Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Dataflows are supported for Power BI Pro, Premium Per User (PPU), and Power BI Premium users. Some features are only available with a Power BI Premium subscription (which is either a Premium capacity or PPU license). This article describes and details the PPU and Premium-only features and their uses.
The following features are available only with Power BI Premium (PPU or a Premium capacity subscription):
- Enhanced compute engine
- DirectQuery
- Computed entities
- Linked Entities
- Incremental refresh
The following sections describe each of these features in detail.
Important
This article applies to the first generation of dataflows (Gen1), and does not apply to the second generation (Gen2) of dataflows, which are available in Microsoft Fabric. For more information, see Upgrade from Dataflow Gen1 to Dataflow Gen2.
The enhanced compute engine
The enhanced compute engine in Power BI enables Power BI Premium subscribers to use their capacity to optimize the use of dataflows. Using the enhanced compute engine provides the following advantages:
- Drastically reduces the refresh time required for long-running ETL (extract, transform, load) steps over computed entities, such as performing joins, distinct, filters, and group by.
- Performs DirectQuery queries over entities.
Note
- The validation and refresh processes inform dataflows of the model schema. To set the schema of the tables yourself, use the Power Query Editor and set data types.
- This feature is available on all Power BI clusters except WABI-INDIA-CENTRAL-A-PRIMARY
Enable the enhanced compute engine
Important
The enhanced compute engine works only for A3 or larger Power BI capacities.
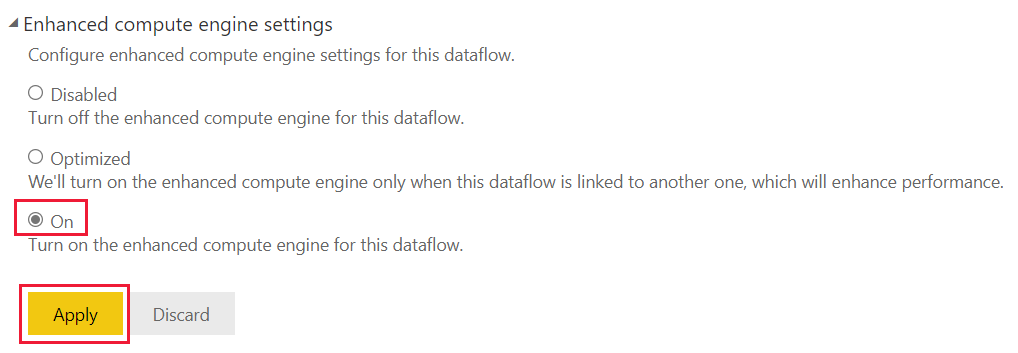
In Power BI Premium, the enhanced compute engine is individually set for each dataflow. There are three configurations to choose from:
Disabled
Optimized (default) - The enhanced compute engine is turned off. It's automatically turned on when a table in the dataflow is referenced by another table or when the dataflow is connected to another dataflow in the same workspace.
On
To change the default setting and enable the enhanced compute engine, do the following steps:
In your workspace, next to the dataflow you want to change the settings for, select More options.
From the dataflow's More options menu, select Settings.
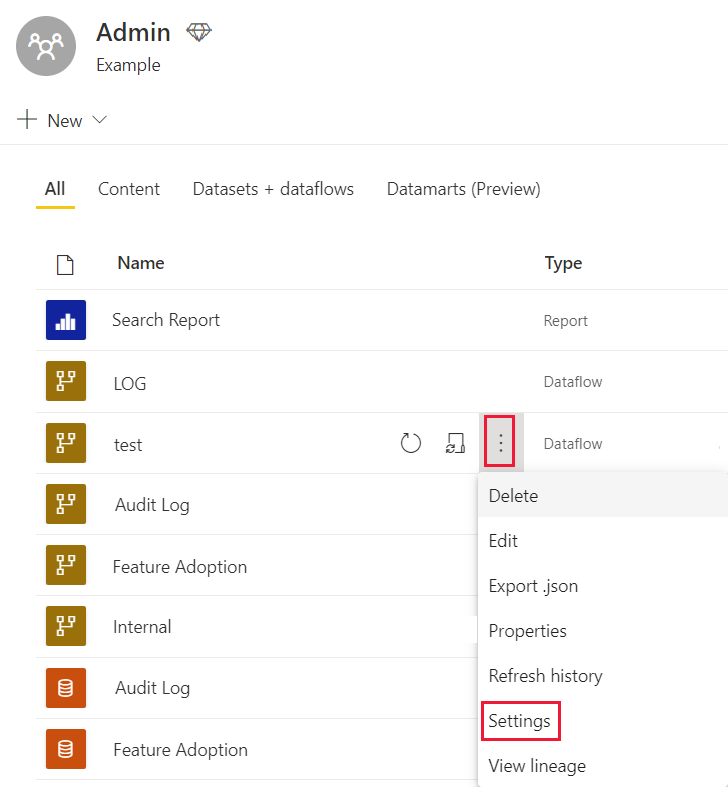
Expand the Enhanced compute engine settings.
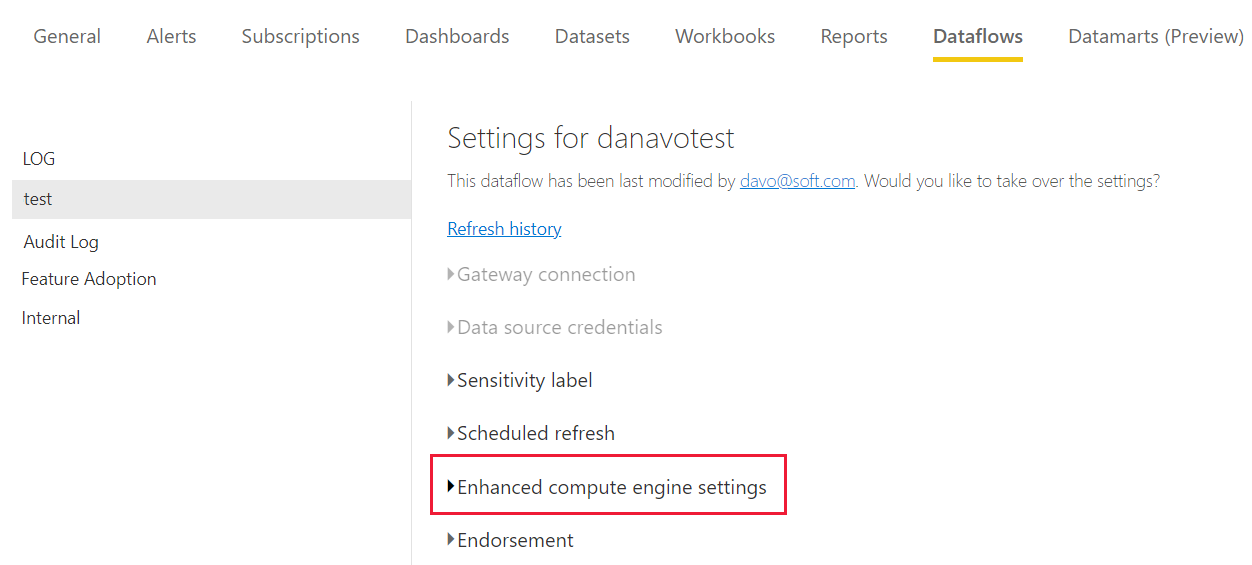
In the Enhanced compute engine settings, select On and then choose Apply.
Use the enhanced compute engine
After the enhanced compute engine is on, return to dataflows and you should see a performance improvement in any computed table that performs complex operations, such as joins or group by operations for dataflows created from existing linked entities on the same capacity.
To make the best use of the compute engine, split the ETL stage into two separate dataflows in the same workspace, in the following way:
- Dataflow 1 - this dataflow should only be ingesting all of the required from a data source.
- Dataflow 2 - perform all ETL operations in this second dataflow, but ensure you're referencing Dataflow 1, which should be on the same capacity. Also ensure you perform operations that can fold first: filter, group by, distinct, join). And perform these operations before any other operation, to ensure the compute engine is utilized.
Common questions and answers
Question: I've enabled the enhanced compute engine, but my refreshes are slower. Why?
Answer: If you enable the enhanced compute engine, there are two possible explanations that could lead to slower refresh times:
When the enhanced compute engine is enabled, it requires some memory to function properly. As such, memory available to perform a refresh is reduced and therefore increases the likelihood of refreshes to be queued. That increase then reduces the number of dataflows that can refresh concurrently. To address this problem, when enabling enhanced compute, spread dataflow refreshes over time and evaluate if your capacity size is adequate, to ensure that there is memory available for concurrent dataflow refreshes.
Another reason you might encounter slower refreshes is that the compute engine only works on top of existing entities. If your dataflow references a data source that's not a dataflow, you won't see an improvement. There will be no performance increase, because in some big data scenarios, the initial read from a data source would be slower because the data needs to be passed to the enhanced compute engine.
Question: I can't see the enhanced compute engine toggle. Why?
Answer: The enhanced compute engine is being released in stages to regions around the world, but isn't yet available in every region.
Question: What are the supported data types for the compute engine?
Answer: The enhanced compute engine and dataflows currently support the following data types. If your dataflow doesn't use one of the following data types, an error occurs during refresh:
- Date/time
- Decimal number
- Text
- Whole number
- Date/time/zone
- True/false
- Date
- Time
Use DirectQuery with dataflows in Power BI
You can use DirectQuery to connect directly to dataflows, and thereby connect directly to your dataflow without having to import its data.
Using DirectQuery with dataflows enables the following enhancements to your Power BI and dataflows processes:
Avoid separate refresh schedules - DirectQuery connects directly to a dataflow, removing the need to create an imported semantic model. As such, using DirectQuery with your dataflows means you no longer need separate refresh schedules for the dataflow and the semantic model to ensure your data is synchronized.
Filtering data - DirectQuery is useful for working on a filtered view of data inside a dataflow. You can use DirectQuery with the compute engine to filter dataflow data and work with the filtered subset you need. Filtering data lets you work with a smaller and more manageable subset of the data in your dataflow.
Use DirectQuery for dataflows
Using DirectQuery with dataflows is available in Power BI Desktop.
There are prerequisites for using DirectQuery with dataflows:
- Your dataflow must reside within a Power BI Premium enabled workspace.
- The compute engine must be turned on.
To learn more about DirectQuery with dataflows, see Using DirectQuery with dataflows.
Enable DirectQuery for dataflows
To ensure your dataflow is available for DirectQuery access, the enhanced compute engine must be in its optimized state. To enable DirectQuery for dataflows, set the new Enhanced compute engine settings option to On.
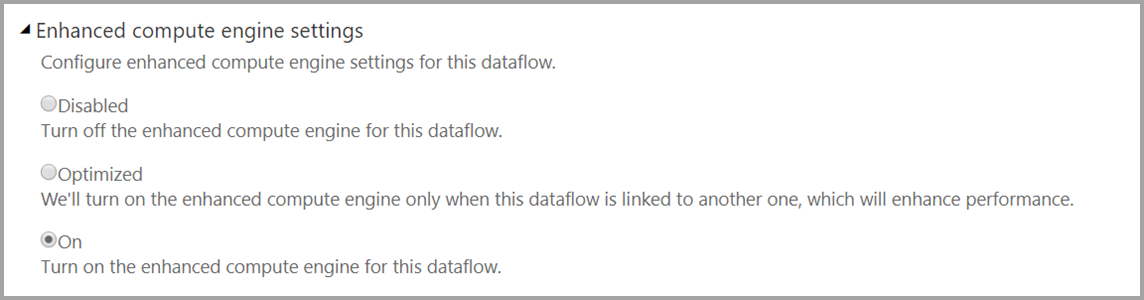
After you've applied that setting, refresh the dataflow for the optimization to take effect.
Considerations and limitations for DirectQuery
There are a few known limitations with DirectQuery and dataflows:
Composite/mixed models that have import and DirectQuery data sources are currently not supported.
Large dataflows might have trouble with timeout issues when viewing visualizations. Large dataflows that run into trouble with timeout issues should use Import mode.
Under data source settings, the dataflow connector will show invalid credentials if you're using DirectQuery. This warning doesn't affect the behavior, and the semantic model will work properly.
When a dataflow has 340 columns or more, using the dataflow connector in Power BI Desktop with the enhanced compute engine setting enabled results in the DirectQuery option being disabled for the dataflow. To use DirectQuery in such configurations, use fewer than 340 columns.
Computed entities
You can perform in-storage computations when using dataflows with a Power BI Premium subscription. This feature lets you perform calculations on your existing dataflows, and return results that enable you to focus on report creation and analytics.
To perform in-storage computations, you first must create the dataflow and bring data into that Power BI dataflow storage. After you have a dataflow that contains data, you can create computed entities, which are entities that perform in-storage computations.
Considerations and limitations of computed entities
When you work with dataflows created in an organization's Azure Data Lake Storage Gen2 account, linked entities and computed entities only work properly when the entities reside in the same storage account.
Computed entities is only supported within a single workspace.
As a best practice, when doing computations on data joined by on-premises and cloud data, create a new dataflow for each source (one for on-premises and one for cloud) and then create a third dataflow to merge/compute over these two data sources.
Linked entities
You can reference existing dataflows in the same workspace by using linked entities with a Power BI Premium subscription, which lets you either perform calculations on these entities using computed entities or allows you to create a "single source of the truth" table that you can reuse within multiple dataflows.
Incremental refresh
Dataflows can be set to refresh incrementally to avoid having to pull all the data on every refresh. To do so, select the dataflow then choose the Incremental Refresh icon.

Setting incremental refresh adds parameters to the dataflow to specify the date range. For detailed information on how to set up incremental refresh, seeUsing incremental refresh with dataflows.
Considerations for when not to set incremental refresh
Don't set a dataflow to incremental refresh in the following situations:
- Linked entities shouldn't use incremental refresh if they reference a dataflow.
Related content
The following articles provide more information about dataflows and Power BI: