Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Tip
Microsoft Fabric Data Warehouse is an enterprise scale relational warehouse on a data lake foundation, with a future-ready architecture, built-in AI, and new features. If you're new to data warehousing, start with Fabric Data Warehouse. Existing dedicated SQL pool workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
This cheat sheet provides helpful tips and best practices for building dedicated SQL pool (formerly SQL DW) solutions.
The following graphic shows the process of designing a data warehouse with dedicated SQL pool (formerly SQL DW):
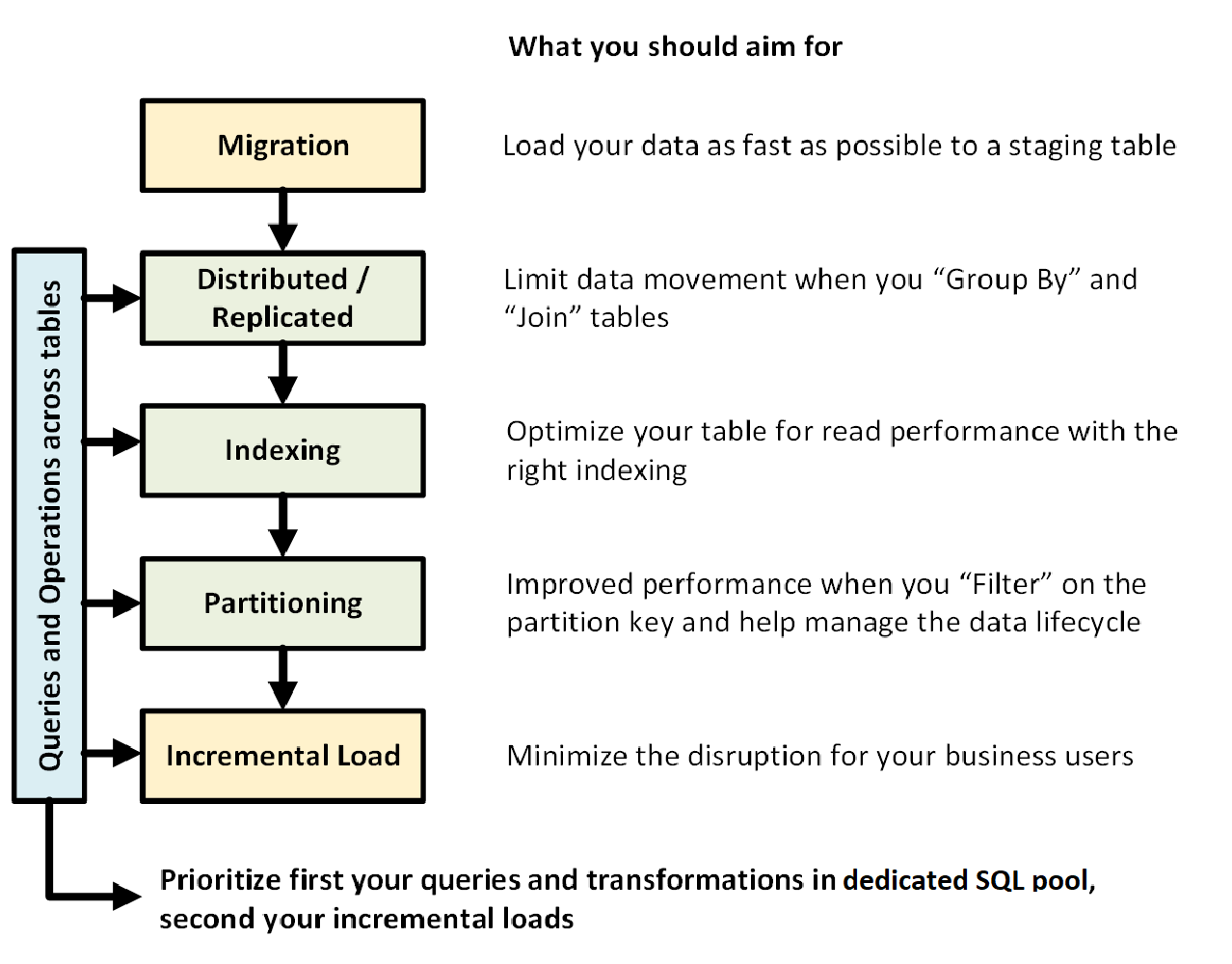
Queries and operations across tables
When you know in advance the primary operations and queries to be run in your data warehouse, you can prioritize your data warehouse architecture for those operations. These queries and operations might include:
- Joining one or two fact tables with dimension tables, filtering the combined table, and then appending the results into a data mart.
- Making large or small updates into your fact sales.
- Appending only data to your tables.
Knowing the types of operations in advance helps you optimize the design of your tables.
Data migration
First, load your data into Azure Data Lake Storage or Azure Blob Storage. Next, use the COPY statement to load your data into staging tables. Use the following configuration:
| Design | Recommendation |
|---|---|
| Distribution | Round Robin |
| Indexing | Heap |
| Partitioning | None |
| Resource Class | largerc or xlargerc |
Learn more about data migration, data loading, and the Extract, Load, and Transform (ELT) process.
Distributed or replicated tables
Use the following strategies, depending on the table properties:
| Type | Great fit for... | Watch out if... |
|---|---|---|
| Replicated | * Small dimension tables in a star schema with less than 2 GB of storage after compression (~5x compression) | * Many write transactions are on table (such as insert, upsert, delete, update) * You change Data Warehouse Units (DWU) provisioning frequently * You only use 2-3 columns but your table has many columns * You index a replicated table |
| Round Robin (default) | * Temporary/staging table * No obvious joining key or good candidate column |
* Performance is slow due to data movement |
| Hash | * Fact tables * Large dimension tables |
* The distribution key can't be updated |
Tips:
- Start with Round Robin, but aspire to a hash distribution strategy to take advantage of a massively parallel architecture.
- Make sure that common hash keys have the same data format.
- Don't distribute on varchar format.
- Dimension tables with a common hash key to a fact table with frequent join operations can be hash distributed.
- Use sys.dm_pdw_nodes_db_partition_stats to analyze any skewness in the data.
- Use sys.dm_pdw_request_steps to analyze data movements behind queries, monitor the time broadcast, and shuffle operations take. This is helpful to review your distribution strategy.
Learn more about replicated tables and distributed tables.
Index your table
Indexing is helpful for reading tables quickly. There is a unique set of technologies that you can use based on your needs:
| Type | Great fit for... | Watch out if... |
|---|---|---|
| Heap | * Staging/temporary table * Small tables with small lookups |
* Any lookup scans the full table |
| Clustered index | * Tables with up to 100 million rows * Large tables (more than 100 million rows) with only 1-2 columns heavily used |
* Used on a replicated table * You have complex queries involving multiple join and Group By operations * You make updates on the indexed columns: it takes memory |
| Clustered columnstore index (CCI) (default) | * Large tables (more than 100 million rows) | * Used on a replicated table * You make massive update operations on your table * You overpartition your table: row groups don't span across different distribution nodes and partitions |
Tips:
- On top of a clustered index, you might want to add a nonclustered index to a column heavily used for filtering.
- Be careful how you manage the memory on a table with CCI. When you load data, you want the user (or the query) to benefit from a large resource class. Make sure to avoid trimming and creating many small compressed row groups.
- On Gen2, CCI tables are cached locally on the compute nodes to maximize performance.
- For CCI, slow performance can happen due to poor compression of your row groups. If this occurs, rebuild or reorganize your CCI. You want at least 100,000 rows per compressed row groups. The ideal is 1 million rows in a row group.
- Based on the incremental load frequency and size, you want to automate when you reorganize or rebuild your indexes. Spring cleaning is always helpful.
- Be strategic when you want to trim a row group. How large are the open row groups? How much data do you expect to load in the coming days?
Learn more about indexes.
Partitioning
You might partition your table when you have a large fact table (greater than 1 billion rows). In 99 percent of cases, the partition key should be based on date.
With staging tables that require ELT, you can benefit from partitioning. It facilitates data lifecycle management. Be careful not to overpartition your fact or staging table, especially on a clustered columnstore index.
Learn more about partitions.
Incremental load
If you're going to incrementally load your data, first make sure that you allocate larger resource classes to loading your data. This is particularly important when loading into tables with clustered columnstore indexes. See resource classes for further details.
We recommend using PolyBase and ADF V2 for automating your ELT pipelines into your data warehouse.
For a large batch of updates in your historical data, consider using a CTAS to write the data you want to keep in a table rather than using INSERT, UPDATE, and DELETE.
Maintain statistics
It's important to update statistics as significant changes happen to your data. See update statistics to determine if significant changes have occurred. Updated statistics optimize your query plans. If you find that it takes too long to maintain all of your statistics, be more selective about which columns have statistics.
You can also define the frequency of the updates. For example, you might want to update date columns, where new values might be added, on a daily basis. You gain the most benefit by having statistics on columns involved in joins, columns used in the WHERE clause, and columns found in GROUP BY.
Learn more about statistics.
Resource class
Resource groups are used as a way to allocate memory to queries. If you need more memory to improve query or loading speed, you should allocate higher resource classes. On the flip side, using larger resource classes impacts concurrency. You want to take that into consideration before moving all of your users to a large resource class.
If you notice that queries take too long, check that your users don't run in large resource classes. Large resource classes consume many concurrency slots. They can cause other queries to queue up.
Finally, by using Gen2 of dedicated SQL pool (formerly SQL DW), each resource class gets 2.5 times more memory than Gen1.
Learn more how to work with resource classes and concurrency.
Lower your cost
A key feature of Azure Synapse is the ability to manage compute resources. You can pause your dedicated SQL pool (formerly SQL DW) when you're not using it, which stops the billing of compute resources. You can scale resources to meet your performance demands. To pause, use the Azure portal or PowerShell. To scale, use the Azure portal, PowerShell, T-SQL, or a REST API.
Autoscale now at the time you want with Azure Functions:

Optimize your architecture for performance
We recommend considering SQL Database and Azure Analysis Services in a hub-and-spoke architecture. This solution can provide workload isolation between different user groups while also using advanced security features from SQL Database and Azure Analysis Services. This is also a way to provide limitless concurrency to your users.
Learn more about typical architectures that take advantage of dedicated SQL pool (formerly SQL DW) in Azure Synapse Analytics.
Deploy your spokes in SQL databases from dedicated SQL pool (formerly SQL DW):