Relevance in keyword search (BM25 scoring)
This article explains the BM25 relevance scoring algorithm used to compute search scores for full text search. BM25 relevance is exclusive to full text search. Filter queries, autocomplete and suggested queries, wildcard search or fuzzy search queries aren't scored or ranked for relevance.
Scoring algorithms used in full text search
Azure AI Search provides the following scoring algorithms for full text search:
| Algorithm | Usage | Range |
|---|---|---|
BM25Similarity |
Fixed algorithm on all search services created after July 2020. You can configure this algorithm, but you can't switch to an older one (classic). | Unbounded. |
ClassicSimilarity |
Present on older search services. You can opt-in for BM25 and choose an algorithm on a per-index basis. | 0 < 1.00 |
Both BM25 and Classic are TF-IDF-like retrieval functions that use the term frequency (TF) and the inverse document frequency (IDF) as variables to calculate relevance scores for each document-query pair, which is then used for ranking results. While conceptually similar to classic, BM25 is rooted in probabilistic information retrieval that produces more intuitive matches, as measured by user research.
BM25 offers advanced customization options, such as allowing the user to decide how the relevance score scales with the term frequency of matched terms. For more information, see Configure the scoring algorithm.
Note
If you're using a search service that was created before July 2020, the scoring algorithm is most likely the previous default, ClassicSimilarity, which you can upgrade on a per-index basis. See Enable BM25 scoring on older services for details.
The following video segment fast-forwards to an explanation of the generally available ranking algorithms used in Azure AI Search. You can watch the full video for more background.
How BM25 ranking works
Relevance scoring refers to the computation of a search score (@search.score) that serves as an indicator of an item's relevance in the context of the current query. The range is unbounded. However, the higher the score, the more relevant the item.
The search score is computed based on statistical properties of the string input and the query itself. Azure AI Search finds documents that match on search terms (some or all, depending on searchMode), favoring documents that contain many instances of the search term. The search score goes up even higher if the term is rare across the data index, but common within the document. The basis for this approach to computing relevance is known as TF-IDF or term frequency-inverse document frequency.
Search scores can be repeated throughout a result set. When multiple hits have the same search score, the ordering of the same scored items is undefined and not stable. Run the query again, and you might see items shift position, especially if you're using the free service or a billable service with multiple replicas. Given two items with an identical score, there's no guarantee that one appears first.
To break the tie among repeating scores, you can add an $orderby clause to first order by score, then order by another sortable field (for example, $orderby=search.score() desc,Rating desc). For more information, see $orderby.
Only fields marked as searchable in the index, or searchFields in the query, are used for scoring. Only fields marked as retrievable, or fields specified in select in the query, are returned in search results, along with their search score.
Note
A @search.score = 1 indicates an un-scored or un-ranked result set. The score is uniform across all results. Un-scored results occur when the query form is fuzzy search, wildcard or regex queries, or an empty search (search=*, sometimes paired with filters, where the filter is the primary means for returning a match).
Scores in a text results
Whenever results are ranked, @search.score property contains the value used to order the results.
The following table identifies the scoring property returned on each match, algorithm, and range.
| Search method | Parameter | Scoring algorithm | Range |
|---|---|---|---|
| full text search | @search.score |
BM25 algorithm, using the parameters specified in the index. | Unbounded. |
Score variation
Search scores convey general sense of relevance, reflecting the strength of match relative to other documents in the same result set. But scores aren't always consistent from one query to the next, so as you work with queries, you might notice small discrepancies in how search documents are ordered. There are several explanations for why this might occur.
| Cause | Description |
|---|---|
| Identical scores | If multiple documents have the same score, any one of them might appear first. |
| Data volatility | Index content varies as you add, modify, or delete documents. Term frequencies will change as index updates are processed over time, affecting the search scores of matching documents. |
| Multiple replicas | For services using multiple replicas, queries are issued against each replica in parallel. The index statistics used to calculate a search score are calculated on a per-replica basis, with results merged and ordered in the query response. Replicas are mostly mirrors of each other, but statistics can differ due to small differences in state. For example, one replica might have deleted documents contributing to their statistics, which were merged out of other replicas. Typically, differences in per-replica statistics are more noticeable in smaller indexes. The following section provides more information about this condition. |
Sharding effects on query results
A shard is a chunk of an index. Azure AI Search subdivides an index into shards to make the process of adding partitions faster (by moving shards to new search units). On a search service, shard management is an implementation detail and nonconfigurable, but knowing that an index is sharded helps to understand the occasional anomalies in ranking and autocomplete behaviors:
Ranking anomalies: Search scores are computed at the shard level first, and then aggregated up into a single result set. Depending on the characteristics of shard content, matches from one shard might be ranked higher than matches in another one. If you notice counter intuitive rankings in search results, it's most likely due to the effects of sharding, especially if indexes are small. You can avoid these ranking anomalies by choosing to compute scores globally across the entire index, but doing so will incur a performance penalty.
Autocomplete anomalies: Autocomplete queries, where matches are made on the first several characters of a partially entered term, accept a fuzzy parameter that forgives small deviations in spelling. For autocomplete, fuzzy matching is constrained to terms within the current shard. For example, if a shard contains "Microsoft" and a partial term of "micro" is entered, the search engine will match on "Microsoft" in that shard, but not in other shards that hold the remaining parts of the index.
The following diagram shows the relationship between replicas, partitions, shards, and search units. It shows an example of how a single index is spanned across four search units in a service with two replicas and two partitions. Each of the four search units stores only half of the shards of the index. The search units in the left column store the first half of the shards, comprising the first partition, while those in the right column store the second half of the shards, comprising the second partition. Since there are two replicas, there are two copies of each index shard. The search units in the top row store one copy, comprising the first replica, while those in the bottom row store another copy, comprising the second replica.
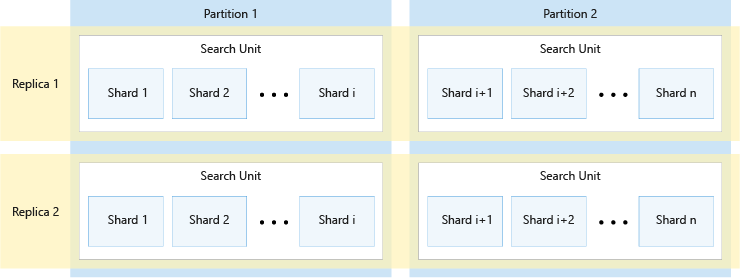
The diagram above is only one example. Many combinations of partitions and replicas are possible, up to a maximum of 36 total search units.
Note
The number of replicas and partitions divides evenly into 12 (specifically, 1, 2, 3, 4, 6, 12). Azure AI Search pre-divides each index into 12 shards so that it can be spread in equal portions across all partitions. For example, if your service has three partitions and you create an index, each partition will contain four shards of the index. How Azure AI Search shards an index is an implementation detail, subject to change in future releases. Although the number is 12 today, you shouldn't expect that number to always be 12 in the future.
Scoring statistics and sticky sessions
For scalability, Azure AI Search distributes each index horizontally through a sharding process, which means that portions of an index are physically separate.
By default, the score of a document is calculated based on statistical properties of the data within a shard. This approach is generally not a problem for a large corpus of data, and it provides better performance than having to calculate the score based on information across all shards. That said, using this performance optimization could cause two very similar documents (or even identical documents) to end up with different relevance scores if they end up in different shards.
If you prefer to compute the score based on the statistical properties across all shards, you can do so by adding scoringStatistics=global as a query parameter (or add "scoringStatistics": "global" as a body parameter of the query request).
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
Using scoringStatistics will ensure that all shards in the same replica provide the same results. That said, different replicas may be slightly different from one another as they're always getting updated with the latest changes to your index. In some scenarios, you may want your users to get more consistent results during a "query session". In such scenarios, you can provide a sessionId as part of your queries. The sessionId is a unique string that you create to refer to a unique user session.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
As long as the same sessionId is used, a best-effort attempt is made to target the same replica, increasing the consistency of results your users will see.
Note
Reusing the same sessionId values repeatedly can interfere with the load balancing of the requests across replicas and adversely affect the performance of the search service. The value used as sessionId cannot start with a '_' character.
Relevance tuning
In Azure AI Search, you can configure BM25 algorithm parameters, and tune search relevance and boost search scores through these mechanisms:
| Approach | Implementation | Description |
|---|---|---|
| Scoring algorithm configuration | Search index | |
| Scoring profiles | Search index | Provide criteria for boosting the search score of a match based on content characteristics. For example, you might want to boost matches based on their revenue potential, promote newer items, or perhaps boost items that have been in inventory too long. A scoring profile is part of the index definition, composed of weighted fields, functions, and parameters. You can update an existing index with scoring profile changes, without incurring an index rebuild. |
| Semantic ranking | Query request | Applies machine reading comprehension to search results, promoting more semantically relevant results to the top. |
| featuresMode parameter | Query request | This parameter is mostly used for unpacking a BM25-ranked score, but it can be used for in code that provides a custom scoring solution. |
featuresMode parameter (preview)
Search Documents requests support a featuresMode parameter that provides more detail about a BM25 relevance score at the field level. Whereas the @searchScore is calculated for the document all-up (how relevant is this document in the context of this query), featuresMode reveals information about individual fields, as expressed in a @search.features structure. The structure contains all fields used in the query (either specific fields through searchFields in a query, or all fields attributed as searchable in an index).
For each field, @search.features give you the following values:
- Number of unique tokens found in the field
- Similarity score, or a measure of how similar the content of the field is, relative to the query term
- Term frequency, or the number of times the query term was found in the field
For a query that targets the "description" and "title" fields, a response that includes @search.features might look like this:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
You can consume these data points in custom scoring solutions or use the information to debug search relevance problems.
The featuresMode parameter isn't documented in the REST APIs, but you can use it on a preview REST API call to Search Documents for text (Keyword) search that's BM25-ranked.
Number of ranked results in a full text query response
By default, if you aren't using pagination, the search engine returns the top 50 highest ranking matches for full text search. You can use the top parameter to return a smaller or larger number of items (up to 1000 in a single response). Full text search is subject to a maximum limit of 1,000 matches (see API response limits). Once 1,000 matches are found, the search engine no longer looks for more.
To return more or less results, use the paging parameters top, skip, and next. Paging is how you determine the number of results on each logical page and navigate through the full payload. For more information, see How to work with search results.