Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article explains search results composition and how to shape full text search results to fit your scenarios. Search results are returned in a query response. The shape of a response is determined by parameters in the query itself. These parameters include:
- Number of matches found in the index (
count) - Number of matches returned in the response (50 by default, configurable through
top) or per page (skipandtop) - A search score for each result, used for ranking (
@search.score) - Fields included in search results (
select) - Sort logic (
orderby) - Highlighting of terms within a result, matching on either the whole or partial term in the body
- Optional elements from the semantic ranker (
answersat the top,captionsfor each match)
Search results can include top-level fields, but most of the response consists of matching documents in an array.
Clients and APIs for defining the query response
You can use the following clients to configure a query response:
- Search Explorer in the Azure portal, using JSON view so that you can specify any supported parameter
- Documents - POST (REST APIs)
- SearchClient.Search Method (Azure SDK for .NET)
- SearchClient.Search Method (Azure SDK for Python)
- SearchClient.Search Method (Azure for JavaScript)
- SearchClient.Search Method (Azure for Java)
Result composition
Results are mostly tabular, composed of fields of either all retrievable fields, or limited to just those fields specified in the select parameter. Rows are the matching documents, typically ranked in order of relevance unless your query logic precludes relevance ranking.
You can choose which fields are in search results. While a search document might have a large number of fields, typically only a few are needed to represent each document in results. On a query request, append select=<field list> to specify which retrievable fields should appear in the response.
Pick fields that offer contrast and differentiation among documents, providing sufficient information to invite a clickthrough response on the part of the user. On an e-commerce site, it might be a product name, description, brand, color, size, price, and rating. For the built-in hotels-sample index, it might be the "select" fields in the following example:
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City",
"count": true
}
Tips for unexpected results
Occasionally, query output isn't what you're expecting to see. For example, you might find that some results appear to be duplicates, or a result that should appear near the top is positioned lower in the results. When query outcomes are unexpected, you can try these query modifications to see if results improve:
Change
searchMode=any(default) tosearchMode=allto require matches on all criteria instead of any of the criteria. This is especially true when boolean operators are included the query.Experiment with different lexical analyzers or custom analyzers to see if it changes the query outcome. The default analyzer breaks up hyphenated words and reduces words to root forms, which usually improves the robustness of a query response. However, if you need to preserve hyphens, or if strings include special characters, you might need to configure custom analyzers to ensure the index contains tokens in the right format. For more information, see Partial term search and patterns with special characters (hyphens, wildcard, regex, patterns).
Counting matches
The count parameter returns the number of documents in the index that are considered a match for the query. To return the count, add count=true to the query request. There's no maximum value imposed by the search service. Depending on your query and the content of your documents, the count could be as high as every document in the index.
Count is accurate when the index is stable. If the system is actively adding, updating, or deleting documents, the count is approximate, excluding any documents that aren't fully indexed.
Count won't be affected by routine maintenance or other workloads on the search service. However if you have multiple partitions and a single replica, you could experience short-term fluctuations in document count (several minutes) as the partitions are restarted.
Tip
To check indexing operations, you can confirm whether the index contains the expected number of documents by adding count=true on an empty search search=* query. The result is the full count of documents in your index.
When testing query syntax, count=true can quickly tell you whether your modifications are returning greater or fewer results, which can be useful feedback.
Number of results in the response
Azure AI Search uses server-side paging to prevent queries from retrieving too many documents at once. Query parameters that determine the number of results in a response are top and skip. top refers to the number of search results in a page. skip is an interval of top, and it tells the search engine how many results to skip before getting the next set.
The default page size is 50, while the maximum page size is 1,000. If you specify a value greater than 1,000 and there are more than 1,000 results found in your index, only the first 1,000 results are returned. If the number of matches exceed the page size, the response includes information to retrieve the next page of results. For example:
"@odata.nextLink": "https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01"
The top matches are determined by search score, assuming the query is full text search or semantic. Otherwise, the top matches are an arbitrary order for exact match queries (where uniform @search.score=1.0 indicates arbitrary ranking).
Set top to override the default of 50. In newer preview APIs, if you're using a hybrid query, you can specify maxTextRecallSize to return up to 10,000 documents.
To control the paging of all documents returned in a result set, use top and skip together. This query returns the first set of 15 matching documents plus a count of total matches.
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 0
}
This query returns the second set, skipping the first 15 to get the next 15 (16 through 30):
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 15
}
The results of paginated queries aren't guaranteed to be stable if the underlying index is changing. Paging changes the value of skip for each page, but each query is independent and operates on the current view of the data as it exists in the index at query time (in other words, there's no caching or snapshot of results, such as those found in a general purpose database).
Following is an example of how you might get duplicates. Assume an index with four documents:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Now assume you want results returned two at a time, ordered by rating. You would execute this query to get the first page of results: $top=2&$skip=0&$orderby=rating desc, producing the following results:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
On the service, assume a fifth document is added to the index in between query calls: { "id": "5", "rating": 4 }. Shortly thereafter, you execute a query to fetch the second page: $top=2&$skip=2&$orderby=rating desc, and get these results:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
Notice that document 2 is fetched twice. This is because the new document 5 has a greater value for rating, so it sorts before document 2 and lands on the first page. While this behavior might be unexpected, it's typical of how a search engine behaves.
Paging through a large number of results
An alternative technique for paging is to use a sort order and range filter as a workaround for skip.
In this workaround, sort and filter are applied to a document ID field or another field that is unique for each document. The unique field must have filterable and sortable attribution in the search index.
Issue a query to return a full page of sorted results.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Choose the last result returned by the search query. An example result with only an ID value is shown here.
{ "id": "50" }Use that ID value in a range query to fetch the next page of results. This ID field should have unique values, otherwise pagination might include duplicate results.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }Pagination ends when the query returns zero results.
Note
The filterable and sortable attributes can only be enabled when a field is first added to an index, they cannot be enabled on an existing field.
Ordering results
In a full text search query, results can be ranked by:
- a search score
- a semantic reranker score
- a sort order on a
sortablefield
You can also boost any matches found in specific fields by adding a scoring profile.
Order by search score
For full text search queries, results are automatically ranked by a search score using a BM25 algorithm, calculated based on term frequency, document length, and average document length.
The @search.score range is either unbounded, or 0 up to (but not including) 1.00 on older services.
For either algorithm, a @search.score equal to 1.00 indicates an unscored or unranked result set, where the 1.0 score is uniform across all results. Unscored results occur when the query form is fuzzy search, wildcard or regex queries, or an empty search (search=*). If you need to impose a ranking structure over unscored results, consider an orderby expression to achieve that objective.
Order by the semantic reranker
If you're using semantic ranker, the @search.rerankerScore determines the sort order of your results.
The @search.rerankerScore range is 1 to 4.00, where a higher score indicates a stronger semantic match.
Order with orderby
If consistent ordering is an application requirement, you can define an orderby expression on a field. Only fields that are indexed as "sortable" can be used to order results.
Fields commonly used in an orderby include rating, date, and location. Filtering by location requires that the filter expression calls the geo.distance() function, in addition to the field name.
Numeric fields (Edm.Double, Edm.Int32, Edm.Int64) are sorted in numeric order (for example, 1, 2, 10, 11, 20).
String fields (Edm.String, Edm.ComplexType subfields) are sorted in either ASCII sort order or Unicode sort order, depending on the language.
Numeric content in string fields is sorted alphabetically (1, 10, 11, 2, 20).
Upper case strings are sorted ahead of lower case (APPLE, Apple, BANANA, Banana, apple, banana). You can assign a text normalizer to preprocess the text before sorting to change this behavior. Using the lowercase tokenizer on a field has no effect on sorting behavior because Azure AI Search sorts on a nonanalyzed copy of the field.
Strings that lead with diacritics appear last (Äpfel, Öffnen, Üben)
Boost relevance using a scoring profile
Another approach that promotes order consistency is using a custom scoring profile. Scoring profiles give you more control over the ranking of items in search results, with the ability to boost matches found in specific fields. The extra scoring logic can help override minor differences among replicas because the search scores for each document are farther apart. We recommend the ranking algorithm for this approach.
Hit highlighting
Hit highlighting refers to text formatting (such as bold or yellow highlights) applied to matching terms in a result, making it easy to spot the match. Highlighting is useful for longer content fields, such as a description field, where the match isn't immediately obvious.
Notice that highlighting is applied to individual terms. There's no highlight capability for the contents of an entire field. If you want to highlight over a phrase, you have to provide the matching terms (or phrase) in a quote-enclosed query string. This technique is described further on in this section.
Hit highlighting instructions are provided on the query request. Queries that trigger query expansion in the engine, such as fuzzy and wildcard search, have limited support for hit highlighting.
Requirements for hit highlighting
- Fields must be
Edm.StringorCollection(Edm.String) - Fields must be attributed at
searchable
Specify highlighting in the request
To return highlighted terms, include the highlight parameter in the query request. The parameter is set to a comma-delimited list of fields.
By default, the format mark up is <em>, but you can override the tag using highlightPreTag and highlightPostTag parameters. Your client code handles the response (for example, applying a bold font or a yellow background).
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
By default, Azure AI Search returns up to five highlights per field. You can adjust this number by appending a dash followed by an integer. For example, "highlight": "description-10" returns up to 10 highlighted terms on matching content in the description field.
Highlighted results
When highlighting is added to the query, the response includes an @search.highlights for each result so that your application code can target that structure. The list of fields specified for "highlight" are included in the response.
In a keyword search, each term is scanned for independently. A query for "divine secrets" returns matches on any document containing either term.
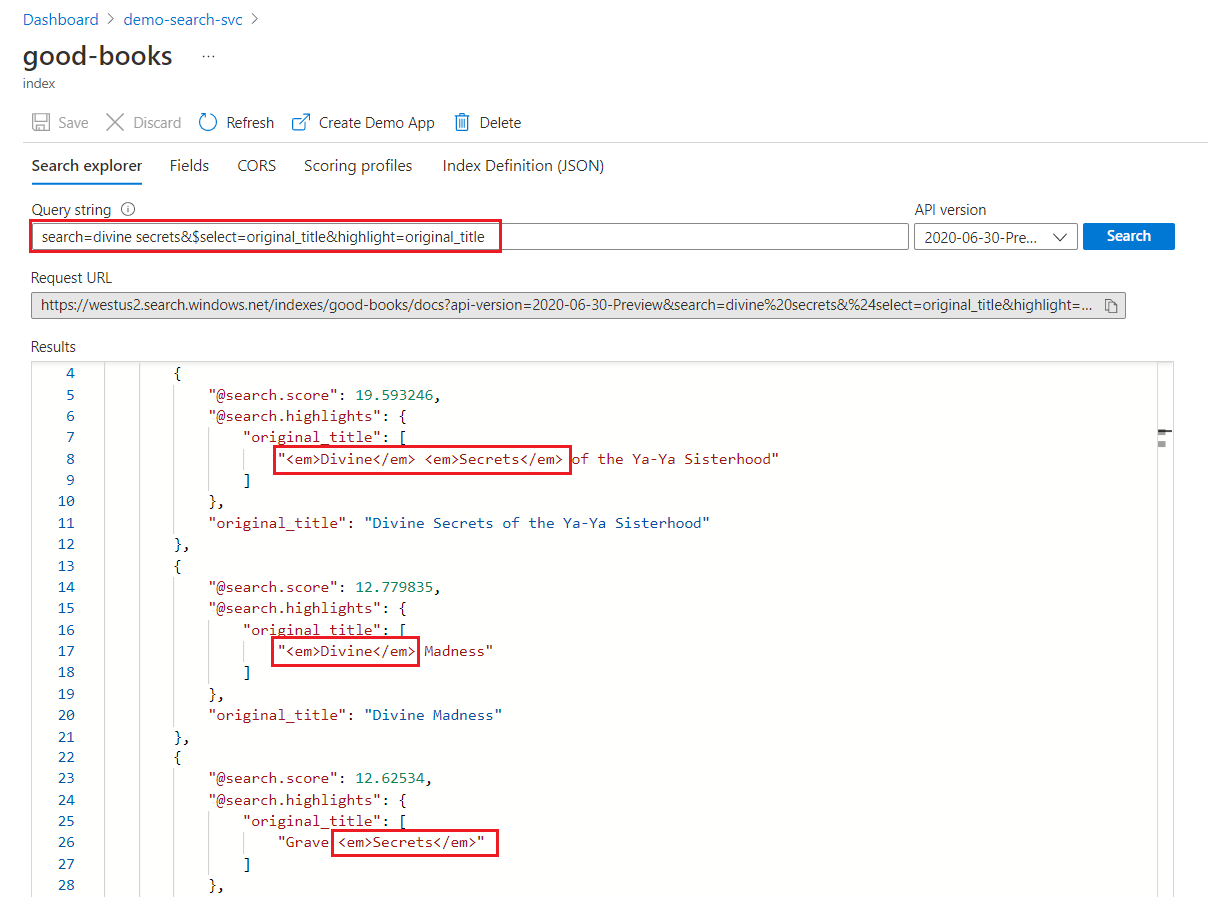
Keyword search highlighting
Within a highlighted field, formatting is applied to whole terms. For example, on a match against "The Divine Secrets of the Ya-Ya Sisterhood", formatting is applied to each term separately, even though they're consecutive.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Phrase search highlighting
Whole-term formatting applies even on a phrase search, where multiple terms are enclosed in double quotation marks. The following example is the same query, except that "divine secrets" is submitted as a quotation-enclosed phrase (some REST clients require that you escape the interior quotation marks with a backslash \"):
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Because the criteria now have both terms, only one match is found in the search index. The response to the previous query looks like this:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Phrase highlighting on older services
Search services that were created before July 15, 2020 implement a different highlighting experience for phrase queries.
For the following examples, assume a query string that includes the quote-enclosed phrase "super bowl". Before July 2020, any term in the phrase is highlighted:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
For search services created after July 2020, only phrases that match the full phrase query are returned in @search.highlights:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Next steps
To quickly generate a search page for your client, consider these options:
Create demo app, in the Azure portal, creates an HTML page with a search bar, faceted navigation, and a thumbnail area if you have images.
Add search to an ASP.NET Core (MVC) app is a tutorial and code sample that builds a functional client.
Add search to web apps is a C# tutorial and code sample that uses the React JavaScript libraries for the user experience. The app is deployed using Azure Static Web Apps and it implements pagination.