Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Tip
Power BI Dataflow Gen1 is now in a legacy state and won't receive new feature investment. For Premium customers with Fabric access, Dataflow Gen2 is the recommended path, offering improvements in performance, scale, reliability, functionality, and built-in AI. Pro/PPU customers can continue to use Gen1 as Gen2 guidance for these scenarios is evolving. See Upgrade from Dataflow Gen1 to Dataflow Gen2 for upgrade guidance.
With dataflows, you can unify data from multiple sources and prepare that unified data for modeling. Whenever you create a dataflow, you're prompted to refresh the data for the dataflow. Refreshing a dataflow is required before it can be consumed in a semantic model in Power BI Desktop, or referenced as a linked or computed table.
Note
Dataflows may not be available in the Power BI service for all U.S. Government DoD customers. For more information about which features are available, and which are not, see Power BI feature availability for U.S. Government customers.
Configure a dataflow
To configure the refresh of a dataflow, select More options (the ellipsis) and choose Settings.
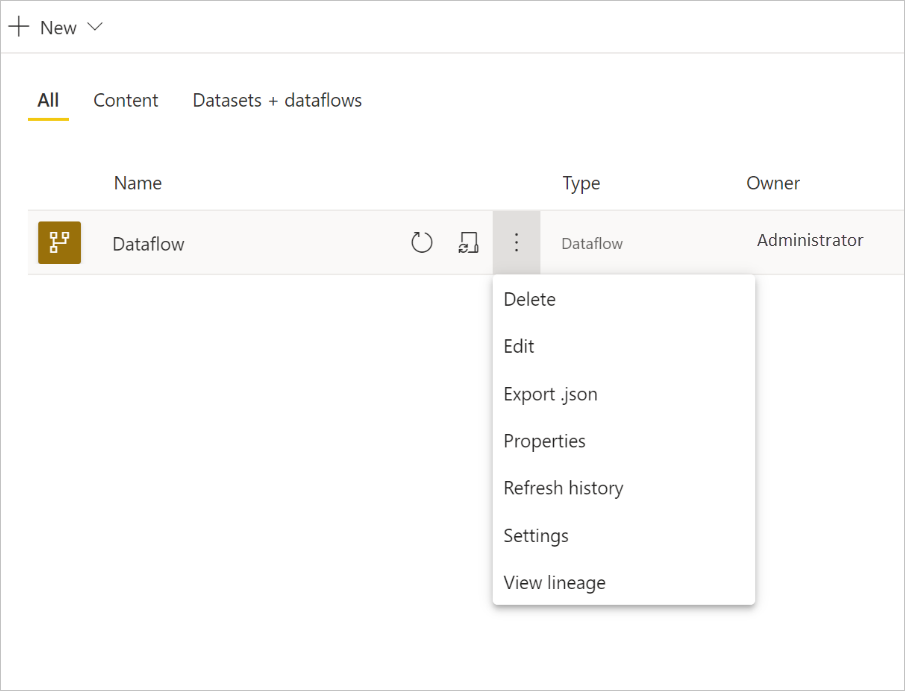
The Settings options provide many options for your dataflow, as the following sections describe.

Take ownership: If you're not the owner of the dataflow, many of these settings are disabled. To take ownership of the dataflow, select Take over to take control. You're prompted to provide credentials to ensure you have the necessary access level.
Gateway Connection: In this section, you can choose whether the dataflow uses a gateway, and select which gateway is used. If you have specified the Gateway as part of editing dataflow, upon taking ownership you may need to update credentials using the edit dataflow option.
Data source credentials: In this section you choose which credentials are being used, and can change how you authenticate to the data source.
Sensitivity label: Here you can define the sensitivity of the data in the dataflow. To learn more about sensitivity labels, see How to apply sensitivity labels in Power BI.
Scheduled refresh: Here you can define the times of day the selected dataflow refreshes. A dataflow can be refreshed at the same frequency as a semantic model.
Enhanced compute engine settings: Here you can define whether the dataflow is stored in the compute engine. The compute engine allows subsequent dataflows, which reference this dataflow, to perform merges and joins and other transformations faster than you would otherwise. It also allows DirectQuery to be performed over the dataflow. Selecting On ensures the dataflow is always supported in DirectQuery mode, and any references benefit from the engine. Selecting Optimized means the engine is only used if there's a reference to this dataflow. Selecting Off disables the compute engine and DirectQuery capability for this dataflow.
Endorsement: You can define whether the dataflow is certified or promoted.
Note
Users with a Pro license or a Premium Per User (PPU) can create a dataflow in a Premium workspace.
Caution
If a workspace is deleted that contains dataflows, all dataflows in that workspace are also deleted. Even if recovery of the workspace is possible, you cannot recover deleted dataflows, either directly or through support from Microsoft.
Refresh a dataflow
Dataflows act as building blocks on top of one another. Suppose you have a dataflow called Raw Data and a linked table called Transformed Data, which contains a linked table to the Raw Data dataflow. When the schedule refresh for the Raw Data dataflow triggers, it will trigger any dataflow that references it upon completion. This functionality creates a chain effect of refreshes, allowing you to avoid having to schedule dataflows manually. There are a few nuances to be aware of when dealing with linked tables refreshes:
A linked table will be triggered by a refresh only if it exists in the same workspace.
A linked table will be locked for editing if a source table is being refreshed or the refresh of the source table is being canceled. If any of the dataflows in a reference chain fail to refresh, all the dataflows will roll back to the old data (dataflow refreshes are transactional within a workspace).
Only referenced tables are refreshed when triggered by a source refresh completion. To schedule all the tables, you should set a schedule refresh on the linked table as well. Avoid setting a refresh schedule on linked dataflows to avoid double refresh.
Cancel Refresh Dataflows support the ability to cancel a refresh, unlike semantic models. If a refresh is running for a long time, you can select More options (the ellipses next to the dataflow) and then select Cancel refresh.
Incremental Refresh (Premium only) Dataflows can also be set to refresh incrementally. To do so, select the dataflow you wish to set up for incremental refresh, and then choose the Incremental Refresh icon.

Setting incremental refresh adds parameters to the dataflow to specify the date range. For detailed information on how to set up incremental refresh, see Using incremental refresh with dataflows.
There are some circumstances under which you shouldn't set incremental refresh:
Linked tables shouldn't use incremental refresh if they reference a dataflow. Dataflows don't support query folding (even if the table is DirectQuery enabled).
Semantic models referencing dataflows shouldn't use incremental refresh. Refreshes to dataflows are generally performant, so incremental refreshes shouldn't be necessary. If refreshes take too long, consider using the compute engine, or DirectQuery mode.
Consume a dataflow
A dataflow can be consumed in the following three ways:
Create a linked table from the dataflow to allow another dataflow author to use the data.
Create a semantic model from the dataflow to allow a user to utilize the data to create reports.
Create a connection from external tools that can read from the CDM (Common Data Model) format.
Consume from Power BI Desktop To consume a dataflow, open Power BI Desktop and select Dataflows in the Get Data dropdown.
Note
The Dataflows connector uses a different set of credentials than the current logged in user. This is by design to support multi-tenant users.
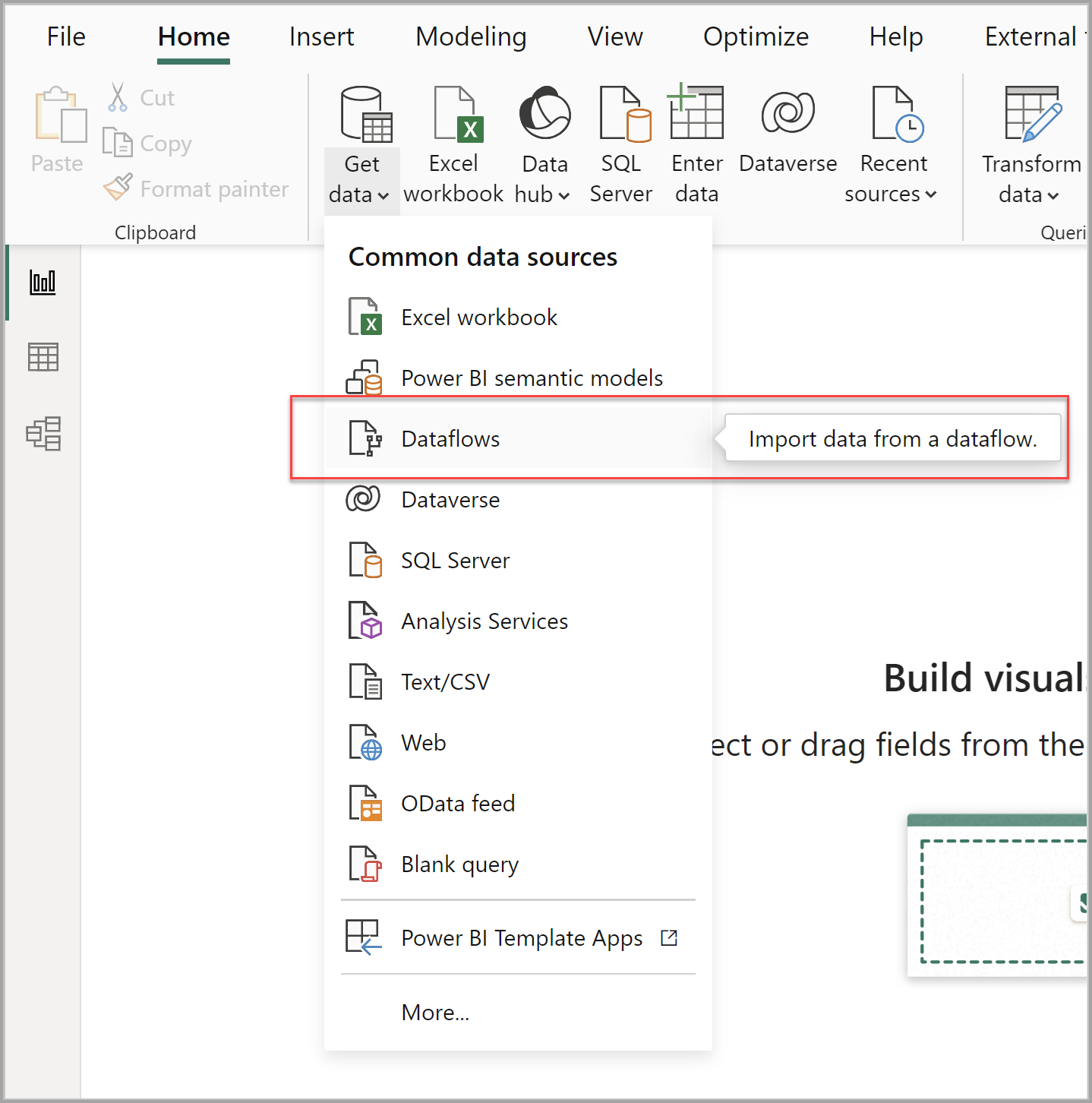
Select the dataflow and tables to which you want to connect.
Note
You can connect to any dataflow or table regardless of which workspace it resides in, and whether or not it was defined in a Premium or non-Premium workspace.
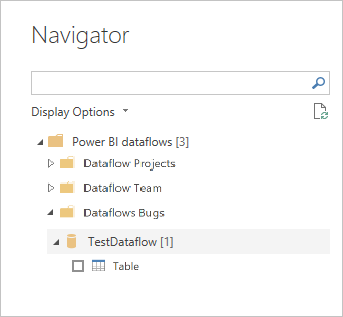
If DirectQuery is available, you're prompted to choose whether you want to connect to the tables through DirectQuery or Import.
In DirectQuery mode, you can quickly interrogate large-scale semantic models locally. However, you can't perform any more transformations.
Using Import brings the data into Power BI, and requires the semantic model to be refreshed independently of the dataflow.
Related content
The following articles provide more information about dataflows and Power BI: