Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Si no está familiarizado con Azure Data Factory, consulte Introducción a Azure Data Factory.
En este tutorial, usará el lienzo del flujo de datos para crear flujos de datos que le permitan analizar y transformar datos en Azure Data Lake Storage (ADLS) Gen2 y almacenarlos en Delta Lake.
Requisitos previos
- Suscripción de Azure. Si no tiene una suscripción de Azure, cree un cuenta de Azure gratuita antes de comenzar.
- Cuenta de almacenamiento de Azure. El almacenamiento ADLS se puede usar como almacén de datos de origen y receptor. Si no tiene una cuenta de almacenamiento, consulte Crear una cuenta de almacenamiento de Azure para ver los pasos para crear una.
El archivo que se está transformando en este tutorial es MoviesDB. csv, que se puede encontrar aquí. Para recuperar el archivo de GitHub, copie el contenido en un editor de texto de su elección para guardarlo localmente como un archivo .csv. Para cargar el archivo en la cuenta de almacenamiento, consulte Upload blobs con el portal de Azure. Los ejemplos hacen referencia a un contenedor denominado "sample-data".
Crear una factoría de datos
En este paso, creará una factoría de datos y abrirá la interfaz de usuario de Data Factory para crear una canalización en la factoría de datos.
Abra Microsoft Edge o Google Chrome. Actualmente, la interfaz de usuario de Data Factory solo se admite en los exploradores web de Microsoft Edge y Google Chrome.
En el menú de la izquierda, seleccione Crear un recurso>Integración>Data Factory.
En la página Nueva factoría de datos, en Nombre, escriba ADFTutorialDataFactory.
Seleccione el Azure subscription en el que desea crear la factoría de datos.
Para Grupo de recursos, realice uno de los siguientes pasos:
a) Seleccione Usar existente, y después seleccione un grupo de recursos de la lista desplegable.
b. Seleccione Crear nuevoy escriba el nombre de un grupo de recursos.
Para obtener información sobre los grupos de recursos, consulte Use grupos de recursos para administrar los recursos de Azure.
En Versión, seleccione V2.
En Ubicación, seleccione la ubicación de la factoría de datos. En la lista desplegable solo se muestran las ubicaciones que se admiten. Los almacenes de datos (por ejemplo, Azure Storage y SQL Database) y los procesos (por ejemplo, Azure HDInsight) usados por la factoría de datos pueden estar en otras regiones.
Seleccione Crear.
Una vez finalizada la creación, verá el aviso en el centro de notificaciones. Seleccione Ir al recurso para ir a la página de Data Factory.
Seleccione Author & Monitor para iniciar la interfaz de usuario de Data Factory en una pestaña independiente.
Crear una canalización con una actividad de flujo de datos
En este paso, crea una canalización que contiene una actividad de flujo de datos.
En la página principal, seleccione Orchestrate.
En la pestaña General de la canalización, escriba DeltaLake en el campo Nombre de la canalización.
En el panel Actividades expanda el acordeón Movimiento y transformación. Arrastre y coloque la actividad Data Flow del panel al lienzo de la canalización.
En la barra superior del lienzo de la canalización, mueva el control deslizante Depuración de flujo de datos a la posición de activado. El modo de depuración permite realizar pruebas interactivas de la lógica de transformación en un clúster de Spark activo. Los clústeres de Data Flow tardan entre 5 y 7 minutos en prepararse y se recomienda a los usuarios que activen primero la depuración si planean realizar desarrollo de Data Flow. Para más información, consulte Modo de depuración.
Construir la lógica de transformación en el lienzo de flujo de datos
En este tutorial se generarán dos flujos de datos. El primer flujo de datos es un origen simple de receptor para generar una nueva instancia de Delta Lake a partir del archivo CSV de películas. Por último, cree el diseño de flujo siguiente para actualizar los datos en Delta Lake.

Objetivos del tutorial
- Use el origen del conjunto de datos MoviesCSV de los requisitos previos y forme una nueva instancia de Delta Lake a partir de él.
- Desarrolle la lógica para actualizar las calificaciones de las películas de 1988 a '1'.
- Elimine todas las películas de 1950.
- Introduzca nuevas películas de 2021 duplicando las de 1960.
Comenzar con un lienzo de flujo de datos en blanco
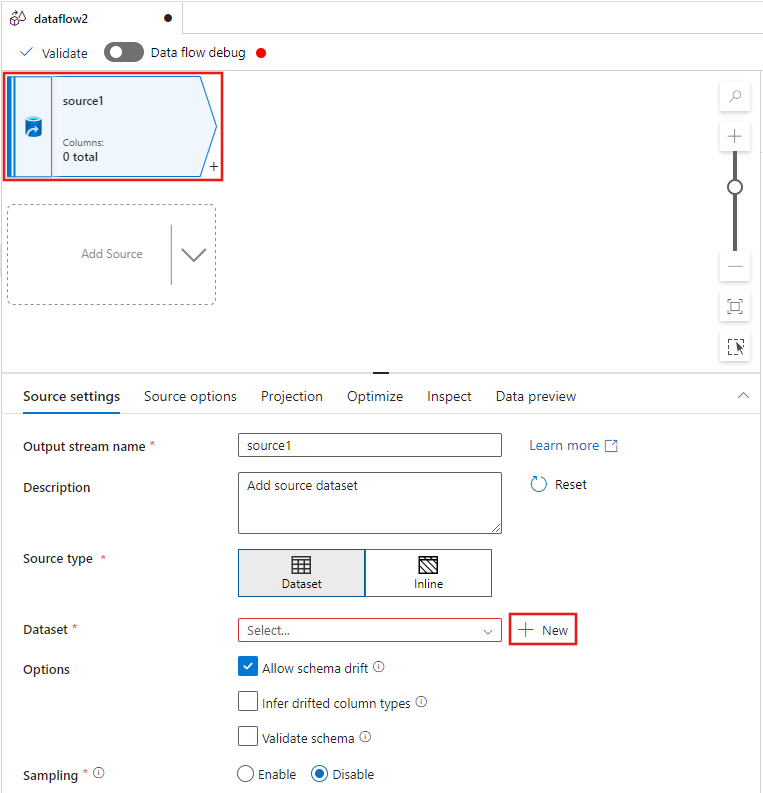
Seleccione la transformación de origen en la parte superior de la ventana del editor de flujo de datos y, a continuación, seleccione + Nuevo junto a la propiedad Conjunto de datos en la ventana Configuración de origen:
Seleccione Azure Data Lake Storage Gen2 en la ventana Nuevo conjunto de datos que aparece y seleccione Continue.
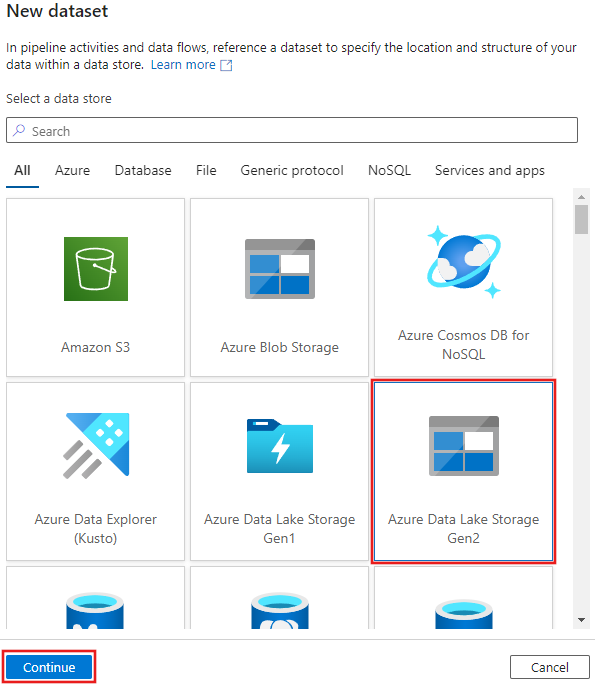
Elija DelimitedText para el tipo de conjunto de datos y seleccione Continuar de nuevo.

Asigne al conjunto de datos el nombre "MoviesCSV" y seleccione + Nuevo en Servicio vinculado para crear un nuevo servicio vinculado al archivo.
Proporcione los detalles de la cuenta de almacenamiento creada anteriormente en la sección Requisitos previos, y busque y seleccione el archivo MoviesCSV que cargó allí.
Después de agregar el servicio vinculado, active la casilla Primera fila como encabezado y, a continuación, seleccione Aceptar para agregar el origen.
Vaya a la pestaña Proyección de la ventana de configuración del flujo de datos y, a continuación, seleccione Detectar tipos de datos.
Ahora seleccione + después del origen en la ventana del editor de flujo de datos y desplácese hacia abajo para seleccionar Receptor en la sección Destino, agregando un nuevo receptor al flujo de datos.
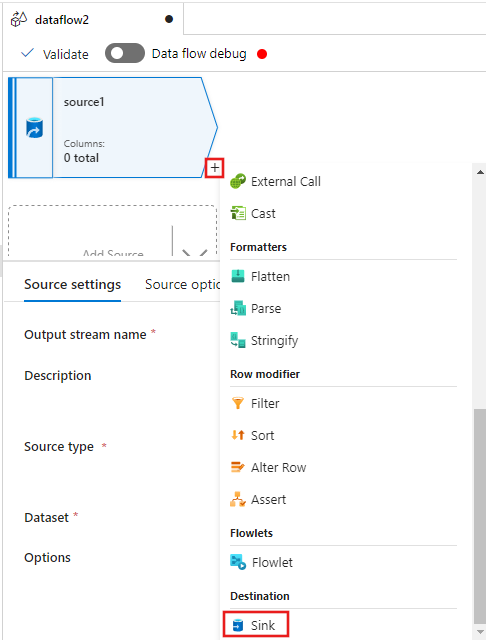
En la pestaña Receptor de la configuración del receptor que aparece después de agregar el receptor, seleccione Insertado para el Tipo de receptor y, a continuación, Delta para el Tipo de conjunto de datos insertado. A continuación, seleccione el Azure Data Lake Storage Gen2 para el servicio Linked.
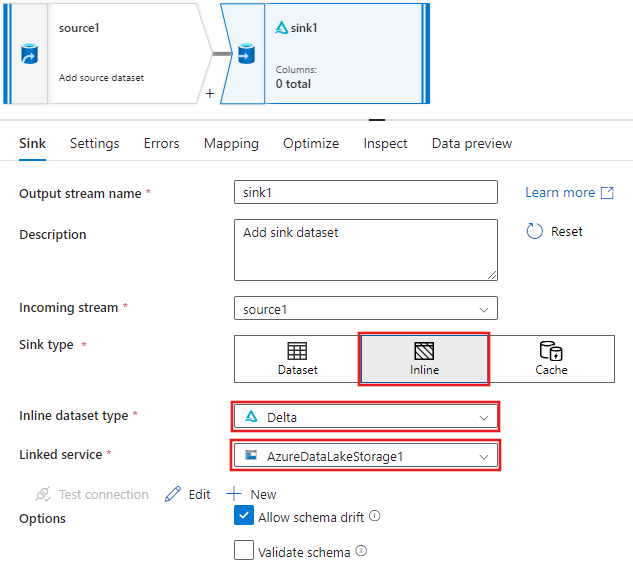
Elija un nombre de carpeta en el contenedor de almacenamiento donde desea que el servicio cree la instancia de Delta Lake.
Finalmente, vuelva al diseñador de canalizaciones y seleccione Depurar para ejecutar la canalización en modo de depuración solo con esta actividad de flujo de datos en el lienzo. Esto genera el nuevo Delta Lake en Azure Data Lake Storage Gen2.
Ahora, en el menú Recursos de fábrica de la izquierda de la pantalla, seleccione + para agregar un nuevo recurso y, a continuación, seleccione Flujo de datos.
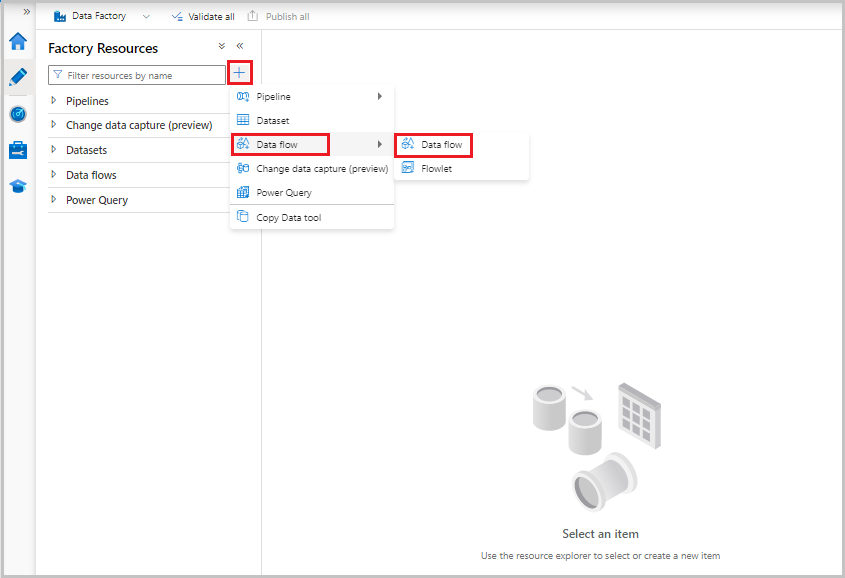
Como antes, vuelva a seleccionar el archivo MoviesCSV como origen y, a continuación, seleccione Detectar tipos de datos de nuevo en la pestaña Proyección.
Esta vez, después de crear el origen, seleccione + en la ventana del editor de flujo de datos y agregue una transformación de filtro al origen.
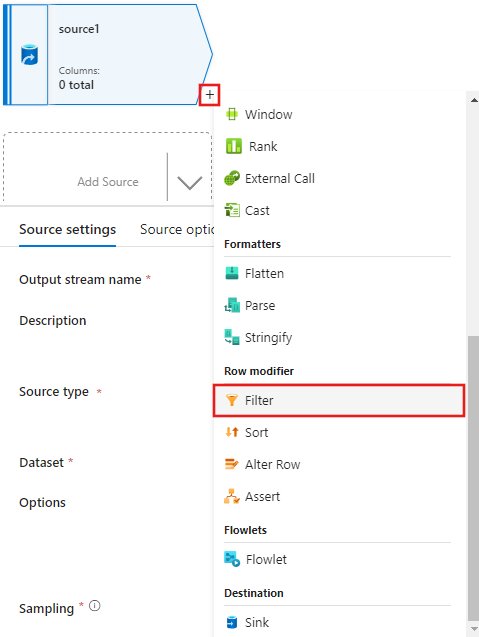
Agregue una condición Filtrar en en la ventana Configuración de filtro que solo permita que las filas de películas coincidan con 1950, 1960 y 1988.
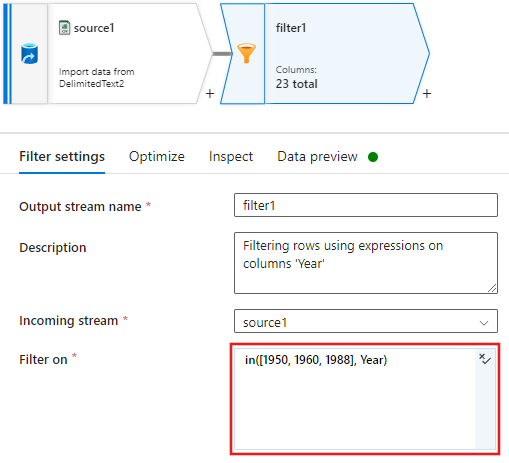
Ahora, agregue una transformación Columna derivada para actualizar a '1' las clasificaciones de cada película de 1988.
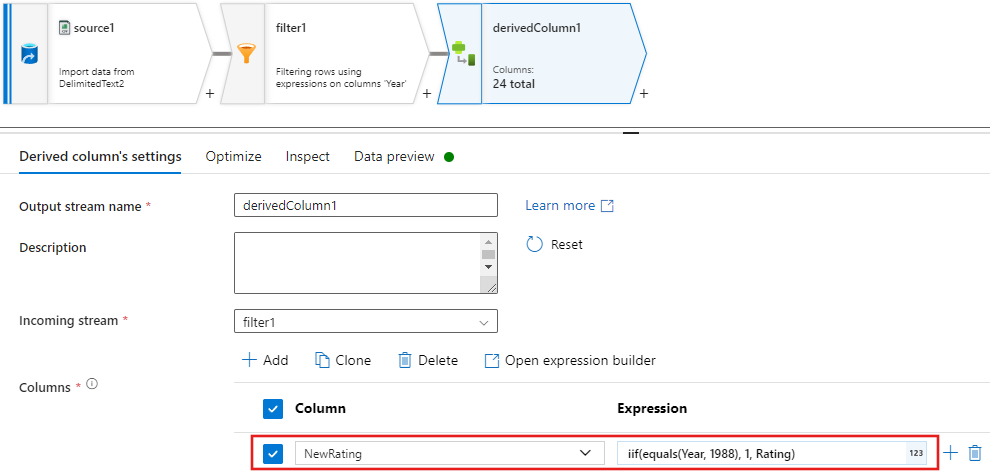
Las directivas
Update, insert, delete, and upsertse crean en la transformación de alteración de fila. Agregue una transformación de alteración de fila después de la columna derivada.Las directivas de alteración de fila deben tener este aspecto.

Ahora que ha establecido la directiva adecuada para cada tipo de fila de alteración, compruebe que se hayan establecido las reglas de actualización adecuadas en la transformación de receptor.
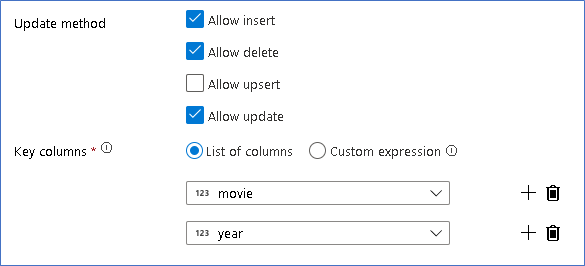
Aquí se usa el receptor de Delta Lake en el lago de datos de Azure Data Lake Storage Gen2 y se permiten inserciones, actualizaciones y eliminaciones.
Observe que las columnas de clave son una clave compuesta formada por la columna de clave principal "movie" y la columna "year". Esto se debe a que hemos creado películas de 2021 falsas mediante la duplicación de las filas de 1960. Esto evita las colisiones, ya que proporciona unicidad al consultar las filas existentes.
Descarga del ejemplo completado
Esta es una solución de ejemplo para la canalización Delta con un flujo de datos para actualizar o eliminar filas en el lago.
Contenido relacionado
Obtenga más información sobre el lenguaje de expresiones de flujo de datos.