Tutorial: Use Pandas to read/write Azure Data Lake Storage Gen2 data in serverless Apache Spark pool in Synapse Analytics
Learn how to use Pandas to read/write data to Azure Data Lake Storage Gen2 (ADLS) using a serverless Apache Spark pool in Azure Synapse Analytics. Examples in this tutorial show you how to read csv data with Pandas in Synapse, as well as excel and parquet files.
In this tutorial, you'll learn how to:
- Read/write ADLS Gen2 data using Pandas in a Spark session.
If you don't have an Azure subscription, create a free account before you begin.
Prerequisites
Azure Synapse Analytics workspace with an Azure Data Lake Storage Gen2 storage account configured as the default storage (or primary storage). You need to be the Storage Blob Data Contributor of the Data Lake Storage Gen2 file system that you work with.
Serverless Apache Spark pool in your Azure Synapse Analytics workspace. For details, see Create a Spark pool in Azure Synapse.
Configure Secondary Azure Data Lake Storage Gen2 account (which is not default to Synapse workspace). You need to be the Storage Blob Data Contributor of the Data Lake Storage Gen2 file system that you work with.
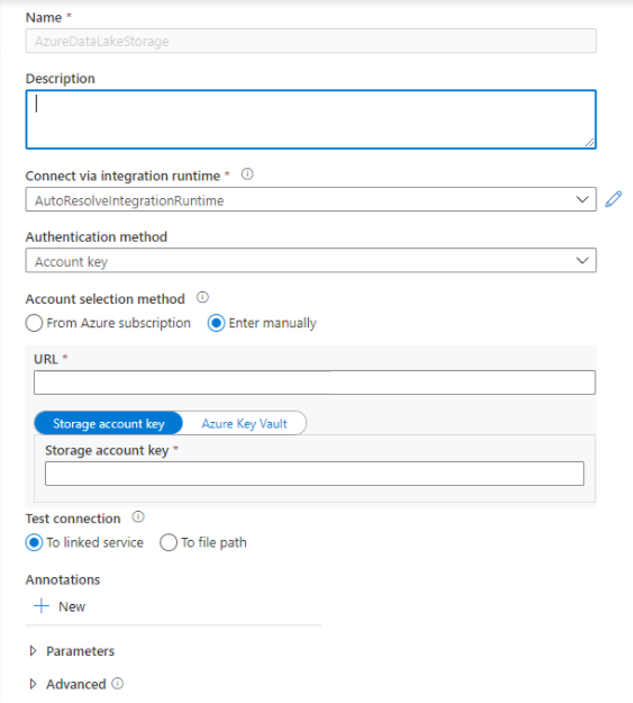
Create linked services - In Azure Synapse Analytics, a linked service defines your connection information to the service. In this tutorial, you'll add an Azure Synapse Analytics and Azure Data Lake Storage Gen2 linked service.
- Open the Azure Synapse Studio and select the Manage tab.
- Under External connections, select Linked services.
- To add a linked service, select New.
- Select the Azure Data Lake Storage Gen2 tile from the list and select Continue.
- Enter your authentication credentials. Account key, service principal (SP), Credentials and Manged service identity (MSI) are currently supported authentication types. Make sure that Storage Blob Data Contributor is assigned on storage for SP and MSI before you choose it for authentication. Test connection to verify your credentials are correct. Select Create.
Important
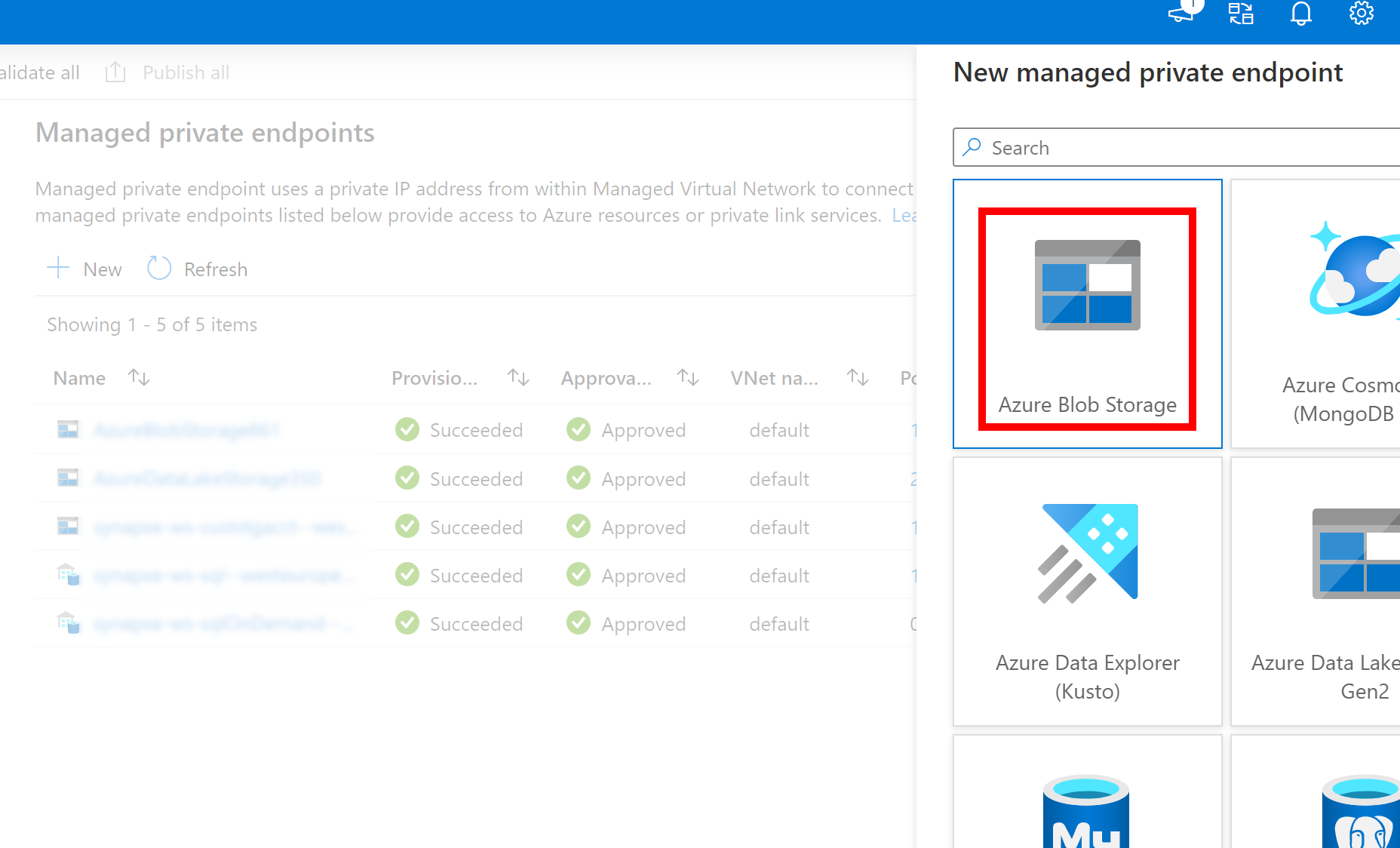
- If the above created Linked Service to Azure Data Lake Storage Gen2 uses a managed private endpoint (with a dfs URI) , then we need to create another secondary managed private endpoint using the Azure Blob Storage option (with a blob URI) to ensure that the internal fsspec/adlfs code can connect using the BlobServiceClient interface.
- In case the secondary managed private endpoint is not configured correctly, then we would see an error message like ServiceRequestError: Cannot connect to host [storageaccountname].blob.core.windows.net:443 ssl:True [Name or service not known]
Note
- Pandas feature is supported on Python 3.8 and Spark3 serverless Apache Spark pool in Azure Synapse Analytics.
- Support available for following versions: pandas 1.2.3, fsspec 2021.10.0, adlfs 0.7.7
- Have capabilities to support both Azure Data Lake Storage Gen2 URI (abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path) and FSSPEC short URL (abfs[s]://container_name/file_path).
Sign in to the Azure portal
Sign in to the Azure portal.
Read/Write data to default ADLS storage account of Synapse workspace
Pandas can read/write ADLS data by specifying the file path directly.
Run the following code.
Note
Update the file URL in this script before running it.
#Read data file from URI of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://container_name/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path')
Read/Write data using secondary ADLS account
Pandas can read/write secondary ADLS account data:
- using linked service (with authentication options - storage account key, service principal, manages service identity and credentials).
- using storage options to directly pass client ID & Secret, SAS key, storage account key and connection string.
Using linked service
Run the following code.
Note
Update the file URL and linked service name in this script before running it.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'linked_service' : 'linked_service_name'})
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
Using storage options to directly pass client ID & Secret, SAS key, storage account key, and connection string.
Run the following code.
Note
Update the file URL and storage_options in this script before running it.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
Example to read/write parquet file
Run the following code.
Note
Update the file URL in this script before running it.
import pandas
#read parquet file
df = pandas.read_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
print(df)
#write parquet file
df.to_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
Example to read/write excel file
Run the following code.
Note
Update the file URL in this script before running it.
import pandas
#read excel file
df = pandas.read_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ excel_file_path')
print(df)
#write excel file
df.to_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/excel_file_path')
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for