Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This solution showcases the implementation of DataOps best practices to create a Modern Data Warehouse (MDW) using the Medallion architecture and a data lake. The MDW is a popular architectural pattern for building analytical data pipelines in a cloud-first environment. It serves as a foundation to support advanced analytical workloads, such as machine learning (ML), in addition to traditional ones, like business intelligence (BI).
Learn about the traditional data warehouse vs the Modern Data Warehouse
The modern data warehouse unlocks advanced capabilities related to analytics that would otherwise be difficult to achieve with traditional data warehousing architectures. In a traditional data warehouse, data pipelines, and the relevant dimensional model (star schema) are built based on known reporting requirements. So, analytics requirements on a traditional data warehouse can be achieved using a top-down (deductive) approach. For advanced analytical requirements in machine learning use cases, the reporting outputs are initially unknown. As a result, data scientists need to undergo an iterative exploratory analysis phase to uncover insights in raw datasets and their relevance to the outcome. This approach can be described as a bottom-up (inductive) method.
The following diagram shows the different types of analytics that can be done using both traditional and modern data warehouses:

Compared to a traditional RDBMS data warehouse, a data lake is the primary means of data storage in an MDW. Data lakes support storage of both structured and unstructured datasets, which is required for advanced analytics use cases. Data lake also enables schema-on-read access, which is crucial for exploratory analysis. The RDBMS data warehouse is still an important component of the MDW architecture but is now used as a serving layer to enable traditional business intelligence reporting.
The mechanism of loading data is also different. While extract-transform-load (ETL) (SQL Server Integration Services (SSIS) is an example) is preferred in traditional data warehousing, extract-load-transform (ELT) is preferred in MDW. In MDW with ELT, data is first ingested into the data lake as-is and then transformed.
Learn about the Modern Data Warehouse architecture
The following are the four stages in an MDW architecture:
- Ingest: Different data sources are ingested and persisted into the data lake.
- Transform: Data is validated and transformed into a predetermined schema.
- Model: Data is then modeled into a form optimized for consumption (for example, Star schema).
- Serve: Data is exposed for consumption. It includes enabling visualization and analysis by end users.
The following functional components of the architecture enable these four stages:
- Storage: The primary role of the storage component is to act as the main storage for both the data lake and the relevant serving layers. For details, see Understanding data lake section.
- Compute: Includes compute for the ingest, transform, and serve stages. Common data computing frameworks include: Apache Spark (available through Azure Synapse Spark pools or Azure Databricks), Azure Data Factory (ADF) data flows, and Azure Synapse SQL dedicated pools (particularly for the serving layer).
- Orchestrator: Responsible for end-to-end orchestration of the data pipeline. Azure Data Factory and Azure Synapse data pipelines are common data orchestrators.
The nonfunctional components that need to be considered are:
Security: Includes platform, application, and data security.
Data governance: Ensures datasets are governed and cataloged along with their captured lineage.
Operability (DevOps): Refers to DevOps practices to ensure efficient operations of the data system, including CI/CD, automated testing, and monitoring.
Learn about the MDW logical architecture
The diagram shows the logical MDW architecture along with its functional components:

The diagram shows the logical MDW architecture with corresponding Azure services. The list of Azure services is nonexhaustive.

Here are a few samples of implementing an MDW architecture:

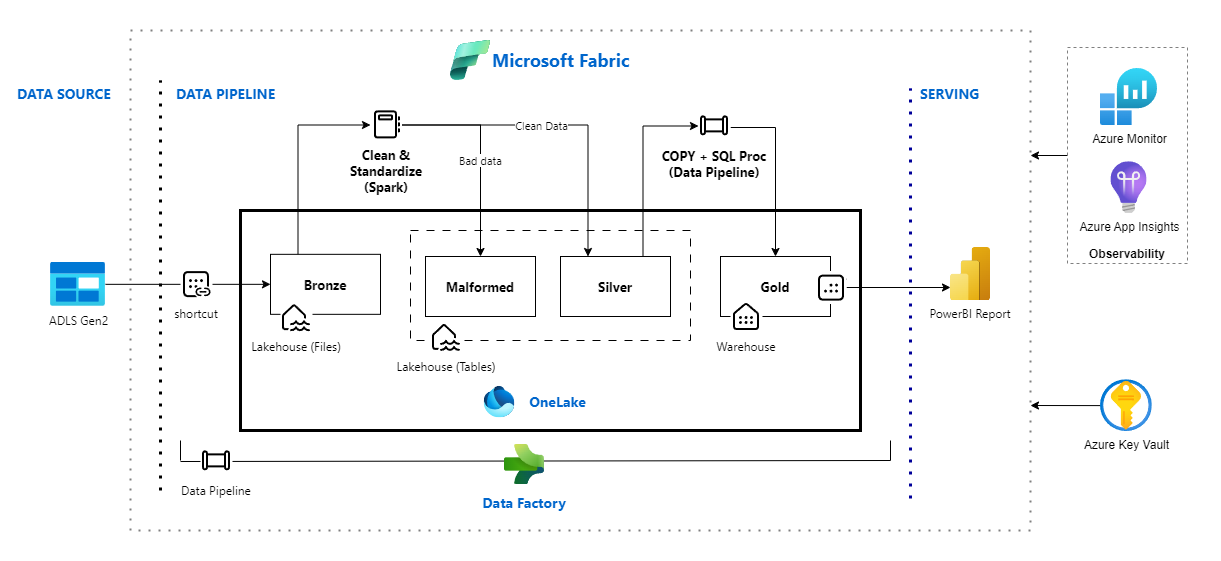
Understand the limitations
The MDW architectural principles are versatile in building analytical data pipelines in a cloud-first environment. However, they don't offer comprehensive guidance in the following areas:
- Enterprise-wide data platform architecture.
- Enterprise data governance.
- Federated data architectures (Example: Data Mesh).
- Data sharing.
- On-premises data workloads.
- Transactional data workloads.
- Detailed guidance in pure streaming and event-driven data pipeline architectures.
Learn Modern Data Warehouse best practices
The following section elaborates more on the specific stages and components within the MDW architecture along with key considerations and best practices.
Understanding data lake
A primary component of MDW architecture is a data lake storage that acts as the source of truth for different datasets. It is recommended to use Azure Data Lake Storage (ADLS) Gen2 for the data lake storage.
It's a best practice to logically divide the data lake into multiple zones corresponding to increasing levels of data quality. Data lake zones typically map directly to different data ingestion, transformation, and serving outputs of your data pipeline activities. At least three zones (Bronze/Silver/Gold or Raw/Enriched/Curated) are recommended:

Raw layer - Datasets are kept as similar to the source dataset as possible with little to no transformations applied. Raw datasets give the ability to replay data pipelines if there are production issues. It also means that data pipelines should be designed to be replayable and idempotent.
Enriched - Datasets have data validation applied and standardized to a common type, format, and schema. It's common to use parquet or delta as the storage format for this layer.
Curated - Datasets are optimized for consumption in the form of Data Product. It's common to have these datasets with dimensional modeling applied and eventually loaded into a data warehouse. This data lake zone forms part of the Serving layer in the MDW architecture. The common storage formats for this layer are parquet and delta.
For detailed information, see CAF: Data Lake Zones and Containers.
Implementing data ingestion
First, identify which data sources need to be ingested. For each of the identified data sources, determine:
- Location.
- Source system (FTP, storage account, SAP, SQL Server, etc.).
- Data format, if applicable (CSV, Parquet, Avro) and corresponding closest matching destination format.
- Expected volume and velocity (frequency, interval).
Second, identify the ingestion mechanism, for example, batch or streaming. The ingestion mechanism would determine appropriate technologies to be used. Azure Data Factory or Azure Synapse data pipelines are common services for ingesting batch datasets. Both provide an integration runtime (IR) for ingesting datasets on different networking environments (on-premises to cloud). While Azure Event Hubs and Azure IoT Hub are common ingestion points for streaming when paired with a streaming service such as Azure Steam Analytics.
Generally, the ingestion pipeline requires a one-time historical load and a recurring delta load. For the latter, determine how to identify data deltas for each run. Two commonly used methods include change data capture and utilizing a dataset attribute to identify modified records. An external state store may be needed to keep track of the last loaded dataset in the form of a watermark table.
Consider using a metadata-driven approach for large-scale ingestion use cases such as loading multiple datasets. For more information, see ADF Metadata-driven copy jobs.
At times, data preprocessing is required after data ingestion and before data transformation. In cases where a large number of huge files (in gigabytes or more) are being ingested, preprocessing steps can get complicated. An industry-specific example is the processing of data in ROS format. Robot Operating System (ROS) format requires the extraction of bagged files and metadata generation for each bag file to make it available for further processing.
Azure Batch can be a great compute option for such scenarios.
Performing data transformation
Following data ingestion into the Raw zone of a data lake, the data needs to be validated and then transformed into a standard format and schema in the Enriched zone. Data validations should be performed at this point. It's best practice to maintain a malformed record store to track records that failed validations to help with debugging issues.
Common services used at this stage include Azure Synapse Spark pools, Azure Databricks, and data flows (ADF/Synapse).
Learn about data modeling
Data modeling goes hand-in-hand with data transformation. Here, data modeling refers to both the standardized data model in the enriched zone and the consumer-optimized data model in the curated zone. While related, both data models serve fundamentally different purposes. The goal of the enriched zone data model is to provide a common data model without a specific business use case in mind. The priority is completeness, data standardization, validity, and uniformity across disparate sources from the raw zone. On the other hand, datasets in the curated zone are designed to be easily consumable. The steps may include data filtering, aggregations, and use case-specific transformations depending on the specific consumer of the dataset. The curated zone therefore may contain many derivative data products produced from datasets in the enriched zone.
How to serve data
The serving layer of the architecture functions primarily to serve the data to downstream consumers. The curated zone in the data lake forms part of the serving layer. Other components such as a data warehouse, an API, or dashboard are also commonly used. Depending on the number of consumers and their requirements, the same datasets may use multiple serving mechanisms.
Common services used at serve stage include Azure Synapse dedicated SQL pool, Azure SQL, and Microsoft Power BI.
Explore MDW technical samples
The following are technical samples showcasing concrete implementations of the Modern Data Warehouse pattern:
- MDW repo: Parking Sensor (Microsoft Fabric)
- MDW repo: Parking Sensor (Azure Databricks and Azure Data Factory)