Configure Apache Spark jobs in Azure Machine Learning
APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
The Azure Machine Learning integration, with Azure Synapse Analytics, provides easy access to distributed computing capability - backed by Azure Synapse - to scale Apache Spark jobs on Azure Machine Learning.
In this article, you learn how to submit a Spark job using Azure Machine Learning serverless Spark compute, Azure Data Lake Storage (ADLS) Gen 2 storage account, and user identity passthrough in a few simple steps.
For more information about Apache Spark in Azure Machine Learning concepts, visit this resource.
Prerequisites
APPLIES TO:
Azure CLI ml extension v2 (current)
- An Azure subscription; if you don't have an Azure subscription, create a free account before you begin.
- An Azure Machine Learning workspace. For more information, visit Create workspace resources.
- An Azure Data Lake Storage (ADLS) Gen 2 storage account. For more information, visit Create an Azure Data Lake Storage (ADLS) Gen 2 storage account.
- Create an Azure Machine Learning compute instance.
- Install Azure Machine Learning CLI.
Add role assignments in Azure storage accounts
Before we submit an Apache Spark job, we must ensure that the input and output data paths are accessible. Assign Contributor and Storage Blob Data Contributor roles to the user identity of the logged-in user, to enable read and write access.
To assign appropriate roles to the user identity:
Open the Microsoft Azure portal.
Search for, and select, the Storage accounts service.

On the Storage accounts page, select the Azure Data Lake Storage (ADLS) Gen 2 storage account from the list. A page showing Overview of the storage account opens.
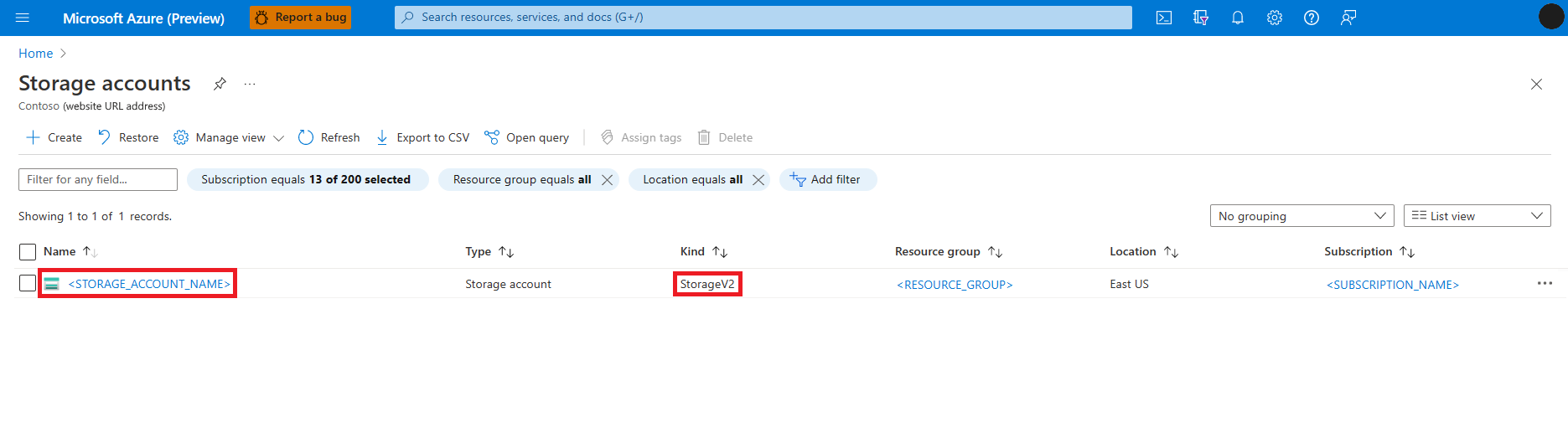
Select Access Control (IAM) from the left panel.
Select Add role assignment.
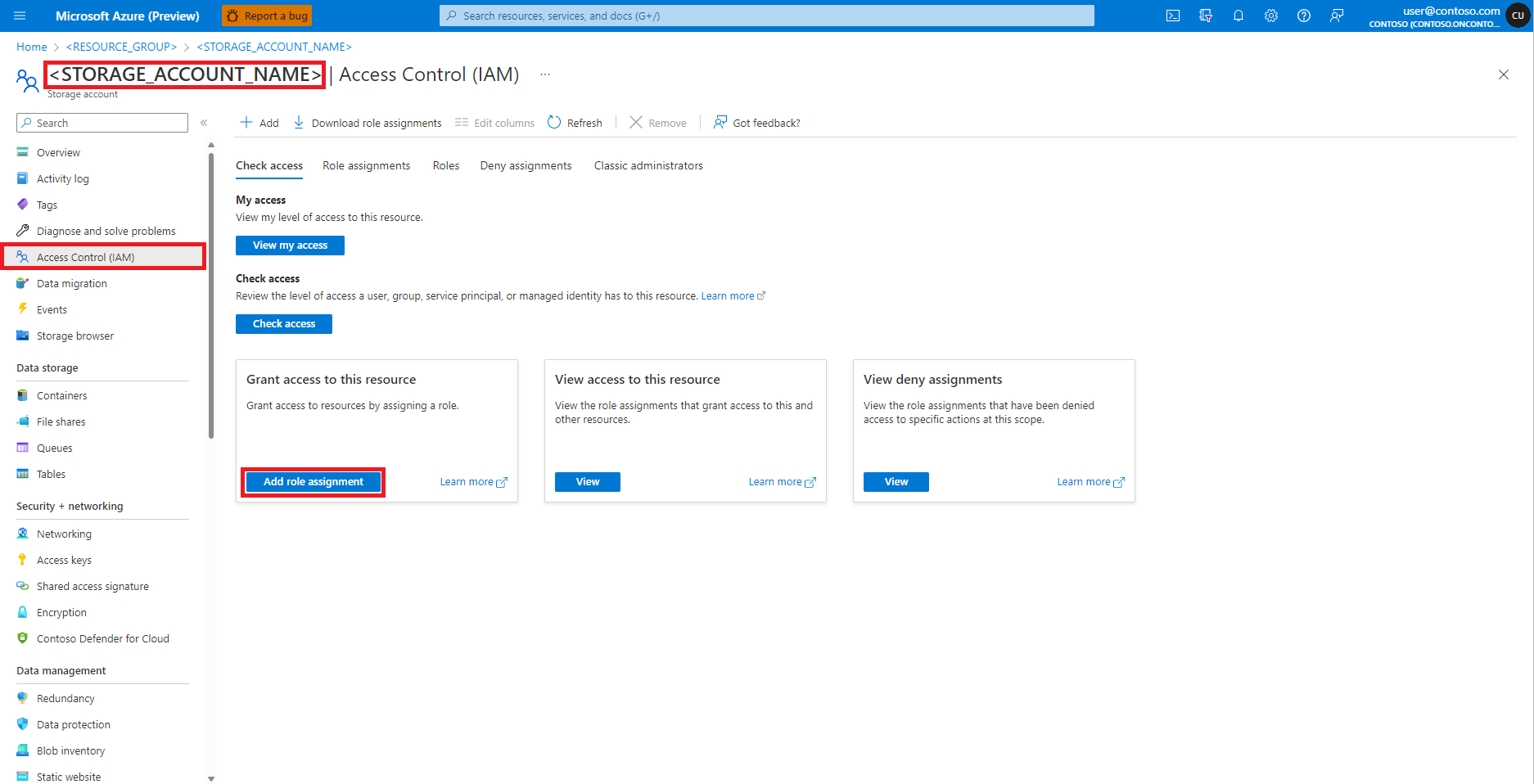
Search for the Storage Blob Data Contributor role.
Select the Storage Blob Data Contributor role.
Select Next.
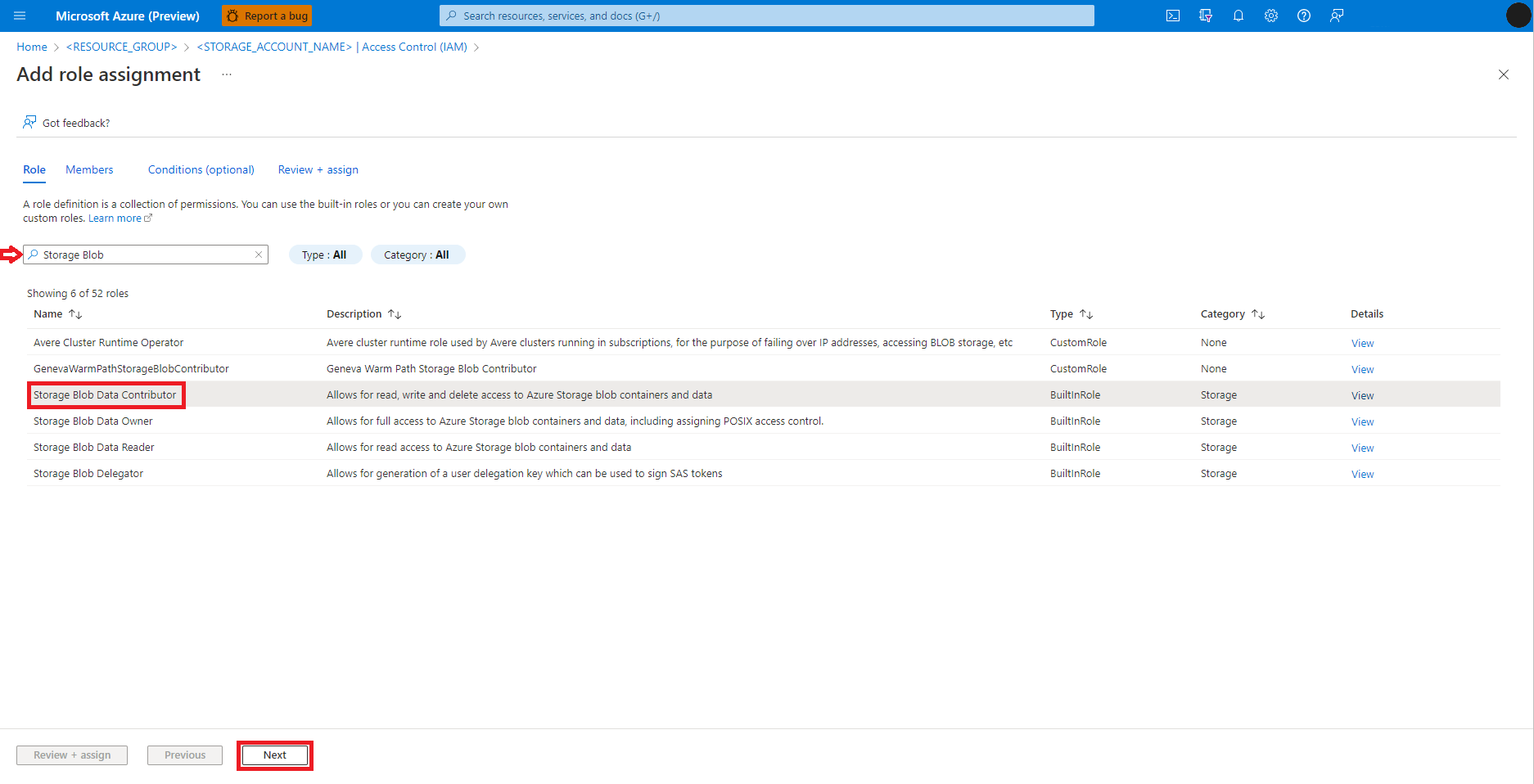
Select User, group, or service principal.
Select + Select members.
In the textbox under Select, search for the user identity.
Select the user identity from the list, so that it shows under Selected members.
Select the appropriate user identity.
Select Next.
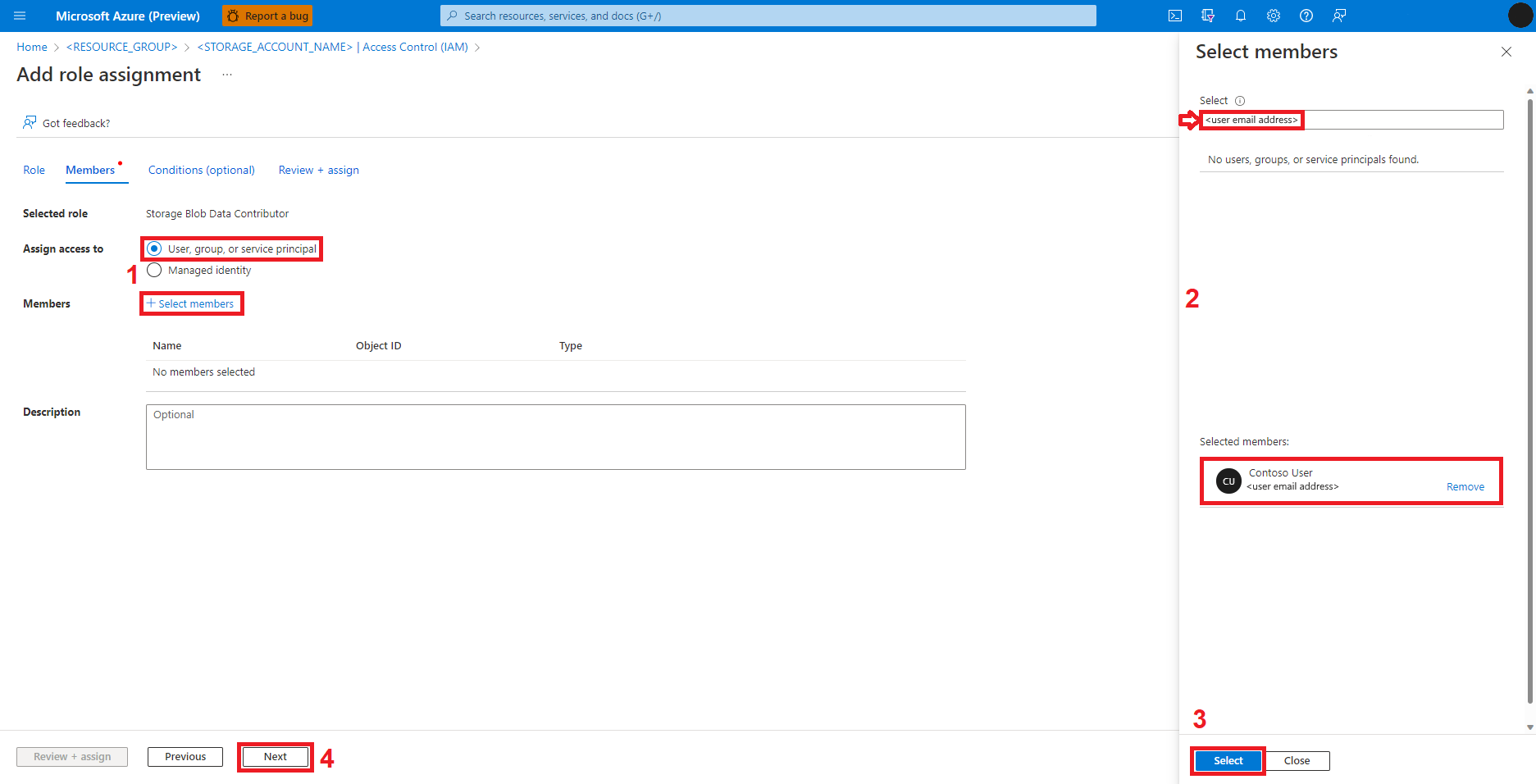
Select Review + Assign.
Repeat steps 2-13 for Storage Blob Contributor role assignment.






Data in the Azure Data Lake Storage (ADLS) Gen 2 storage account should become accessible once the user identity has the appropriate roles assigned.
Create parametrized Python code
A Spark job requires a Python script that accepts arguments. To build this script, you can modify the Python code developed from interactive data wrangling. A sample Python script is shown here:
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Note
- This Python code sample uses
pyspark.pandas, which only Spark runtime version 3.2 supports. - Please ensure that the
titanic.pyfile is uploaded to a folder namedsrc. Thesrcfolder should be located in the same directory where you have created the Python script/notebook or the YAML specification file that defines the standalone Spark job.
That script takes two arguments: --titanic_data and --wrangled_data. These arguments pass the input data path, and the output folder, respectively. The script uses the titanic.csv file, available here. Upload this file to a container created in the Azure Data Lake Storage (ADLS) Gen 2 storage account.
Submit a standalone Spark job
APPLIES TO:
Azure CLI ml extension v2 (current)
Tip
You can submit a Spark job from:
- the terminal of an Azure Machine Learning compute instance.
- the terminal of Visual Studio Code, connected to an Azure Machine Learning compute instance.
- your local computer that has the Azure Machine Learning CLI installed.
This example YAML specification shows a standalone Spark job. It uses an Azure Machine Learning serverless Spark compute, user identity passthrough, and input/output data URI in the abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA> format. Here, <FILE_SYSTEM_NAME> matches the container name.
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./src
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.2"
In the above YAML specification file:
- the
codeproperty defines relative path of the folder containing parameterizedtitanic.pyfile. - the
resourceproperty defines theinstance_typeand the Apache Sparkruntime_versionvalues that serverless Spark compute uses. These instance type values are currently supported:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
The YAML file shown can be used in the az ml job create command, with the --file parameter, to create a standalone Spark job as shown:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Tip
You might have an existing Synapse Spark pool in your Azure Synapse workspace. To use an existing Synapse Spark pool, please follow the instructions to attach a Synapse Spark pool in Azure Machine Learning workspace.
Next steps
- Apache Spark in Azure Machine Learning
- Quickstart: Interactive Data Wrangling with Apache Spark
- Attach and manage a Synapse Spark pool in Azure Machine Learning
- Interactive Data Wrangling with Apache Spark in Azure Machine Learning
- Submit Spark jobs in Azure Machine Learning
- Code samples for Spark jobs using Azure Machine Learning CLI
- Code samples for Spark jobs using Azure Machine Learning Python SDK