Migración de datos de Apache HBase a la cuenta de Azure Cosmos DB for NoSQL
SE APLICA A: ![]() NoSQL
NoSQL
Azure Cosmos DB es una base de datos totalmente administrada, escalable y distribuida globalmente. Proporciona acceso de baja latencia garantizado a los datos. Para obtener más información sobre Azure Cosmos DB, vea el artículo de información general. Este artículo explica cómo migrar los datos de HBase a la cuenta de Azure Cosmos DB for NoSQL.
Diferencias entre Azure Cosmos DB y HBase
Antes de migrar, debe saber las diferencias entre Azure Cosmos DB y HBase.
Modelo de recursos
Azure Cosmos DB tiene el siguiente modelo de recursos: 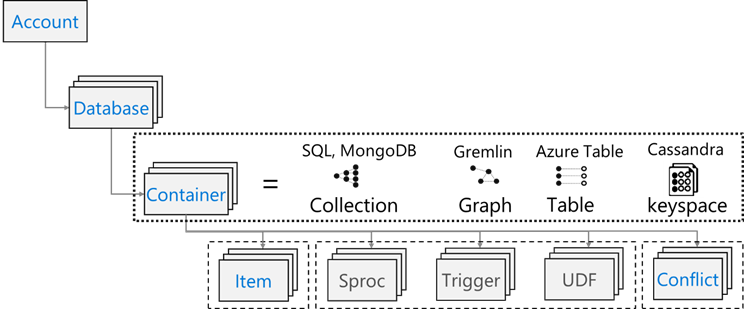
HBase tiene el siguiente modelo de recursos: 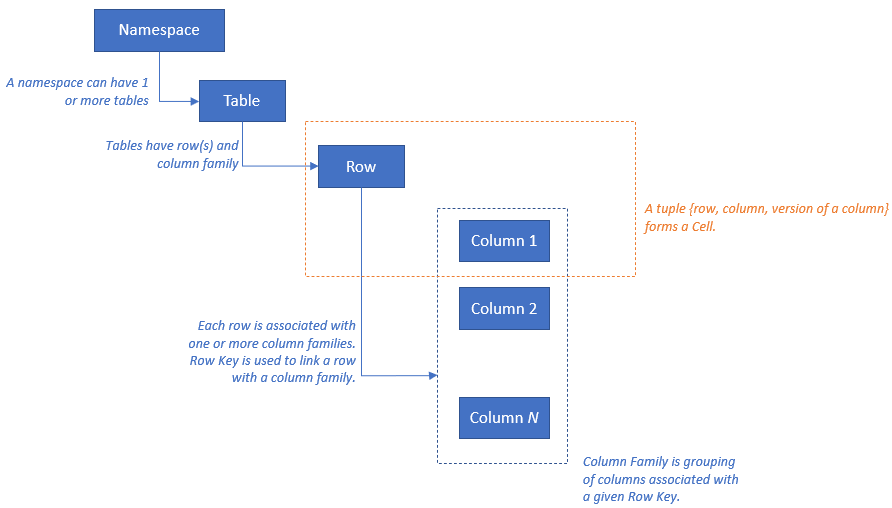
Asignación de recursos
En la tabla siguiente se muestra una asignación conceptual entre Apache HBase, Apache Phoenix y Azure Cosmos DB.
| HBase | Phoenix | Azure Cosmos DB |
|---|---|---|
| Clúster | Clúster | Cuenta |
| Espacio de nombres | Esquema (si está habilitado) | Base de datos |
| Tabla | Tabla | Contenedor o colección |
| Familia de columnas | Familia de columnas | N/D |
| Row | Row | Elemento o documento |
| Versión (marca de tiempo) | Versión (marca de tiempo) | N/D |
| N/D | Clave principal | Partition Key |
| N/D | Índice | Índice |
| N/D | Índice secundario | Índice secundario |
| N/D | Ver | N/D |
| N/D | Secuencia | N/D |
Comparación y diferencias de estructura de datos
Las diferencias clave entre la estructura de datos de Azure Cosmos DB y HBase son las siguientes:
RowKey
En HBase, RowKey almacena los datos y se particiona horizontalmente en regiones por el rango de RowKey especificado durante la creación de la tabla.
Azure Cosmos DB en el otro lado distribuye datos en particiones en función del valor hash de una clave de partición especificada.
Familia de columnas
En HBase, las columnas se agrupan dentro de una familia de columnas (CF).
Azure Cosmos DB (API para NoSQL) almacena datos como documento JSON. Por lo tanto, se aplican todas las propiedades asociadas a una estructura de datos JSON.
Timestamp
HBase usa marca de tiempo para dar versión a varias instancias de una celda determinada. Puede consultar diferentes versiones de una celda con marca de tiempo.
Azure Cosmos DB incluye la característica fuente de cambios, que realiza un seguimiento persistente de los cambios en un contenedor en el orden en que se producen A continuación, muestra la lista ordenada de los documentos que han cambiado en el orden en el que se modificaron.
Formato de datos
El formato de datos HBase consta de RowKey, Familia de columnas: Nombre de columna, Marca de tiempo, Valor. A continuación se muestra un ejemplo de una fila de tabla HBase:
ROW COLUMN+CELL 1000 column=Office:Address, timestamp=1611408732448, value=1111 San Gabriel Dr. 1000 column=Office:Phone, timestamp=1611408732418, value=1-425-000-0002 1000 column=Personal:Name, timestamp=1611408732340, value=John Dole 1000 column=Personal:Phone, timestamp=1611408732385, value=1-425-000-0001En Azure Cosmos DB for NoSQL, el objeto JSON representa el formato de los datos. La clave de partición reside en un campo del documento y establece qué campo es la clave de partición de la colección. Azure Cosmos DB no tiene el concepto de marca de tiempo que se usa para la familia de columnas o la versión. Como se ha resaltado anteriormente, tiene compatibilidad de fuente de cambios a través de la cual se puede realizar un seguimiento o registro de los cambios realizados en un contenedor. A continuación, se muestra un ejemplo de un documento.
{ "RowId": "1000", "OfficeAddress": "1111 San Gabriel Dr.", "OfficePhone": "1-425-000-0002", "PersonalName": "John Dole", "PersonalPhone": "1-425-000-0001", }
Sugerencia
HBase almacena datos en matriz de bytes, por lo que si desea migrar datos que contienen caracteres de dos bytes a Azure Cosmos DB, los datos deben estar codificados con UTF-8.
Modelo de coherencia
HBase ofrece lecturas y escrituras estrictamente coherentes.
Azure Cosmos DB ofrece cinco niveles de coherencia bien definidos. Cada nivel proporciona equilibrio entre la disponibilidad y el rendimiento. De más fuerte a más débil, los niveles de consistencia que se admiten son:
- Alta
- Uso vinculado
- Sesión
- Prefijo coherente
- Ocasional
Ajuste de tamaño
HBase
Para una implementación a escala empresarial de HBase, patrón; servidores de región; y ZooKeeper conducen la mayor parte del tamaño. Como cualquier aplicación distribuida, HBase está diseñado para escalar horizontalmente. El rendimiento de HBase se basa principalmente en el tamaño de los HBase RegionServers. El tamaño se basa principalmente en dos requisitos clave: rendimiento y tamaño del conjunto de datos que debe almacenarse en HBase.
Azure Cosmos DB
Azure Cosmos DB es una oferta de PaaS de Microsoft y los detalles de implementación de infraestructura subyacente se abstrae de los usuarios finales. Cuando se aprovisiona un contenedor de Azure Cosmos DB, la plataforma Azure aprovisiona automáticamente la infraestructura subyacente ( informática, almacenamiento, memoria, pila de redes) para admitir los requisitos de rendimiento de una carga de trabajo determinada. Azure Cosmos DB se encarga de normalizar el costo de todas las operaciones de base de datos y se expresa en términos de unidades de solicitud (RU en su forma abreviada).
Para estimar las CPU consumidas por la carga de trabajo, tenga en cuenta los siguientes factores:
Hay una calculadora de capacidad disponible para ayudar con el ejercicio de ajuste de tamaño de las RU.
También puede usar el rendimiento de aprovisionamiento de autoescalado en Azure Cosmos DB para escalar automática e instantáneamente el rendimiento de su base de datos o contenedor (RU/seg). El rendimiento se escala en función del uso sin afectar a la disponibilidad de la carga de trabajo, la latencia, el rendimiento o las prestaciones.
Distribución de datos
HBase HBase ordena los datos según RowKey. Los datos se particiona en regiones y se almacenan en RegionServers. La partición automática divide las regiones horizontalmente según la directiva de particionamiento. Esto se controla mediante el valor asignado al parámetro HBase hbase.hregion.max.filesize (el valor predeterminado es 10 GB). Una fila de HBase con una fila determinada RowKey siempre pertenece a una región. Además, los datos se separan en el disco para cada familia de columnas. Esto permite filtrar en el momento de la lectura y el aislamiento de E/S en HFile.
Azure Cosmos DB Azure Cosmos DB usa el particionamiento para escalar contenedores individuales en la base de datos La creación de particiones divide los elementos de un contenedor en subconjuntos específicos denominados "particiones lógicas". Las particiones lógicas se forman en función del valor de la "clave de partición" asociada a cada elemento del contenedor. Todos los elementos de una partición lógica tienen el mismo valor de clave de partición. Cada partición lógica puede hospedar un máximo de 20 GB de datos.
Las particiones físicas contienen una réplica de los datos y una instancia del motor de base de datos de Azure Cosmos DB. Esta estructura hace que los datos sean resistentes y tengan alta disponibilidad, y el rendimiento se divide equitativamente entre las particiones físicas locales. Las particiones físicas se crean y configuran automáticamente, y no es posible controlar su tamaño, ubicación ni las particiones lógicas que contienen. Las particiones lógicas no se dividen entre particiones físicas.
Al igual que con HBase RowKey, el diseño de clave de partición es importante para Azure Cosmos DB. La clave de fila de HBase funciona ordenando datos y almacenando datos continuos, y la clave de partición de Azure Cosmos DB es un mecanismo diferente porque distribuye datos mediante hash. Suponiendo que la aplicación que usa HBase está optimizada para los patrones de acceso a datos en HBase, el uso de la misma RowKey para la clave de partición no dará buenos resultados de rendimiento. Dado que se trata de datos ordenados en HBase, el índice compuesto de Azure Cosmos DB. Es necesario si desea usar la cláusula ORDER BY en más de un campo. También se puede mejorar el rendimiento de muchas consultas iguales y de rango definiendo un índice compuesto.
Disponibilidad
HBase HBase consta de Patrón; Servidor de región; y ZooKeeper. Se puede lograr una alta disponibilidad en un solo clúster haciendo que cada componente sea redundante. Al configurar la redundancia geográfica, se pueden implementar clústeres de HBase en distintos centros de datos físicos y usar la replicación para mantener varios clústeres sincronizados.
Azure Cosmos DB Azure Cosmos DB no requiere ninguna configuración, como la redundancia de componentes del clúster. Proporciona un contrato de nivel de servicio completo para alta disponibilidad, coherencia y latencia. Consulte Acuerdo de Nivel de Servicio de Azure Cosmos DB para obtener más detalles.
Confiabilidad de los datos
HBase HBase se basa en Hadoop Distributed File System (HDFS) y los datos almacenados en HDFS se replican tres veces.
Azure Cosmos DB Azure Cosmos DB proporciona principalmente alta disponibilidad de dos maneras. En primer lugar, Azure Cosmos DB replica los datos entre las regiones configuradas dentro de una cuenta de Azure Cosmos DB. En segundo lugar, Azure Cosmos DB conserva cuatro réplicas de los datos en la región.
Consideraciones antes de migrar
Dependencias del sistema
Este aspecto de la planificación se centra en el reconocimiento las dependencias ascendentes y descendentes para la instancia de HBase, que se migra a Azure Cosmos DB.
Ejemplo de dependencias descendentes podrían ser las aplicaciones que leen datos de HBase. Estos deben refactorizarse para leerse desde Azure Cosmos DB. Estos puntos siguientes deben considerarse como parte de la migración:
Preguntas para evaluar dependencias: ¿Es el sistema HBase actual un componente independiente? ¿O llama a un proceso en otro sistema, o lo llama un proceso en otro sistema o se tiene acceso a él mediante un servicio de directorio? ¿Funcionan otros procesos importantes en el clúster de HBase? Es necesario aclarar estas dependencias del sistema para determinar el impacto de la migración.
La implementación local de RPO y RTO para HBase.
Migración sin conexión y en línea
Para una migración de datos correcta, es importante comprender las características de la empresa que usa la base de datos y decidir cómo hacerlo. Seleccione migración sin conexión si puede cerrar completamente el sistema, realizar la migración de datos y reiniciar el sistema en el destino. Además, si la base de datos siempre está ocupada y no puede permitirse una interrupción larga, considere la posibilidad de migrar en línea.
Nota:
Este documento trata solo la migración sin conexión.
Al realizar la migración de datos sin conexión, depende de la versión de HBase que esté ejecutando actualmente y de las herramientas disponibles. Consulte la sección de migración de datos para obtener más detalles.
Consideraciones de rendimiento
Este aspecto de la planificación consiste en comprender los objetivos de rendimiento para HBase y luego trasladarlos a la semántica de Azure Cosmos DB. Por ejemplo: para alcanzar un valor "X" de IOPS en HBase, cuántas unidades de solicitud (RU/s) serán necesarias en Azure Cosmos DB. Hay diferencias entre HBase y Azure Cosmos DB, este ejercicio se centra en crear una visión de cómo los objetivos de rendimiento de HBase se trasladarán a Azure Cosmos DB. Esto impulsará el ejercicio de escalado.
Preguntas que se deben formular:
- ¿La implementación de HBase es de lectura pesada o de escritura pesada?
- ¿Cuál es la división entre lecturas y escrituras?
- ¿Cuál es el objetivo de IOPS que se expresa como percentil?
- ¿Cómo y qué aplicaciones se usan para cargar datos en HBase?
- ¿Cómo y qué aplicaciones se usan para leer datos de HBase?
Al ejecutar consultas que solicitan datos ordenados, HBase devolverá el resultado con rapidez porque los datos están ordenados por RowKey. Sin embargo, Azure Cosmos DB no tiene este concepto. Para optimizar el rendimiento, se pueden utilizar índices compuestos según sea necesario.
Consideraciones de la implementación
Puede usar Azure Portal o la CLI de Azure para implementar Azure Cosmos DB for NoSQL. Puesto que el destino de la migración es Azure Cosmos DB for NoSQL, seleccione "SQL" para la API como parámetro al implementar. Además, configure la georredundancia, las escrituras multirregionales y las zonas de disponibilidad según sus requisitos de disponibilidad.
Consideración de red
Azure Cosmos DB tiene tres opciones de red principales. La primera es una configuración que usa una dirección IP pública y controla el acceso con un firewall IP (predeterminada). La segunda es una configuración que usa una dirección IP pública y solo permite el acceso desde una subred específica de una red virtual específica (punto de conexión de servicio). El tercero es una configuración (punto de conexión privado) que se une a una red privada con una dirección IP privada.
Vea los siguientes documentos para obtener más información sobre las tres opciones de red:
Evaluar los datos existentes
Detección de datos
Recopile información de antemano desde el clúster de HBase existente para identificar los datos que desea migrar. Esto puede ayudarle a identificar cómo migrar, decidir qué tablas migrar, comprender la estructura dentro de esas tablas y decidir cómo crear el modelo de datos. Por ejemplo, recopilo detalles como los siguientes:
- Versión de HBase
- Tablas de destino de migración
- Información de familia de columnas
- Estado de la tabla
Los siguientes comandos muestran cómo recopilar los detalles anteriores con un script de shell hbase y almacenarlos en el sistema de archivos local del equipo operativo.
Obtener la versión de HBase
hbase version -n > hbase-version.txt
Salida:
cat hbase-version.txt
HBase 2.1.8.4.1.2.5
Obtener la lista de tablas
Puede obtener una lista de tablas almacenadas en HBase. Si ha creado un espacio de nombres distinto del predeterminado, se mostrará en el formato "Namespace: Table".
echo "list" | hbase shell -n > table-list.txt
HBase 2.1.8.4.1.2.5
Salida:
echo "list" | hbase shell -n > table-list.txt
cat table-list.txt
TABLE
COMPANY
Contacts
ns1:t1
3 row(s)
Took 0.4261 seconds
COMPANY
Contacts
ns1:t1
Identificar las tablas que se migrarán
Obtenga los detalles de las familias de columnas de la tabla especificando el nombre de tabla que se va a migrar.
echo "describe '({Namespace}:){Table name}'" | hbase shell -n > {Table name} -schema.txt
Salida:
cat {Table name} -schema.txt
Table {Table name} is ENABLED
{Table name}
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'cf2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
2 row(s)
Took 0.5775 seconds
Obtener las familias de columnas en la tabla y su configuración
echo "status 'detailed'" | hbase shell -n > hbase-status.txt
Salida:
{HBase version}
0 regionsInTransition
active master: {Server:Port number}
2 backup masters
{Server:Port number}
{Server:Port number}
master coprocessors: []
# live servers
{Server:Port number}
requestsPerSecond=0.0, numberOfOnlineRegions=44, usedHeapMB=1420, maxHeapMB=15680, numberOfStores=49, numberOfStorefiles=14, storefileUncompressedSizeMB=7, storefileSizeMB=7, compressionRatio=1.0000, memstoreSizeMB=0, storefileIndexSizeKB=15, readRequestsCount=36210, filteredReadRequestsCount=415729, writeRequestsCount=439, rootIndexSizeKB=15, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=464, currentCompactedKVs=464, compactionProgressPct=1.0, coprocessors=[GroupedAggregateRegionObserver, Indexer, MetaDataEndpointImpl, MetaDataRegionObserver, MultiRowMutationEndpoint, ScanRegionObserver, SecureBulkLoadEndpoint, SequenceRegionObserver, ServerCachingEndpointImpl, UngroupedAggregateRegionObserver]
[...]
"Contacts,,1611126188216.14a597a0964383a3d923b2613524e0bd."
numberOfStores=2, numberOfStorefiles=2, storefileUncompressedSizeMB=7168, lastMajorCompactionTimestamp=0, storefileSizeMB=7, compressionRatio=0.0010, memstoreSizeMB=0, readRequestsCount=4393, writeRequestsCount=0, rootIndexSizeKB=14, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=0, currentCompactedKVs=0, compactionProgressPct=NaN, completeSequenceId=-1, dataLocality=0.0
[...]
Puede obtener información útil sobre el tamaño, como el tamaño de la memoria de almacenamiento dinámico, el número de regiones, el número de solicitudes como el estado del clúster y el tamaño de los datos en comprimidos o sin comprimir como el estado de la tabla.
Si usa Apache Phoenix en el clúster de HBase, también debe recopilar datos de Phoenix.
- Tabla de destino de migración
- Esquemas de tabla
- Índices
- Clave principal
Conectar a Apache Phoenix en el clúster
sqlline.py ZOOKEEPER/hbase-unsecure
Obtener la lista de tablas
!tables
Obtener los detalles de la tabla
!describe <Table Name>
Obtener los detalles del índice
!indexes <Table Name>
Obtener los detalles de la clave principal
!primarykeys <Table Name>
Migración de los datos
Opciones de migración
Hay varios métodos para migrar datos sin conexión, pero aquí presentaremos cómo usar Azure Data Factory.
| Solución | La versión de origen | Consideraciones |
|---|---|---|
| Azure Data Factory | HBase < 2 | Fácil de configurar. Adecuada para grandes conjuntos de datos. No es compatible con HBase 2 o posterior. |
| Spark de Apache | Todas las versiones | Admite todas las versiones de HBase. Adecuada para grandes conjuntos de datos. Se requiere la configuración de Spark. |
| Herramienta personalizada con la biblioteca BulkExecutor de Azure Cosmos DB | Todas las versiones | Más flexible para crear herramientas de migración de datos personalizadas con bibliotecas. Requiere más esfuerzo para configurar. |
El siguiente diagrama de flujo usa algunas condiciones para llegar a los métodos de migración de datos disponibles.
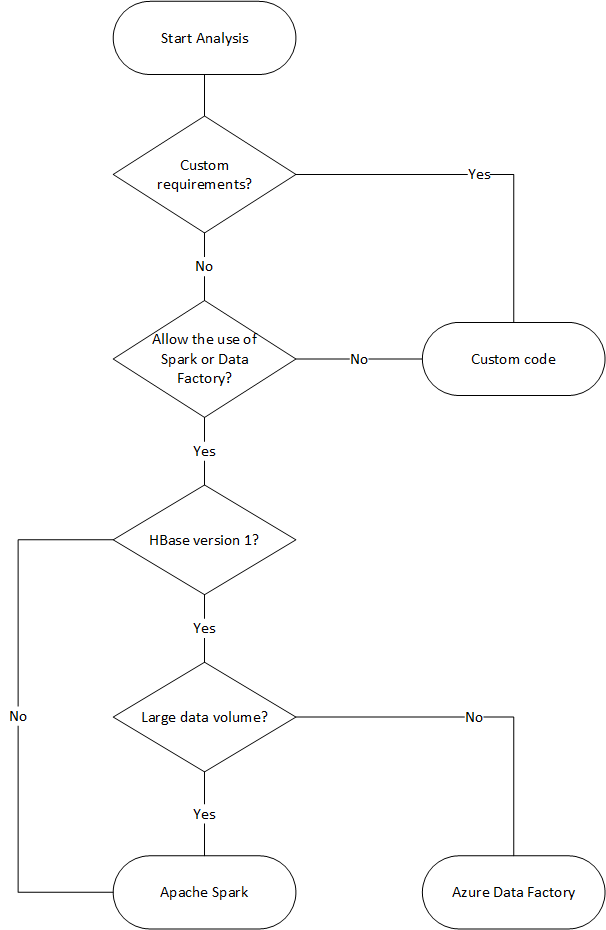
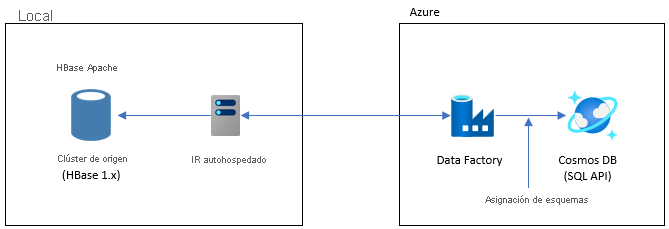
Migrar con Data Factory
Esta opción es adecuada para conjuntos de datos grandes. Se utiliza la biblioteca Azure Cosmos DB Bulk Executor. No hay puntos de comprobación, por lo que si encuentra algún problema durante la migración, tendrá que reiniciar el proceso de migración desde el principio. También puede usar el entorno de ejecución de integración autohospedado de Data Factory para conectarse a su HBase local, o implementar Data Factory en una VNET administrada y conectarse a su red local mediante VPN o ExpressRoute.
La actividad de copia de Data Factory admite HBase como origen de datos. Consulte el artículo Copiar datos de HBase con Azure Data Factory para obtener más detalles
Puede especificar una instancia de Azure Cosmos DB (API para NoSQL) como destino de sus datos. Consulte el artículo Copiar y transformar datos en Azure Cosmos DB (API para NoSQL) con Azure Data Factory para obtener más detalles.
Migración con Apache Spark: Conector Apache HBase y Conector de Spark para Azure Cosmos DB
Este es un ejemplo para migrar los datos a Azure Cosmos DB. Se supone que HBase 2.1.0 y Spark 2.4.0 se ejecutan en el mismo clúster.
Apache Spark: el repositorio de Apache HBase Connector se puede encontrar en Apache Spark: Apache HBase Connector
Para el conector Spark de Azure Cosmos DB, consulte la Guía de inicio rápido y descargue la biblioteca adecuada para su versión de Spark.
Copie hbase-site.xml en el directorio de configuración de Spark.
cp /etc/hbase/conf/hbase-site.xml /etc/spark2/conf/Ejecute spark -shell con el conector Spark HBase y el conector Azure Cosmos DB Spark.
spark-shell --packages com.hortonworks.shc:shc-core:1.1.0.3.1.2.2-1 --repositories http://repo.hortonworcontent/groups/public/ --jars azure-cosmosdb-spark_2.4.0_2.11-3.6.8-uber.jarDespués de que se inicie el shell de Spark, ejecute el código Scala de la siguiente manera. Importe las bibliotecas necesarias para cargar datos desde HBase.
// Import libraries import org.apache.spark.sql.{SQLContext, _} import org.apache.spark.sql.execution.datasources.hbase._ import org.apache.spark.{SparkConf, SparkContext} import spark.sqlContext.implicits._Defina el esquema del catálogo de Spark para las tablas de HBase. Aquí el espacio de nombres es "predeterminado" y el nombre de la tabla es "Contactos". La clave de fila se especifica como la clave. Las columnas, la familia de columnas y la columna se asignan al catálogo de Spark.
// define a catalog for the Contacts table you created in HBase def catalog = s"""{ |"table":{"namespace":"default", "name":"Contacts"}, |"rowkey":"key", |"columns":{ |"rowkey":{"cf":"rowkey", "col":"key", "type":"string"}, |"officeAddress":{"cf":"Office", "col":"Address", "type":"string"}, |"officePhone":{"cf":"Office", "col":"Phone", "type":"string"}, |"personalName":{"cf":"Personal", "col":"Name", "type":"string"}, |"personalPhone":{"cf":"Personal", "col":"Phone", "type":"string"} |} |}""".stripMarginDespués, defina un método para obtener los datos de la tabla de contactos de HBase como un DataFrame.
def withCatalog(cat: String): DataFrame = { spark.sqlContext .read .options(Map(HBaseTableCatalog.tableCatalog->cat)) .format("org.apache.spark.sql.execution.datasources.hbase") .load() }Cree un DataFrame con el método definido.
val df = withCatalog(catalog)Luego importa las bibliotecas necesarias para usar el conector de Spark para Azure Cosmos DB.
import com.microsoft.azure.cosmosdb.spark.schema._ import com.microsoft.azure.cosmosdb.spark._ import com.microsoft.azure.cosmosdb.spark.config.ConfigHaga la configuración para escribir datos en Azure Cosmos DB.
val writeConfig = Config(Map( "Endpoint" -> "https://<cosmos-db-account-name>.documents.azure.com:443/", "Masterkey" -> "<comsmos-db-master-key>", "Database" -> "<database-name>", "Collection" -> "<collection-name>", "Upsert" -> "true" ))Escriba datos de DataFrame en Azure Cosmos DB.
import org.apache.spark.sql.SaveMode df.write.mode(SaveMode.Overwrite).cosmosDB(writeConfig)
Escribe en paralelo a gran velocidad, su rendimiento es alto. Por otro lado, tenga en cuenta que puede consumir RU/s en el lado de Azure Cosmos DB.
Phoenix
Phoenix es compatible como origen de datos de Data Factory. Consulte los siguientes documentos para conocer los pasos detallados.
Migración del código
En esta sección se describen las diferencias entre la creación de aplicaciones en Azure Cosmos DB for NoSQL y HBase. Los ejemplos que aquí se presentan utilizan las API de Apache HBase 2.x y Azure Cosmos DB Java SDK v4
Estos códigos de ejemplo de HBase se basan en los descritos en la documentación oficial de HBase.
El código para Azure Cosmos DB que se presenta aquí se basa en la Azure Cosmos DB for NoSQL: documentación de ejemplos de Java SDK v4. Puede obtener acceso al ejemplo de código completo desde la documentación.
Las asignaciones para la migración de código se muestran aquí, pero las claves de partición de HBase y Azure Cosmos DB usadas en estos ejemplos no siempre están bien diseñadas. Diseño según el modelo de datos real del origen de migración.
Establecimiento de la conexión
HBase
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum","zookeepernode0,zookeepernode1,zookeepernode2");
config.set("hbase.zookeeper.property.clientPort", "2181");
config.set("hbase.cluster.distributed", "true");
Connection connection = ConnectionFactory.createConnection(config)
Phoenix
//Use JDBC to get a connection to an HBase cluster
Connection conn = DriverManager.getConnection("jdbc:phoenix:server1,server2:3333",props);
Azure Cosmos DB
// Create sync client
client = new CosmosClientBuilder()
.endpoint(AccountSettings.HOST)
.key(AccountSettings.MASTER_KEY)
.consistencyLevel(ConsistencyLevel.{ConsistencyLevel})
.contentResponseOnWriteEnabled(true)
.buildClient();
Crear base de datos/tabla/colección
HBase
// create an admin object using the config
HBaseAdmin admin = new HBaseAdmin(config);
// create the table...
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("FamilyTable"));
// ... with single column families
tableDescriptor.addFamily(new HColumnDescriptor("ColFam"));
admin.createTable(tableDescriptor);
Phoenix
CREATE IF NOT EXISTS FamilyTable ("id" BIGINT not null primary key, "ColFam"."lastName" VARCHAR(50));
Azure Cosmos DB
// Create database if not exists
CosmosDatabaseResponse databaseResponse = client.createDatabaseIfNotExists(databaseName);
database = client.getDatabase(databaseResponse.getProperties().getId());
// Create container if not exists
CosmosContainerProperties containerProperties = new CosmosContainerProperties("FamilyContainer", "/lastName");
// Provision throughput
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
// Create container with 400 RU/s
CosmosContainerResponse databaseResponse = database.createContainerIfNotExists(containerProperties, throughputProperties);
container = database.getContainer(databaseResponse.getProperties().getId());
Crear fila o documento
HBase
HTable table = new HTable(config, "FamilyTable");
Put put = new Put(Bytes.toBytes(RowKey));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes("1"));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Witherspoon"));
table.put(put)
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Witherspoon’);
Azure Cosmos DB
Azure Cosmos DB proporciona seguridad de tipos mediante el modelo de datos. Se usa el modelo de datos denominado "Familia".
public class Family {
public Family() {
}
public void setId(String id) {
this.id = id;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
private String id="";
private String lastName="";
}
Lo anterior forma parte del código. Consulteejemplo de código completo.
Use la clase Familia para definir documento e insertar elemento.
Family family = new Family();
family.setLastName("Witherspoon");
family.setId("1");
// Insert this item as a document
// Explicitly specifying the /pk value improves performance.
container.createItem(family,new PartitionKey(family.getLastName()),new CosmosItemRequestOptions());
Leer fila o documento
HBase
HTable table = new HTable(config, "FamilyTable");
Get get = new Get(Bytes.toBytes(RowKey));
get.addColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Result result = table.get(get);
byte[] col = result.getValue(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Phoenix
SELECT lastName FROM FamilyTable;
Azure Cosmos DB
// Read document by ID
Family family = container.readItem(documentId,new PartitionKey(documentLastName),Family.class).getItem();
String sql = "SELECT lastName FROM c";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
Actualización de datos
HBase
Para HBase, use el método append y el método checkAndPut para actualizar el valor. append es el proceso de anexar un valor de forma atómica al final del valor actual y checkAndPut compara atómicamente el valor actual con el valor esperado y las actualizaciones solo si coinciden.
// append
HTable table = new HTable(config, "FamilyTable");
Append append = new Append(Bytes.toBytes(RowKey));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes(2));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Harris"));
Result result = table.append(append)
// checkAndPut
byte[] row = Bytes.toBytes(RowKey);
byte[] colfam = Bytes.toBytes("ColFam");
byte[] col = Bytes.toBytes("lastName");
Put put = new Put(row);
put.add(colfam, col, Bytes.toBytes("Patrick"));
boolearn result = table.checkAndPut(row, colfam, col, Bytes.toBytes("Witherspoon"), put);
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Brown’)
ON DUPLICATE KEY UPDATE id = "1", lastName = "Whiterspoon";
Azure Cosmos DB
En Azure Cosmos DB, las actualizaciones se tratan como operaciones de Upsert. Es decir, si el documento no existe, se insertará.
// Replace existing document with new modified document (contingent on modification).
Family family = new Family();
family.setLastName("Brown");
family.setId("1");
CosmosItemResponse<Family> famResp = container.upsertItem(family, new CosmosItemRequestOptions());
Eliminar fila o documento
HBase
En Hbase, no hay ninguna forma de eliminación directa de seleccionar la fila por valor. Es posible que haya implementado el proceso de eliminación en combinación con ValueFilter, etc. En este ejemplo, RowKey especifica la fila que se va a eliminar.
HTable table = new HTable(config, "FamilyTable");
Delete delete = new Delete(Bytes.toBytes(RowKey));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("id"));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
table.dalate(delete)
Phoenix
DELETE FROM TableName WHERE id = "xxx";
Azure Cosmos DB
A continuación se muestra el método de eliminación por id. de documento.
container.deleteItem(documentId, new PartitionKey(documentLastName), new CosmosItemRequestOptions());
Consultar filas o documentos
HBase HBase le permite recuperar varias filas mediante el examen. Puede usar Filtro para especificar condiciones de examen detalladas. Consulte Filtros de solicitud de cliente para tipos de filtro integrados de HBase.
HTable table = new HTable(config, "FamilyTable");
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("ColFam"),
Bytes.toBytes("lastName"), CompareOp.EQUAL, New BinaryComparator(Bytes.toBytes("Witherspoon")));
filter.setFilterIfMissing(true);
filter.setLatestVersionOnly(true);
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
Phoenix
SELECT * FROM FamilyTable WHERE lastName = "Witherspoon"
Azure Cosmos DB
Operación de filtro
String sql = "SELECT * FROM c WHERE c.lastName = 'Witherspoon'";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
Eliminar tabla o colección
HBase
HBaseAdmin admin = new HBaseAdmin(config);
admin.deleteTable("FamilyTable")
Phoenix
DROP TABLE IF EXISTS FamilyTable;
Azure Cosmos DB
CosmosContainerResponse containerResp = database.getContainer("FamilyContainer").delete(new CosmosContainerRequestOptions());
Otras consideraciones
Los clústeres de HBase se pueden usar con cargas de trabajo de HBase y MapReduce, Hive, Spark y muchas más. Si tiene otras cargas de trabajo con su HBase actual, también deben migrarse. Para obtener más información, consulte cada guía de migración.
- MapReduce
- HBase
- Spark
Programación en el lado servidor
HBase ofrece varias características de programación del lado servidor. Si usa estas características, también tendrá que migrar su procesamiento.
HBase
-
Varios filtros están disponibles de forma predeterminada en HBase, pero también puede implementar sus propios filtros personalizados. Los filtros personalizados se pueden implementar si los filtros disponibles de forma predeterminada en HBase no cumplen sus requisitos.
-
El Coprocesador es un marco que le permite ejecutar su propio código en el servidor de región. Con el Coprocesador, es posible realizar el procesamiento que se estaba ejecutó en el lado cliente en el lado del servidor y, dependiendo del procesamiento, se puede hacer más eficiente. Hay dos tipos de Coprocesadores, Observador y Punto de conexión.
Observador
- El observador conecta operaciones y eventos específicos. Esta es una función para agregar procesamiento arbitrario. Esta es una característica similar a los desencadenadores RDBMS.
Punto de conexión
- El punto de conexión es una característica para extender RPC de HBase. Es una función similar a un procedimiento almacenado RDBMS.
Azure Cosmos DB
-
- Los procedimientos almacenados de Azure Cosmos DB se escriben en JavaScript y pueden realizar operaciones como crear, actualizar, leer, consultar y eliminar elementos en los contenedores de Azure Cosmos DB.
-
- Los desencadenadores se pueden especificar para las operaciones de la base de datos. Hay dos métodos proporcionados: un desencadenador previo que se ejecuta antes de que cambie el elemento de base de datos y un desencadenador posterior que se ejecute después de que cambie el elemento de base de datos.
-
- Azure Cosmos DB le permite definir funciones definidas por el usuario (UDF). Las funciones definidas por el usuario pueden escribirse en JavaScript.
Los procedimientos almacenados y los desencadenadores consumen unidades de solicitud según la complejidad de las operaciones realizadas. Al desarrollar el procesamiento del lado servidor, compruebe el uso necesario para obtener una mejor comprensión de la cantidad de RU consumida por cada operación. Consulte Unidades de solicitud en Azure Cosmos DB y Optimizar el coste de las solicitudes en Azure Cosmos DB para más detalles.
Ejemplos de asignación en el servidor
| HBase | Azure Cosmos DB | Descripción |
|---|---|---|
| Filtros personalizados | DONDE cláusula | Si la cláusula WHERE de Azure Cosmos DB no puede lograr el procesamiento implementado por el filtro personalizado, use UDF en combinación. |
| Coprocesador (Observador) | Desencadenador | Observador es un desencadenador que se ejecuta antes y después de un evento en particular. Al igual que Observador admite llamadas previas y posteriores, el desencadenador de Azure Cosmos DB también admite desencadenadores previos y posteriores. |
| Coprocesador (punto de conexión) | Procedimiento almacenado | El punto de conexión es un mecanismo de procesamiento de datos del lado servidor que se ejecuta para cada región. Esto es similar a un procedimiento almacenado RDBMS. Los procedimientos almacenados de Azure Cosmos DB se escriben con JavaScript. Proporciona acceso a todas las operaciones que se pueden realizar en Azure Cosmos DB a través de procedimientos almacenados. |
Nota
Es posible que se necesiten diferentes asignaciones e implementaciones en Azure Cosmos DB en función del procesamiento implementado en HBase.
Seguridad
La seguridad de los datos es una responsabilidad compartida entre el cliente y el proveedor de la base de datos. Para las soluciones locales, los clientes tienen que proporcionar todo, desde protección de punto de conexión hasta seguridad de hardware físico, lo que no es una tarea fácil. Si elige un proveedor de bases de datos en la nube de PaaS como Azure Cosmos DB, la participación del cliente se reducirá. Azure Cosmos DB se ejecuta en la plataforma Azure, por lo que se puede mejorar de una manera diferente a HBase. Azure Cosmos DB no requiere que se instalen componentes adicionales para la seguridad. Le recomendamos que considere la posibilidad de migrar la implementación de seguridad del sistema de base de datos con la siguiente lista de comprobación:
| Control de seguridad | HBase | Azure Cosmos DB |
|---|---|---|
| Seguridad de red y la configuración de firewall | Controle el tráfico mediante funciones de seguridad como dispositivos de red. | Admite el control de acceso basado en políticas de IP en el firewall de entrada. |
| Autenticación de usuarios y controles de usuario muy específicos | Control de acceso preciso combinando LDAP con componentes de seguridad como Apache Ranger. | Puede usar la clave principal de la cuenta para crear recursos de usuario y permisos para cada base de datos. Los tokens de recursos están asociados con permisos en la base de datos para determinar cómo los usuarios pueden obtener acceso a los recursos de la aplicación en la base de datos (lectura/escritura, solo lectura o sin acceso). También puede usar su Microsoft Entra ID para autenticar las solicitudes de datos. Esto le permite autorizar solicitudes de datos con un modelo RBAC de grano fino. |
| Capacidad de replicar datos globalmente en caso de errores regionales | Realice una réplica de base de datos en un centro de datos remoto con la replicación de HBase. | Azure Cosmos DB realiza una distribución global sin configuración y le permite replicar datos en centros de datos de todo el mundo en Azure con la selección de un botón. En términos de seguridad, la replicación global garantiza que los datos estén protegidos contra errores locales. |
| Capacidad de conmutar por error de un centro de datos a otro | Debe implementar la conmutación por error usted mismo. | Si va a replicar datos en varios centros de datos y el centro de datos de la región se desconecta, Azure Cosmos DB se revierte automáticamente sobre la operación. |
| Replicación de datos local dentro de un centro de datos | El mecanismo HDFS le permite tener varias réplicas en nodos dentro de un único sistema de archivos. | Azure Cosmos DB replica automáticamente los datos para mantener una alta disponibilidad, incluso dentro de un único centro de datos. Puede elegir el nivel de coherencia usted mismo. |
| Copias de seguridad de datos automáticas | No hay ninguna función de copia de seguridad automática. Debe implementar la copia de seguridad de datos usted mismo. | Se realizan copias de seguridad de Azure Cosmos DB con regularidad y se guardan en el almacenamiento georedundante. |
| Protección y aislamiento de datos confidenciales | Por ejemplo, si usa Apache Ranger, puede usar la directiva de Ranger para aplicar la directiva a la tabla. | Puede separar datos personales y otros datos confidenciales en contenedores específicos y leer y escribir, o limitar el acceso de solo lectura a usuarios específicos. |
| Supervisión de ataques | Debe implementarse con productos de terceros. | Use los registros de auditoría y los registros de actividad para supervisar la actividad normal y la anómala de su cuenta. |
| Respuesta a alertas | Debe implementarse con productos de terceros. | Cuando se contacta con el soporte técnico de Azure y se informa de un posible ataque, se inicia un proceso de respuesta a incidentes en cinco pasos. |
| Capacidad de aplicar límites geografos a datos para cumplir las restricciones de gobernanza de datos | Debe comprobar las restricciones de cada país o región y llevar a cabo la implementación usted mismo. | Garantiza la gobernanza de datos para regiones soberanas (Alemania, China, USGov., etc.). |
| Protección física de los servidores en centros de datos protegidos | Depende del centro de datos donde se encuentra el sistema. | Para obtener una lista de las certificaciones más recientes, vea el sitio global de cumplimiento de Azure. |
| Certificaciones | Depende de la distribución de Hadoop. | Consulte Documentación del cumplimiento de Azure |
Para obtener más información sobre la seguridad, consulte Seguridad en Azure Cosmos DB - información general
Supervisión
HBase suele supervisar el clúster con la interfaz web de la métrica del clúster o con Ambari, Cloudera Manager u otras herramientas de supervisión. Azure Cosmos DB le permite usar el mecanismo de supervisión integrado en la plataforma de Azure. Para obtener más información sobre la supervisión Azure Cosmos DB, consulte Supervisar Azure Cosmos DB.
Si su entorno implementa la supervisión del sistema HBase para enviar alertas, por ejemplo, por correo electrónico, es posible que pueda reemplazarlo por alertas de Azure Monitor. Puede recibir alertas basadas en métricas o eventos de registro de actividades para su cuenta de Azure Cosmos DB.
Para obtener más información sobre alertas en Azure Monitor, consulte Crear alertas para Azure Cosmos DB con Azure Monitor
También, consulte las métricas de Azure Cosmos DB y los tipos de registro que se pueden recopilar con Azure Monitor.
Copia de seguridad y recuperación de desastres
Backup
Hay varias formas de obtener una copia de seguridad de HBase. Por ejemplo, Instantánea, Exportar, CopyTable, Copia de seguridad sin conexión de datos HDFS y otras copias de seguridad personalizadas.
Azure Cosmos DB realiza automáticamente copias de seguridad de los datos a intervalos periódicos, lo que no afecta al rendimiento ni a la disponibilidad de las operaciones de base de datos. Las copias de seguridad se almacenan en Azure Storage y se pueden usar para recuperar datos si es necesario. Hay dos tipos de copias de seguridad de Azure Cosmos DB:
Recuperación ante desastres
HBase es un sistema distribuido con tolerancia a fallos, pero hay que implementar la recuperación de desastres con el uso de instantáneas, la replicación, etc. cuando se requiere la conmutación por error en la ubicación de copia de seguridad en el caso de un fallo a nivel de centro de datos. La replicación de HBase puede configurarse con tres modelos de replicación: Leader-Follower, Leader-Leader y Cyclic. Si el HBase de origen implementa la Recuperación de Desastres, necesitas entender cómo puedes configurar la Recuperación de Desastres en Azure Cosmos DB y cumplir con los requisitos de tu sistema.
Azure Cosmos DB es una base de datos distribuida globalmente con capacidades integradas de recuperación de desastres. Puede replicar los datos de base de datos en cualquier región de Azure. Azure Cosmos DB mantiene la base de datos altamente disponible en el caso poco probable de un error en algunas regiones.
La cuenta de Azure Cosmos DB que utiliza una sola región puede perder disponibilidad en caso de error de la región. Le recomendamos que configure al menos dos regiones para garantizar siempre una alta disponibilidad. También puede garantizar una alta disponibilidad para las escrituras y las lecturas configurando su cuenta de base de datos de Azure Cosmos para que abarque al menos dos regiones con varias regiones de escritura para garantizar una alta disponibilidad para las escrituras y lecturas. En el caso de las cuentas multirregión que constan de varias regiones de escritura, el cliente Azure Cosmos DB detecta y administra la conmutación por error entre regiones. Estos son momentáneos y no requieren ningún cambio de la aplicación. De este modo, puede conseguir una configuración de disponibilidad que incluya recuperación ante desastres para Azure Cosmos DB. Como se mencionó anteriormente, la replicación de HBase se puede configurar con tres modelos, pero Azure Cosmos DB se puede configurar con disponibilidad basada en SLA configurando regiones de escritura única y de varias escrituras.
Para obtener más información sobre alta disponibilidad, consulte ¿Cómo proporciona Azure Cosmos DB alta disponibilidad?
Preguntas más frecuentes
¿Por qué migrar a la API para NoSQL en lugar de otras API en Azure Cosmos DB?
La API para NoSQL proporciona la mejor experiencia de un extremo a otro en términos de interfaz, biblioteca de cliente de SDK de servicio. Las nuevas características que se han lanzado a Azure Cosmos DB estarán disponibles primero en su cuenta de la API para NoSQL. Además, la API para NoSQL es compatible con la analítica y proporciona una separación de rendimiento entre las cargas de trabajo de producción y las analíticas. Si desea utilizar las tecnologías modernizadas para crear aplicaciones, la API para NoSQL es la opción recomendada.
¿Puedo asignar la RowKey de HBase a la clave de partición de Azure Cosmos DB?
Es posible que no esté optimizada tal como está. En HBase, los datos se ordenan por la RowKey especificada, se almacenan en la región y se dividen en tamaños fijos. Esto se comporta de manera diferente a la partición en Azure Cosmos DB. Por lo tanto, es necesario rediseñar las claves para distribuir mejor los datos según las características de la carga de trabajo. Consulte la sección de distribución para obtener más detalles.
Los datos se ordenan por RowKey en HBase, pero se particionan por clave en Azure Cosmos DB. ¿Cómo Azure Cosmos DB lograr la ordenación y la colocación?
En Azure Cosmos DB, puede agregar un índice compuesto para ordenar los datos en orden ascendente o descendente para mejorar el rendimiento de las consultas de rango y igualdad. Consulte la sección de distribución y el índice compuesto en la documentación del producto.
El procesamiento analítico se ejecuta en datos de HBase con Hive o Spark. ¿Cómo puedo modernizarlos en Azure Cosmos DB?
Puede utilizar el almacén analítico de Azure Cosmos DB para sincronizar automáticamente los datos operativos con otro almacén de columnas. El formato de almacén de columnas es adecuado para consultas analíticas de gran tamaño que se ejecutan de forma optimizada, lo que mejora la latencia de dichas consultas. Azure Synapse Link le permite crear una solución HTAP sin ETL vinculando directamente desde Azure Synapse Analytics al almacén analítico de Azure Cosmos DB. Esto le permite realizar análisis a gran escala y casi en tiempo real de los datos operativos. Synapse Analytics es compatible con Apache Spark y con grupos de SQL sin servidor en el almacén de análisis de Azure Cosmos DB. Puede aprovechar esta función para migrar su procesamiento analítico. Consulte el almacén analítico para obtener más información.
¿Cómo pueden los usuarios utilizar la consulta de marca de tiempo de HBase en Azure Cosmos DB?
Azure Cosmos DB no tiene exactamente la misma función de control de versiones de marca de tiempo que HBase. Pero Azure Cosmos DB proporciona la capacidad de obtener acceso a la fuente de cambios y puede utilizarla para el control de versiones.
Almacene cada versión o cambio como un elemento independiente.
Lea la fuente de cambios para fusionar o consolidar los cambios y desencadenar las acciones apropiadas en sentido descendente filtrando con el campo "_ts". Además, para la versión antigua de datos, puede expirar versiones anteriores con TTL.
Pasos siguientes
Para realizar pruebas de rendimiento, vea el artículo Pruebas de escala y rendimiento con Azure Cosmos DB.
Para optimizar el código, vea el artículo Sugerencias de rendimiento para Azure Cosmos DB.
Para examinar el SDK de Java asincrónico versión 3, vea el repositorio de GitHub Referencia de SDK.