Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
The Refresh SQL Endpoint activity in Microsoft Fabric pipelines lets you programmatically refresh a Lakehouse SQL endpoint as part of an orchestrated workflow. This approach ensures that downstream consumers—such as Power BI reports, notebooks, or external SQL clients—see the latest data after data preparation or maintenance steps complete.
Use this activity to make SQL endpoints immediately reflect recent updates without relying on manual refreshes or ad-hoc processes. Use this activity when your pipeline:
- Updates or maintains Lakehouse data (for example, after Copy Jobs, Notebook execution, or Lakehouse maintenance activities).
- Requires the Lakehouse SQL endpoint to reflect the latest metadata and data changes.
- Needs deterministic refresh timing before downstream steps such as reporting, analytics, or exports.
Prerequisites
Before using this activity, make sure that:
- A tenant account with an active subscription. Create an account for free.
- A workspace with a Lakehouse
- A SQL endpoint exists for the Lakehouse.
- The pipeline identity (user or service principal) has permission to refresh the SQL endpoint.
Add a Refresh SQL Endpoint activity to your pipeline in the UI
Create a new pipeline in your workspace.
Search for Refresh SQL Endpoint in the pipeline Activities pane and select it to add it to the pipeline canvas.
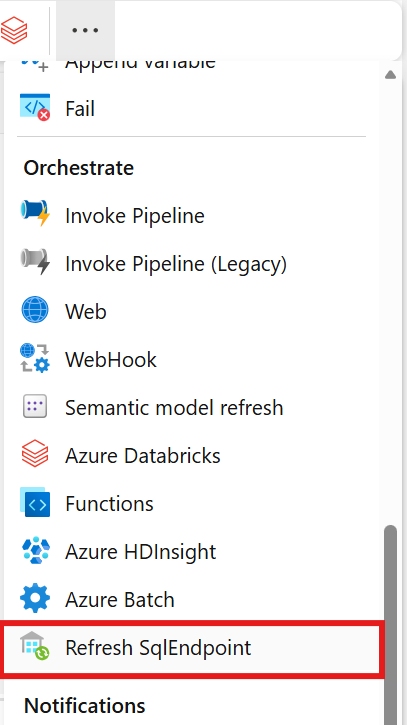
Select the new Refresh SQL Endpoint activity on the canvas if it isn't already selected.
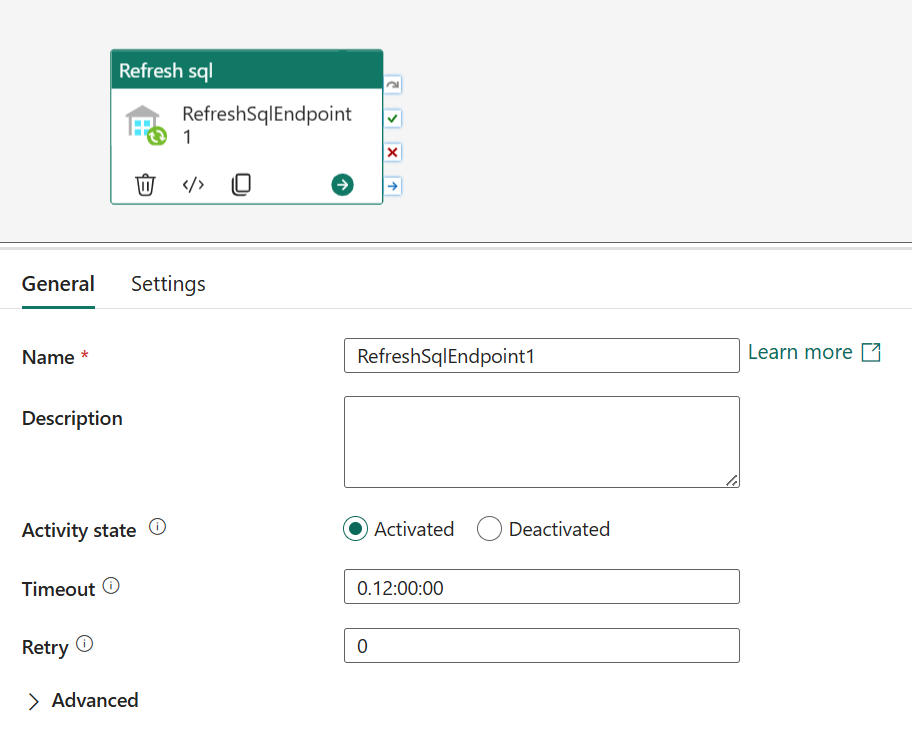
Refer to the General settings guidance to configure the General settings tab.


Refresh SQL Endpoint activity settings
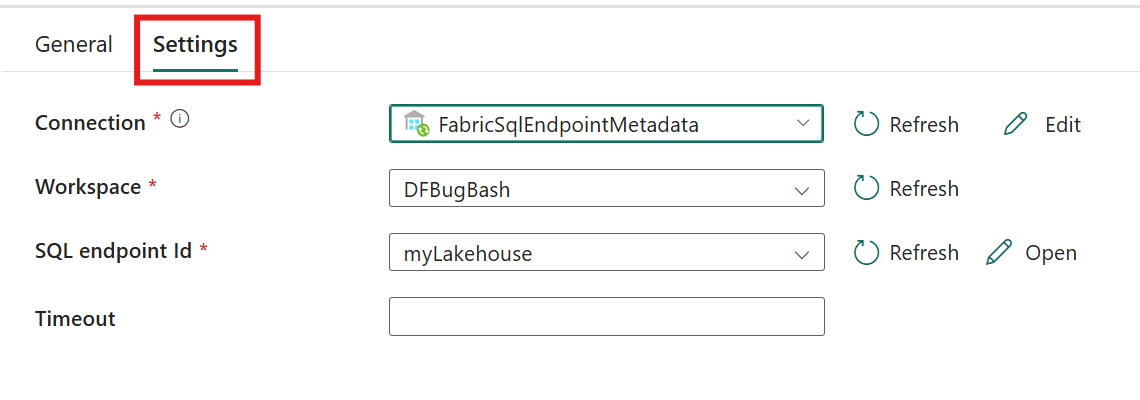
Select the Settings tab to configure the activity.
Configure connection by selecting an existing connection from the Connection dropdown, or creating a new connection, and specifying its configuration details.
Specify the Workspace that contains the Lakehouse.
Specify the SQL Endpoint that contains the materialized lake view to refresh. This SQL endpoint is the Lakehouse whose SQL endpoint you want to refresh. The SQL endpoint associated with the selected Lakehouse.

Activity behavior
When the activity run finishes:
If the Output pop-up shows the Success status, the request syncs unsynced data successfully.
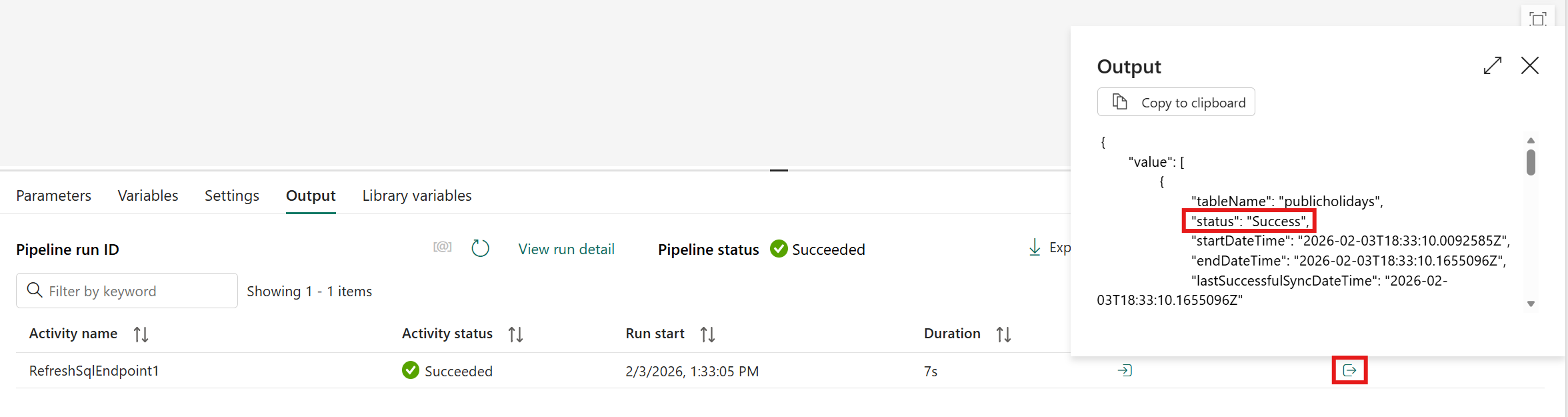
A NotRun status in the Output pop-up means that the refresh of the SQL endpoint didn't run. That condition usually means that you didn't add new data since the last sync, so you didn't need to run it.
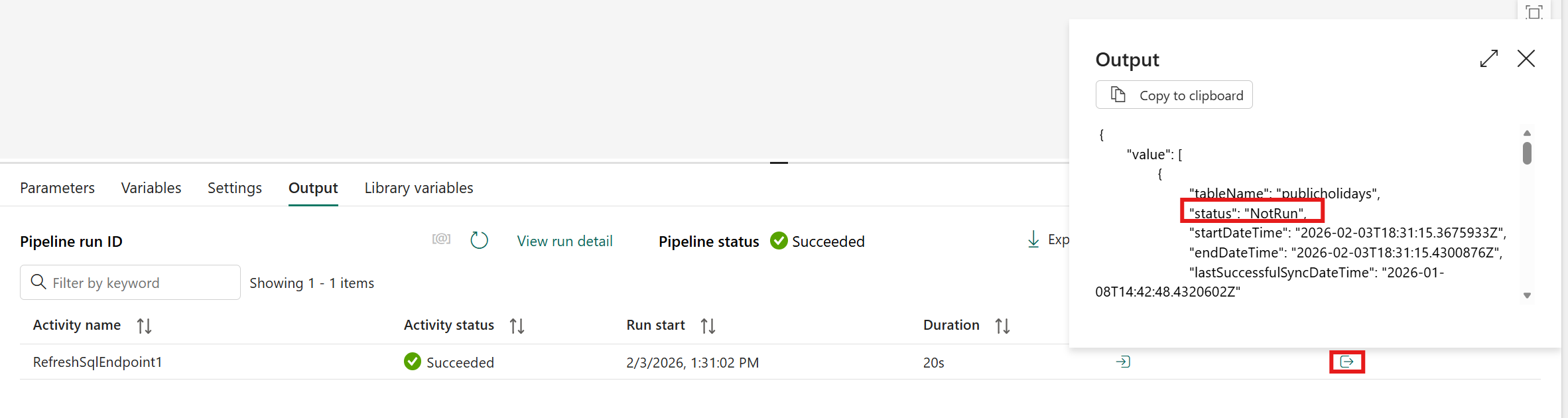
If the Output pop-up shows the Failure status, something went wrong.


Note
The activity run sets these statuses in the Output pop-up. Don't confuse these statuses with the activity status itself.
Common scenarios
- Refreshing the SQL endpoint after a Notebook writes transformed data to a Lakehouse.
- Triggering a SQL endpoint refresh after Optimize or Vacuum operations complete.
- Ensuring reports and dashboards query the most recent Lakehouse state at well‑defined points in a pipeline.
Why does my SQL Endpoint Refresh fail when underlying data is locked?
The Refresh SQL Endpoint activity can fail intermittently when other processes actively update the underlying Lakehouse data. These processes include ingestion pipelines, notebooks, or concurrent write operations.
This failure happens because the SQL Endpoint needs to acquire internal locks to complete the refresh. If another operation locks the data, the request times out or returns an error.
This behavior is expected based on how SQL Endpoints manage metadata refresh operations.
Symptoms
- The activity fails intermittently, not consistently.
- Error messages indicate refresh conflicts or lock contention.
- Pipelines with multiple sequential Refresh SQL Endpoint activities show higher failure rates.
Root cause
SQL Endpoints require exclusive access to certain metadata structures during refresh. If another compute process writes to the Lakehouse at the same time, lock contention occurs.
This behavior isn't a defect in the Refresh SQL Endpoint activity. It's the natural result of concurrent read and write operations on the underlying data.
Workarounds
Two practical approaches can mitigate this issue:
- Use Only One Refresh SQL Endpoint Activity at the End of Processing
- Implement a Recurring Refresh Schedule
Use Only One Refresh SQL Endpoint Activity at the End of Processing
To reduce the likelihood of lock conflicts, consolidate your pipeline so that:
- All ingestion, transformation, and update activities run first,
- Then only one Refresh SQL Endpoint activity executes at the end.
- This approach doesn't eliminate failures completely, but greatly reduces how often they occur.
Implement a Recurring Refresh Schedule
If your scenario doesn't require strict transactional consistency at a specific moment, adopt a recurring refresh pattern:
- Schedule a refresh every 15 minutes—continuously. Some refresh attempts might fail due to locking, but enough succeed to keep your SQL Endpoint relatively up to date.

This approach is practical and robust for many analytics workloads.
Save and run or schedule the pipeline
Switch to the Home tab at the top of the pipeline editor and select the save button to save your pipeline. Select Run to run it directly or Schedule to schedule runs at specific times or intervals. For more information on pipeline runs, see: schedule pipeline runs.

After running, you can monitor the pipeline execution and view run history from the Output tab below the canvas.
Known issues
- The Refresh SQL Endpoint activity might intermittently fail when other processes actively update the underlying Lakehouse data. For workarounds, see the section Why is my SQL Endpoint Refresh failing when underlying data is locked?