Implementación de modelos de lenguaje grande con Azure AI Studio
Importante
Algunas de las características descritas en este artículo solo pueden estar disponibles en versión preliminar. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
La implementación de un modelo de lenguaje grande (LLM) hace que esté disponible para su uso en un sitio web, una aplicación u otros entornos de producción. La implementación suele implicar hospedar el modelo en un servidor o en la nube y crear una API u otra interfaz para que los usuarios interactúen con el modelo. Puede invocar la implementación para la inferencia en tiempo real de aplicaciones de IA generativa, como chat y copiloto.
En este artículo aprenderá a implementar modelos de lenguaje grande en Inteligencia artificial de Azure Studio. Puede implementar modelos desde el catálogo de modelos o desde el proyecto. También puede implementar modelos mediante el SDK de Azure Machine Learning. En el artículo también se explica cómo realizar la inferencia en el modelo implementado.
Implementación e inferencia de un modelo de API sin servidor con código
Implementación de un modelo
Los modelos de API sin servidor son los modelos que puede implementar con la facturación de pago por uso. Algunos ejemplos son Phi-3, Llama-2, Command R, Mistral Large, etc. En el caso de los modelos de API sin servidor, solo se le cobrará por la inferencia, a menos que decida ajustar el modelo.
Obtención del id. del modelo
Puede implementar modelos de API sin servidor mediante el SDK de Azure Machine Learning, pero en primer lugar, vamos a examinar el catálogo de modelos y obtener el identificador de modelo que necesita para la implementación.
Inicie sesión en Inteligencia artificial de Azure Studio y vaya a la página Inicio.
Seleccione Catálogo de modelos en la barra lateral izquierda.
En el filtro Opciones de implementación, seleccione API sin servidor.
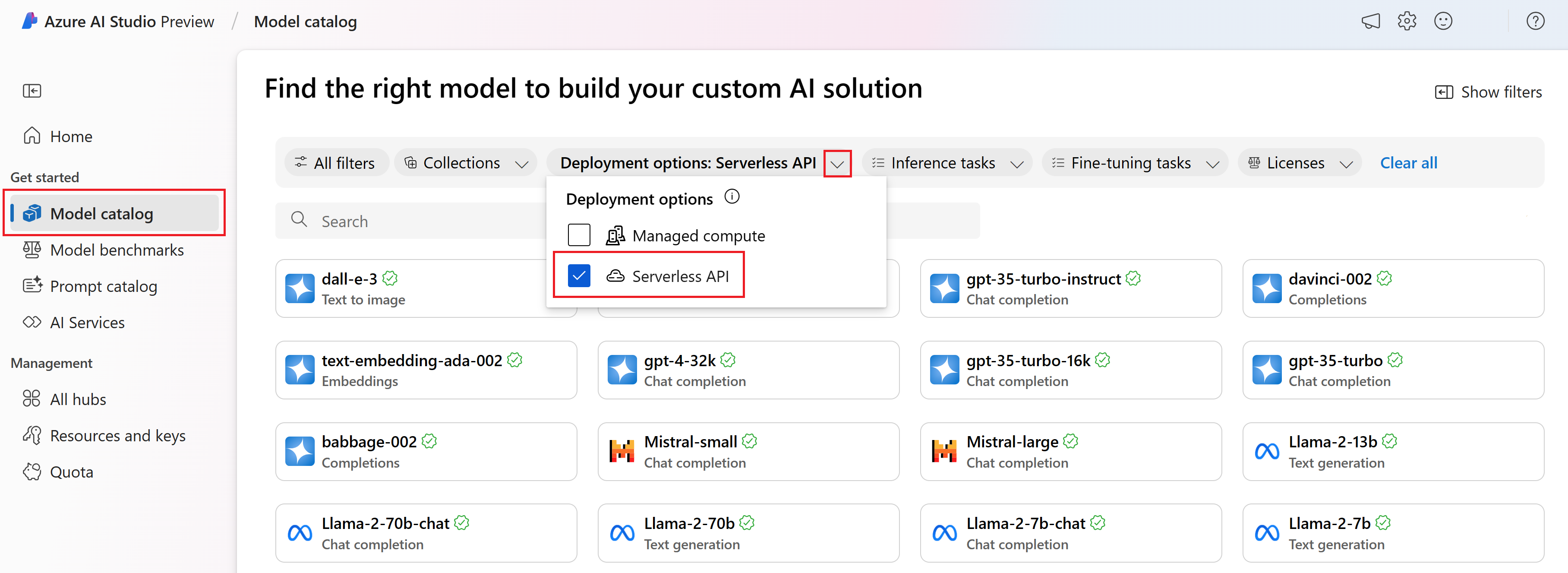
Seleccione un modelo.
Copie el id. del modelo de la página de detalles del modelo seleccionado. Se parece a esta:
azureml://registries/azureml-cohere/models/Cohere-command-r-plus/versions/3

Instalación del SDK de Azure Machine Learning
A continuación, debe instalar el SDK de Azure Machine Learning. Ejecute los siguientes comandos en el terminal:
pip install azure-ai-ml
pip install azure-identity
Implementación del modelo de API sin servidor
En primer lugar, debe autenticarse en Azure AI.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import MarketplaceSubscription, ServerlessEndpoint
# You can find your credential information in project settings.
client = MLClient(
credential=DefaultAzureCredential(),
subscription_id="your subscription name goes here",
resource_group_name="your resource group name goes here",
workspace_name="your project name goes here",
)
En segundo lugar, vamos a hacer referencia al identificador de modelo que encontró anteriormente.
# You can find the model ID on the model catalog.
model_id="azureml://registries/azureml-meta/models/Llama-2-70b-chat/versions/18"
Los modelos de API sin servidor de proveedores de modelos de terceros requieren una suscripción de Azure Marketplace para poder usar el modelo. Vamos a crear una suscripción a Marketplace.
Nota:
Puede omitir esta parte si está implementando un modelo de API sin servidor de Microsoft, como Phi-3.
# You can customize the subscription name.
subscription_name="Meta-Llama-2-70b-chat"
marketplace_subscription = MarketplaceSubscription(
model_id=model_id,
name=subscription_name,
)
marketplace_subscription = client.marketplace_subscriptions.begin_create_or_update(
marketplace_subscription
).result()
Por último, vamos a crear un punto de conexión sin servidor.
endpoint_name="Meta-Llama-2-70b-chat-qwerty" # Your endpoint name must be unique
serverless_endpoint = ServerlessEndpoint(
name=endpoint_name,
model_id=model_id
)
created_endpoint = client.serverless_endpoints.begin_create_or_update(
serverless_endpoint
).result()
Obtención del punto de conexión y las claves de la API sin servidor
endpoint_keys = client.serverless_endpoints.get_keys(endpoint_name)
print(endpoint_keys.primary_key)
print(endpoint_keys.secondary_key)
Inferencia de implementación
Para la inferencia, querrá usar el código específico para los distintos tipos de modelos y SDK que esté usando. Puede encontrar ejemplos de código en el repositorio de ejemplos de Azure/azureml-examples.
Implementación e inferencia de una implementación de proceso administrada con código
Implementación de un modelo
El catálogo de modelos de Inteligencia artificial de Azure Studio ofrece más de 1.600 modelos, y la forma más común de implementar estos modelos es usando la opción de implementación de equipo administrado, a la que a veces también se hace referencia como implementación en línea administrada.
Obtención del id. del modelo
Puede implementar modelos de proceso administrados usando el SDK de Azure Machine Learning, pero primero vamos a examinar el catálogo de modelos y obtener el id. del modelo que necesita para la implementación.
Inicie sesión en Inteligencia artificial de Azure Studio y vaya a la página Inicio.
Seleccione Catálogo de modelos en la barra lateral izquierda.
En el filtro Opciones de implementación, seleccione Proceso administrado.
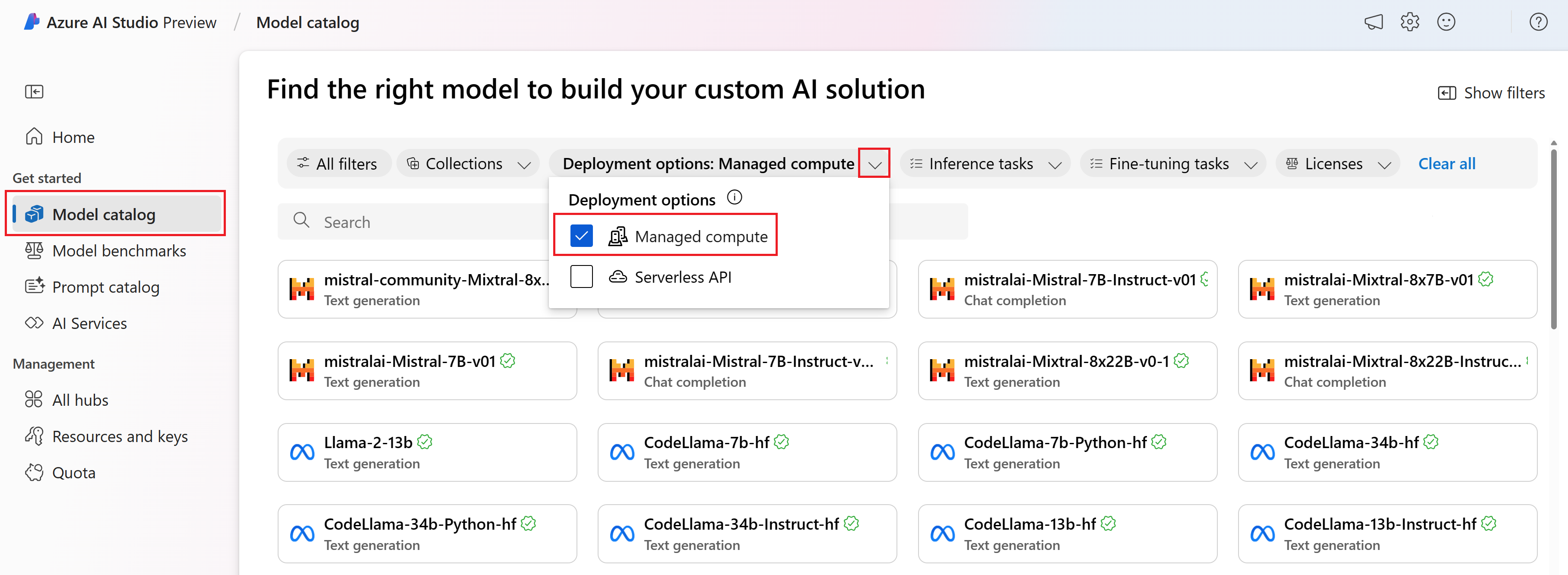
Seleccione un modelo.
Copie el id. del modelo de la página de detalles del modelo seleccionado. Se parece a esta:
azureml://registries/azureml/models/deepset-roberta-base-squad2/versions/16

Instalación del SDK de Azure Machine Learning
Para este paso, debe instalar el SDK de Azure Machine Learning.
pip install azure-ai-ml
pip install azure-identity
Implementación del modelo
En primer lugar, debe autenticarse en Azure AI.
from azure.ai.ml import MLClient
from azure.identity import InteractiveBrowserCredential
client = MLClient(
credential=InteractiveBrowserCredential,
subscription_id="your subscription name goes here",
resource_group_name="your resource group name goes here",
workspace_name="your project name goes here",
)
Vamos a implementar el modelo.
Para la opción de Implementación de proceso administrado, es necesario crear un punto de conexión antes de implementar un modelo. Piense en el punto de conexión como un contenedor que puede albergar múltiples implementaciones de modelos. Los nombres de los puntos de conexión deben ser únicos en una región, por lo que en este ejemplo estamos usando la marca de tiempo para crear un nombre de punto de conexión único.
import time, sys
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
ProbeSettings,
)
# Make the endpoint name unique
timestamp = int(time.time())
online_endpoint_name = "customize your endpoint name here" + str(timestamp)
# Create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
auth_mode="key",
)
workspace_ml_client.begin_create_or_update(endpoint).wait()
Cree una implementación. Puede encontrar el identificador de modelo en el catálogo de modelos.
model_name = "azureml://registries/azureml/models/deepset-roberta-base-squad2/versions/16"
demo_deployment = ManagedOnlineDeployment(
name="demo",
endpoint_name=online_endpoint_name,
model=model_name,
instance_type="Standard_DS3_v2",
instance_count=2,
liveness_probe=ProbeSettings(
failure_threshold=30,
success_threshold=1,
timeout=2,
period=10,
initial_delay=1000,
),
readiness_probe=ProbeSettings(
failure_threshold=10,
success_threshold=1,
timeout=10,
period=10,
initial_delay=1000,
),
)
workspace_ml_client.online_deployments.begin_create_or_update(demo_deployment).wait()
endpoint.traffic = {"demo": 100}
workspace_ml_client.begin_create_or_update(endpoint).result()
Inferencia de implementación
Necesita datos json de ejemplo para probar la inferencia. Cree sample_score.json con el siguiente código.
{
"inputs": {
"question": [
"Where do I live?",
"Where do I live?",
"What's my name?",
"Which name is also used to describe the Amazon rainforest in English?"
],
"context": [
"My name is Wolfgang and I live in Berlin",
"My name is Sarah and I live in London",
"My name is Clara and I live in Berkeley.",
"The Amazon rainforest (Portuguese: Floresta Amaz\u00f4nica or Amaz\u00f4nia; Spanish: Selva Amaz\u00f3nica, Amazon\u00eda or usually Amazonia; French: For\u00eat amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
]
}
}
Vamos a hacer una inferencia con sample_score.json. Cambie la ubicación en función de dónde guardó el archivo json de ejemplo.
scoring_file = "./sample_score.json"
response = workspace_ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="demo",
request_file=scoring_file,
)
response_json = json.loads(response)
print(json.dumps(response_json, indent=2))
Eliminación de un punto de conexión de implementación
Para eliminar implementaciones en Inteligencia artificial de Azure Studio, seleccione el botón Eliminar en el panel superior de la página de detalles de la implementación.
Consideraciones de cuota
Para implementar y realizar inferencias con puntos de conexión en tiempo real, usted consume la cuota de núcleo de máquina virtual (VM) que se asigna a su suscripción en función de la región. Al registrarse en Inteligencia artificial de Azure Studio, recibirá una cuota de máquina virtual predeterminada para varias familias de máquinas virtuales disponibles en la región. Puede seguir creando implementaciones hasta alcanzar el límite de cuota. Una vez que esto suceda, puede solicitar un aumento de la cuota.
Pasos siguientes
- Más información sobre lo que puede hacer en Inteligencia artificial de Azure Studio
- Obtenga respuestas a las preguntas más frecuentes en el artículo preguntas más frecuentes sobre Azure AI.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de