Lifecycle management best practices
This article provides guidance for data & analytics creators who are managing their content throughout its lifecycle in Microsoft Fabric. The article focuses on the use of Git integration for source control and deployment pipelines as a release tool. For a general guidance on Enterprise content publishing, Enterprise content publishing.
Important
This feature is in preview.
The article is divided into four sections:
Content preparation - Prepare your content for lifecycle management.
Development - Learn about the best ways of creating content in the deployment pipelines development stage.
Test - Understand how to use a deployment pipelines test stage to test your environment.
Production - Utilize a deployment pipelines production stage to make your content available for consumption.
Content preparation
To best prepare your content for on-going management throughout its lifecycle, review the information in this section before you:
Release content to production.
Start using a deployment pipeline for a specific workspace.
Separate development between teams
Different teams in the org usually have different expertise, ownership, and methods of work, even when working on the same project. It’s important to set boundaries while giving each team their independence to work as they like. Consider having separate workspaces for different teams. With separate workspaces, each team can have different permissions, work with different source control repos, and ship content to production in a different cadence. Most items can connect and use data across workspaces, so it doesn't block collaboration on the same data and project.
Plan your permission model
Both Git integration and deployment pipelines require different permissions than just the workspace permissions. Read about the permission requirements for Git integration and deployment pipelines.
To implement a secure and easy workflow, plan who gets access to each part of the environments being used, both the Git repository and the dev/test/prod stages in a pipeline. Some of the considerations to take into account are:
Who should have access to the source code in the Git repository?
Which operations should users with pipeline access be able to perform in each stage?
Who’s reviewing content in the test stage?
Should the test stage reviewers have access to the pipeline?
Who should oversee deployment to the production stage?
Which workspace are you assigning to a pipeline, or connecting to git?
Which branch are you connecting the workspace to? What’s the policy defined for that branch?
Is the workspace shared by multiple team members? Should they make changes directly in the workspace, or only through Pull requests?
Which stage are you assigning your workspace to?
Do you need to make changes to the permissions of the workspace you’re assigning?
Connect different stages to different databases
A production database should always be stable and available. It's best not to overload it with queries generated by BI creators for their development or test semantic models. Build separate databases for development and testing in order to protect production data and not overload the development database with the entire volume of production data.
Use parameters for configurations that will change between stages
Whenever possible, add parameters to any definition that might change between dev/test/prod stages. Using parameters helps you change the definitions easily when you move your changes to production. While there’s still no unified way to manage parameters in Fabric, we recommend using it on items that support any type of parameterization.
Parameters have different uses, such as defining connections to data sources, or to internal items in Fabric. They can also be used to make changes to queries, filters, and the text displayed to users.
In deployment pipelines, you can configure parameter rules to set different values for each deployment stage.
Development
This section provides guidance for working with the deployment pipelines and using fit for your development stage.
Back up your work into a Git repository
With Git integration, any developer can back up their work by committing it into Git. To back up your work properly in Fabric, here are some basic rules:
Make sure you have an isolated environment to work in, so others don’t override your work before it gets committed. This means working in a Desktop tool (such as VS Code, Power BI Desktop or others), or in a separate workspace that other users can’t access.
Commit to a branch that you created and no other developer is using. If you’re using a workspace as an authoring environment, read about working with branches.
Commit together changes that must be deployed together. This advice applies for a single item, or multiple items that are related to the same change. Committing all related changes together can help you later when deploying to other stages, creating pull requests, or reverting changes back.
Big commits might hit a max commit size limit. Be mindful of the number of items you commit together, or the general size of an item. For example, reports can grow large when adding large images. It’s bad practice to store large-size items in source control systems, even if it works. Consider ways to reduce the size of your items if they have lots of static resources, like images.
Rolling back changes
After you back up your work, there might be cases where you want to revert to a previous version and restore it in the workspace. There are a few ways to revert to a previous version:
Undo button: The Undo operation is an easy and fast way to revert the immediate changes you made, as long as they aren't committed yet. You can also undo each item separately. Read more about the undo operation.
Reverting to older commits: There’s no direct way to go back to a previous commit in the UI. The best option is to promote an older commit to be the HEAD using git revert or git reset. Doing this shows that there’s an update in the source control pane, and you can update the workspace with that new commit.
Since data isn’t stored in Git, keep in mind that reverting a data item to an older version might break the existing data and could possibly require you to drop the data or the operation might fail. Check this in advance before reverting changes back.
Working with a 'private' workspace
When you want to work in isolation, use a separate workspace as an isolated environment. Read more about isolating your work environment in working with branches. For an optimal workflow for you and the team, consider the following points:
Setting up the workspace: Before you start, make sure you can create a new workspace (if you don’t already have one), that you can assign it to a Fabric capacity, and that you have access to data to work in your workspace.
Creating a new branch: Create a new branch from the main branch, so you have the most up-to-date version of your content. Also make sure you connect to the correct folder in the branch, so you can pull the right content into the workspace.
Small, frequent changes: It's a Git best practice to make small incremental changes that are easy to merge and less likely to get into conflicts. If that’s not possible, make sure to update your branch from main so you can resolve conflicts on your own first.
Configuration changes: If necessary, change the configurations in your workspace to help you work more productively. Some changes can include connection between items, or to different data sources or changes to parameters on a given item. Just remember that anything you commit becomes part of the commit and can accidentally be merged into the main branch.
Use Client tools to edit your work
For items and tools that support it, it might be easier to work with client tools for authoring, such as Power BI Desktop for semantic models and reports, VSCode for Notebooks etc. These tools can be your local development environment. After you complete your work, push the changes into the remote repo, and sync the workspace to upload the changes. Just make sure you're working with the supported structure of the item you're authoring. If you’re not sure, first clone a repo with content already synced to a workspace, then start authoring from there, where the structure is already in place.
Managing workspaces and branches
Since a workspace can only be connected to a single branch at a time, it's recommended to treat this as a 1:1 mapping. However, to reduce the amount of workspace it entails, consider these options:
If a developer set up a private workspace with all required configurations, they can continue to use that workspace for any future branch they create. When a sprint is over, your changes are merged and you're starting a fresh new task, just switch the connection to a new branch on the same workspace. You can also do this if you suddenly need to fix a bug in the middle of a sprint. Think of it as a working directory on the web.
Developers using a client tool (such as VS Code, Power BI Desktop, or others), don’t necessarily need a workspace. They can create branches and commit changes to that branch locally, push those to the remote repo and create a pull request to the main branch, all without a workspace. A workspace is needed only as a testing environment to check that everything works in a real-life scenario. It's up to you to decide when that should happen.
Duplicate an item in a Git repository
To duplicate an item in a Git repository:
- Copy the entire item directory.
- Change the logicalId to something unique for that connected workspace.
- Change the display name to differentiate it from the original item and to avoid duplicate display name error.
- If necessary, update the logicalId and/or display names in any dependencies.
Test
This section provides guidance for working with a deployment pipelines test stage.
Simulate your production environment
It’s important to see how your proposed change will impact the production stage. A deployment pipelines test stage allows you to simulate a real production environment for testing purposes. Alternatively, you can simulate this by connecting Git to another workspace.
Make sure that these three factors are addressed in your test environment:
Data volume
Usage volume
A similar capacity as in production
When testing, you can use the same capacity as the production stage. However, using the same capacity can make production unstable during load testing. To avoid unstable production, test using a different capacity similar in resources to the production capacity. To avoid extra costs, use a capacity where you can pay only for the testing time.
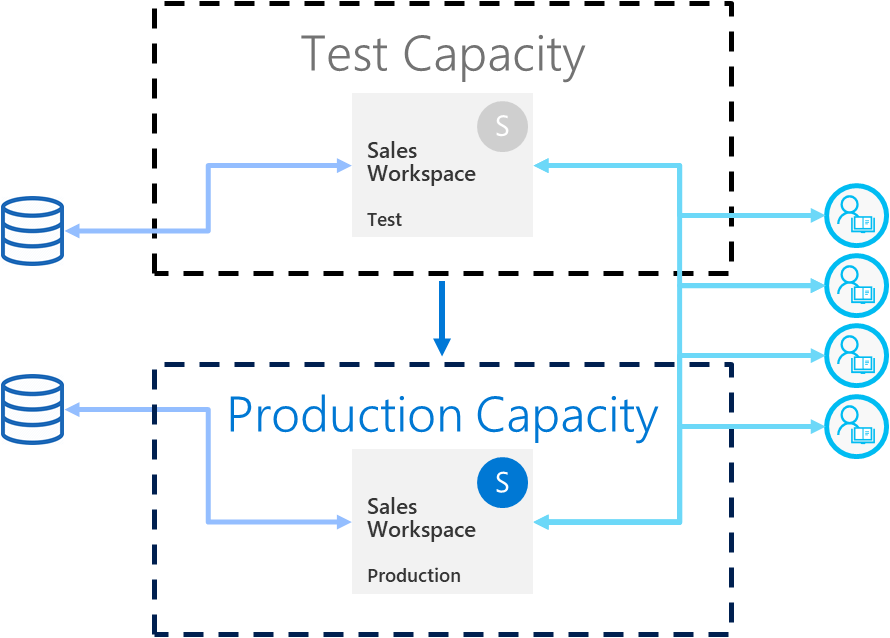
Use deployment rules with a real-life data source
If you're using the test stage to simulate real life data usage, it's best to separate the development and test data sources. The development database should be relatively small, and the test database should be as similar as possible to the production database. Use data source rules to switch data sources in the test stage or parameterize the connection if not working through deployment pipelines.
Check related items
Changes you make can also affect the dependent items. During testing, verify that your changes don’t affect or break the performance of existing items, which can be dependent on the updated ones.
You can easily find the related items by using impact analysis.
Updating data items
Data items are items that store data. The item’s definition in Git defines how the data is stored. When updating an item in the workspace, we're importing its definition into the workspace and applying it on the existing data. The operation of updating data items is the same for Git and deployment pipelines.
As different items have different capabilities when it comes to retaining data when changes to the definition are applied, be mindful when applying the changes. Some practices that can help you apply the changes in the safest way:
Know in advance what the changes are and what their impact might be on the existing data. Use commit messages to describe the changes made.
To see how that item handles the change with test data, upload the changes first to a dev or test environment.
If everything goes well, it’s recommended to also check it on a staging environment, with real-life data (or as close to it as possible), to minimize the unexpected behaviors in production.
Consider the best timing when updating the Prod environment to minimize the damage that any errors might cause to your business users who consume the data.
After deployment, post-deployment tests in Prod to verify that everything is working as expected.
Some changes will always be considered breaking changes. Hopefully, the preceding steps will help you track them before production. Build a plan for how to apply the changes in Prod and recover the data to get back to normal state and minimize downtime for business users.
Test your app
If you're distributing content to your customers through an app, review the app's new version before it's in production. Since each deployment pipeline stage has its own workspace, you can easily publish and update apps for development and test stages. Publishing and updating apps allows you to test the app from an end user's point of view.
Important
The deployment process doesn't include updating the app content or settings. To apply changes to content or settings, manually update the app in the required pipeline stage.
Production
This section provides guidance to the deployment pipelines production stage.
Manage who can deploy to production
Because deploying to production should be handled carefully, it's good practice to let only specific people manage this sensitive operation. However, you probably want all BI creators for a specific workspace to have access to the pipeline. Use production workspace permissions to manage access permissions. Other users can have a production workspace viewer role to see content in the workspace but not make changes from Git or deployment pipelines.
In addition, limit access to the repo or pipeline by only enabling permissions to users that are part of the content creation process.
Set rules to ensure production stage availability
Deployment rules are a powerful way to ensure the data in production is always connected and available to users. With deployment rules applied, deployments can run while you have the assurance that customers can see the relevant information without disturbance.
Make sure that you set production deployment rules for data sources and parameters defined in the semantic model.
Update the production app
Deployment in a pipeline through the UI updates the workspace content. To update the associated app, use the deployment pipelines API. It's not possible to update the app through the UI. If you use an app for content distribution, don’t forget to update the app after deploying to production so that end users are immediately able to use the latest version.
Deploying into production using Git branches
As the repo serves as the ‘single-source-of-truth’, some teams might want to deploy updates into different stages directly from Git. This is possible with Git integration, with a few considerations:
We recommend using release branches. You need to continuously change the connection of workspace to the new release branches before every deployment.
If your build or release pipeline requires you to change the source code, or run scripts in a build environment before deployment to the workspace, then connecting the workspace to Git won't help you.
After deploying to each stage, make sure to change all the configuration specific to that stage.
Quick fixes to content
Sometimes there are issues in production that require a quick fix. Deploying a fix without testing it first is bad practice. Therefore, always implement the fix in the development stage and push it to the rest of the deployment pipeline stages. Deploying to the development stage allows you to check that the fix works before deploying it to production. Deploying across the pipeline takes only a few minutes.
If you're using deployment from Git, we recommend following the practices described in Adopt a Git branching strategy.
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for