En este artículo se proporcionan instrucciones técnicas para implementar una solución de análisis de riesgos de cumplimiento mediante Azure Cognitive Search. Las directrices se basan en las experiencias de proyectos reales. Dado el ámbito exhaustivo de la solución y la necesidad de adaptarla a su caso de uso específico, el artículo se centra en los aspectos esenciales y específicos de la arquitectura y la implementación. Además, hace referencia a tutoriales detallados cuando es necesario.
Apache®, Apache Lucene® y el logotipo de la llama son marcas registradas o marcas comerciales de Apache Software Foundation en Estados Unidos y otros países. El uso de estas marcas no implica la aprobación de Apache Software Foundation.
Introducción
Cada día, los consultores y los comerciantes de las instituciones financieras debaten, analizan y cierran transacciones por un valor de millones de dólares. Las transacciones fraudulentas, la connivencia, el uso de información privilegiada y otras malas prácticas por parte de los empleados son grandes riesgos para estas instituciones, tanto en términos de consecuencias legales como de imagen pública.
Los equipos de cumplimiento trabajan para mitigar estos riesgos. Parte de su trabajo consiste en supervisar las comunicaciones en varios canales, incluida la mensajería instantánea, el correo electrónico y las llamadas telefónicas profesionales. A menudo, se realiza una comprobación cruzada comparando los resultados de esta supervisión con datos de transacciones empresariales. El objetivo es detectar signos de incumplimiento, que por lo general están ocultos y son sutiles. Esta tarea requiere mucho esfuerzo y atención, e implica examinar grandes cantidades de datos. Aunque los sistemas automatizados pueden resultar de ayuda, el volumen de riesgos que se pasan por alto puede ser bastante alto, lo que conlleva la necesidad de revisar las comunicaciones originales.
Azure Cognitive Search puede ayudarle a automatizar y mejorar la calidad de la evaluación de riesgos. Incluye funcionalidades de inteligencia artificial integradas, inteligencia artificial extensible y búsqueda inteligente. La solución de análisis de riesgos de cumplimiento que se presenta en este artículo muestra cómo identificar riesgos (por ejemplo, una conducta incorrecta de los operadores financieros) mediante la consolidación y el análisis de contenido procedente de varios canales de comunicación. Entre los posibles riesgos que se pueden identificar en este contenido no estructurado se incluyen señales de manipulación del mercado, uso de información privilegiada y fraudes con fondos mutualistas, entre otros.
La arquitectura de la solución usa Azure Cognitive Services y Azure Cognitive Search. El escenario se centra en los riesgos de comunicación en el sector financiero, pero el modelo de diseño se puede aplicar a otras industrias y sectores, como el gobierno y la atención sanitaria. Las organizaciones pueden adaptar la arquitectura mediante el desarrollo y la integración de modelos de evaluación de riesgos que se aplican a sus escenarios empresariales. Por ejemplo, la aplicación de demostración de Wolters Kluwer permite a los abogados encontrar rápidamente información pertinente en declaraciones y correspondencia enviadas a la Comisión de Bolsa y Valores (SEC). Identifica los riesgos relacionados con las finanzas, incluidos los riesgos de ciberseguridad y propiedad intelectual.
Azure Cognitive Search incluye funcionalidades de inteligencia artificial integradas y capacidades personalizadas que mejoran el rendimiento de los procesos empresariales, así como la productividad de los equipos de cumplimiento. Resulta especialmente útil en las situaciones siguientes:
- Es necesario extraer información de un gran número de documentos heterogéneos no estructurados, como informes financieros, transcripciones de voz y correos electrónicos.
- No se han implementado por completo procedimientos de administración de riesgos para contenido no estructurado.
- Los enfoques existentes requieren mucho tiempo y esfuerzo, y generan demasiadas falsas alarmas o pasan por alto riesgos reales.
- Es necesario integrar diversos canales de comunicación y orígenes de datos, incluidos datos estructurados, para realizar un análisis de riesgos más completo.
- Hay disponibles datos y conocimientos sobre el dominio con los que se pueden entrenar modelos de aprendizaje automático para identificar señales de riesgo en texto no estructurado. Como alternativa, se pueden integrar modelos existentes.
- Es necesario que la arquitectura pueda ingerir y procesar continuamente los nuevos datos no estructurados disponibles, como conversaciones y noticias, para mejorar la solución.
- Los analistas de cumplimiento necesitan una herramienta eficaz para identificar y analizar de forma detallada de los riesgos. La herramienta debe permitir la intervención humana para que los analistas controlen el proceso y puedan marcar posibles predicciones incorrectas para mejorar los modelos.
Azure Cognitive Search es un servicio de búsqueda en la nube con funcionalidades de inteligencia artificial integradas que enriquecen todos los tipos de información para ayudar a identificar y explorar el contenido pertinente a gran escala. Permite usar aptitudes cognitivas para la visión y el idioma, o bien emplear modelos de Machine Learning personalizados para descubrir información de todos los tipos de contenido. Azure Cognitive Search también ofrece funcionalidad de búsqueda semántica que usan técnicas avanzadas de aprendizaje automático para clasificar la intención del usuario y ordenar contextualmente los resultados de la búsqueda más relevantes.
En el diagrama siguiente se muestra una vista general de cómo funciona Azure Cognitive Search, desde la ingesta de datos y la indexación hasta la entrega de los resultados al usuario.

Descargue un archivo de PowerPoint de esta arquitectura.
En este artículo se proporcionan detalles sobre la solución para el caso de uso de análisis de riesgos y otros escenarios de servicios financieros, como el ejemplo de Wolters Kluwer que se mencionó anteriormente. Contiene los pasos para la ejecución técnica, con menciones a la documentación de los procedimientos y una arquitectura de referencia. Además, incluye procedimientos recomendados desde la perspectiva organizativa y técnica. El modelo de diseño da por supuesto que usted traerá sus datos y desarrollará sus propios modelos de análisis de riesgos, adecuados para los requisitos y el contexto empresarial.
Sugerencia
Consulte estos recursos para obtener una introducción a Azure Cognitive Search y experimentarlo en acción:
Información general de la solución
El siguiente diagrama ofrece una visión general de la solución de análisis de riesgos.

Descargue un archivo de PowerPoint de esta arquitectura.
Para identificar las comunicaciones que plantean verdadero riesgo, el contenido procedente de canales de comunicación heterogéneos se extrae y enriquece mediante varios modelos de Machine Learning de Cognitive Services. A continuación, se aplican modelos personalizados específicos del dominio para identificar signos de manipulación del mercado y otros riesgos que pueden aparecer en las comunicaciones e interacciones entre personas. Todos los datos se agregan a una solución de Azure Cognitive Search consolidada. La solución consta de una aplicación fácil de usar con funcionalidades de identificación y análisis de riesgos. Los datos de la aplicación se almacenan en un índice de búsqueda, y en un almacén de conocimiento si necesita almacenamiento a largo plazo.
En la ilustración siguiente se muestra información general conceptual de la arquitectura de la solución:

Descargue un archivo de PowerPoint de esta arquitectura.
Aunque cada canal de comunicación (por ejemplo, correo electrónico, chats y telefonía) se puede usar de forma aislada para detectar posibles riesgos, se consigue una información mejor si se combinan los canales y se aumentan el contenido con información complementaria, como noticias del mercado.
La solución de análisis de riesgos usa varias interfaces para integrar sistemas de comunicaciones empresariales para la ingesta de datos:
- Blob Storage se usa como origen general de datos en formato de documento, como contenido de correo electrónico, incluidos datos adjuntos, transcripciones de llamadas telefónicas o chats, y documentos de noticias.
- Los servicios de comunicación de Office 365, como Microsoft Exchange Online y Microsoft Teams, pueden integrarse mediante Microsoft Graph Data Connect para la ingesta masiva de correo electrónico, chats y otro contenido. También hay disponible una interfaz de Azure Cognitive Search para SharePoint en Microsoft 365.
- Las comunicaciones de voz, como las llamadas telefónicas, se transcriben mediante el servicio Speech to Text de Cognitive Services. Las transcripciones y metadatos resultantes se ingieren mediante Azure Cognitive Search a través de Blob Storage.
En estos ejemplos se tratan los canales de comunicación empresariales que se usan con frecuencia. Aun así, también es posible la integración de canales adicionales y se pueden usar patrones de ingesta similares.
Después de la consolidación, las funcionalidades de inteligencia artificial enriquecen los datos sin procesar para detectar la estructura y crear contenido basado en texto a partir de tipos de contenido en los que antes no se podía buscar. Por ejemplo:
- Los informes financieros en archivos PDF o de PowerPoint suelen contener imágenes insertadas en lugar de texto que pueda leer una máquina, con el fin de impedir los cambios. Para procesar este tipo de contenido, todas las imágenes se analizan mediante el reconocimiento óptico de caracteres (OCR) gracias a la aptitud cognitiva de OCR.
- El contenido en varios idiomas se traduce al inglés u otro idioma mediante la aptitud cognitiva de traducción de texto.
- La información importante, como los nombres de personas y organizaciones, se extrae automáticamente y se puede usar para consultas de búsqueda eficaces mediante la aptitud cognitiva de reconocimiento de entidades. Por ejemplo, una búsqueda puede encontrar todas las comunicaciones entre James Doe y Mary Silva en las que hablan sobre una empresa determinada durante un período de tiempo específico.
- Se usan modelos personalizados para identificar en las comunicaciones pruebas de que existe riesgo, como uso de información privilegiada. Estos modelos específicos del dominio se pueden basar en palabras clave, expresiones o párrafos completos. Para ello, emplean tecnologías avanzadas de procesamiento del lenguaje natural (NLP). Los modelos personalizados se entrenan mediante datos específicos del dominio para el caso de uso actual.
Después de aplicar funcionalidades personalizadas y el enriquecimiento con IA de Azure Cognitive Search, el contenido se consolida en un índice de búsqueda para admitir escenarios enriquecidos de búsqueda y minería de conocimientos. Los analistas de cumplimiento y otros usuarios usan la aplicación de front-end para identificar las posibles comunicaciones de riesgo y realizar búsquedas en profundidad para llevar a cabo análisis adicionales. La administración de riesgos es un proceso dinámico. Los modelos se mejoran constantemente en producción y se agregan modelos para los nuevos tipos de riesgo. Por esta razón, la solución debe ser modular. Los nuevos tipos de riesgo se marcan automáticamente en la interfaz de usuario a medida que se amplía el conjunto de modelos.
La aplicación de front-end usa consultas de búsqueda semántica e inteligente para examinar el contenido. El contenido también se puede mover a un almacén de conocimiento para la retención de cumplimiento o la integración con otros sistemas.
Los bloques de creación de la solución se describen con más detalle en las secciones siguientes.
La implementación de una solución de análisis de riesgos es un ejercicio multidisciplinario que requiere la participación de partes interesadas clave de varios dominios. Según nuestra experiencia, es recomendable incluir los roles siguientes para garantizar un desarrollo correcto y la adopción de la solución en la organización.

Sugerencia
- Consulte la documentación para obtener más información sobre Azure AI Search.
Ingesta de datos
En esta sección se explica cómo consolidar contenido heterogéneo en un único origen de datos y, después, configurar una colección inicial de recursos de búsqueda derivados de ese origen.
El desarrollo e implementación de una solución de Azure Cognitive Search suele ser un proceso incremental. La adición de orígenes de datos, transformaciones y aumentos se realiza en iteraciones sucesivas, sobre configuraciones básicas de referencia.
El primer paso de una solución de Azure Cognitive Search consiste en crear una instancia de servicio en Azure Portal. Además del servicio de búsqueda en sí mismo, necesita varios recursos de búsqueda, como un índice de búsqueda, un indexador, un origen de datos y un conjunto de aptitudes. Puede crear una configuración básica de referencia con poco esfuerzo mediante el Asistente para importar datos de Azure Cognitive Search, que se encuentra en Azure Portal. Este asistente, que se muestra aquí, guía al usuario por los pasos básicos para crear y cargar un índice de búsqueda simple que usa datos de un origen de datos externo.

La creación del índice de búsqueda mediante el Asistente para importar datos consta de cuatro pasos:
- Conexión a los datos: la conexión a la instancia existente de Blob Storage, por ejemplo, se puede realizar sin esfuerzo con unos pocos clics. Se usa una cadena de conexión para la autenticación. Otros orígenes de datos admitidos de forma nativa incluyen diversos servicios de Azure, como Azure SQL Database, Azure Cosmos DB y servicios como SharePoint Online. En esta solución, se usa Blob Storage para consolidar los tipos de contenido heterogéneos.
- Adición de aptitudes cognitivas: en este paso opcional, se agregan funcionalidades de inteligencia artificial integrada al proceso de indexación. Se aplican para enriquecer el contenido que se lee del origen de datos. Por ejemplo, este paso puede extraer los nombres y las ubicaciones de personas y organizaciones.
- Personalización del índice de destino: en este paso, el desarrollador configura las entidades de campo para el índice. Se proporciona un índice predeterminado, pero es posible agregar campos, eliminarlos o cambiarles el nombre. Estos son algunos campos de ejemplo: título del documento, descripción, dirección URL, autor, ubicación, empresa y código de cotización, así como los tipos de operaciones que son posibles en cada uno de ellos.
- Creación del indexador: en el último paso se configura un indexador, es decir, el componente que se ejecuta periódicamente para actualizar el contenido del índice de búsqueda. Un parámetro clave es la frecuencia con la que se debe ejecutar el indexador.
Cuando se confirman los valores de configuración, se crean un origen de datos, un conjunto de aptitudes, un indexador y un índice. Para cada uno de estos componentes, se crea una definición de JSON. Las definiciones de JSON proporcionan una personalización mejorada y se pueden usar para crear los servicios mediante programación a través de una API REST. La ventaja es la creación coherente de recursos mediante programación en todas las iteraciones de desarrollo posteriores. Por este motivo, usamos definiciones de JSON para mostrar la configuración de todos los recursos. La sección Creación automática de recursos de búsqueda proporciona explicaciones detalladas sobre cómo usar estas definiciones para crear todos los recursos mediante programación.
En la configuración, Blob Storage se selecciona como origen de datos predeterminado. Aunque las comunicaciones pueden originarse en varios canales o orígenes, un enfoque genérico para este modelo de solución se basa en todas las comunicaciones existentes en Blob Storage que contienen texto o imágenes. En el paso siguiente se explicará con más detalle la configuración de una definición de JSON de origen de datos para Blob Storage.
En esta sección se hace referencia a algunos modelos para ejemplificar cómo se ingieren las comunicaciones de Office 365 en Blob Storage y cómo se transcriben llamadas de audio mediante el servicio Speech to Text.
Sugerencia
Cómo implementar:
Blob Storage
En la siguiente definición de JSON puede verse la estructura y la información que son necesarias para configurar Blob Storage como origen de datos para Azure Cognitive Search:
{
"name": "email-ds",
"description": "Datasource for emails.",
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=..."
},
"container": {
"name": "communications",
"query": "written_comms/emails"
}
}
Se requieren los campos siguientes:
- Nombre: nombre asignado al origen de datos.
- Tipo: define el origen de datos como Blob Storage.
- Credenciales: cadena de conexión para Blob Storage.
- Contenedor: nombre del contenedor donde se almacenan los blobs. Es posible especificar un directorio en el contenedor para que se puedan crear varios orígenes de datos dentro del mismo contenedor.
De forma predeterminada, el origen de datos de Blob Storage admite una amplia gama de formatos de documento. Por ejemplo, las transcripciones de audio a menudo se almacenan en archivos JSON, los correos electrónicos suelen ser archivos MSG o EML, y las noticias o el material de comunicación adicional en general está en PDF, formatos de Word como DOC/DOCX/DOCM, formatos de PowerPoint como PPT/PPTX/PPTM, o páginas web HTML.
Para configurar varios orígenes de datos para las comunicaciones en la misma instancia de Blob Storage, puede usar una de las técnicas siguientes:
- Asignar a cada origen de datos su propio contenedor.
- Usar el mismo contenedor para todos los orígenes de datos, pero asignando a cada origen de datos su propio directorio en ese contenedor.
Microsoft Graph Data Connect
Para clientes de Office 365, Microsoft Graph Data Connect se puede usar para extraer datos seleccionados de Microsoft Graph en Azure Storage, en un nivel superior de la solución de Azure Cognitive Search. Los datos almacenados en Microsoft Graph incluyen datos como correos electrónicos, reuniones, chats, documentos de SharePoint, personas y tareas.
Nota
El uso de este mecanismo está sujeto a un proceso de consentimiento de datos.

Descargue un archivo de PowerPoint de esta arquitectura.
En el diagrama se muestra el flujo de datos de Microsoft Graph. El proceso se basa en funcionalidades de Azure Data Factory para extraer datos de Microsoft Graph. Hay un control de seguridad pormenorizado, que incluye el consentimiento y un modelo de gobernanza. La canalización de Data Factory se configura con los tipos de datos que se van a extraer, como mensajes de correo electrónico y chats de equipo, y con un ámbito como un grupo de usuarios y un intervalo de fechas. La búsqueda se ejecuta según una programación definida a intervalos configurables y está configurada para colocar los datos extraídos en Azure Storage. Desde ahí, un indexador ingiere los datos en Azure Cognitive Search.
Sugerencia
En los artículos siguientes se incluyen instrucciones detalladas para configurar una extracción de datos de Microsoft Graph Data Connect en Azure Storage a través de Data Factory, para su posterior ingesta en Azure Cognitive Search:
Arquitectura de referencia de conversión de voz en texto
Las conversaciones telefónicas son una herramienta de trabajo esencial en cualquier organización de servicios financieros. Se pueden incluir en una solución de análisis de riesgos si hay acceso a los archivos de audio correspondientes. En esta sección se trata esta situación.
El descifrado de documentos en Azure Cognitive Search es un conjunto de pasos de procesamiento que ejecuta el indexador para extraer texto e imágenes del origen de datos. En el caso de los archivos de audio, necesitamos una manera de extraer transcripciones de estas comunicaciones de audio con el fin de que estén disponibles para el procesamiento basado en texto.
En el diagrama siguiente se muestra una canalización de ingesta de audio y de conversión de voz en texto. La canalización procesa lotes de archivos de audio y almacena los archivos de transcripción en Blob Storage, en un nivel superior de la solución de Azure Cognitive Search.

Descargue un archivo de PowerPoint de esta arquitectura.
En esta arquitectura de referencia, los archivos de audio se cargan en Blob Storage mediante una aplicación cliente. Durante este proceso, la aplicación se autentica con Azure Active Directory y llama a la API REST para obtener un token para Blob Storage. Azure API Management proporciona acceso seguro a la API REST, mientras que Azure Key Vault proporciona almacenamiento seguro de los secretos necesarios para generar los tokens, así como las credenciales de cuenta.
Una vez que se han cargado los archivos, se emite un desencadenador de Azure Event Grid para invocar una función de Azure. Después, la función procesa el archivo de audio mediante la API de conversión de voz en texto de Cognitive Services. A continuación, el documento JSON transcrito se almacena en un contenedor de blobs independiente, que Azure Cognitive Search puede ingerir como origen de datos.
Solución de búsqueda
Como ya se ha indicado, se crean varios orígenes de datos, como correos electrónicos, transcripciones y noticias, que se almacenan en Blob Storage. Después, cada origen de datos se transforma y enriquece a su manera. La salida resultante se asigna al mismo índice y se consolidan los datos de todos los tipos de documentos de origen.
En el diagrama siguiente se muestra este enfoque. Cada uno de los orígenes de datos disponibles tiene configurado un indexador personalizado y todos los resultados alimentan un único índice de búsqueda.

En las secciones siguientes se exploran los motores de indexación y los índices que permiten las búsquedas. Además, se muestra cómo configurar un indexador y cómo indexar definiciones de JSON para implementar una solución que permita las búsquedas.
Indizadores
Un indexador organiza la extracción y el enriquecimiento del contenido del documento. Una definición de indexador incluye detalles sobre el origen de datos que se va a ingerir, cómo se asignan los campos y cómo se transforman y enriquecen los datos.
Dado que la asignación, la transformación y el enriquecimiento varían según el tipo de datos, debe haber un indexador para cada origen de datos. Por ejemplo, la indexación de correos electrónicos puede requerir aptitudes de OCR para procesar imágenes y datos adjuntos, mientras que las transcripciones solo necesitan aptitudes basadas en el lenguaje.
Estos son los pasos del proceso de indexación:
- Descifrado de documentos: Azure Cognitive Search abre y extrae el contenido pertinente de los documentos. El contenido indexable extraído es una función del origen de datos y los formatos de archivo. Por ejemplo, en el caso de un archivo PDF o de Microsoft 365 en Blob Storage, el indexador abre el archivo y extrae texto, imágenes y metadatos.
- Asignación de campos: los nombres de los campos que se extrajeron del origen se asignan a campos de destino de un índice de búsqueda.
- Ejecución del conjunto de aptitudes: el procesamiento de inteligencia artificial integrada o personalizada se realiza en este paso, como se describe en una sección posterior.
- Asignación de campos de salida: los nombres de los campos transformados o enriquecidos se asignan a los campos de destino de un índice.
En el fragmento de código siguiente se muestra un segmento de la definición de JSON del indexador de correo electrónico. Esta definición usa la información que se indica en los pasos y proporciona un conjunto detallado de instrucciones al motor de indexación.
{
"name": "email-indexer",
"description": "",
"dataSourceName": "email-ds",
"skillsetName": "email-skillset",
"targetIndexName": "combined-index",
"disabled": null,
"schedule": {
"interval": "P1D",
"startTime": "2021-10-17T22:00:00Z"
},
"parameters": {
"batchSize": null,
"mixabilities": 50,
"maxFailedItemsPerBatch": 0,
"base64EncodeKeys": null,
"configuration": {
"imageAction": "generateNormalizedImages",
"dataToExtract": "contentAndMetadata",
"parsingMode": "default"
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_path",
"targetFieldName": "metadata_storage_path",
"mappingFunction": {
"name": "base64Encode",
"parameters": null
}
}
],
"outputFieldMappings": [
{
"sourceFieldName": "/document/merged_content/people",
"targetFieldName": "people"
},
{
"sourceFieldName": "/document/merged_content/organizations",
"targetFieldName": "organizations"
},
En este ejemplo, el indexador se identifica mediante el nombre único email-indexer. Este indexador hace referencia a un origen de datos denominado email-ds, y el enriquecimiento con IA se define mediante el conjunto de aptitudes denominado email-skillset. Las salidas del proceso de indexación se almacenan en el índice denominado combined-index. Los detalles adicionales incluyen una programación establecida en "Diariamente", un número máximo de 50 elementos con errores y una configuración para generar imágenes normalizadas y extraer contenido y metadatos.
En la sección de asignación de campos, el campo metadata_storage_path está codificado mediante base64encode, para actuar como clave de documento única. En la configuración de asignación de los campos de salida (que solo se muestra parcialmente), las salidas del proceso de enriquecimiento están asignadas al esquema de índice.
Si se crea un indexador para un nuevo origen de datos (por ejemplo, transcripciones), la mayor parte de la definición de JSON se configura para alinearse con el origen de datos y la selección del conjunto de aptitudes. Aun así, el índice de destino debe ser combined-index (siempre que todas las asignaciones de campos sean compatibles). Esta es la técnica que permite al índice consolidar los resultados de varios orígenes de datos.
Índices y otras estructuras
Una vez que se ha llevado a cabo el proceso de indexación, los documentos extraídos y aumentados se conservan en un índice en el que se pueden realizar búsquedas y, opcionalmente, en almacenes de conocimiento.
Índice en el que se pueden realizar búsquedas: se corresponde con la salida necesaria que se crea siempre como parte de un proceso de indexación. En ocasiones, también se denomina catálogo de búsqueda. Para crear un índice, se requiere una definición de índice. Contiene valores de configuración (como "type", "searchable", "filterable", "sortable", "facetable" y "retrievable") para todos los campos. Estos nombres de campo de índice deben alinearse con las asignaciones del campo del indexador y del campo de salida.
Se pueden asignar varios indexadores al mismo índice, de modo que el índice consolide las comunicaciones procedentes de diferentes conjuntos de datos, como correos electrónicos o transcripciones. Después, se puede consultar un índice mediante la búsqueda de texto completo o la búsqueda semántica.
Igual que los indexadores, los índices se pueden configurar mediante una definición de JSON de índice. El fragmento de código siguiente corresponde a un segmento de la definición de JSON de combined-index:
{ "name": "combined-index", "fields": [ { "name": "metadata_storage_path", "type": "Edm.String", "facetable": false, "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false, "analyzer": null, "indexAnalyzer": null, "searchAnalyzer": null, "synonymMaps": [], "fields": [] }, { "name": "people", "type": "Collection(Edm.String)", "facetable": true, "filterable": true, "retrievable": true, "searchable": true, "analyzer": "standard.lucene", "indexAnalyzer": null, "searchAnalyzer": null, "synonymMaps": [], "fields": [] },En este ejemplo, el índice se identifica mediante el nombre único combined-index. La definición de índice es independiente de los indexadores, orígenes de datos o conjuntos de aptitudes. Los campos definen el esquema del índice. En el momento de la configuración, un usuario puede configurar el nombre y el tipo de cada campo, así como un conjunto de propiedades, como facetable y filterable.
En este fragmento de código se incluyen dos campos. Metadata_storage_path es una cadena recuperable que se usa como clave de documento. Por otro lado, el campo people es una colección de cadenas clasificables, filtrables y recuperables y que permiten búsquedas. La consulta de texto completo se procesa mediante un analizador standard.lucene.
Almacén de conocimiento: puede ser una salida opcional, que se usará para el análisis independiente y el procesamiento descendente en escenarios que no son de búsqueda, como la minería de conocimientos. La implementación de un almacén de conocimiento se define dentro de un conjunto de aptitudes, donde el documento enriquecido o los campos específicos se pueden configurar para proyectarse como tablas o archivos.
En la ilustración siguiente se muestra una implementación de un almacén de conocimiento:


Descargue un archivo de PowerPoint de esta arquitectura.
Con un almacén de conocimiento de Azure Cognitive Search, los datos se pueden conservar con las opciones siguientes (denominadas proyecciones):
- Las proyecciones de archivos permiten la extracción de contenido (por ejemplo, imágenes insertadas) como archivos. Un ejemplo son los diagramas o gráficos de informes financieros que se exportan en formatos de archivo de imagen.
- Las proyecciones de tablas admiten estructuras de informes tabulares (por ejemplo, para casos de uso de análisis). Se pueden usar para almacenar información agregada, como puntuaciones de riesgo para cada documento.
- Las proyecciones de objetos extraen contenido como objetos JSON en Blob Storage. Se pueden usar para la solución de análisis de riesgos si es necesario conservar los datos con detalles pormenorizados por motivos de cumplimiento. Las puntuaciones de riesgo se pueden archivar con este enfoque.
Dado que la estructura de los datos de búsqueda está optimizada para las consultas, en general no está optimizada para otros fines, como la exportación a un almacén de conocimiento. Puede usar la aptitud de conformador para reestructurar los datos con el fin de cumplir los requisitos de retención antes de aplicar las proyecciones.
En un almacén de conocimiento, el contenido conservado se almacena en Azure Storage, ya sea en Table Storage o Blob Storage.
Hay varias opciones para usar datos de un almacén de conocimiento. Azure Machine Learning puede acceder al contenido para crear modelos de Machine Learning. Power BI puede analizar los datos y crear objetos visuales.
Las organizaciones financieras cuentan con directivas y sistemas para la retención de cumplimiento a largo plazo. Por lo tanto, es posible que Azure Storage no sea la solución de destino ideal para este caso de uso. Una vez que los datos se han guardado en el almacén de conocimiento, Data Factory puede exportarlos a otros sistemas, como bases de datos.
Motor de consultas
Una vez que se ha creado un índice, puede usar Azure Cognitive Search para consultarlo mediante búsquedas semánticas y de texto completo.
- La búsqueda de texto completo se basa en el motor de consultas de Apache Lucene y acepta términos o frases que se pasan en un parámetro de búsqueda en todos los campos del índice en los que se puede buscar. Cuando se encuentran términos coincidentes, el motor de consultas clasifica los documentos por orden de relevancia y devuelve los resultados principales. La clasificación de los documentos se puede personalizar mediante perfiles de puntuación y los resultados se pueden ordenar mediante campos de índice ordenables.
- La búsqueda semántica proporciona un conjunto de características eficaces que mejoran la calidad de los resultados de la búsqueda mediante la relevancia semántica y el reconocimiento del lenguaje. Cuando se habilita, la búsqueda semántica amplía la funcionalidad de búsqueda de las maneras siguientes:
- La reclasificación semántica usa el contexto o el significado semántico de una consulta para calcular una nueva puntuación de relevancia en los resultados existentes.
- Los resaltados semánticos extraen las oraciones y frases de un documento que resumen mejor el contenido.
La sección Interfaz de usuario incluye un ejemplo de la eficacia de la búsqueda semántica. La búsqueda semántica está disponible en la versión preliminar pública. Encontrará más información sobre sus funcionalidades en la documentación.
Creación automática de recursos de búsqueda
El proceso de desarrollar una solución de búsqueda es iterativo. Después de implementar la infraestructura de Azure Cognitive Search y la versión inicial de los recursos de búsqueda, como el origen de datos, el índice, el indexador y el conjunto de aptitudes, puede realizar una mejora continua de la solución (por ejemplo, mediante la adición y la configuración de aptitudes de inteligencia artificial).
Para garantizar la coherencia y las iteraciones rápidas, se recomienda automatizar el proceso de creación de los recursos de Azure Cognitive Search.
Para nuestra solución, usamos la API REST de Azure Cognitive Search para implementar diez recursos de forma automatizada, como se muestra en esta ilustración:

Dado que nuestra solución requiere un procesamiento y enriquecimiento con IA diferentes para los correos electrónicos, las transcripciones y los documentos de noticias, hemos creado orígenes de datos, indexadores y conjuntos de aptitudes distintos. Aun así, hemos decidido usar un único índice para todos los canales con el fin de simplificar el uso de la solución de análisis de riesgos.
Cada uno de los diez elementos tiene asociado un archivo de definición de JSON para especificar su configuración. Consulte los cuadros de código de ejemplo incluidos en esta guía para obtener una explicación de la configuración.
Las especificaciones de JSON se envían a Azure Cognitive Search a través de solicitudes de API realizadas por el script build-search-config.py en el orden que se muestra. En el ejemplo siguiente se indica cómo se crea el conjunto de aptitudes de correo electrónico especificado en email-skillset.json:
url = f"https://{search_service}.search.windows.net/skillsets?api-version=2020-06-30-Preview"
headers = {'Content-type': 'application/json', 'api-key': cog_search_admin_key}
r = requests.post(url, data=open('email-skillset.json', 'rb'), headers=headers)
print(r)
- search_service es el nombre del recurso de Azure Cognitive Search.
- cog_search_admin_key es la clave de administrador. El uso de una clave de consulta no es suficiente para las operaciones de administración.
Una vez que se han realizado todas las solicitudes de configuración y que se ha cargado el índice, una consulta REST determina si la solución de búsqueda responde correctamente. Tenga en cuenta que se produce un retraso antes de que se generen todos los recursos y los indexadores hayan completado sus ejecuciones iniciales. Es posible que tenga que esperar unos minutos antes de realizar una consulta por primera vez.
Para obtener información sobre cómo usar la API REST de Azure Cognitive Search con el fin de crear mediante programación la configuración para indexar el contenido de Blob Storage, consulte Tutorial: Uso de REST e IA para generar contenido en el que se pueden realizar búsquedas desde blobs de Azure.
Sugerencia
Enriquecimientos de inteligencia artificial
En las secciones anteriores, creamos la base de la solución de análisis de riesgos. Ahora es el momento de centrarse en el procesamiento de la información, para convertirla de contenido sin procesar en información empresarial tangible.
Para que se puedan realizar búsquedas en el contenido, el contenido de las comunicaciones se pasa por una canalización de enriquecimiento con IA que usa aptitudes integradas y modelos personalizados para la detección de riesgos:

En primer lugar, veremos cómo usar aptitudes integradas basadas en las aptitudes de ejemplo de la 1 a la 4 que usamos para la solución de análisis de riesgos. Después, aprenderemos a agregar una aptitud personalizada para integrar modelos de riesgo (paso 5). Por último, obtendremos información sobre cómo revisar y depurar la canalización de aptitudes.
En las secciones siguientes se proporciona una introducción a los conceptos. Si prefiere una experiencia práctica, consulte la guía detallada de Microsoft Learn.
Aptitudes integradas de enriquecimiento con IA
La canalización de enriquecimiento con IA aplicado recibe el nombre de conjunto de aptitudes Azure Cognitive Search. Las siguientes aptitudes integradas se usan en la solución de análisis de riesgos:
Reconocimiento óptico de caracteres: los informes financieros pueden incluir una cantidad considerable de contenido insertado en imágenes, en lugar de en texto, para impedir cambios en el contenido. En la presentación siguiente se muestra un ejemplo de un informe trimestral de Microsoft:
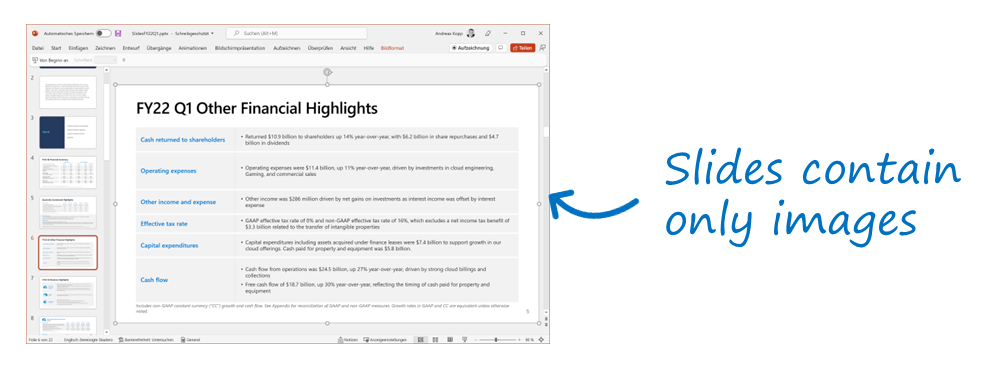
Todas las diapositivas de la presentación incluyen exclusivamente contenido gráfico. Para usar la información, se emplea la aptitud cognitiva de OCR para los correos electrónicos (es especialmente relevante para los datos adjuntos) y los documentos de noticias del mercado. Esto garantiza que las consultas de búsqueda, como "capital expenditures" (gastos de capital) en el ejemplo anterior, encuentren el texto de la diapositiva aunque el contenido original no lo pueda leer una máquina. La relevancia de la búsqueda mejora todavía más gracias a la búsqueda semántica en los casos en los que los usuarios emplean términos diferentes de "capital expenditures" (gastos de capital) que no están contenidos en el texto.
Detección del idioma: en una organización global, la compatibilidad con la traducción automática es un requisito habitual. Por ejemplo, si el equipo de analistas de cumplimiento prefiere leer y comunicarse de forma coherente en inglés, la solución debe poder traducir el contenido con precisión. La aptitud cognitiva de detección del idioma se usa para identificar el idioma del documento original. Esta información se usa para identificar si se requiere una traducción al idioma de destino deseado y también se muestra en la interfaz de usuario para indicar el idioma original al usuario.
Extracción de personas y organizaciones: la aptitud cognitiva de reconocimiento de entidades puede identificar personas, ubicaciones, organizaciones y otras entidades en texto no estructurado. Esta información se puede usar para mejorar la búsqueda o la navegación (por ejemplo, el filtrado y la clasificación) en un volumen grande de contenido heterogéneo. Para la solución de análisis de riesgos, se ha elegido la extracción de personas (por ejemplo, nombres de comerciantes) y organizaciones (por ejemplo, nombres de empresas).
En el ejemplo siguiente tomado de la definición de JSON del conjunto de aptitudes para correos electrónicos se proporcionan detalles sobre la configuración seleccionada:
"skills": [ { "@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill", "name": "Detect Entities", "description": "Detect people and organizations in emails", "context": "/document/merged_content", "categories": [ "Person", "Organization" ], "defaultLanguageCode": "en", "minimumPrecision": 0.85, "modelVersion": null, "inputs": [ { "name": "text", "source": "/document/merged_content" }, { "name": "languageCode", "source": "/document/original_language" } ], "outputs": [ { "name": "persons", "targetName": "people" }, { "name": "organizations", "targetName": "organizations" } ] },En primer lugar, especificamos la extracción de personas y organizaciones del contenido. Existen otras categorías (por ejemplo, ubicaciones) que se pueden extraer si es necesario. Aun así, hemos restringido la extracción intencionadamente a estas dos entidades para no sobrecargar a los usuarios con demasiada información al principio.
Dado que ninguna solución de inteligencia artificial proporciona una precisión del 100 %, siempre hay un riesgo de falsos positivos (por ejemplo, nombres de organización que no son realmente organizaciones) y falsos negativos (por ejemplo, organizaciones reales que se pasan por alto). Azure Cognitive Search proporciona controles para equilibrar la relación entre señal y ruido en la extracción de entidades. En nuestro caso, establecemos la precisión mínima para la detección en 0,85 para mejorar la relevancia del reconocimiento y reducir el ruido.
En el paso siguiente, se especifican las entradas y salidas del conjunto de aptitudes dentro del documento enriquecido. Nuestra ruta de acceso de entrada apunta a merged_content, que incluye el correo electrónico y los datos adjuntos. El contenido de los datos adjuntos incluye texto extraído mediante OCR.
Por último, definimos los nombres de salida people y organizations para las entidades especificadas. Más adelante, se asignan al índice de búsqueda como parte de la definición del indexador.
Las definiciones de las demás aptitudes siguen un patrón similar, complementado con valores de configuración específicos de la aptitud.
Traducción: la traducción real al inglés de los documentos que contienen idiomas extranjeros se realiza en el paso siguiente. Para la conversión se usa la aptitud cognitiva de traducción de texto. Tenga en cuenta que los cargos de traducción se evalúan cada vez que se envía texto a Translator Text API, incluso si el idioma de origen y el de destino es el mismo. Para evitar cargos del servicio en estas circunstancias, se usan aptitudes cognitivas condicionales adicionales para omitir la traducción en estos casos.

Sugerencia
Puede usar el Asistente para la importación de datos de Azure Cognitive Search para empezar a ingerir y enriquecer contenido rápidamente. En el futuro, se beneficiará de la creación de conjuntos de aptitudes y otros recursos de Azure Cognitive Search de forma automatizada. En este artículo se proporciona más información:
Enriquecimiento con IA personalizado para la detección de riesgos
Ahora que ha implementado las aptitudes integradas deseadas desde Azure Cognitive Search, veamos cómo agregar modelos personalizados para el análisis de riesgos.
La identificación de malas conductas intencionadas o reales en el contenido de las comunicaciones siempre depende del contexto y requiere un amplio conocimiento del dominio. Un objetivo clave de la solución de análisis de riesgos es proporcionar una manera de integrar y aplicar con flexibilidad modelos de riesgo personalizados en la canalización de enriquecimiento, con el fin de detectar riesgos reales para escenarios empresariales específicos.
En función del caso de uso, el siguiente ejemplo de conversación podría indicar una posible mala conducta intencionada:

Las opciones siguientes pueden analizar contenido no estructurado de comunicaciones para identificar riesgos:
- Enfoque basado en palabras clave: esta técnica usa una lista de palabras clave relevantes para identificar posibles riesgos, como offline (en este caso, "en persona") y special insights ("información especial"). Este enfoque es fácil de implementar, pero puede pasar por alto riesgos si las formulaciones del contenido no coinciden con las palabras clave.
- Enfoques basados en el reconocimiento de entidades: un modelo de Machine Learning se entrena con expresiones cortas (por ejemplo, oraciones) para identificar los riesgos mediante un modelo de lenguaje. Se usa conocimiento experto para crear un conjunto de formación integrado por ejemplos representativos con la clasificación de riesgos correspondiente (por ejemplo, manipulación del mercado o uso de información privilegiada). Una ventaja clave de esta técnica es que es probable que se identifiquen los riesgos si las expresiones tienen un significado semántico similar, pero formulaciones diferentes de los ejemplos del conjunto de formación. El servicio de reconocimiento del lenguaje conversacional de Azure puede usarse con este fin.
- Enfoques avanzados basados en el procesamiento del lenguaje natural (NLP): los avances recientes en las redes neuronales permiten analizar segmentos más largos de texto no estructurado, lo que incluye la clasificación y otras tareas de NLP. Este enfoque puede identificar señales más sutiles y que abarcan varias oraciones o párrafos. La desventaja es que normalmente se necesitan mucho más datos de entrenamiento que con otras técnicas. Azure proporciona varias opciones para entrenar modelos de NLP, incluida la clasificación de texto personalizado y el aprendizaje automático automatizado.
Cualquier modelo que se proporcione como un servicio web REST se puede integrar como una aptitud personalizada en la solución de análisis de riesgos de Azure Cognitive Search. En nuestro ejemplo, integramos un conjunto de modelos de reconocimiento del lenguaje conversacional con una función de Azure que actúa como interfaz entre Azure Cognitive Search y los modelos. En el diagrama siguiente se muestra esta técnica:

Descargue un archivo de PowerPoint de esta arquitectura.
Los correos electrónicos y las transcripciones se examinan en busca de riesgos después del procesamiento de las aptitudes integradas. La aptitud personalizada proporciona el tipo de documento y su contenido a la aplicación Azure Functions para el preprocesamiento. La aplicación se basa en el ejemplo publicado y lleva a cabo las tareas siguientes:
- Determina qué modelos se usarán: las organizaciones pueden emplear modelos distintos para identificar varios tipos de riesgos (por ejemplo, la manipulación del mercado, el uso de información privilegiada o los fraudes con fondos mutualistas). La aplicación Functions activa los modelos disponibles en función de las preferencias configuradas.
- Preprocesa el contenido: esta tarea incluye colocar el contenido de los datos adjuntos y dividir el texto en oraciones para que coincida con la estructura de los datos que se usan para entrenar los modelos de riesgo.
- Envía el contenido tokenizado a los modelos de riesgo configurados: los modelos de riesgo asignan puntuaciones de riesgo a cada oración.
- Agrega y puntúa los resultados: esta tarea se realiza antes de devolverlos al conjunto de aptitudes. La puntuación de riesgo del documento es el riesgo más alto de todas sus oraciones. La oración con el riesgo más elevado identificado también se devuelve para su visualización en la interfaz de usuario. Además, los riesgos del documento se clasifican como bajo, medio o alto, en función de la puntuación.
- Escribe información en el índice de Azure Cognitive Search: la información se usa en la interfaz de usuario del analista de cumplimiento y en el almacén de conocimiento. Incluye el contenido de todas las comunicaciones, el enriquecimiento integrado y los resultados de los modelos de riesgo personalizados.
En el ejemplo de JSON siguiente se muestra la definición de la interfaz entre Azure Cognitive Search y la aplicación Functions (que llama a los modelos de riesgo) como una aptitud personalizada:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "apply-risk-models",
"description": "Obtain risk model results",
"context": "/document/content",
"uri": "https://risk-models.azurewebsites.net/api/luis-risks?...",
"httpMethod": "POST",
"timeout": "PT3M",
"batchSize": 100,
"degreeOfParallelism": null,
"inputs": [
{
"name": "text",
"source": "/document/mergedenglishtext"
},
{
"name": "doc_type",
"source": "/document/type"
}
],
"outputs": [
{
"name": "risk_average",
"targetName": "risk_average"
},
{
"name": "risk_models",
"targetName": "risk_models"
}
],
},
El URI especifica la dirección web de la aplicación Functions que obtiene las entradas siguientes de Azure Cognitive Search:
- text incluye el contenido en inglés.
- doc_type se usa para distinguir entre transcripciones, correos electrónicos y noticias del mercado, que requieren diferentes pasos de preprocesamiento.
Una vez que la aplicación Functions recibe las puntuaciones de riesgo de la característica de reconocimiento del lenguaje conversacional de Azure Cognitive Service para lenguaje, devuelve los resultados consolidados a Azure Cognitive Search.
Las organizaciones de servicios financieros necesitan un enfoque modular para combinar de forma flexible los modelos de riesgo existentes y nuevos. Por lo tanto, no se realiza ninguna codificación rígida de modelos específicos. En su lugar, risk_models es un tipo de datos complejo que devuelve detalles de cada tipo de riesgo (por ejemplo, uso de información privilegiada), incluida la puntuación de riesgo y la oración identificada con la puntuación de riesgo más alta. El cumplimiento y la rastreabilidad son cuestiones clave para las organizaciones de servicios financieros. Pero los modelos de riesgo se mejoran constantemente (por ejemplo, mediante el uso de nuevos datos de entrenamiento), por lo que las predicciones de un documento pueden cambiar con el paso del tiempo. Para garantizar la rastreabilidad, con cada predicción también se devuelve la versión específica del modelo de riesgo.
La arquitectura se puede reutilizar para integrar modelos de NLP más avanzados (por ejemplo, para habilitar la identificación de señales de riesgo más sutiles que podrían abarcar varias expresiones). El principal ajuste que debe llevarse a cabo consiste en hacer coincidir el paso de preprocesamiento de la aplicación Functions con el preprocesamiento que se realizó para entrenar el modelo de NLP.
Sugerencia
Cómo implementar:
- Este ejemplo de la documentación se usó como punto de partida para crear la solución de análisis de riesgos que se describe en esta guía.
- Use esta guía para crear e implementar una aptitud personalizada con Azure Machine Learning.
Depuración de canalizaciones de enriquecimiento con IA
Puede resultar complicado comprender el flujo de información y el enriquecimiento con IA para grandes conjuntos de aptitudes. Azure Cognitive Search proporciona funcionalidades útiles para depurar y visualizar la canalización de enriquecimiento, incluidas las entradas y salidas de las aptitudes.

El diagrama de flujo se extrajo de la pestaña de Debug Sessions del recurso de Azure Cognitive Search en Azure Portal. Resume el flujo de enriquecimientos a medida que el contenido se procesa sucesivamente mediante las aptitudes integradas y los modelos de riesgo personalizados en un conjunto de aptitudes.
Azure Cognitive Search genera automáticamente el flujo de procesamiento del gráfico de aptitudes en función de las configuraciones de entrada y salida de las aptitudes. En el gráfico también se muestra el grado de paralelismo en el procesamiento.
Se usa una aptitud condicional para identificar el tipo de documento (correo electrónico, transcripción o noticias), porque estos se procesan de forma diferente en pasos posteriores. Las aptitudes condicionales sirven para evitar cargos de traducción en los casos en los que el idioma de origen y el de destino es el mismo.
Las aptitudes integradas incluyen OCR, detección del idioma, detección de entidades, traducción y combinación de texto, que se usa para reemplazar una imagen insertada por la salida OCR insertada en el documento original.
La última aptitud de la canalización es la integración de los modelos de riesgo de reconocimiento del lenguaje conversacional mediante la aplicación Functions.
Por último, los campos originales y enriquecidos se indexan y se asignan al índice de Azure Cognitive Search.
En el siguiente extracto de una respuesta de búsqueda se muestra un ejemplo de la información que se puede obtener mediante el uso de contenido enriquecido y búsqueda semántica. El término de consulta es "how were capex" (cómo fueron los gastos de capital), que es la forma abreviada de "how did capital expenditures develop in the reporting period?" (¿Cómo evolucionaron los gastos de capital en el período del informe?).
{
"@search.captions" : [
{
"highlights" : "Cash flow from operations was $22.7 billion, up 2296 year-over-year, driven by strong cloud billings and collections Free cash flow of $16.3 billion, up 1796 year-over-year, reflecting higher<em> capital expenditures</em> to support our cloud business 6 includes non-GAAP constant currency CCC\") growth and cash flow."
}],
"sender_or_caller" : "Jim Smith",
"recipient" : "Mary Turner",
"metadata_storage_name" : "Reevaluate MSFT.msg",
"people" : ["Jim Smith", "Mary Turner", "Bill Ford", … ],
"organizations" : ["Microsoft", "Yahoo Finance", "Federal Reserve", … ],
"original_language" : "nl",
"translated_text" : "Here is the latest update about …",
"risk_average" : "high",
"risk_models" : [
{
"risk" : "Insider Trade",
"risk_score" : 0.7187,
"risk_sentence" : "Happy to provide some special insights to you. Let’s take this conversation offline.",
"risk_model_version" : "Inside Trade v1.3"
},
]
}
Interfaz de usuario
Después de implementar una solución de búsqueda, puede consultar el índice directamente mediante Azure Portal. Aunque esta opción es adecuada para aprender, experimentar y depurar, no ofrece una buena experiencia al usuario final.
Una interfaz de usuario personalizada, centrada en la experiencia del usuario, resulta útil para mostrar el verdadero valor de la solución de búsqueda y para que las organizaciones puedan identificar y revisar las comunicaciones de riesgo en diversos canales y orígenes.
El Acelerador de soluciones de minería de conocimientos proporciona una plantilla de interfaz de usuario de Azure Cognitive Search (una aplicación web MVC de .NET Core) que se puede usar para crear rápidamente un prototipo para consultar y ver los resultados de la búsqueda.
La interfaz de usuario de la plantilla se puede configurar en unos pocos pasos para conectarse y consultar el índice de búsqueda, tras lo que se muestra una página web sencilla para buscar y visualizar los resultados. Esta plantilla se puede personalizar aún más para mejorar la experiencia de recuperar y analizar las comunicaciones de riesgo.
En la captura de pantalla siguiente se muestra una interfaz de usuario de ejemplo para nuestro escenario de riesgo, creada mediante la personalización de la plantilla de interfaz de usuario de Azure Cognitive Search. Esta interfaz de usuario indica cómo se puede mostrar la solución de búsqueda mediante una vista intuitiva de las comunicaciones entre canales y la información de riesgo.

La página de inicio permite interactuar con la solución de búsqueda. Aquí el usuario puede buscar, refinar, visualizar y explorar los resultados:
- Los resultados iniciales se recuperan de un índice de búsqueda y se muestran en un formulario tabular, lo que ofrece acceso fácil a las comunicaciones y simplifica la comparación de resultados.
- Los principales detalles de las comunicaciones están al alcance del usuario y los documentos de varios canales (correos electrónicos, transcripciones y noticias) aparecen consolidados en una sola vista.
- Las puntuaciones de los modelos de riesgo personalizados se muestran para cada comunicación, donde se pueden resaltar los mayores riesgos.
- Una clasificación de riesgos consolidada agrega las puntuaciones de los modelos de riesgo personalizados y se usa para ordenar los resultados en función del nivel de riesgo medio.
- Un control deslizante de umbral permite que el usuario cambie los umbrales de riesgo. Las puntuaciones de riesgo personalizadas que superan el umbral aparecen resaltadas.
- Un selector de intervalo de fechas permite ampliar el período de análisis o buscar resultados históricos.
- Los resultados de la búsqueda se pueden refinar mediante un conjunto de filtros, como el idioma o el tipo de documento. Estas opciones se generan dinámicamente en la interfaz de usuario, como una función de los campos clasificables configurados en el índice.
- Una barra de búsqueda ofrece la posibilidad de buscar términos o frases específicos en el índice.
- La búsqueda semántica está disponible. El usuario puede cambiar entre la búsqueda estándar y semántica.
- Las nuevas comunicaciones se pueden cargar e indexar directamente en la interfaz de usuario. También se proporciona una página de detalles para cada documento:

La página de detalles proporciona acceso al contenido de la comunicación y a los enriquecimientos y metadatos:
- Se muestra el contenido que se extrajo durante el proceso de descifrado de documentos. Algunos archivos, como los PDF, se pueden ver directamente en la página de detalles.
- Los resultados de los modelos de riesgo personalizados se muestran resumidos.
- Las principales personas y organizaciones que se mencionan en el documento aparecen en esta página.
- Los metadatos adicionales que se capturaron durante el proceso de indexación pueden agregarse y mostrarse en pestañas adicionales de la página de detalles.
Si se ingiere contenido que no está en inglés, el usuario puede revisar el contenido en el idioma original o en inglés. La pestaña Transcripción de la página de detalles incluye el contenido original y el contenido traducido en paralelo. Esto demuestra que, durante el proceso de indexación, ambos idiomas se conservan, lo que permite que la interfaz de usuario consuma los dos.
Por último, el usuario puede realizar búsquedas semánticas. En el ejemplo siguiente se muestra el primer resultado obtenido al buscar mediante la búsqueda semántica la expresión "how were capex" (cómo fueron los gastos de capital), que es la forma abreviada de "how did capital expenditures develop in the reporting quarter?" (¿Cómo evolucionaron los gastos de capital en el trimestre del informe?).

Si se realiza una búsqueda equivalente en el modo de texto completo, la consulta busca una coincidencia exacta para "capex", que no aparece en el documento. En cambio, la funcionalidad semántica permite que el motor de consultas identifique que "capex" se relaciona con "capital expenditures" (gastos de capital), de modo que esta comunicación se identifica como la más relevante. Además, la búsqueda semántica genera resaltados semánticos (12), que resumen el documento con las oraciones más relevantes.
Prácticas recomendadas
En esta sección se resumen los procedimientos recomendados desde la perspectiva organizativa y técnica para desarrollar la solución de análisis de riesgos de cumplimiento.
Involucre a las partes interesadas pertinentes: la implementación de una solución de análisis de riesgos es un ejercicio multidisciplinario en el que participan partes interesadas clave de varios dominios. Debería incluir los roles relacionados con el proyecto que se presentaron anteriormente y otros roles que se ven afectados por la solución.
Garantice una adopción adecuada y la administración de cambios: la automatización de las prácticas de análisis de riesgos probablemente introducirá cambios considerables en la manera de trabajar de los empleados. Aunque la solución agrega valor, los cambios en cualquier flujo de trabajo pueden plantear dificultades, lo que conlleva largos períodos de adopción y, posiblemente, resistencia. Se recomienda implicar desde el principio a los empleados afectados. Considere el modelo de adopción ADKAR de Prosci, que se centra en cinco pasos clave del recorrido de adopción de una tecnología: Consciencia, Deseo, Conocimiento, Habilidad y Refuerzo.
Use varios canales para detectar riesgos: cada canal de comunicación (por ejemplo, correo electrónico, chats y telefonía) se puede estudiar de forma aislada para detectar posibles riesgos. Pero se consigue información mejor si se combinan canales heterogéneos de comunicaciones formales (por ejemplo, correo electrónico) y menos formales (por ejemplo, chats). Además, la integración de información complementaria (como noticias del mercado, informes de la empresa y declaraciones de SEC) puede proporcionar contexto adicional para el analista de cumplimiento (por ejemplo, sobre una iniciativa específica de una empresa).
Comience de forma sencilla e iterada: Azure Cognitive Search proporciona un conjunto completo de enriquecimiento con IA integrado basado en varios servicios de Cognitive Services. Puede resultar tentador agregar muchas de estas funcionalidades desde el principio, pero el número de entidades o frases clave que se pueden extraer, si no se controla correctamente, puede abrumar al usuario final. Si empieza con un conjunto reducido de aptitudes o entidades, ayudará a los usuarios y desarrolladores a comprender cuáles agregan más valor.
Innovación responsable: el desarrollo de soluciones de inteligencia artificial exige un alto nivel de responsabilidad por parte de todos los implicados. Microsoft se toma muy en serio el uso responsable de la inteligencia artificial y ha desarrollado un marco de principios básicos de diseño:
- Imparcialidad
- Confiabilidad y seguridad
- Privacidad y seguridad
- Inclusión
- Transparencia y responsabilidad
La evaluación de las comunicaciones de los empleados requiere atención especial y plantea cuestiones éticas. En algunos países/regiones, la supervisión automatizada de los empleados está sujeta a estrictas restricciones legales. Por todas estas razones, haga que la innovación responsable sea una piedra angular del plan del proyecto. Microsoft ofrece varios marcos y herramientas para este fin. Para obtener más información, consulte el cuadro Sugerencia que se incluye al final de esta sección.
Automatice las iteraciones de desarrollo: el Asistente para importar datos facilita empezar a trabajar, pero cuando se trata de soluciones más complejas y casos de uso productivos se recomienda crear recursos en el código, como orígenes de datos, indexadores, índices y conjuntos de aptitudes. La automatización acelera drásticamente los ciclos de desarrollo y garantiza una implementación coherente en producción. Los recursos se especifican en formato JSON. Puede copiar definiciones de JSON desde el portal, modificarlas según sea necesario e incluirlas en el cuerpo de la solicitud de las llamadas a las API REST de Azure Cognitive Search.
Seleccione el enfoque de NLP adecuado para el análisis de riesgos: las formas en que se identifican los riesgos en texto no estructurado varían desde la búsqueda básica de palabras clave y la extracción de entidades hasta arquitecturas de NLP modernas eficaces. La mejor opción depende de la cantidad y la calidad de los datos de entrenamiento existentes para el caso de uso específico. Si los datos de entrenamiento son limitados, puede entrenar un modelo basado en expresiones mediante la característica de reconocimiento del lenguaje conversacional de Azure Cognitive Service para lenguaje. Las conversaciones existentes se pueden revisar para identificar y etiquetar las oraciones que indican tipos de riesgo relevantes. A veces, basta con decenas de muestras para entrenar un modelo con buenos resultados.
En los casos en los que los signos de riesgo son más sutiles y abarcan varias oraciones, probablemente la mejor opción sea el entrenamiento de un modelo de NLP de última generación, pero este enfoque suele requerir muchos más datos de entrenamiento. Siempre que sea posible, se recomienda usar los datos reales cuando la solución está en producción para ajustarse a posibles predicciones erróneas y volver a entrenar continuamente el modelo para mejorar su rendimiento a lo largo del tiempo.
Adapte la interfaz de usuario en función de sus requisitos específicos: una interfaz de usuario enriquecida puede poner a disposición todo el valor añadido de Azure Cognitive Search y el enriquecimiento con IA. Aunque la plantilla de interfaz de usuario de Azure AI Search proporciona una manera sencilla y rápida de implementar una aplicación web inicial, es probable que tenga que adaptarla para integrar más características. También debe adaptarse a los tipos de comunicaciones que se procesan, los tipos de enriquecimiento con IA que se usan y otros requisitos empresariales. La colaboración e iteración continuas entre los desarrolladores de front-end, las partes interesadas empresariales y los usuarios finales ayudarán a mejorar el valor de la solución mediante la optimización de la experiencia del usuario para encontrar y revisar las comunicaciones pertinentes.
Optimice los costes de los servicios de traducción: de forma predeterminada, todos los documentos fluyen a través de la canalización de enriquecimiento con IA. Esto significa que los documentos en inglés se pasan al servicio de traducción incluso si no requieren traducción. Aun así, como Translation API procesa el contenido, se aplican cargos de todos modos. En nuestra solución, usamos la detección de idioma junto con aptitudes condicionales para evitar la traducción en estos casos. Si el idioma detectado del documento original no es inglés, el contenido se copia en un campo específico para el texto que no está inglés y se pasa al servicio de traducción. Si el documento está en inglés, este campo se deja vacío y no se generan cargos de traducción. Por último, todo el contenido (originalmente en inglés o traducido) se combina en un campo común para su posterior procesamiento. También puede habilitar el almacenamiento en caché para reutilizar los enriquecimientos existentes.
Garantice la disponibilidad y la escalabilidad del entorno de producción: después de pasar de la prueba de concepto al planeamiento de producción, debe tener en cuenta la disponibilidad y la escalabilidad para garantizar la fiabilidad y el rendimiento de la solución de búsqueda. Las instancias del servicio de búsqueda se denominan réplicas y se usan para equilibrar la carga de las operaciones de consulta. Agregue réplicas para lograr una alta disponibilidad y un mayor rendimiento de las consultas. Use particiones para administrar la escalabilidad de la solución. Las particiones representan el almacenamiento físico y tienen características específicas de tamaño y E/S. Consulte la documentación para obtener más instrucciones sobre cómo administrar la capacidad y otras consideraciones relacionadas con la administración de servicios.
Sugerencia
Consulte los recursos siguientes para obtener más detalles sobre los procedimientos recomendados que se describen en esta sección:
Conclusión
En esta guía se proporcionan instrucciones completas para configurar una solución que usa inteligencia artificial para buscar signos de fraude. El enfoque se puede aplicar a otros sectores regulados, como la sanidad o el gobierno.
Puede ampliar la arquitectura para incluir otros orígenes de datos y funcionalidades de inteligencia artificial, por ejemplo:
- Ingiera datos estructurados, como datos del mercado (por ejemplo, cotizaciones bursátiles) e información de transacciones.
- Asocie modelos de clasificación diseñados para extraer contenido de orígenes en papel mediante funcionalidades como Azure Form Recognizer y Read API de Azure.
- Ingiera información de las redes sociales mediante funcionalidades de Azure Language Studio para clasificar y filtrar temas relevantes, o Análisis de sentimiento de Azure para capturar tendencias de opinión.
- Use Microsoft Graph para reunir y consolidar información de Microsoft 365, como las interacciones interpersonales, las empresas con las que trabajan las personas o la información con la que acceden. Al guardar estos datos en Azure Storage, puede realizar búsquedas en ellos fácilmente.
La tecnología que subyace a la solución, Azure Cognitive Search, es la mejor opción porque admite minería de conocimientos, búsqueda en catálogos y búsqueda en la aplicación. Es fácil implementar y conectarse a varios orígenes de datos, así como proporcionar inteligencia artificial integrada y extensible para el procesamiento de contenido. Incluye funcionalidades como la búsqueda semántica, que cuentan con tecnología de aprendizaje profundo y características que deducen la intención del usuario, y muestran y clasifican los resultados más relevantes.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Creadores de entidad de seguridad:
- Andreas Kopp | Arquitecto sénior de soluciones en la nube
- João Pedro Martins | Responsable de arquitectos sénior de soluciones en la nube
- Carlos Alexandre Santos | Arquitecto sénior de soluciones en la nube
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.