Tutorial: Clean data with functional dependencies
In this tutorial, you use functional dependencies for data cleaning. A functional dependency exists when one column in a semantic model (a Power BI dataset) is a function of another column. For example, a zip code column might determine the values in a city column. A functional dependency manifests itself as a one-to-many relationship between the values in two or more columns within a DataFrame. This tutorial uses the Synthea dataset to show how functional relationships can help to detect data quality problems.
In this tutorial, you learn how to:
- Apply domain knowledge to formulate hypotheses about functional dependencies in a semantic model.
- Get familiarized with components of semantic link's Python library (SemPy) that help to automate data quality analysis. These components include:
- FabricDataFrame - a pandas-like structure enhanced with additional semantic information.
- Useful functions that automate the evaluation of hypotheses about functional dependencies and that identify violations of relationships in your semantic models.
Prerequisites
Get a Microsoft Fabric subscription. Or, sign up for a free Microsoft Fabric trial.
Sign in to Microsoft Fabric.
Use the experience switcher on the left side of your home page to switch to the Synapse Data Science experience.

- Select Workspaces from the left navigation pane to find and select your workspace. This workspace becomes your current workspace.
Follow along in the notebook
The data_cleaning_functional_dependencies_tutorial.ipynb notebook accompanies this tutorial.
To open the accompanying notebook for this tutorial, follow the instructions in Prepare your system for data science tutorials, to import the notebook to your workspace.
If you'd rather copy and paste the code from this page, you can create a new notebook.
Be sure to attach a lakehouse to the notebook before you start running code.
Set up the notebook
In this section, you set up a notebook environment with the necessary modules and data.
- For Spark 3.4 and above, Semantic link is available in the default runtime when using Fabric, and there is no need to install it. If you are using Spark 3.3 or below, or if you want to update to the most recent version of Semantic Link, you can run the command:
python %pip install -U semantic-link
Perform necessary imports of modules that you'll need later:
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_syntheaPull the sample data. For this tutorial, you use the Synthea dataset of synthetic medical records (small version for simplicity):
download_synthea(which='small')
Explore the data
Initialize a
FabricDataFramewith the content of the providers.csv file:providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Check for data quality issues with SemPy's
find_dependenciesfunction by plotting a graph of autodetected functional dependencies:deps = providers.find_dependencies() plot_dependency_metadata(deps)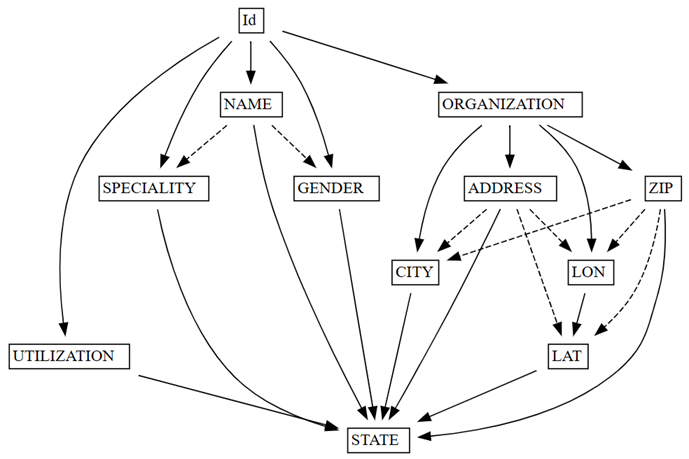
The graph of functional dependencies shows that
IddeterminesNAMEandORGANIZATION(indicated by the solid arrows), which is expected, sinceIdis unique:Confirm that
Idis unique:providers.Id.is_uniqueThe code returns
Trueto confirm thatIdis unique.

Analyze functional dependencies in depth
The functional dependencies graph also shows that ORGANIZATION determines ADDRESS and ZIP, as expected. However, you might expect ZIP to also determine CITY, but the dashed arrow indicates that the dependency is only approximate, pointing towards a data quality issue.
There are other peculiarities in the graph. For example, NAME doesn't determine GENDER, Id, SPECIALITY, or ORGANIZATION. Each of these peculiarities might be worth investigating.
Take a deeper look at the approximate relationship between
ZIPandCITY, by using SemPy'slist_dependency_violationsfunction to see a tabular list of violations:providers.list_dependency_violations('ZIP', 'CITY')Draw a graph with SemPy's
plot_dependency_violationsvisualization function. This graph is helpful if the number of violations is small:providers.plot_dependency_violations('ZIP', 'CITY')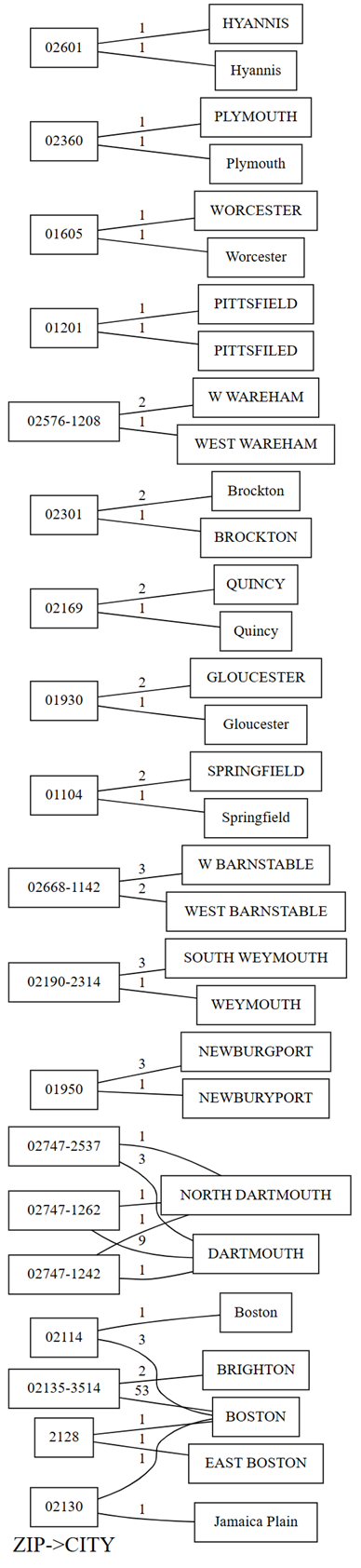
The plot of dependency violations shows values for
ZIPon the left hand side, and values forCITYon the right hand side. An edge connects a zip code on the left hand side of the plot with a city on the right hand side if there's a row that contains these two values. The edges are annotated with the count of such rows. For example, there are two rows with zip code 02747-1242, one row with city "NORTH DARTHMOUTH" and the other with city "DARTHMOUTH", as shown in the previous plot and the following code:Confirm the previous observations you made with the plot of dependency violations by running the following code:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()The plot also shows that among the rows that have
CITYas "DARTHMOUTH", nine rows have aZIPof 02747-1262; one row has aZIPof 02747-1242; and one row has aZIPof 02747-2537. Confirms these observations with the following code:providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()There are other zip codes associated with "DARTMOUTH", but these zip codes aren't shown in the graph of dependency violations, as they don't hint at data quality issues. For example, the zip code "02747-4302" is uniquely associated to "DARTMOUTH" and doesn't show up in the graph of dependency violations. Confirm by running the following code:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Summarize data quality issues detected with SemPy
Going back to the graph of dependency violations, you can see that there are several interesting data quality issues present in this semantic model:
- Some city names are all uppercase. This issue is easy to fix using string methods.
- Some city names have qualifiers (or prefixes), such as "North" and "East". For example, the zip code "2128" maps to "EAST BOSTON" once and to "BOSTON" once. A similar issue occurs between "NORTH DARTHMOUTH" and "DARTHMOUTH". You could try to drop these qualifiers or map the zip codes to the city with the most common occurrence.
- There are typos in some cities, such as "PITTSFIELD" vs. "PITTSFILED" and "NEWBURGPORT vs. "NEWBURYPORT". For "NEWBURGPORT" this typo could be fixed by using the most common occurrence. For "PITTSFIELD", having only one occurrence each makes it much harder for automatic disambiguation without external knowledge or the use of a language model.
- Sometimes, prefixes like "West" are abbreviated to a single letter "W". This issue could potentially be fixed with a simple replace, if all occurrences of "W" stand for "West".
- The zip code "02130" maps to "BOSTON" once and "Jamaica Plain" once. This issue isn't easy to fix, but if there was more data, mapping to the most common occurrence could be a potential solution.
Clean the data
Fix the capitalization issues by changing all capitalization to title case:
providers['CITY'] = providers.CITY.str.title()Run the violation detection again to see that some of the ambiguities are gone (the number of violations is smaller):
providers.list_dependency_violations('ZIP', 'CITY')At this point, you could refine your data more manually, but one potential data cleanup task is to drop rows that violate functional constraints between columns in the data, by using SemPy's
drop_dependency_violationsfunction.For each value of the determinant variable,
drop_dependency_violationsworks by picking the most common value of the dependent variable and dropping all rows with other values. You should apply this operation only if you're confident that this statistical heuristic would lead to the correct results for your data. Otherwise you should write your own code to handle the detected violations as needed.Run the
drop_dependency_violationsfunction on theZIPandCITYcolumns:providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')List any dependency violations between
ZIPandCITY:providers_clean.list_dependency_violations('ZIP', 'CITY')The code returns an empty list to indicate that there are no more violations of the functional constraint CITY -> ZIP.
Related content
Check out other tutorials for semantic link / SemPy:
- Tutorial: Analyze functional dependencies in a sample semantic model
- Tutorial: Extract and calculate Power BI measures from a Jupyter notebook
- Tutorial: Discover relationships in a semantic model, using semantic link
- Tutorial: Discover relationships in the Synthea dataset, using semantic link
- Tutorial: Validate data using SemPy and Great Expectations (GX)