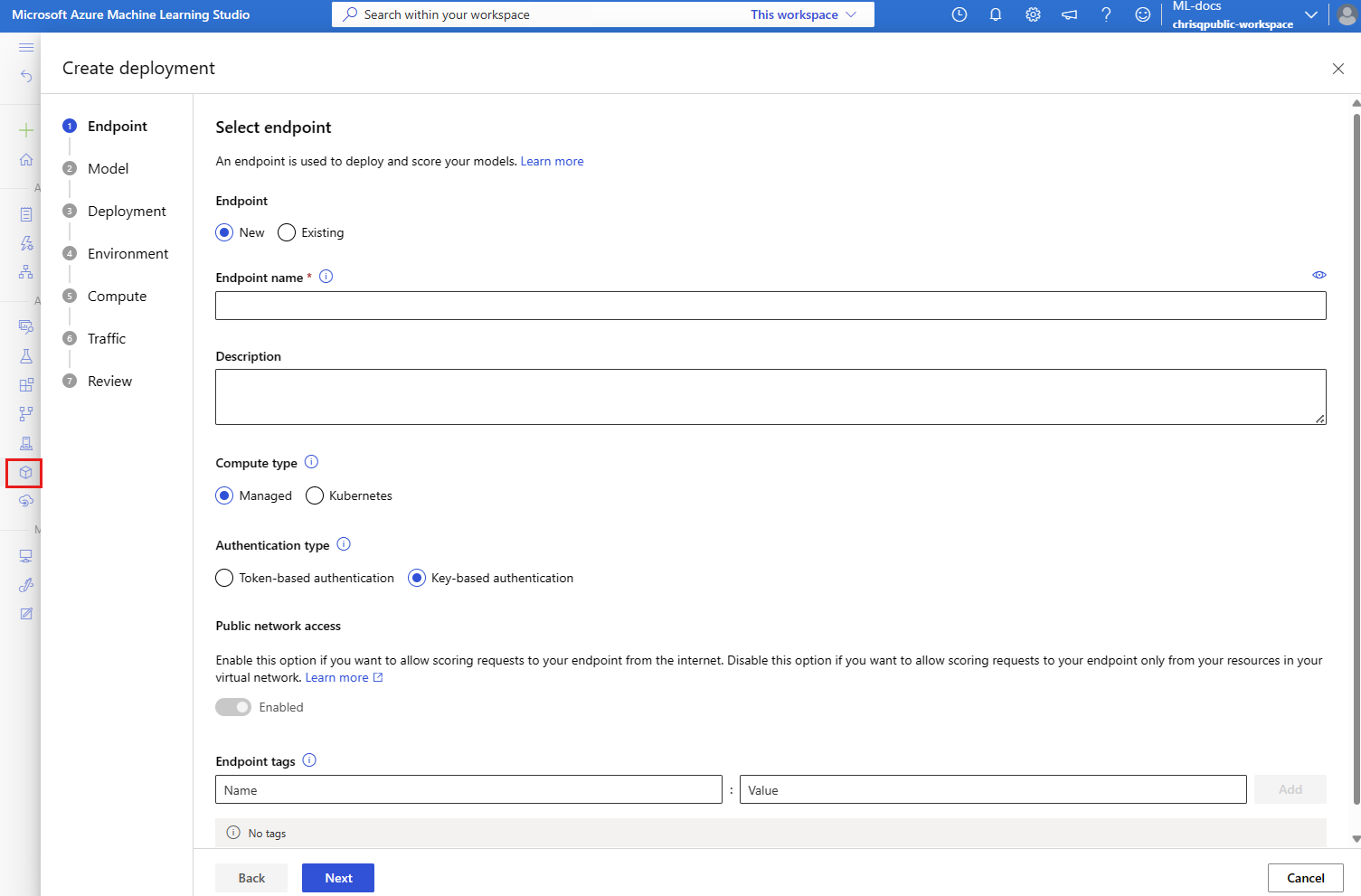
Under Endpoint name, enter a name for your endpoint.
Under Compute type, keep the default value of Managed.
Under Authentication type, keep the default value of key-based authentication.
Select Next, and then on the Model page, select Next.
Configure remaining settings and create the deployment
On the Deployment page, take the following steps:
- Under Deployment name, enter blue.
- If you want to view graphs of your endpoint activities in the studio later:
- Under Inferencing data collection, turn on the toggle.
- Under Application Insights diagnostics, turn on the toggle.
- Select Next.
On the Code and environment for inferencing page, take the following steps:
- Under Select a scoring script for inferencing, select Browse, and then select the \azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py file from the repository you cloned or downloaded earlier.
- In the search box above the list of environments, start entering sklearn, and then select the sklearn-1.5:19 curated environment.
- Select Next.
On the Compute page, take the following steps:
- Under Virtual machine, keep the default value.
- Under Instance count, replace the default value with 1.
- Select Next.
On the Live Traffic page, select Next to accept the default traffic allocation of 100 percent to the blue deployment.
On the Review page, review your deployment settings, and then select Create.
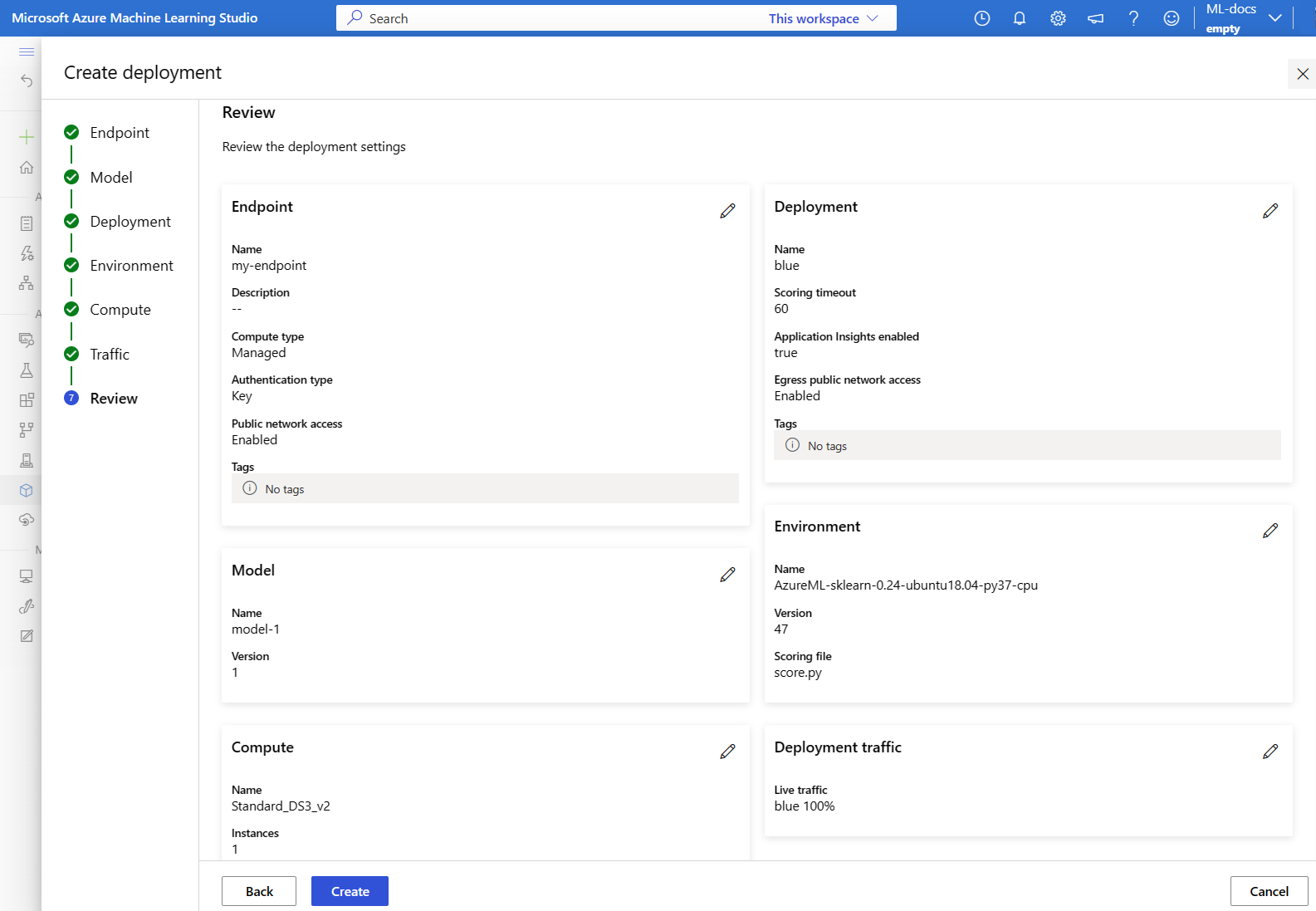
Create an endpoint from the Endpoints page
Alternatively, you can create a managed online endpoint from the Endpoints page in the studio.
Go to Azure Machine Learning studio.
Select Endpoints.
Select Create.
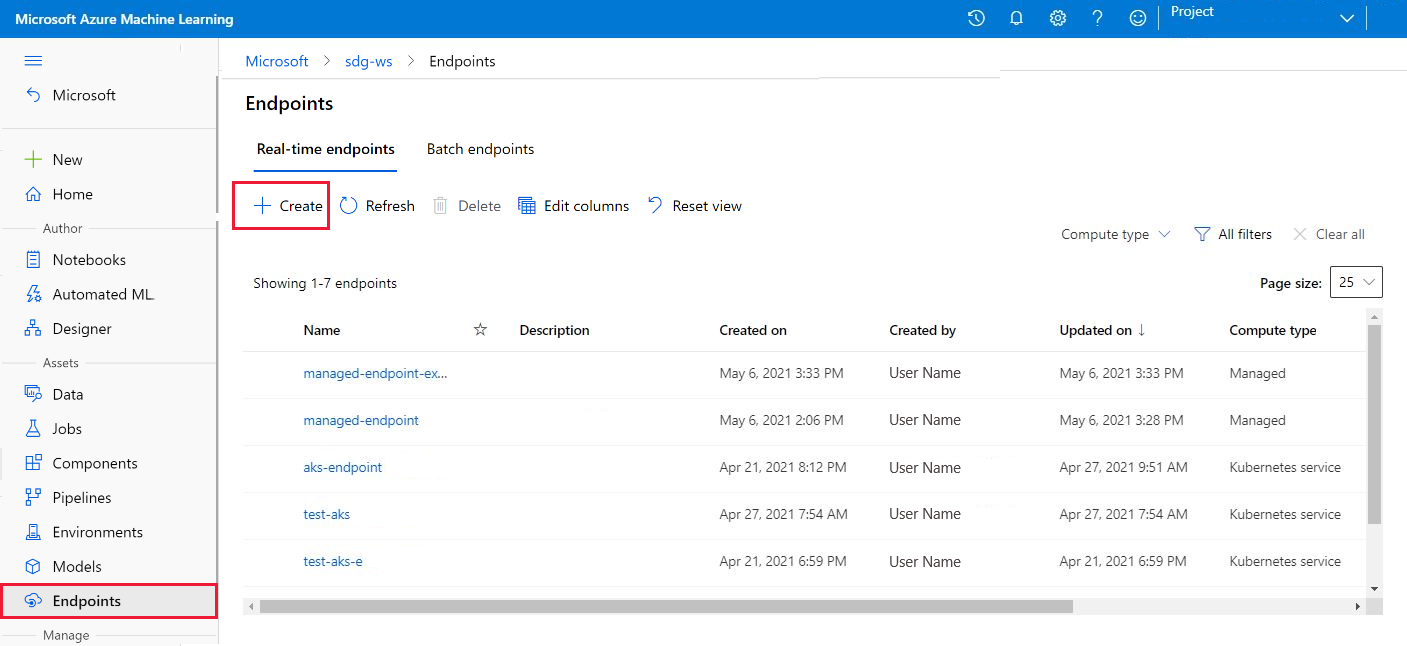
A window opens that you can use to specify detailed information about your endpoint and deployment.
Select a model, and then select Select.
Enter settings for your endpoint and deployment as described in the previous two sections. In each step, use the default values, and in the last step, select Create to create the deployment.
Confirm your existing deployment
One way to confirm your existing deployment is to invoke your endpoint so that it can score your model for a given input request. When you invoke your endpoint via the Azure CLI or the Python SDK, you can choose to specify the name of the deployment to receive incoming traffic.
Note
Unlike the Azure CLI or Python SDK, Azure Machine Learning studio requires you to specify a deployment when you invoke an endpoint.
Invoke an endpoint with a deployment name
When you invoke an endpoint, you can specify the name of a deployment that you want to receive traffic. In this case, Azure Machine Learning routes the endpoint traffic directly to the specified deployment and returns its output. You can use the --deployment-name option for the Azure Machine Learning CLI v2, or the deployment_name option for the Python SDK v2 to specify the deployment.
Invoke the endpoint without specifying a deployment
If you invoke the endpoint without specifying the deployment that you want to receive traffic, Azure Machine Learning routes the endpoint's incoming traffic to the deployments in the endpoint based on traffic control settings.
Traffic control settings allocate specified percentages of incoming traffic to each deployment in the endpoint. For example, if your traffic rules specify that a particular deployment in your endpoint should receive incoming traffic 40 percent of the time, Azure Machine Learning routes 40 percent of the endpoint traffic to that deployment.
To view the status of your existing endpoint and deployment, run the following commands:
az ml online-endpoint show --name $ENDPOINT_NAME
az ml online-deployment show --name blue --endpoint $ENDPOINT_NAME
The output lists information about the $ENDPOINT_NAME endpoint and the blue deployment.
Test the endpoint by using sample data
You can invoke the endpoint by using the invoke command. The following command uses the sample-request.json JSON file to send a sample request:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Use the following code to check the status of the model deployment:
ml_client.online_endpoints.get(name=online_endpoint_name)
Test the endpoint by using sample data
You can use the instance of MLClient that you created earlier to get a handle to the endpoint. To invoke the endpoint, you can use the invoke command with the following parameters:
endpoint_name: The name of the endpointrequest_file: A file that contains request datadeployment_name: The name of a deployment to test in the endpoint
The following code uses the sample-request.json JSON file to send a sample request.
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
View managed online endpoints
You can view all your managed online endpoints in the studio endpoints page. The Details tab of each endpoint's page displays critical information, such as the endpoint URI, status, testing tools, activity monitors, deployment logs, and sample consumption code. To see this information, take the following steps:
In the studio, select Endpoints. A list of all the endpoints in the workspace is displayed.
Optionally, create a filter on the compute instance type to show only managed types.
Select an endpoint name to view the endpoint's Details page.
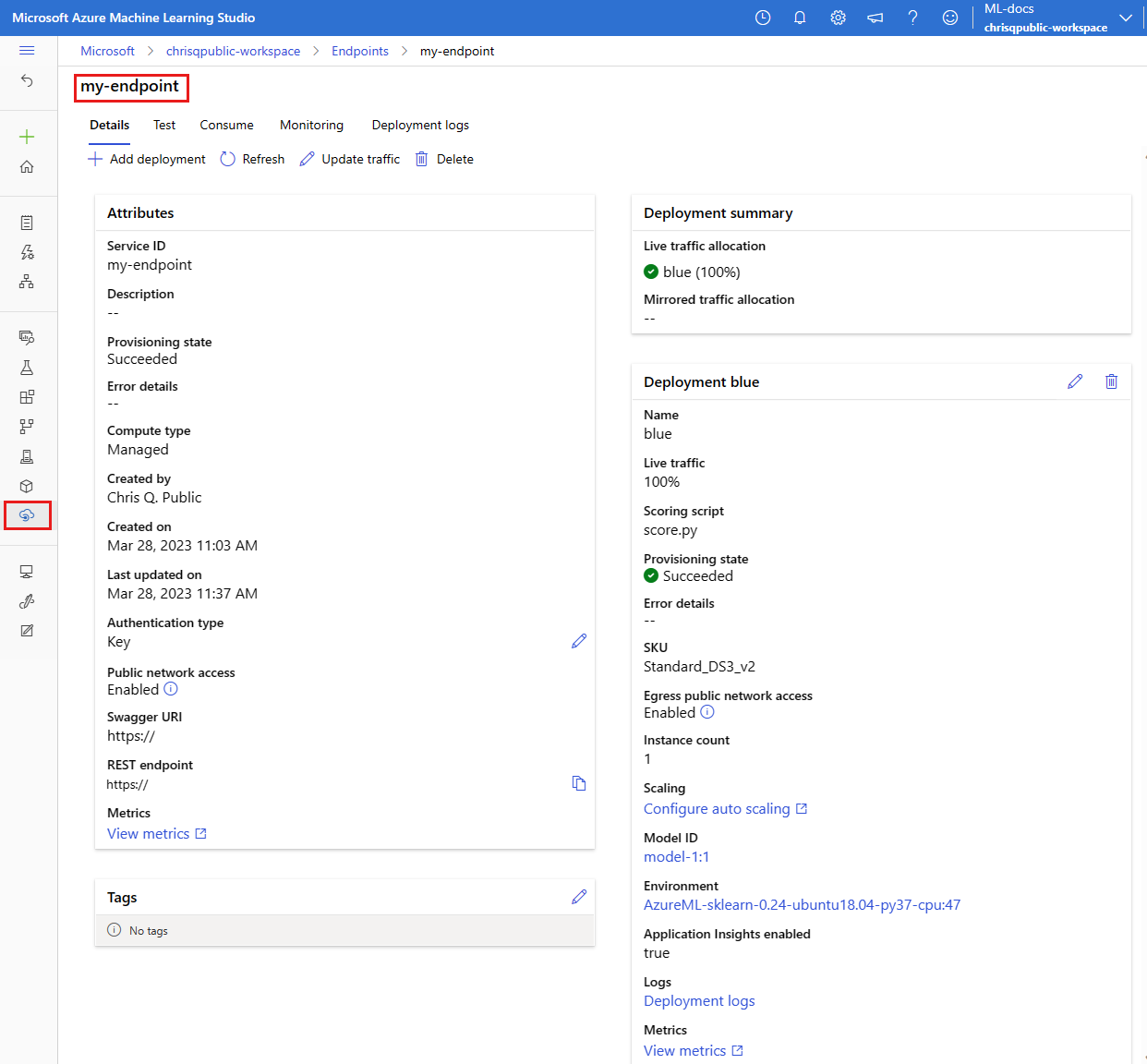
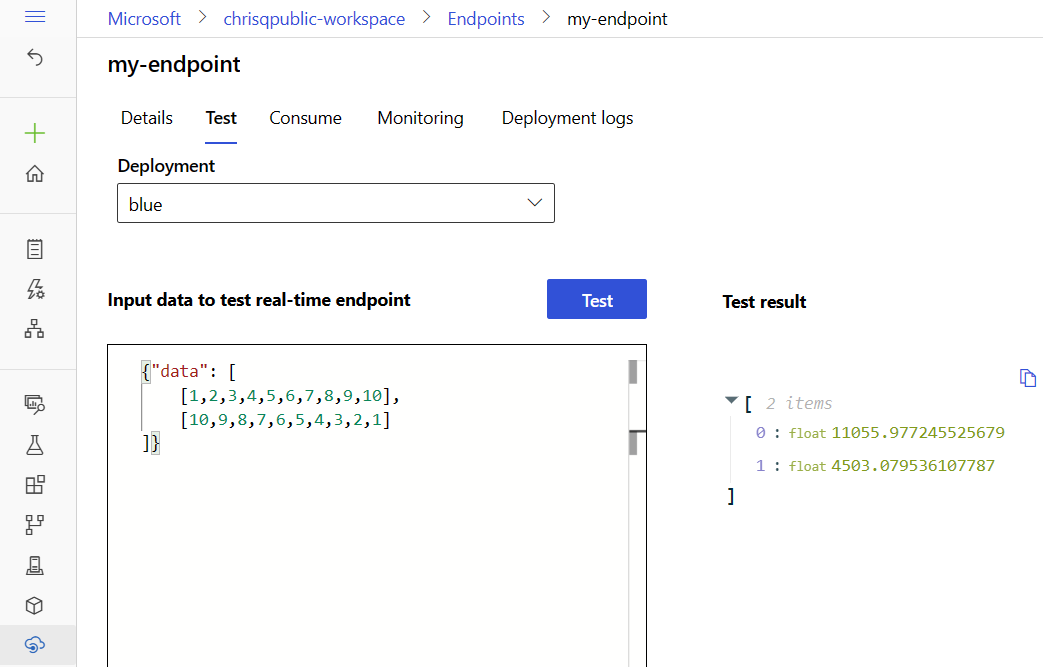
Test the endpoint by using sample data
On the endpoint page, you can use the Test tab to test your managed online deployment. To enter sample input and view the results, take the following steps:
On the endpoint page, go to the Test tab. In the Deployment list, the blue deployment is already selected.
Go to the sample-request.json file and copy its sample input.
In the studio, paste the sample input into the Input box.
Select Test.
Scale your existing deployment to handle more traffic
In the deployment described in Deploy and score a machine learning model by using an online endpoint, you set the instance_count value to 1 in the deployment YAML file. You can scale out by using the update command:
az ml online-deployment update --name blue --endpoint-name $ENDPOINT_NAME --set instance_count=2
Note
In the previous command, the --set option overrides the deployment configuration. Alternatively, you can update the YAML file and pass it as input to the update command by using the --file option.
You can use the instance of MLClient that you created earlier to get a handle to the deployment. To scale the deployment, you can increase or decrease the value of instance_count.
# scale the deployment
blue_deployment = ml_client.online_deployments.get(
name="blue", endpoint_name=online_endpoint_name
)
blue_deployment.instance_count = 2
ml_client.online_deployments.begin_create_or_update(blue_deployment).result()
# Get the details for online endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
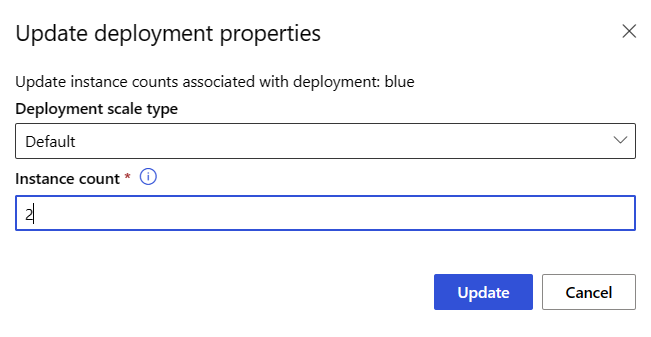
To scale the deployment up or down by adjusting the number of instances, take the following steps:
On the endpoint page, go to the Details tab, and find the card for the blue deployment.
On the header of the blue deployment card, select the edit icon.
Under Instance count, enter 2.
Select Update.
Deploy a new model but don't send it traffic
Create a new deployment named green:
az ml online-deployment create --name green --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/green-deployment.yml
Because you don't explicitly allocate any traffic to the green deployment, it has zero traffic allocated to it. You can verify that fact by using the following command:
az ml online-endpoint show -n $ENDPOINT_NAME --query traffic
Test the new deployment
Even though the green deployment has 0 percent of traffic allocated to it, you can invoke it directly by using the --deployment option:
az ml online-endpoint invoke --name $ENDPOINT_NAME --deployment-name green --request-file endpoints/online/model-2/sample-request.json
If you want to use a REST client to invoke the deployment directly without going through traffic rules, set the following HTTP header: azureml-model-deployment: <deployment-name>. The following code uses Client for URL (cURL) to invoke the deployment directly. You can run the code in a Unix or Windows Subsystem for Linux (WSL) environment. For instructions for retrieving the $ENDPOINT_KEY value, see Get the key or token for data plane operations.
# get the scoring uri
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
# use curl to invoke the endpoint
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --header "azureml-model-deployment: green" --data @endpoints/online/model-2/sample-request.json
Create a new deployment for your managed online endpoint, and name the deployment green:
# create green deployment
model2 = Model(path="../model-2/model/sklearn_regression_model.pkl")
env2 = Environment(
conda_file="../model-2/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
)
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model2,
environment=env2,
code_configuration=CodeConfiguration(
code="../model-2/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
# use MLClient to create green deployment
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Note
If you're creating a deployment for a Kubernetes online endpoint, use the KubernetesOnlineDeployment class, and specify a Kubernetes instance type in your Kubernetes cluster.
Test the new deployment
Even though the green deployment has 0 percent of the traffic allocated to it, you can still invoke the endpoint and deployment. The following code uses the sample-request.json JSON file to send a sample request.
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="green",
request_file="../model-2/sample-request.json",
)
You can create a new deployment to add to your managed online endpoint. To create a deployment named green, take the steps in the following sections.
On the endpoint page, go to the Details tab, and then select Add Deployment.
On the Select a model page, select model-2, and then select Select.
On the Endpoint page and on the Model page, select Next.
On the Deployment page, take the following steps:
- Under Deployment name, enter green.
- Under Inferencing data collection, turn on the toggle.
- Under Application Insights diagnostics, turn on the toggle.
- Select Next.
On the Code and environment for inferencing page, take the following steps:
- Under Select a scoring script for inferencing, select Browse, and then select the \azureml-examples\cli\endpoints\online\model-2\onlinescoring\score.py file from the repository you cloned or downloaded earlier.
- In the search box above the list of environments, start entering sklearn, and then select the sklearn-1.5:19 curated environment.
- Select Next.
On the Compute page, take the following steps:
- Under Virtual machine, keep the default value.
- Under Instance count, replace the default value with 1.
- Select Next.
Configure remaining settings and create the deployment
On the Live Traffic page, select Next to accept the default traffic allocation of 100 percent to the blue deployment and 0 percent to green.
On the Review page, review your deployment settings, and then select Create.
Add a deployment from the Models page
Alternatively, you can use the Models page to add a deployment:
In the studio, select Models.
Select a model in the list.
Select Deploy > Real-time endpoint.
Under Endpoint, select Existing.
In the list of endpoints, select the managed online endpoint that you want to deploy the model to, and then select Next.
On the Model page, select Next.
To finish creating the green deployment, follow steps 4 through 6 in the Configure initial settings section and all the steps in the Configure remaining settings and create the deployment section.
Note
When you add a new deployment to an endpoint, you can use the Update traffic allocation page to adjust the traffic balance between the deployments. But to follow the rest of the procedures in this article, keep the default traffic allocation of 100 percent to the blue deployment for now and 0 percent to the green deployment.
Test the new deployment
Even though 0 percent of the traffic goes to the green deployment, you can still invoke the endpoint and that deployment. On the endpoint page, you can use the Test tab to test your managed online deployment. To enter sample input and view the results, take the following steps:
On the endpoint page, go to the Test tab.
In the Deployment list, select green.
Go to the sample-request.json file and copy its sample input.
In the studio, paste the sample input into the Input box.
Select Test.
Test the deployment with mirrored traffic
After you test your green deployment, you can mirror a percentage of the live traffic to your endpoint by copying that percentage of traffic and sending it to the green deployment. Traffic mirroring, which is also called shadowing, doesn't change the results returned to clients—100 percent of requests still flow to the blue deployment. The mirrored percentage of the traffic is copied and also submitted to the green deployment so that you can gather metrics and logging without impacting your clients.
Mirroring is useful when you want to validate a new deployment without impacting clients. For example, you can use mirroring to check whether latency is within acceptable bounds or to check that there are no HTTP errors. The use of traffic mirroring, or shadowing, to test a new deployment is also known as shadow testing. The deployment that receives the mirrored traffic, in this case, the green deployment, can also be called the shadow deployment.
Mirroring has the following limitations:
- Mirroring is supported for versions 2.4.0 and later of the Azure Machine Learning CLI and versions 1.0.0 and later of the Python SDK. If you use an older version of the Azure Machine Learning CLI or the Python SDK to update an endpoint, you lose the mirror traffic setting.
- Mirroring isn't currently supported for Kubernetes online endpoints.
- You can mirror traffic to only one deployment in an endpoint.
- The maximum percentage of traffic you can mirror is 50 percent. This cap limits the effect on your endpoint bandwidth quota, which has a default value of 5 MBps. Your endpoint bandwidth is throttled if you exceed the allocated quota. For information about monitoring bandwidth throttling, see Bandwidth throttling.
Also note the following behavior:
- You can configure a deployment to receive only live traffic or mirrored traffic, not both.
- When you invoke an endpoint, you can specify the name of any of its deployments—even a shadow deployment—to return the prediction.
- When you invoke an endpoint and specify the name of a deployment to receive incoming traffic, Azure Machine Learning doesn't mirror traffic to the shadow deployment. Azure Machine Learning mirrors traffic to the shadow deployment from traffic sent to the endpoint when you don't specify a deployment.
If you set the green deployment to receive 10 percent of mirrored traffic, clients still receive predictions from the blue deployment only.
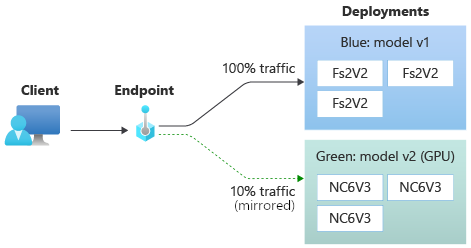
Use the following command to mirror 10 percent of the traffic and send it to the green deployment:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=10"
You can test mirrored traffic by invoking the endpoint several times without specifying a deployment to receive the incoming traffic:
for i in {1..20} ; do
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
done
You can confirm that the specified percentage of the traffic is sent to the green deployment by checking the logs from the deployment:
az ml online-deployment get-logs --name green --endpoint $ENDPOINT_NAME
After testing, you can set the mirror traffic to zero to disable mirroring:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=0"
Use the following code to mirror 10 percent of the traffic and send it to the green deployment:
endpoint.mirror_traffic = {"green": 10}
ml_client.begin_create_or_update(endpoint).result()
You can test mirrored traffic by invoking the endpoint several times without specifying a deployment to receive the incoming traffic:
# You can test mirror traffic by invoking the endpoint several times
for i in range(20):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="../model-1/sample-request.json",
)
You can confirm that the specified percentage of the traffic is sent to the green deployment by checking the logs from the deployment:
ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
After testing, you can set the mirror traffic to zero to disable mirroring:
endpoint.mirror_traffic = {"green": 0}
ml_client.begin_create_or_update(endpoint).result()
To mirror 10 percent of the traffic and send it to the green deployment, take the following steps:
On the endpoint page, go to the Details tab, and then select Update traffic.
Turn on the Enable mirrored traffic toggle.
In the Deployment name list, select green.
Under Traffic allocation %, keep the default value of 10 percent.
Select Update.
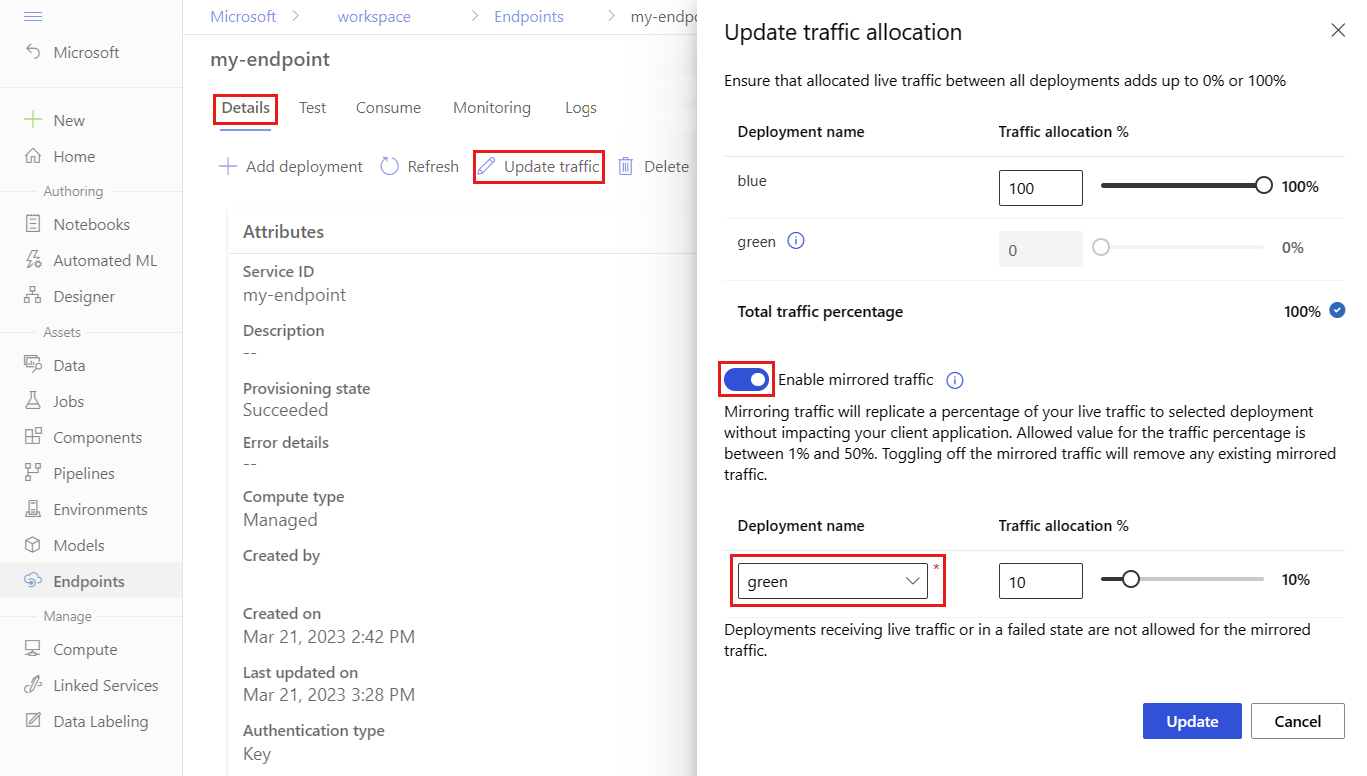
The endpoint details page now shows a mirrored traffic allocation of 10 percent to the green deployment.
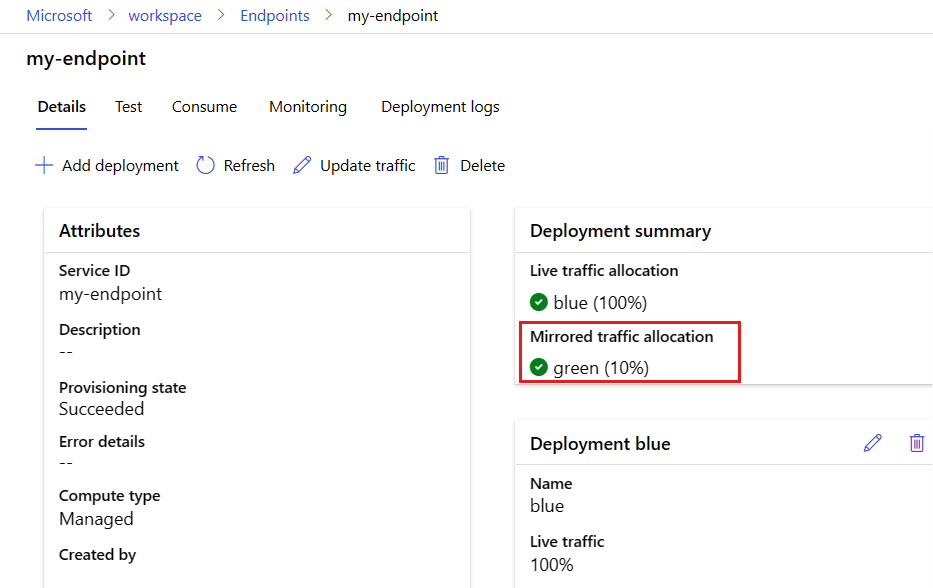
To test mirrored traffic, see the Azure CLI or Python tabs to invoke the endpoint several times. Confirm that the specified percentage of traffic is sent to the green deployment by checking the logs from the deployment. You can access the deployment logs on the endpoint page by going to the Logs tab.
You can also use metrics and logs to monitor the performance of the mirrored traffic. For more information, see Monitor online endpoints.
After testing, you can disable mirroring by taking the following steps:
On the endpoint page, go to the Details tab, and then select Update traffic.
Turn off the Enable mirrored traffic toggle.
Select Update.

Allocate a small percentage of live traffic to the new deployment
After you test your green deployment, allocate a small percentage of traffic to it:
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=90 green=10"
endpoint.traffic = {"blue": 90, "green": 10}
ml_client.begin_create_or_update(endpoint).result()
On the endpoint page, go to the Details tab, and then select Update traffic.
Adjust the deployment traffic by allocating 10 percent to the green deployment and 90 percent to the blue deployment.
Select Update.
Tip
The total traffic percentage must be either 0 percent, to disable traffic, or 100 percent, to enable traffic.
Your green deployment now receives 10 percent of all live traffic. Clients receive predictions from both the blue and green deployments.
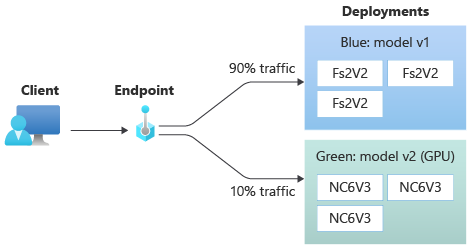
Send all traffic to the new deployment
When you're fully satisfied with your green deployment, switch all traffic to it.
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=0 green=100"
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
On the endpoint page, go to the Details tab, and then select Update traffic.
Adjust the deployment traffic by allocating 100 percent to the green deployment and 0 percent to the blue deployment.
Select Update.
Remove the old deployment
Use the following steps to delete an individual deployment from a managed online endpoint. Deleting an individual deployment doesn't affect the other deployments in the managed online endpoint:
az ml online-deployment delete --name blue --endpoint $ENDPOINT_NAME --yes --no-wait
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).wait()
Note
You can't delete a deployment that has live traffic allocated to it. Before you delete the deployment, you must set the traffic allocation for the deployment to 0 percent.
On the endpoint page, go to the Details tab, and then go to the blue deployment card.
Next to the deployment name, select the delete icon.
Delete the endpoint and deployment
If you aren't going to use the endpoint and deployment, you should delete them. When you delete an endpoint, all its underlying deployments are also deleted.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Go to Azure Machine Learning studio.
Select Endpoints.
Select an endpoint in the list.
Select Delete.
Alternatively, you can delete a managed online endpoint directly in the endpoint page by going to the Details tabs and selecting the delete icon.
Related content












