Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En esta guía se proporcionan instrucciones paso a paso para usar el reconocimiento de entidades con nombre (NER) personalizado con Microsoft Foundry o la API REST. NER permite detectar y clasificar entidades en texto no estructurado, como personas, lugares, organizaciones y números. Con NER personalizado, puede entrenar modelos para identificar entidades específicas de su negocio y adaptarlas a medida que evolucionan las necesidades.
Para empezar, se proporciona un contrato de préstamo de ejemplo como un conjunto de datos para crear un modelo NER personalizado y extraer estas entidades clave:
- Fecha del contrato
- Nombre, dirección, ciudad y estado del prestatario
- Nombre, dirección, ciudad y estado del prestamista
- Importes de préstamo e intereses
Nota:
- Si ya tiene un lenguaje de Azure en Foundry Tools o un recurso de varios servicios( ya sea por su cuenta o a través de Language Studio), puede seguir usando esos recursos de lenguaje existentes en el portal de Microsoft Foundry. Para obtener más información, consulte Uso de las herramientas de Foundry en el portal de Foundry.
Requisitos previos
Una suscripción de Azure. Si no tiene ninguna, puede crearla gratis.
Permisos necesarios. Asegúrese de que a la persona que establece la cuenta y el proyecto se le asigne el rol de propietario de cuenta de Azure AI en el nivel de suscripción. Como alternativa, tener el rol Colaborador o Colaborador de Cognitive Services en el ámbito de la suscripción también cumple este requisito. Para obtener más información, consulteControl de acceso basado en rol (RBAC).
Un recurso de idioma con una cuenta de almacenamiento. En la página seleccionar características adicionales , seleccione la clasificación de texto personalizado, Reconocimiento de entidades con nombre personalizado, Análisis de sentimiento personalizado y Análisis de texto personalizado para el estado para vincular una cuenta de almacenamiento necesaria a este recurso:

Nota:
- Debe tener un propietario rol asignado en el grupo de recursos para crear un recurso de idioma.
- Si va a conectar una cuenta de almacenamiento preexistente, debe tener asignado un rol de propietario.
- No mueva la cuenta de almacenamiento a otro grupo de recursos o suscripción una vez vinculado con el recurso de lenguaje de Azure.
Un proyecto de fundición creado en Foundry. Para obtener más información, consulteCrear un proyecto Foundry.
Un conjunto de datos NER personalizado cargado en el contenedor de almacenamiento. Un conjunto de datos de reconocimiento de entidades (NER) personalizado es la colección de documentos de texto etiquetados que se usan para entrenar el modelo NER personalizado. Puede descargar nuestro conjunto de datos de ejemplo para este inicio rápido. El idioma de origen es inglés.
Paso 1: Configurar los roles, permisos y opciones necesarios
Comencemos configurando los recursos.
Habilitación de la característica de reconocimiento de entidades con nombre personalizada
Asegúrese de que la característica Clasificación de texto personalizada o Reconocimiento de entidades con nombre personalizado está habilitada en Azure Portal.
- Navegue al recurso de Lenguaje en Azure Portal.
- En el menú de la izquierda, en la sección Administración de recursos , seleccione Características.
- Asegúrese de que la característica Custom text classification /Custom Named Entity Recognition está habilitada.
- Si la cuenta de almacenamiento no está asignada, seleccione y conecte la cuenta de almacenamiento.
- Seleccione Aplicar.
Añadir roles necesarios para su recurso de lenguaje
- En la página Recurso de idioma de Azure Portal, seleccione Control de acceso (IAM) en el panel izquierdo.
- Seleccione Agregar para agregar asignaciones de roles y agregue la asignación de roles Propietario del lenguaje de Cognitive Services o Colaborador de Cognitive Services para el recurso de lenguaje.
- En Asignar acceso a, seleccione Usuario, grupo o entidad de servicio.
- Elija Seleccionar miembros.
- Seleccione el nombre de usuario. Puede buscar por nombres de usuario en el campo Seleccionar. Repita este paso para todos los roles.
- Repita estos pasos para todas las cuentas de usuario que necesitan acceso a este recurso.
Agregar roles necesarios para su cuenta de almacenamiento
- Vaya a la página de la cuenta de almacenamiento en Azure Portal.
- Seleccione Control de acceso (IAM) en el panel izquierdo.
- Seleccione Agregar para Agregar asignaciones de roles y elija el rol Colaborador de datos de blobs de almacenamiento en la cuenta de almacenamiento.
- En Asignar acceso a, seleccione Identidad administrada.
- Elija Seleccionar miembros.
- Seleccione la suscripción y El idioma como identidad administrada. Puedes buscar tu recurso de idioma en el campo Seleccionar.
Adición de roles de usuario necesarios
Importante
Si omite este paso, obtendrá un error 403 al intentar conectarse al proyecto personalizado. Es importante que el usuario actual tenga este rol para acceder a los datos del blob de la cuenta de almacenamiento, incluso si es el propietario de la cuenta de almacenamiento.
- Vaya a la página de la cuenta de almacenamiento en Azure Portal.
- Seleccione Control de acceso (IAM) en el panel izquierdo.
- Seleccione Agregar para Agregar asignaciones de roles y elija el rol Colaborador de datos de blobs de almacenamiento en la cuenta de almacenamiento.
- En Asignar acceso a, seleccione Usuario, grupo o entidad de servicio.
- Elija Seleccionar miembros.
- Seleccione su usuario. Puede buscar por nombres de usuario en el campo Seleccionar.
Importante
Si tiene un firewall, una red virtual o un punto de conexión privado, asegúrese de seleccionar Permitir que los servicios de Azure en la lista de servicios de confianza accedan a esta cuenta de almacenamiento en la pestaña Redes de Azure Portal.

Paso 2: Carga del conjunto de datos en el contenedor de almacenamiento
A continuación, vamos a agregar un contenedor y cargar los archivos del conjunto de datos directamente en el directorio raíz del contenedor de almacenamiento. Estos documentos se usan para entrenar el modelo.
Agregue un contenedor a la cuenta de almacenamiento asociada al recurso de idioma. Para más información, consulteCreación de un contenedor.
Descargue el conjunto de datos de ejemplo de GitHub. El conjunto de datos de ejemplo proporcionado contiene 20 contratos de préstamo:
- Cada contrato incluye dos partes: un prestamista y un prestatario.
- Usted extrae información relevante para: ambas partes, fecha del contrato, importe del préstamo y tasa de interés.
Abra el archivo .zip y extraiga la carpeta que contiene los documentos.
Vaya a Foundry.
Si aún no ha iniciado sesión, el portal le pedirá que lo haga con sus credenciales de Azure.
Una vez que haya iniciado sesión, acceda al proyecto foundry existente para este inicio rápido.
Seleccione Centro de administración en el menú de navegación izquierdo.
Seleccione Recursos conectados en la sección Concentrador del menú Centro de administración .
A continuación, elija el almacenamiento de blobs del área de trabajo que se configuró como recurso conectado.
En el almacenamiento de blobs del área de trabajo, seleccione Ver en el Portal de Azure.
En la página AzurePortal del almacenamiento de blobs, seleccione Cargar en el menú superior. A continuación, elija los
.txtarchivos y.jsonque descargó anteriormente. Por último, seleccione el botón Cargar para agregar el archivo al contenedor.
Ahora que los recursos de Azure necesarios se aprovisionan y configuran en Azure Portal, vamos a usar estos recursos en Foundry para crear un modelo personalizado de Reconocimiento de entidades con nombre (NER) personalizado.
Paso 3: Conectar el recurso de idioma
A continuación, creamos una conexión al recurso de idioma para que Foundry pueda acceder a él de forma segura. Esta conexión proporciona autenticación y administración de identidades seguras, así como acceso controlado y aislado a los datos.
Vuelva a Foundry.
Acceda al proyecto de Foundry existente para este inicio rápido.
Seleccione Centro de administración en el menú de navegación izquierdo.
Seleccione Recursos conectados en la sección Concentrador del menú Centro de administración .
En la ventana principal, seleccione el botón + Nueva conexión .
Seleccione Idioma en la ventana Agregar una conexión a recursos externos .
Seleccione Agregar conexión y, a continuación, seleccione Cerrar.

Paso 4: Ajuste del modelo NER personalizado
Ahora, estamos listos para crear un modelo personalizado de ajuste fino de NER.
En la sección Proyecto del menú Centro de administración , seleccione Ir al proyecto.
En el menú Información general , seleccione Ajustar.
En la ventana principal, seleccione la pestaña ajuste preciso del servicio de IA y, a continuación, el botón + Ajuste preciso.
En la ventana Crear ajuste preciso del servicio, elija la pestaña Reconocimiento de entidades con nombre personalizado y, a continuación, seleccione Siguiente.

En la ventana de Crear tarea de ajuste fino del servicio, complete los campos como se indica a continuación.
Servicio conectado. De forma predeterminada, el nombre de su recurso de idioma ya debería de aparecer en este campo. si no es así, agréguelo desde el menú desplegable.
Nombre. Dé un nombre a su proyecto de tarea de ajuste fino.
Idioma. El inglés se establece como valor predeterminado y ya aparece en el campo .
Descripción. Opcionalmente, puede proporcionar una descripción o dejar este campo vacío.
Contenedor de almacenamiento de blobs. Seleccione el contenedor de almacenamiento de blobs del área de trabajo en el paso 2 y elija el botón Conectar .
Finalmente, seleccione el botón Crear. La operación de creación puede tardar unos minutos en completarse.

Paso 5: Entrenamiento del modelo

- En el menú Introducción , elija Administrar datos. En la ventana Agregar datos para entrenamiento y pruebas , verá los datos de ejemplo que cargó anteriormente en el contenedor de Azure Blob Storage.
- A continuación, en el menú Introducción, seleccione Entrenar modelo.
- Seleccione el botón + Entrenar modelo. Cuando aparezca la ventana Entrenar un nuevo modelo , escriba un nombre para el nuevo modelo y mantenga los valores predeterminados. Haz clic en el botón Siguiente.
- En la ventana Entrenar un nuevo modelo, mantenga habilitado el valor predeterminado Dividir automáticamente el conjunto de test a partir de los datos de entrenamiento, con el porcentaje recomendado establecido en 80% para los datos de entrenamiento y 20% para los datos de test.
- Revise la configuración del modelo y seleccione el botón Crear .
- Después de entrenar un modelo, puede seleccionar Evaluar modelo en el menú Introducción . Puede seleccionar el modelo en la ventana Evaluar modelo y realizar mejoras si es necesario.
Paso 6: Implementación del modelo
Típicamente, después de entrenar un modelo, revisas los detalles de su evaluación. En este inicio rápido, solo tiene que implementar el modelo y hacer que esté disponible para probarlo en el área de juegos de lenguaje de Azure o llamando a la API de predicción. Sin embargo, si lo desea, puede tardar un momento en seleccionar Evaluar el modelo en el menú de la izquierda y explorar la telemetría en profundidad del modelo. Complete los pasos siguientes para implementar el modelo en Foundry.
Seleccione Implementar modelo desde el menú de la izquierda.
A continuación, seleccione ➕Implementar un modelo entrenado en la ventana Implementar el modelo.

Asegúrese de que está seleccionado el botón Crear una nueva implementación.
Complete los campos de ventanaImplementar un modelo entrenado:
- Nombre de la implementación. Asigne un nombre al modelo.
- Asignar un modelo. Seleccione el modelo entrenado en el menú desplegable.
- Región. Seleccione una región en el menú desplegable.
Finalmente, seleccione el botón Crear. El modelo puede tardar unos minutos en implementarse.
Después de una implementación correcta, puede ver el estado de implementación del modelo en la página Implementar el modelo. La fecha de expiración que aparece marca la fecha en que el modelo implementado deja de estar disponible para las tareas de predicción. Esta fecha suele ser de 18 meses después de implementar una configuración de entrenamiento.

Paso 7: Prueba del área de juegos de lenguaje de Azure
El área de juegos de lenguaje proporciona un espacio aislado para probar y configurar el modelo optimizado antes de implementarlo en producción, todo ello sin escribir código.
- En la barra de menús superior, seleccione Probar en el área de juegos.
- En la ventana Área de juegos de lenguaje de Azure, seleccione el icono Reconocimiento de entidades con nombre personalizado .
- En la sección Configuración , seleccione el nombre del proyecto y el nombre de la implementación en los menús desplegables.
- Introduzca una entidad y dé clic en Ejecutar.
- Puede evaluar los resultados en la ventana Detalles .
Eso es todo, ¡enhorabuena!
En este inicio rápido, ha creado un modelo NER personalizado optimizado, lo ha implementado en Foundry y ha probado el modelo en el área de juegos de lenguaje de Azure.
Limpieza de recursos
Si ya no necesita el proyecto, puede eliminarlo de Foundry.
- Vaya a la página principal de Foundry . Inicie el proceso de autenticación iniciando sesión, a menos que ya haya completado este paso y la sesión esté activa.
- Seleccione el proyecto que desea eliminar desde Mantener la compilación con Foundry.
- Seleccione Centro de administración.
- Seleccione Eliminar proyecto.
Para eliminar el centro junto con todos sus proyectos:
Vaya a la pestaña Resumen de la sección Hub.
A la derecha, seleccione Eliminar hub.
El enlace abre Azure Portal para que elimine el centro en él.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita
Creación de un nuevo lenguaje de Azure en el recurso de Foundry Tools y la cuenta de almacenamiento de Azure
Para poder usar el reconocimiento de entidades con nombre personalizado (NER), debe crear un recurso de lenguaje, que proporciona las credenciales que necesita para crear un proyecto e iniciar el entrenamiento de un modelo. También necesita una cuenta de Azure Storage, donde puede cargar el conjunto de datos que se usa en la creación del modelo.
Importante
Para empezar a trabajar rápidamente, se recomienda crear un nuevo recurso de lenguaje. Siga los pasos proporcionados en este artículo para crear un recurso de lenguaje de Azure y crear o conectar una cuenta de almacenamiento al mismo tiempo. Crear ambos al mismo tiempo es más fácil que hacerlo más adelante.
Si tiene un recurso preexistente que le gustaría usar, debe conectarlo a la cuenta de almacenamiento. Para obtener más información, consulte Creación de un proyecto.
Creación de un nuevo recurso en Azure Portal
Inicie sesión en Azure Portal para crear un nuevo lenguaje de Azure en el recurso de Foundry Tools.
En la ventana que se abre, seleccione Clasificación de texto personalizado y reconocimiento de entidades con nombre personalizadas en las características personalizadas. Seleccione Continuar para crear el recurso en la parte inferior de la pantalla.

Cree un recurso de idioma con los detalles siguientes.
Nombre Descripción Suscripción Su suscripción de Azure. Grupo de recursos Un grupo de recursos que contiene tu recurso. Puede elegir uno existente o crear uno. Region La región del recurso de idioma. Por ejemplo, "Oeste de EE. UU. 2". Nombre Nombre del recurso. Plan de tarifa Plan de tarifa del recurso de idioma. Puede usar el nivel de servicio Gratis (F0) para probar el servicio. Nota:
Si recibe un mensaje que indica "la cuenta de inicio de sesión no es propietario del grupo de recursos de la cuenta de almacenamiento seleccionada", la cuenta debe tener asignado un rol de propietario en el grupo de recursos para poder crear un recurso de idioma. Póngase en contacto con el propietario de la suscripción de Azure para obtener ayuda.
En la sección Clasificación de texto personalizado y reconocimiento de entidades con nombre personalizadas, seleccione una cuenta de almacenamiento existente o Nueva cuenta de almacenamiento. Estos valores son para ayudarle a empezar y no necesariamente los valores de la cuenta de almacenamiento que desea usar en entornos de producción. Para evitar la latencia durante la compilación del proyecto, conéctese a cuentas de almacenamiento en la misma región que el recurso language.
Valor de la cuenta de almacenamiento Valor recomendado Nombre de la cuenta de almacenamiento Cualquier nombre Tipo de cuenta de almacenamiento Almacenamiento con redundancia local estándar (LRS) Asegúrese de que el Aviso de IA responsable esté activado. Seleccione Revisar y crear en la parte inferior de la página y, luego, seleccione Crear.

Carga de datos de ejemplo en el contenedor de blob
Después de crear una cuenta de Azure Storage y conectarla al recurso language, debe cargar los documentos del conjunto de datos de ejemplo en el directorio raíz del contenedor. Estos documentos se usan para entrenar el modelo.
Descargue el conjunto de datos de ejemplo de GitHub.
Abra el archivo .zip y extraiga la carpeta que contiene los documentos.
En Azure Portal, navegue hasta la cuenta de almacenamiento que ha creado y selecciónela.
En la cuenta de almacenamiento, seleccione Contenedores en el menú de la izquierda, que se encuentra debajo de Almacenamiento de datos. En la pantalla que aparece, seleccione + Contenedor. Asigne al contenedor el nombre example-data y deje el Nivel de acceso público predeterminado.
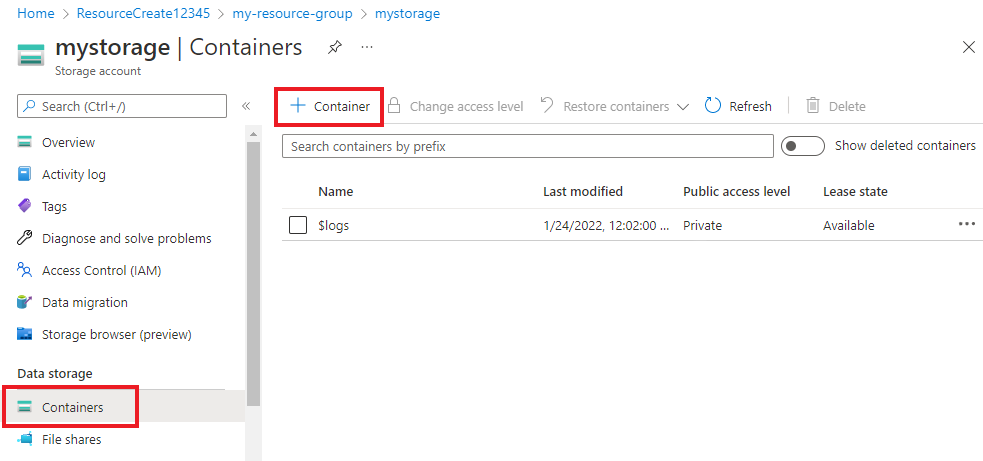
Una vez creado el contenedor, selecciónelo. A continuación, seleccione el botón Cargar para seleccionar los archivos
.txty.jsonque descargó anteriormente.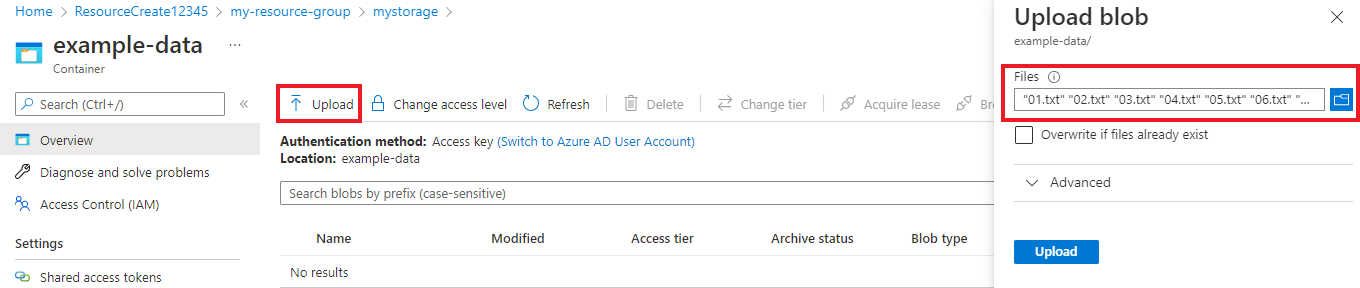


El conjunto de datos de muestra proporcionado contiene 20 contratos. Cada contrato incluye dos partes: un prestamista y un prestatario. Puede usar el archivo de ejemplo proporcionado para extraer información pertinente de ambas partes, una fecha de contrato, el importe del préstamo y una tasa de interés.
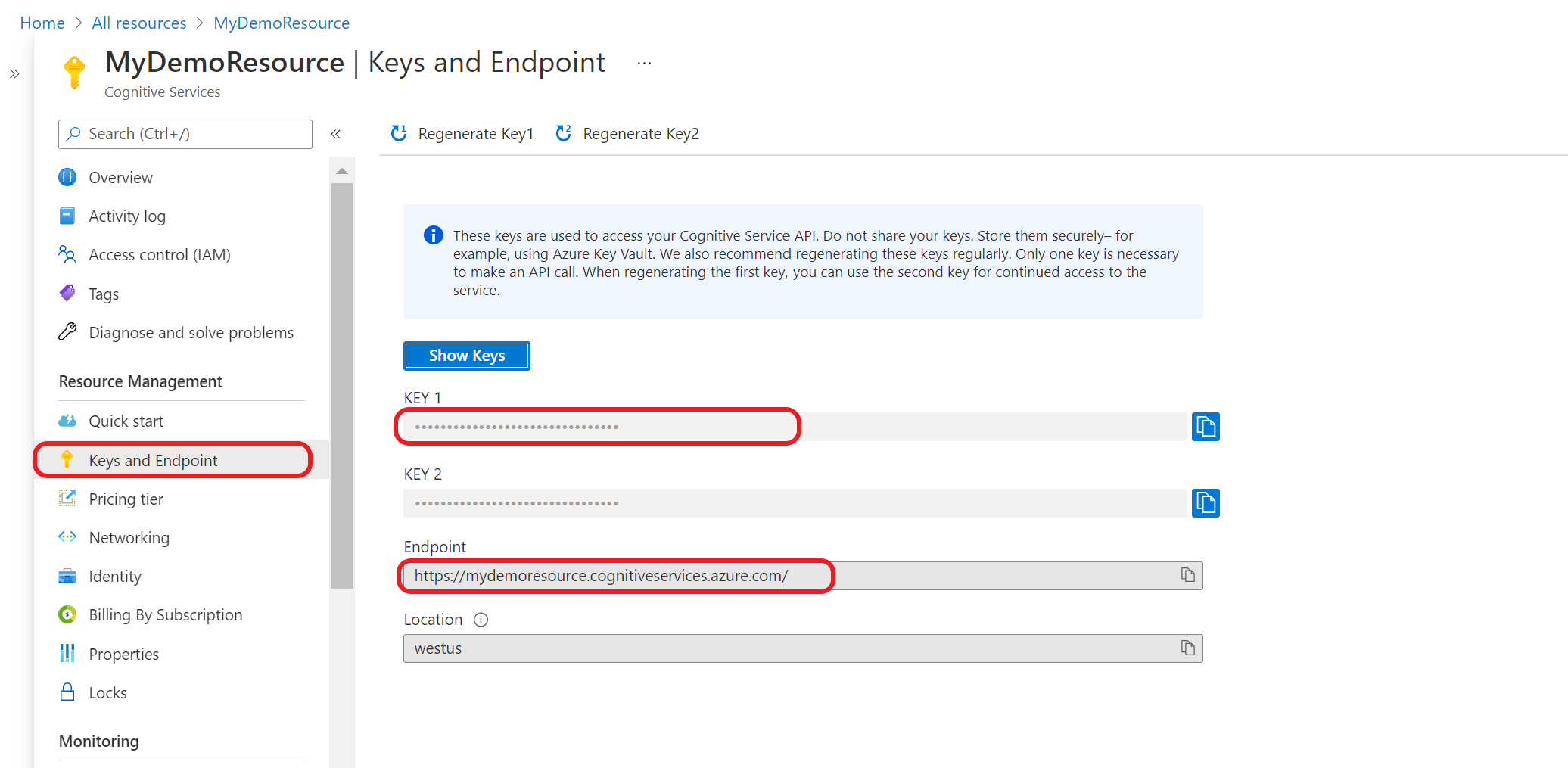
Obtención de las claves de recursos y el punto de conexión
Vaya a la página de información general del recurso en Azure Portal.
En el menú de la izquierda, seleccione Claves y punto de conexión. El punto de conexión y la clave se usan para las solicitudes de API.

Creación de un proyecto de NER personalizado
Una vez configurados el recurso y la cuenta de almacenamiento, cree un nuevo proyecto de NER personalizado. Un proyecto es un área de trabajo para compilar modelos de Machine Learning personalizados basados en los datos. Solo usted y otros usuarios que tengan acceso al recurso de Lenguaje de Azure que se usa pueden acceder al proyecto.
Use el archivo de etiquetas que descargó de los datos de ejemplo en el paso anterior y agréguelo al cuerpo de la siguiente solicitud.
Desencadenamiento del trabajo del proyecto de importación
Envíe una solicitud POST con la dirección URL, los encabezados y el cuerpo JSON que se incluyen a continuación para importar el archivo de etiquetas. Asegúrese de que el archivo de etiquetas siga el formato aceptado.
Si ya existe un proyecto con el mismo nombre, se reemplazan los datos de ese proyecto.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Marcador de posición | Value | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{API-VERSION} |
La versión de la API que estás llamando. El valor al que se hace referencia aquí es para la versión más reciente publicada. Para obtener más información, consulteCiclo de vida del modelo. | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Value |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Body
Utilice el siguiente código JSON en la solicitud. Reemplace los valores de marcador de posición por sus propios valores.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomEntityRecognition",
"description": "Trying out custom NER",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomEntityRecognition",
"entities": [
{
"category": "Entity1"
},
{
"category": "Entity2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| Clave | Marcador de posición | Value | Ejemplo |
|---|---|---|---|
api-version |
{API-VERSION} |
La versión de la API que estás llamando. La versión que se usa aquí debe ser la misma versión de API en la dirección URL. Obtenga más información sobre otras versiones de API disponibles | 2022-03-01-preview |
projectName |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
projectKind |
CustomEntityRecognition |
El tipo de proyecto. | CustomEntityRecognition |
language |
{LANGUAGE-CODE} |
Una cadena que especifica el código de idioma de los documentos que se usan en el proyecto. Si el proyecto es un proyecto multilingüe, elija el código de idioma de la mayoría de los documentos. | en-us |
multilingual |
true |
Un valor booleano que le permite tener documentos en varios idiomas del conjunto de datos y, cuando se implementa el modelo, puede consultar el modelo en cualquier idioma admitido (no necesariamente incluido en los documentos de entrenamiento. Consulte Compatibilidad de idioma para obtener información sobre la compatibilidad multilingüe. | true |
storageInputContainerName |
{CONTAINER-NAME} | Nombre del contenedor de Azure Storage que contiene los documentos cargados. | myContainer |
entities |
Matriz que contiene todos los tipos de entidad que tiene en su proyecto y que se han extraído de sus documentos. | ||
documents |
Matriz que contiene todos los documentos del proyecto y la lista de las entidades etiquetadas en cada documento. | [] | |
location |
{DOCUMENT-NAME} |
Ubicación de los documentos en el contenedor de almacenamiento. | doc1.txt |
dataset |
{DATASET} |
Conjunto de pruebas al que este archivo va cuando se divide antes del entrenamiento. Para obtener más información, veaCómo entrenar un modelo. Los valores posibles que admite este campo son Train y Test. |
Train |
Una vez que envíe la solicitud de API, recibirá una 202 respuesta que indica que el trabajo se envió correctamente. En los encabezados de respuesta, extraiga el valor operation-location. Este es un ejemplo del formato:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} se usa para identificar la solicitud, ya que esta operación es asincrónica. Utilice esta dirección URL para obtener el estado del trabajo de importación.
Posibles escenarios de error para esta solicitud:
- El recurso seleccionado no tiene los permisos adecuados para la cuenta de almacenamiento.
- El valor
storageInputContainerNameespecificado no existe. - Se ha usado un código de idioma no válido o si el tipo de código de idioma no es una cadena.
-
El valor de
multilinguales una cadena y no un valor booleano.
Obtención del estado del trabajo de importación
Use la siguiente solicitud GET para obtener el estado de la importación del proyecto. Reemplace los valores de marcador de posición por sus propios valores.
URL de la solicitud
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Marcador de posición | Value | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{JOB-ID} |
Identificador para localizar el estado de entrenamiento del modelo. Este valor se encuentra en el valor de encabezado location que recibió en el paso anterior. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versión de la API que estás llamando. El valor al que se hace referencia es para la versión más reciente publicada. Para obtener más información, consulteCiclo de vida del modelo. | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Value |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Entrenamiento de un modelo
Después de crear un proyecto, continúe y empiece a etiquetar los documentos que tiene en el contenedor conectado al proyecto. En este inicio rápido, ha importado un conjunto de datos etiquetado de ejemplo e inicializó el proyecto con el archivo de etiquetas JSON de ejemplo.
Inicio del trabajo de entrenamiento
Después de importar el proyecto, puede empezar a entrenar el modelo.
Envíe una solicitud POST mediante la dirección URL, los encabezados y el cuerpo JSON para enviar un trabajo de entrenamiento. Reemplace los valores de marcador de posición por sus propios valores.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Marcador de posición | Value | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{API-VERSION} |
La versión de la API que estás llamando. El valor al que se hace referencia es para la versión más reciente publicada. Para obtener más información, consulteCiclo de vida del modelo. | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Value |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la solicitud
Use el siguiente código JSON en el cuerpo de la solicitud. El modelo se denomina igual que {MODEL-NAME} una vez completado el entrenamiento. Solo los trabajos de entrenamiento exitosos generan modelos.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Clave | Marcador de posición | Value | Ejemplo |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
El nombre que se asigna al modelo una vez que ha sido entrenado correctamente. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Esta es la versión del modelo que se usa para entrenar el modelo. | 2022-05-01 |
| evaluationOptions | Opción para dividir los datos en conjuntos de entrenamiento y pruebas. | {} |
|
| kind | percentage |
Métodos de división. Los valores posibles son percentage o manual. Para obtener más información, veaCómo entrenar un modelo. |
percentage |
| trainingSplitPercentage | 80 |
Porcentaje de los datos etiquetados que se incluirán en el conjunto de entrenamiento. El valor recomendado es 80. |
80 |
| testingSplitPercentage | 20 |
Porcentaje de los datos etiquetados que se incluirán en el conjunto de pruebas. El valor recomendado es 20. |
20 |
Nota:
trainingSplitPercentage y testingSplitPercentage solo son necesarios si Kind se establece en percentage y la suma de ambos porcentajes es igual a 100.
Una vez que envíe la solicitud de API, recibirá una 202 respuesta que indica que el trabajo se envió correctamente. En los encabezados de respuesta, extraiga el valor location con el siguiente formato:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} se usa para identificar la solicitud, ya que esta operación es asincrónica. Puede usar esta dirección URL para obtener el estado del entrenamiento.
Obtención del estado del trabajo de entrenamiento
El entrenamiento puede tardar entre 10 y 30 minutos en este conjunto de datos de ejemplo. Puede usar la siguiente solicitud para seguir consultando el estado del trabajo de entrenamiento hasta que se complete con éxito.
Use la siguiente solicitud GET para obtener el estado del proceso de entrenamiento del modelo. Reemplace los valores de marcador de posición por sus propios valores.
URL de la solicitud
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Marcador de posición | Value | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{JOB-ID} |
Identificador para localizar el estado de entrenamiento del modelo. Este valor se encuentra en el valor de encabezado location que recibió en el paso anterior. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versión de la API que estás llamando. El valor al que se hace referencia es para la versión más reciente publicada. Para obtener más información, consulteCiclo de vida del modelo. | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Value |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la respuesta
Una vez que envíe la solicitud, obtendrá la siguiente respuesta.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Implementación del modelo
Por lo general, después de entrenar un modelo, revisaría sus detalles de evaluación y realizaría mejoras si fuera necesario. En este inicio rápido, solo tiene que implementar el modelo y hacer que esté disponible para probarlo en Language Studio, o bien puede llamar a la API de predicción.
Inicio del trabajo de implementación
Envíe una solicitud PUT mediante la dirección URL, los encabezados y el cuerpo JSON para enviar un trabajo de implementación. Reemplace los valores de marcador de posición por sus propios valores.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Marcador de posición | Value | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{DEPLOYMENT-NAME} |
Nombre de la implementación. Este valor distingue mayúsculas de minúsculas. | staging |
{API-VERSION} |
La versión de la API que estás llamando. El valor al que se hace referencia es para la versión más reciente publicada. Para obtener más información, consulteCiclo de vida del modelo. | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Value |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la solicitud
Use el siguiente JSON en el cuerpo de la solicitud. Use el nombre del modelo que se va a asignar a la implementación.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Clave | Marcador de posición | Value | Ejemplo |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
El nombre del modelo que se asigna a tu implementación. Solo puede asignar modelos entrenados correctamente. Este valor distingue mayúsculas de minúsculas. | myModel |
Una vez que envíe la solicitud de API, recibirá una 202 respuesta que indica que el trabajo se envió correctamente. En los encabezados de respuesta, extraiga el valor operation-location con el siguiente formato:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} se usa para identificar la solicitud, ya que esta operación es asincrónica. Puede usar esta dirección URL para obtener el estado de la implementación.
Obtención del estado del trabajo de implementación
Use la siguiente solicitud GET para consultar el estado del trabajo de implementación. Puede usar la dirección URL que recibió en el paso anterior o reemplazar los valores de los marcadores de posición por sus propios valores.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Marcador de posición | Value | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{DEPLOYMENT-NAME} |
Nombre de la implementación. Este valor distingue mayúsculas de minúsculas. | staging |
{JOB-ID} |
Identificador para localizar el estado de entrenamiento del modelo. Se encuentra en el valor del encabezado location que recibió en el paso anterior. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versión de la API que estás llamando. El valor al que se hace referencia es para la versión más reciente publicada. Para obtener más información, consulteCiclo de vida del modelo. | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Value |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la respuesta
Una vez que envíe la solicitud, obtendrá la siguiente respuesta. Siga sondeando este punto de conexión hasta que el parámetro status cambie a "succeeded". Debe obtener un código 200 para indicar el éxito de la solicitud.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Extracción de entidades personalizadas
Una vez implementado el modelo, puede empezar a usarlo para extraer entidades del texto mediante Prediction API. En el conjunto de datos de ejemplo, descargado anteriormente, puede encontrar algunos documentos de prueba que puede usar en este paso.
Envío de una tarea de NER personalizado
Use esta solicitud POST para iniciar una tarea de clasificación de texto.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Marcador de posición | Value | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
La versión de la API que estás llamando. El valor al que se hace referencia es para la versión más reciente publicada. Para obtener más información, consulteCiclo de vida del modelo. | 2022-05-01 |
encabezados
| Clave | Value |
|---|---|
| Ocp-Apim-Subscription-Key | La clave que proporciona acceso a esta API. |
Body
{
"displayName": "Extracting entities",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomEntityRecognition",
"taskName": "Entity Recognition",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Clave | Marcador de posición | Value | Ejemplo |
|---|---|---|---|
displayName |
{JOB-NAME} |
Nombre del trabajo. | MyJobName |
documents |
[{},{}] | Lista de documentos en los que se van a ejecutar las tareas. | [{},{}] |
id |
{DOC-ID} |
Nombre o identificador del documento. | doc1 |
language |
{LANGUAGE-CODE} |
Cadena donde se especifica el código de idioma del documento. Si no se especifica esta clave, el servicio asume el idioma predeterminado del proyecto que se seleccionó durante la creación del proyecto. Consulte Compatibilidad de idiomas para ver una lista de los códigos de idioma admitidos. | en-us |
text |
{DOC-TEXT} |
Tarea de documento en la que ejecutar las tareas. | Lorem ipsum dolor sit amet |
tasks |
Lista de tareas que queremos realizar. | [] |
|
taskName |
CustomEntityRecognition |
Nombre de la tarea. | CustomEntityRecognition |
parameters |
Lista de parámetros que se van a pasar a la tarea. | ||
project-name |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Nombre de la implementación. Este valor distingue mayúsculas de minúsculas. | prod |
Response
Recibe una respuesta 202 que indica que la tarea se ha enviado correctamente. En los encabezados de respuesta, extraigaoperation-location.
operation-location tiene el formato siguiente:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Puede usar esta dirección URL para consultar el estado de finalización de la tarea y obtener los resultados cuando la tarea se complete.
Obtención de resultados de la tarea
Use la siguiente solicitud GET para consultar el estado y los resultados de la tarea de reconocimiento de entidades personalizado.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Marcador de posición | Value | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
La versión de la API que estás llamando. El valor al que se hace referencia es para la versión más reciente publicada. Para obtener más información, consulteCiclo de vida del modelo. | 2022-05-01 |
encabezados
| Clave | Value |
|---|---|
| Ocp-Apim-Subscription-Key | La clave que proporciona acceso a esta API. |
Cuerpo de la respuesta
La respuesta será un documento JSON con los parámetros siguientes.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxx-xxxxx-xxxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "EntityRecognitionLROResults",
"taskName": "Recognize Entities",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"entities": [
{
"category": "Event",
"confidenceScore": 0.61,
"length": 4,
"offset": 18,
"text": "trip"
},
{
"category": "Location",
"confidenceScore": 0.82,
"length": 7,
"offset": 26,
"subcategory": "GPE",
"text": "Seattle"
},
{
"category": "DateTime",
"confidenceScore": 0.8,
"length": 9,
"offset": 34,
"subcategory": "DateRange",
"text": "last week"
}
],
"id": "1",
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Limpieza de recursos
Cuando ya no necesite el proyecto, puede eliminarlo con la siguiente solicitud DELETE. Reemplace los valores de marcador de posición por sus propios valores.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Marcador de posición | Value | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{API-VERSION} |
La versión de la API que estás llamando. El valor al que se hace referencia es para la versión más reciente publicada. Para obtener más información, consulteCiclo de vida del modelo. | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Value |
|---|---|
| Ocp-Apim-Subscription-Key | Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Una vez que envíe la solicitud de API, recibirá una 202 respuesta que indica que se ha realizado correctamente, lo que significa que se elimina el proyecto. Resultados de una llamada correcta con un encabezado Operation-Location usado para comprobar el estado del trabajo.
Contenido relacionado
Después de crear el modelo de extracción de entidades, puede usar la API en tiempo de ejecución para extraer entidades.
A medida que crea sus propios proyectos NER personalizados, utilice nuestros artículos instructivos para aprender más sobre el etiquetado, el entrenamiento y el uso detallado de su modelo.