Events
Nov 19, 11 PM - Nov 21, 11 PM
Discover the latest partner benefits with product enhancements to support AI practice growth at Microsoft Ignite online.
Register nowThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
[This article is prerelease documentation and is subject to change.]
The FHIR data ingestion capability lets you import your Fast Healthcare Interoperability Resources (FHIR) data from a FHIR service such as Azure Health Data Services to OneLake. You can set up this capability after you deploy healthcare data solutions (preview) and the Healthcare data foundations capability to your Fabric workspace.
Note
If you're using your own FHIR data, you need the FHIR data ingestion capability to run other healthcare data solutions (preview) capabilities. FHIR data ingestion also has a direct dependency on the Healthcare data foundations capability. Make sure you successfully deploy Healthcare data foundations first before you deploy FHIR data ingestion.
Deploy healthcare data solutions (preview) to your Fabric workspace.
If you use Azure Health Data Services as your FHIR data source, make sure you complete the following steps on the Azure portal:
Deploy Healthcare data foundations.
If you don't have a FHIR server in your test environment, use the sample data instead. Follow the steps in Deploy sample data to download the sample data into your environment.
To deploy FHIR data ingestion to your workspace, follow these steps:
Navigate to the healthcare data solutions home page on Fabric.
Select the FHIR data ingestion tile.

On the capability page, select Deploy to workspace. The deployment includes provisioning the FHIR export service notebook that brings data from the Azure FHIR service to OneLake.

The deployment can take a few minutes to complete. Don't close the tab or the browser while the deployment is in progress. In the meantime, you can work in another tab.
When the deployment completes, you get a notification. Select the Manage capability button from the message bar to navigate to the FHIR data ingestion capability management page. You can view, configure, and manage the deployed FHIR export service notebook here.

The healthcare#_msft_fhir_export_service notebook, deployed with FHIR data ingestion, uses the bulk $export API provided by Azure Health Data Services to export FHIR data to an Azure Storage container on a recurring basis. The FHIRExportService exports the data from the FHIR server and helps you monitor the status of these exports as per the following protocol:
Export function key extraction: Before export initiation, the service extracts the ExportFunctionKey secret from a user-specified Azure Key Vault.
Trigger the Azure Function: The service uses the extracted ExportFunctionKey secret and triggers the designated Azure Function (function app).
Continuous polling: After the bulk export is successfully requested, you can use the URL in the Content-Location header to check the status of the export periodically.
Completion confirmation: The polling process continues until the server returns an HTTP 200 status code when the export operation is done. The operation might also partially succeed.
Before you run this notebook, make sure you complete configuring the healthcare#_msft_config_notebook as explained in Configure the global configuration notebook. Essentially, ensure you complete the following steps:
Update the key vault parameter value kv_name in the global configuration notebook. This value should point to the key vault service deployed with the Healthcare data solutions in Microsoft Fabric Azure Marketplace offer.
kv_name = "%%keyvault_name%%"
Regardless of how you ingest data into the lake, make sure you assign these required permissions to all the users who want to run the data pipelines and notebooks:
The healthcare#_msft_fhir_export_service notebook has the following key configuration parameters:
spark: Spark session.max_polling_days: The maximum number of days to poll the FHIR server for export completion. The default value is set to three days. The values can range from one day to seven days.kv_name: Name of the key vault service. Configure this value in the global configuration notebook.function_url_secret_name: Name of the secret in the key vault service that contains the function URL. Configure this value too in the global configuration notebook.Important
By default, all new Fabric workspaces use the latest Fabric runtime version, which is currently Runtime 1.3. However, the solution only supports Runtime 1.2 now.
So, after you deploy healthcare data solutions (preview) to your workspace, remember to update the default Fabric runtime version to Runtime 1.2 (Apache Spark 3.4 and Delta Lake 2.4) before executing any of the pipelines or notebooks. If not, your pipeline or notebook executions will fail.
For more information, see Support for multiple runtimes in Fabric Runtime.

To use the FHIR data ingestion capability, you can choose one of the following three data ingestion options:
Note
Ingesting data using a FHIR service only works with first-party Microsoft FHIR services.
If you wish to proceed with option 2 or 3, you need to follow these requirements:
All data must be in NDJSON format.
Each file can only contain data related to one FHIR resource.
Each resource in the file must have a metadata field with a Meta.lastUpdated element value. For more information, see Resource - FHIR v6.0.0-cibuild.
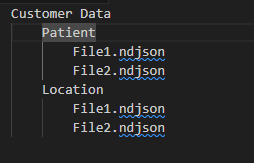
Data must be organized in one of the following two supported folder formats. The file names and folder names are case sensitive.
Data can be distributed across multiple folders, with file names beginning with the resource name.
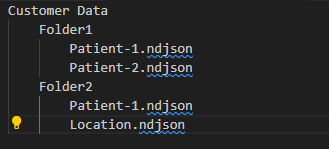
Data can be stored in folders where the folder names correspond to the resource names.
Also, if you wish to bring in your own data to the Fabric lakehouse or use a FHIR service, review the following configuration sections based on your usage scenario.
Suppose you upload data to the healthcare#_msft_bronze lakehouse under files called "FHIRData". Then, update the source_path_pattern in the healthcare#_msft_raw_bronze_ingestion notebook as shown in the following examples:
source_path_pattern = 'abfss://<workspace_name>@onelake.dfs.fabric.microsoft.com/{bronze_lakehouse_name}.Lakehouse/Files/FHIRData/**/<resource_name>[^a-zA-Z]*ndjson'
source_path_pattern = 'abfss://<workspace_name>@onelake.dfs.fabric.microsoft.com/{bronze_lakehouse_name}.Lakehouse/Files/FHIRData/<resource_name>/*ndjson'
When you run the healthcare#_msft_fhir_export_service notebook, the data is automatically exported to a container named export-landing-zone in the Azure Storage account. You must create a shortcut of this folder in your storage account in the bronze lakehouse.
For example, let's say the shortcut you create in the bronze lakehouse is named FHIRData. The Azure Health Data Service FHIR service always exports data in the pattern shown in Example 1 in the previous section. So, the source_path_pattern value should be illustrated in the following format:
source_path_pattern = 'abfss://<workspace_name>@onelake.dfs.fabric.microsoft.com/{bronze_lakehouse_name}.Lakehouse/Files/FHIRData/**/<resource_name>[^a-zA-Z]*ndjson'
Events
Nov 19, 11 PM - Nov 21, 11 PM
Discover the latest partner benefits with product enhancements to support AI practice growth at Microsoft Ignite online.
Register nowTraining
Learning path
Ingest data with Microsoft Fabric - Training
Explore how Microsoft Fabric enables you to ingest and orchestrate data from various sources (such as files, databases, or web services) through dataflows, notebooks, and pipelines.
Certification
Microsoft Certified: Azure Data Scientist Associate - Certifications
Manage data ingestion and preparation, model training and deployment, and machine learning solution monitoring with Python, Azure Machine Learning and MLflow.