Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article describes design topics relevant to developing Direct Lake semantic models.
Create the model
You can create a Direct Lake semantic model in Power BI Desktop or from many Fabric items in the browser. For example, from an open Lakehouse you can choose New semantic model to create a new semantic model in Direct Lake storage mode.
There are two forms of Direct Lake storage mode, summarized here. See the Key concepts and terminology section for more information.
- Use Direct Lake on OneLake for compatibility with OneLake security, more modeling features, and faster query performance.
- Use Direct Lake on SQL when you depend on security rules defined in the SQL analytics endpoint with delegated identity mode, or you need fallback to DirectQuery.
The following table shows the most common creation methods for each type of Direct Lake semantic model.
| Supports Direct Lake on OneLake | Supports Direct Lake on SQL | |
|---|---|---|
| Creation from the Power BI service. For example, select Create from the left navigation bar, then select OneLake catalog. | Yes | No |
| Creation from Power BI Desktop. | Yes | No |
| Creation from the SQL analytics endpoint page. For example, open the SQL analytics endpoint for a lakehouse, then select New semantic model. | Yes | Yes |
When you create a Direct Lake semantic model from the SQL analytics endpoint, you can choose between the two Direct Lake types, as shown in the following image:
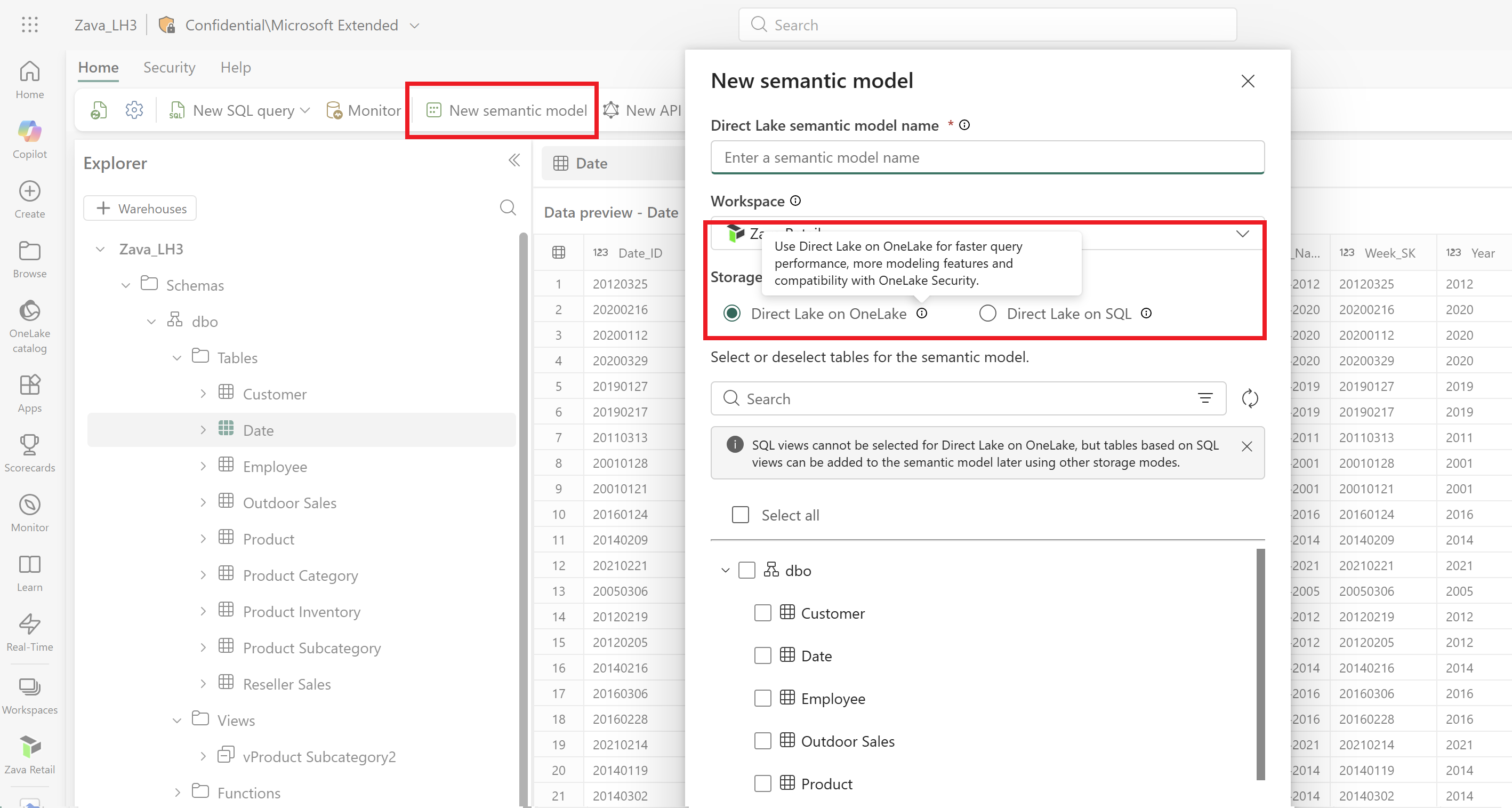
This dialog defaults to Direct Lake on OneLake if the SQL analytics endpoint is in user identity mode, or Direct Lake on SQL if the SQL analytics endpoint is in delegated mode. For more information, see Access modes in SQL analytics endpoint.
Alternatively, as with any Power BI semantic model, you can continue the development of your model by using an XMLA-compliant tool, like SQL Server Management Studio (SSMS) (version 19.1 or later) or open-source, community tools. Fabric notebooks can also programmatically create and edit semantic models with semantic link and semantic link labs.
Power Query connectors
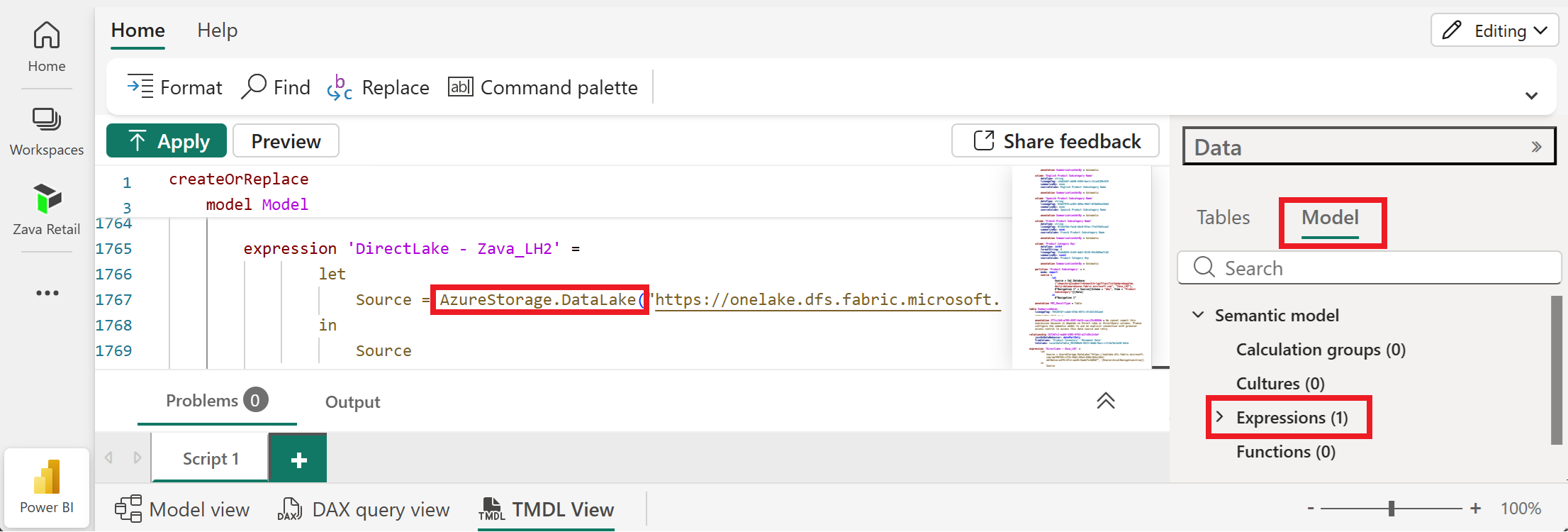
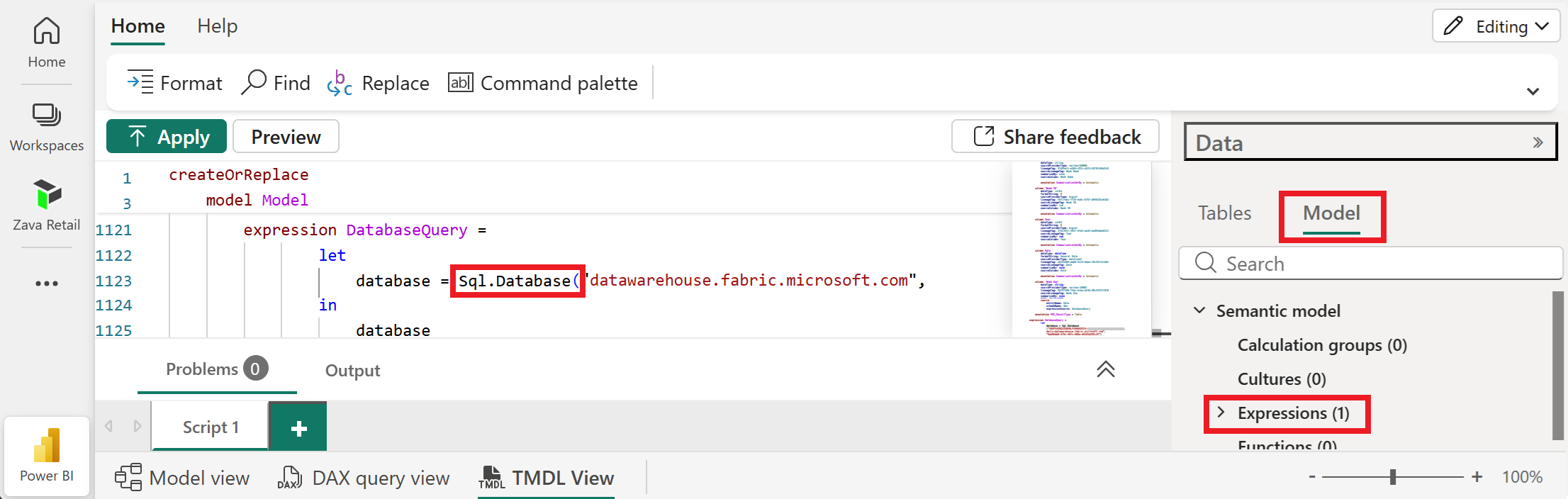
An easy way to tell if an existing Direct Lake semantic model is on OneLake or SQL is to check the connector in TMDL view. From the Model tab, drag the Expressions node to see the M expression definition.
Direct Lake on OneLake uses the Azure Data Lake Storage connector.
Direct Lake on SQL uses the SQL Server connector, or the OneLake.SqlAnalytics() connector.
Direct Lake composite models
Direct Lake on OneLake enables creation of multi-source, composite models that combine tables in Direct Lake mode with other tables in Import/DirectQuery mode, providing valuable flexibility for dimension tables while leveraging Direct Lake for very large fact tables to avoid costly refreshes and management overhead. For more information, see the Composite semantic models with Direct Lake and Import storage mode tables section.
Model tables
Model tables are normally based on the table in the source Fabric data item. Direct Lake on SQL also allows selection of a SQL view. Queries to a model table based on a SQL view fall back to DirectQuery mode, which might result in slower query performance.
Note
With Direct Lake on OneLake, tables based on SQL views can be added using other storage modes like Import and/or DirectQuery because Direct Lake on OneLake supports composite models.
Tables should include columns for filtering, grouping, sorting, and summarizing, in addition to columns that support model relationships.
For more information about columns to include in your semantic model tables, see Understand Direct Lake query performance.
For information about enforcing data-access rules with object-level security (OLS) and row-level security (RLS), see Integrate Direct Lake security.
Direct Lake model metadata
When you connect to a Direct Lake semantic model with the XMLA endpoint, the metadata looks like that of any other model. However, Direct Lake models show the following differences:
- The
compatibilityLevelproperty of the database object is 1604 (or higher). - The mode property of Direct Lake partitions is set to
directLake. - Direct Lake partitions use shared expressions to define data sources.
- Direct Lake on SQL — The expression points to the SQL analytics endpoint of the lakehouse or warehouse. Direct Lake uses the SQL analytics endpoint to discover schema and security information, but it loads the data directly from OneLake (unless it falls back to DirectQuery mode for any reason).
- Direct Lake on OneLake — The expression points directly to the OneLake storage location of the Fabric data source. Direct Lake uses the OneLake APIs for schema discovery, security checks, and data loading. Direct Lake on OneLake doesn't fall back to DirectQuery mode.
Post-publication tasks
After you publish a Direct Lake semantic model, you should complete some setup tasks. For more information, see Manage Direct Lake semantic models.