Ingesta de datos de Azure Stream Analytics en Azure Data Explorer
Importante
Este conector se puede usar en Inteligencia en tiempo real en Microsoft Fabric. Use las instrucciones de este artículo con las siguientes excepciones:
- Si es necesario, cree bases de datos con las instrucciones de Creación de una base de datos KQL.
- Si es necesario, cree tablas con las instrucciones de Creación de una tabla vacía.
- Obtenga los URI de consulta o ingesta mediante las instrucciones del URI de copia.
- Ejecutar consultas en un conjunto de consultas KQL.
Azure Data Explorer admite la ingesta de datos desde Azure Stream Analytics. Azure Stream Analytics es un motor de procesamiento de eventos complejos y de análisis en tiempo real que está diseñado para analizar y procesar grandes volúmenes de datos de streaming rápido de varios orígenes de manera simultánea.
Un trabajo de Azure Stream Analytics consta de un origen de entrada, una consulta de transformación y una conexión de salida. Puede crear, editar y probar trabajos de Stream Analytics mediante Azure Portal, plantillas de Azure Resource Manager (ARM), Azure PowerShell, API de .NET, API REST, Visual Studio y Stream Analytics sin editor de código.
En este artículo, aprenderá a usar un trabajo de Stream Analytics para recopilar datos de un centro de eventos y enviarlos al clúster de Azure Data Explorer mediante Azure Portal o una plantilla de ARM.
Requisitos previos
Cree un clúster y una base de datos, y una tabla.
Cree un centro de eventos mediante las secciones siguientes del tutorial de Azure Stream Analytics:
- Creación de un centro de eventos
- Concesión de acceso al centro de eventos y obtención de un cadena de conexión
Sugerencia
Para las pruebas, se recomienda descargar la aplicación de generación de eventos de llamada telefónica del Centro de descarga de Microsoft u obtener el código fuente de GitHub. Al configurar el trabajo de Azure Stream Analytics, lo configurará para extraer datos del centro de eventos y pasarlos al conector de salida de Azure Data Explorer.
Creación de una conexión de salida de Azure Data Explorer
Siga estos pasos para crear una salida de Azure Data Explorer para un trabajo de Stream Analytics mediante Azure Portal o mediante una plantilla de ARM. El trabajo de Stream Analytics usa la conexión para enviar datos a una tabla de Azure Data Explorer especificada. Una vez creado y ejecutándose el trabajo, los datos que fluyen al trabajo se ingieren en la tabla de destino especificada.
Importante
- El conector de salida de Azure Data Explorer solo admite la autenticación de identidad administrada. Como parte de la creación del conector, se conceden permisos de supervisor de base de datos y de agente de ingesta de base de datos a la identidad administrada del trabajo de Azure Stream Analytics.
- Al configurar el conector de salida de Azure Data Explorer, especifique el nombre de la tabla, la base de datos y el clúster de destino. Para que la ingesta se realice correctamente, todas las columnas definidas en la consulta de Azure Stream Analytics deben coincidir con los nombres y tipos de columna de la tabla de Azure Data Explorer. Los nombres de columna distinguen mayúsculas de minúsculas y pueden estar en cualquier orden. Si hay columnas en la consulta de Azure Stream Analytics que no se asignan a columnas de la tabla de Azure Data Explorer, se genera un error.
Nota:
- Se admiten todas las entradas de Azure Stream Analytics. El conector transforma las entradas en formato CSV y, a continuación, importa los datos en la tabla de Azure Data Explorer especificada.
- Azure Data Explorer tiene una directiva de agregación (procesamiento por lotes) para la ingesta de datos diseñada para optimizar dicho proceso. De manera predeterminada, la directiva está configurada en 5 minutos, 1000 elementos o 1 GB de datos, por lo que puede experimentar una latencia. Para obtener información sobre cómo configurar las opciones de agregación, consulte Directiva IngestionBatching.
Antes de empezar, asegúrese de que tiene un trabajo de Stream Analytics existente o cree uno nuevo y, a continuación, siga estos pasos para crear la conexión de Azure Data Explorer.
Inicie sesión en Azure Portal.
En Azure Portal, abra Todos los recursos y seleccione el trabajo de Stream Analytics.
En Topología de trabajo, seleccione la opción Salidas.
Seleccione Agregar>Azure Data Explorer.
Rellene el formulario de salida con la siguiente información y, después, seleccione Guardar.
Nota:
Puede utilizar las siguientes opciones para especificar el clúster y la base de datos:
- Suscripción: seleccione Select Azure Data Explorer from your subscriptions (Seleccionar Azure Data Explorer de las suscripciones), seleccione la suscripción y, después, elija el clúster y la base de datos.
- Manualmente: seleccione Provide Azure Data Explorer settings manually (Proporcionar la configuración de Azure Data Explorer manualmente), especifique el identificador URI del clúster y la base de datos.
Nombre de propiedad Descripción Alias de salida Un nombre descriptivo usado en las consultas para dirigir la salida de la consulta a esta base de datos. Subscription Seleccione la suscripción de Azure donde reside el clúster. Clúster Nombre único que identifica al clúster. El nombre de dominio [region].kusto.windows.net se anexa al nombre del clúster que proporcione. El nombre solo puede contener letras minúsculas y números. Tiene que contener entre 4 y 22 caracteres. URI del clúster Identificador URI de ingesta de datos del clúster. Puede especificar el identificador URI de los puntos de conexión de ingesta de datos de Azure Data Explorer o el explorador de datos de Azure Synapse. Base de datos Nombre de la base de datos adonde envía la salida. El nombre de la base de datos debe ser único dentro del clúster. Authentication Una identidad administrada de Microsoft Entra que permite al clúster acceder fácilmente a otros recursos protegidos de Microsoft Entra. La plataforma Azure administra la identidad y no es necesario que lleve a cabo el aprovisionamiento ni la rotación de los secretos. La configuración de la identidad administrada le permite usar claves administradas por el cliente para el clúster. Tabla Nombre de la tabla a la que se envía la salida. Los nombres de columna y los tipos de datos de la salida de Azure Stream Analytics deben coincidir con el esquema de la tabla de Azure Data Explorer. 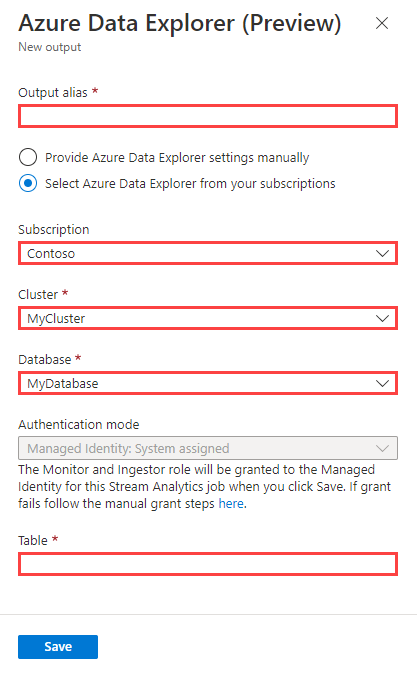
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de