Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describen las consideraciones para administrar datos en una arquitectura de microservicios. Cada microservicio administra sus propios datos, por lo que la integridad de los datos y la coherencia de los datos suponen desafíos críticos.
Dos servicios no deben compartir un almacén de datos. Cada servicio administra su propio almacén de datos privado y otros servicios no pueden acceder a él directamente. Esta regla impide el acoplamiento accidental entre servicios, lo que sucede cuando los servicios comparten los mismos esquemas de datos subyacentes. Si cambia el esquema de datos, el cambio debe coordinarse en todos los servicios que se basen en esa base de datos. Aislar el almacén de datos de cada servicio limita el ámbito del cambio y conserva la agilidad de las implementaciones independientes. Cada microservicio también puede tener modelos de datos, consultas o patrones de lectura y escritura únicos. Un almacén de datos compartido limita la capacidad de cada equipo para optimizar el almacenamiento de datos para su servicio específico.
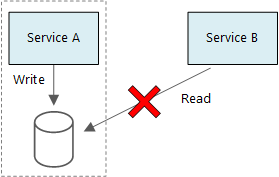
En el diagrama se muestra el servicio A y una base de datos en una sección a la izquierda. Flecha etiquetada como puntos de escritura del servicio A a la base de datos. El servicio B reside fuera de esta sección a la derecha. Una flecha etiquetada como "leer" apunta a la base de datos. Una X roja pasa por esta flecha.
Este enfoque conduce naturalmente a la persistencia políglota, lo que significa el uso de varias tecnologías de almacenamiento de datos dentro de una sola aplicación. Un servicio podría necesitar las funcionalidades de esquema en lectura de una base de datos de documentos. Otro servicio podría necesitar la integridad referencial que proporciona un sistema de administración de bases de datos relacionales (RDBMS). Cada equipo puede elegir la mejor opción para su servicio.
Nota:
Los servicios pueden compartir de forma segura el mismo servidor de base de datos físico. Los problemas se producen cuando los servicios comparten el mismo esquema o leen y escriben en el mismo conjunto de tablas de base de datos.
Desafíos
El enfoque distribuido para administrar datos presenta varios desafíos. En primer lugar, la redundancia puede producirse en todos los almacenes de datos. El mismo elemento de datos puede aparecer en varios lugares. Por ejemplo, los datos pueden almacenarse como parte de una transacción y, después, almacenarse en otro lugar para el análisis, los informes o el archivado. Los datos duplicados o particionados pueden provocar problemas con la integridad y la coherencia de los datos. Cuando las relaciones de datos abarcan varios servicios, las técnicas tradicionales de administración de datos no pueden aplicar esas relaciones.
El modelado de datos tradicional sigue la regla de un hecho en un solo lugar. Cada entidad aparece exactamente una vez en el esquema. Otras entidades pueden hacer referencia a ella, pero no duplicarla. La principal ventaja del enfoque tradicional es que las actualizaciones se producen en un solo lugar, lo que impide problemas de coherencia de datos. En una arquitectura de microservicios, debe tener en cuenta cómo se propagan las actualizaciones entre servicios y cómo administrar la coherencia final cuando los datos aparecen en varios lugares sin una coherencia fuerte.
Enfoques para administrar datos
Ningún enfoque único funciona para todos los casos. Tenga en cuenta las siguientes directrices generales para administrar datos en una arquitectura de microservicios:
Defina el nivel de coherencia necesario para cada componente y prefiera la coherencia final siempre que sea posible. Identifique las áreas del sistema en las que necesita consistencia fuerte o transacciones ACID (atomicidad, consistencia, aislamiento y durabilidad). E identifique las áreas en las que la coherencia final es aceptable. Para obtener más información, consulte Uso del diseño táctico controlado por dominios (DDD) para microservicios.
Use una única fuente de verdad cuando necesite una coherencia fuerte. Un servicio podría representar el origen de verdad de una entidad determinada y exponerlo a través de una API. Otros servicios pueden contener su propia copia de los datos o un subconjunto de los datos, que finalmente es coherente con los datos principales, pero no se consideran el origen de la verdad. Por ejemplo, en un sistema de comercio electrónico que tiene un servicio de pedidos de cliente y un servicio de recomendación, el servicio de recomendación podría escuchar eventos del servicio de pedidos. Pero si un cliente solicita un reembolso, el servicio de pedido, no el servicio de recomendación, tiene el historial de transacciones completo.
Aplique patrones de transacción para mantener la coherencia entre los servicios. Use patrones como Scheduler Agent Supervisor y Transacción de compensación para mantener los datos coherentes entre varios servicios. Para evitar errores parciales entre varios servicios, es posible que tenga que almacenar un fragmento adicional de datos que capture el estado de una unidad de trabajo que abarque varios servicios. Por ejemplo, mantenga un elemento de trabajo en una cola persistente mientras se procesa una transacción de varios pasos.
Almacene solo los datos que necesita un servicio. Un servicio puede necesitar solo un subconjunto de información sobre una entidad de dominio. Por ejemplo, en el contexto delimitado de envío, necesitas saber qué cliente está asociado a una entrega específica. Pero no necesita la dirección de facturación del cliente porque el contexto delimitado de cuentas administra esa información. El análisis cuidadoso de dominios y un enfoque DDD pueden aplicar este principio.
Tenga en cuenta si los servicios son coherentes y acoplados flexiblemente. Si dos servicios intercambian continuamente información entre sí y crean API de chatty, es posible que tenga que volver a dibujar los límites del servicio. Combine los dos servicios o refactorice su funcionalidad.
Use un estilo de arquitectura controlado por eventos. En este estilo de arquitectura, un servicio publica un evento cuando se producen cambios en sus modelos o entidades públicos. Otros servicios pueden suscribirse a estos eventos. Por ejemplo, otro servicio puede usar los eventos para construir una vista materializada de los datos más adecuados para realizar consultas.
Publique un esquema para eventos. Un servicio propietario de eventos debe publicar un esquema para automatizar la serialización y deserialización de eventos. Este enfoque evita un acoplamiento estricto entre publicadores y suscriptores. Considere el esquema JSON o un marco como Protobuf o Avro.
Reduzca los cuellos de botella en los eventos a gran escala. A gran escala, los eventos pueden convertirse en un cuello de botella en el sistema. Considere la posibilidad de usar la agregación o el procesamiento por lotes para reducir la carga total.
Ejemplo: Elegir almacenes de datos para la aplicación de entrega de drones
En los artículos anteriores de esta serie se describe un servicio de entrega de drones como ejemplo en ejecución. Para obtener más información sobre el escenario y la arquitectura correspondiente, consulte Diseño de una arquitectura de microservicios.
Para volver a resumir, esta aplicación define varios microservicios para programar entregas por dron. Cuando un usuario programa una nueva entrega, la solicitud de cliente incluye información sobre la entrega, como las ubicaciones de recogida y entrega, y sobre el paquete, como el tamaño y el peso. Esta información define una unidad de trabajo.
Los distintos servicios back-end usan diferentes partes de la información de la solicitud y tienen perfiles de lectura y escritura diferentes.

Servicio de entrega
El servicio de entrega almacena información sobre todas las entregas programadas o en curso. Escucha eventos de los drones y realiza un seguimiento del estado de las entregas en curso. También envía eventos de dominio con actualizaciones de estado de entrega.
Los usuarios suelen comprobar el estado de una entrega mientras esperan su paquete. Por lo tanto, el servicio de entrega requiere un almacén de datos que resalte el rendimiento (lectura y escritura) en el almacenamiento a largo plazo. El servicio de entrega no realiza consultas ni análisis complejos. Solo captura el estado más reciente de una entrega específica. El equipo del servicio de entrega eligió Azure Managed Redis por su alto rendimiento de lectura y escritura. La información almacenada en Azure Managed Redis es de corta duración. Una vez finalizada la entrega, el servicio de historial de entrega se convierte en el sistema de registro.
Servicio de historial de entrega
El servicio de historial de entrega escucha los eventos de estado relacionados con la entrega provenientes del servicio de envío. Almacena estos datos en el almacenamiento a largo plazo. Estos datos históricos admiten dos escenarios, cada uno con requisitos de almacenamiento diferentes.
El primer escenario agrega datos para el análisis de datos para optimizar la empresa o mejorar la calidad del servicio. El servicio de historial de entrega no realiza el análisis de datos real. Solo ingiere y almacena los datos. En este escenario, el almacenamiento debe optimizarse para el análisis de datos en conjuntos de datos grandes y usar un enfoque de esquema en lectura para dar cabida a varios orígenes de datos. Azure Data Lake Storage es una buena opción para este escenario porque es un sistema de archivos de Apache Hadoop compatible con el sistema de archivos distribuido de Hadoop (HDFS). También está optimizado para el rendimiento de los escenarios de análisis de datos.
El segundo escenario permite a los usuarios buscar el historial de una entrega una vez finalizada la entrega. Data Lake Storage no admite este escenario. Para obtener un rendimiento óptimo, almacene los datos de serie temporal en Data Lake Storage en carpetas con particiones por fecha. Pero esta estructura hace que las búsquedas basadas en identificadores individuales no sea eficaz. A menos que también conozca la marca de tiempo, una búsqueda de identificadores requiere que examine toda la colección. Para solucionar este problema, el servicio de historial de entrega también almacena un subconjunto de los datos históricos de Azure Cosmos DB para una búsqueda más rápida. Los registros no necesitan permanecer indefinidamente en Azure Cosmos DB. Puede archivar entregas anteriores después de un período de tiempo específico, como un mes, ejecutando un proceso por lotes ocasional. El archivado de datos puede reducir los costos de Azure Cosmos DB y mantener los datos disponibles para los informes históricos de Data Lake Storage.
Para más información, consulte Optimización de Data Lake Storage para obtener un rendimiento.
Servicio de paquete
El servicio de paquetes almacena información sobre todos los paquetes. El almacén de datos para el servicio de paquete debe cumplir los siguientes requisitos:
- Almacenamiento a largo plazo
- Alto rendimiento de escritura para gestionar un gran volumen de paquetes
- Consultas simples por identificador de paquete sin combinaciones complejas ni restricciones de integridad referencial
Los datos del paquete no son relacionales, por lo que una base de datos orientada a documentos funciona bien. Azure DocumentDB puede lograr un alto rendimiento mediante colecciones particionadas. El equipo de servicio de paquetes está familiarizado con la pila de MongoDB, Express.js, AngularJS y Node.js (MEAN), por lo que eligen implementar Azure DocumentDB. Esta opción les permite usar su experiencia existente de MongoDB al obtener las ventajas de un servicio de Azure de alto rendimiento totalmente administrado.