Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga más información sobre cómo iniciar una nueva evaluación gratuita.
A menudo, al procesar datos para trabajos ETL, necesitarás cambiar los nombres de columna antes de escribir los resultados. A veces, esto es necesario para alinear los nombres de columna con un esquema de destino conocido. En otras ocasiones, es posible que tenga que establecer nombres de columna en tiempo de ejecución en función de los esquemas en constante evolución. En este tutorial, aprenderá a usar flujos de datos para establecer nombres de columna para los archivos de destino y las tablas de base de datos dinámicamente mediante parámetros y archivos de configuración externos.
Si no está familiarizado con Azure Data Factory, consulte Introducción a Azure Data Factory.
Requisitos previos
- Suscripción de Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita de Azure antes de empezar.
- Cuenta de Azure Storage. El almacenamiento ADLS se puede usar como almacén de datos de origen y receptor. Si no tiene una cuenta de almacenamiento, consulte Crear una cuenta de almacenamiento de Azure para ver los pasos para crear una.
Crear una factoría de datos
En este paso, creará una factoría de datos y abrirá la interfaz de usuario de Data Factory para crear una canalización en la factoría de datos.
- Abra Microsoft Edge o Google Chrome. Actualmente, la interfaz de usuario de Data Factory solo se admite en los exploradores web Microsoft Edge y Google Chrome.
- En el menú de la izquierda, seleccione Crear un recurso>Integración>Data Factory.
- En la página Nueva factoría de datos, en Nombre, escriba ADFTutorialDataFactory.
- Seleccione la suscripción de Azure en la que quiere crear la factoría de datos.
- Para Grupo de recursos, realice uno de los siguientes pasos:
- Seleccione Usar existente, y después seleccione un grupo de recursos existente de la lista desplegable.
- Seleccione Crear nuevo y especifique un nombre de grupo de recursos. Para obtener más información sobre los grupos de recursos, consulte Uso de grupos de recursos para administrar los recursos de Azure.
- En Versión, seleccione V2.
- En Ubicación, seleccione la ubicación de la factoría de datos. En la lista desplegable solo se muestran las ubicaciones que se admiten. Los almacenes de datos (por ejemplo, Azure Storage y SQL Database) y los procesos (por ejemplo, Azure HDInsight) que la factoría de datos usa pueden estar en otras regiones.
- Seleccione Crear.
- Una vez finalizada la creación, verá el aviso en el centro de notificaciones. Seleccione Ir al recurso para ir a la página de Data Factory.
- Seleccione Author & Monitor para iniciar la interfaz de usuario de Data Factory en una pestaña independiente.
Creación de una canalización con una actividad de flujo de datos
En este paso, creará una canalización que contiene una actividad de flujo de datos.
En la página principal de ADF, seleccione Crear canalización.
En la pestaña General de la canalización, escriba DeltaLake en el campo Nombre de la canalización.
En la barra superior de Data Factory, deslice el control deslizante Depuración de Data Flow para activarlo. El modo de depuración permite realizar pruebas interactivas de la lógica de transformación en un clúster de Spark activo. Los clústeres de Data Flow tardan de 5 a 7 minutos en prepararse y se recomienda que los usuarios activen primero la depuración si planean realizar el desarrollo de Data Flow. Para más información, consulte Modo de depuración.
En el panel Actividades expanda el acordeón Movimiento y transformación. Arrastre y coloque la actividad Data Flow del panel al lienzo de la canalización.
En el menú emergente Adding Data Flow (Agregar Data Flow), seleccione Create New Data Flow (Crear Data Flow) y, después, asigne el nombre DynaCols al flujo de datos. Seleccione Finalizar cuando haya terminado.
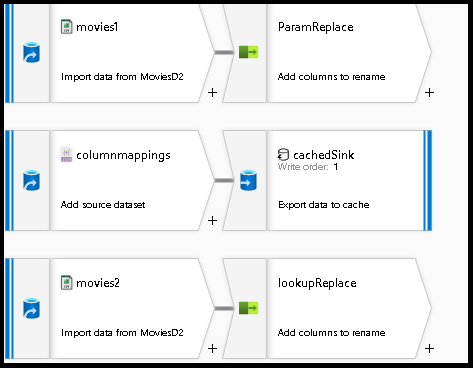
Creación de asignaciones de columnas dinámicas en flujos de datos
En este tutorial, se usará un archivo de clasificación de películas de ejemplo y se modificará el nombre de algunos de los campos del origen a un nuevo conjunto de columnas de destino que pueden cambiar con el tiempo. Los conjuntos de datos que creará a continuación deben apuntar a este archivo CSV de películas en la cuenta de almacenamiento de Blob Storage o ADLS Gen2. Descargue el archivo de películas aquí y guárdelo en la cuenta de almacenamiento de Azure.
Objetivos del tutorial
Aprenderá a establecer dinámicamente nombres de columna mediante un flujo de datos.
- Cree un conjunto de datos de origen para el archivo CSV de películas.
- Creará un conjunto de datos de búsqueda para un archivo de configuración JSON de asignación de campos.
- Convertirá las columnas del origen a los nombres de las columnas de destino.
Comenzar con un lienzo de flujo de datos en blanco
En primer lugar, se configurará el entorno de flujo de datos para cada uno de los mecanismos que se describen a continuación para enviar datos a ADLS Gen2.
Seleccione la transformación de origen y asígnele el nombre
movies1.Seleccione el botón Nuevo situado junto al conjunto de datos en el panel inferior.
Elija Blob o ADLS Gen2, en función de dónde haya almacenado el archivo moviesDB.csv anterior.
Agregue una segunda fuente, que utilizaremos para referenciar el archivo JSON de configuración y consultar las asignaciones de campos.
Asígnele el nombre
columnmappings.Para el conjunto de datos, apunte a un nuevo archivo JSON que almacenará una configuración para la asignación de columnas. Puede pegar el contenido dentro del archivo JSON para este ejemplo de tutorial.
[ {"prevcolumn":"title","newcolumn":"movietitle"}, {"prevcolumn":"year","newcolumn":"releaseyear"} ]Establezca esta configuración de origen en
array of documents.Agregue un tercer origen y asígnele el nombre
movies2. Configure esto exactamente igual quemovies1.
Mapeo de columnas parametrizado
En este primer escenario, definirá nombres de columna de salida en el flujo de datos mediante el establecimiento de la asignación de columnas en función de la coincidencia de campos entrantes con un parámetro que es una matriz de cadenas de columnas y hará coincidir cada índice de matriz con la posición ordinal de la columna entrante. Al ejecutar este flujo de datos desde una canalización, podrá establecer nombres de columna diferentes en cada ejecución de canalización mediante el envío de este parámetro de matriz de cadenas a la actividad de flujo de datos.
Vuelva al diseñador de flujo de datos y modifique el flujo de datos creado anteriormente.
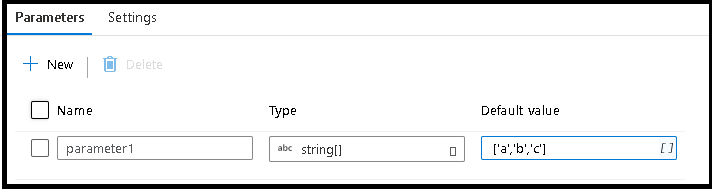
Seleccione la pestaña Parámetros
Cree un parámetro y elija el tipo de datos de la matriz de cadenas.
Para el valor predeterminado, escriba
['a','b','c'].Use el origen
movies1superior para modificar los nombres de columna y asignarlos a estos valores de matriz.Agregue una transformación Select (Seleccionar). La transformación Select se usará para asignar columnas entrantes a nuevos nombres de columna de salida.
Se cambiarán los tres primeros nombres de columna por los nuevos nombres definidos en el parámetro
Para ello, agregue tres entradas de asignación basadas en reglas en el panel inferior
Para la primera columna, la regla de coincidencia será
position==1y el nombre será$parameter1[1].Siga el mismo patrón para las columnas 2 y 3.
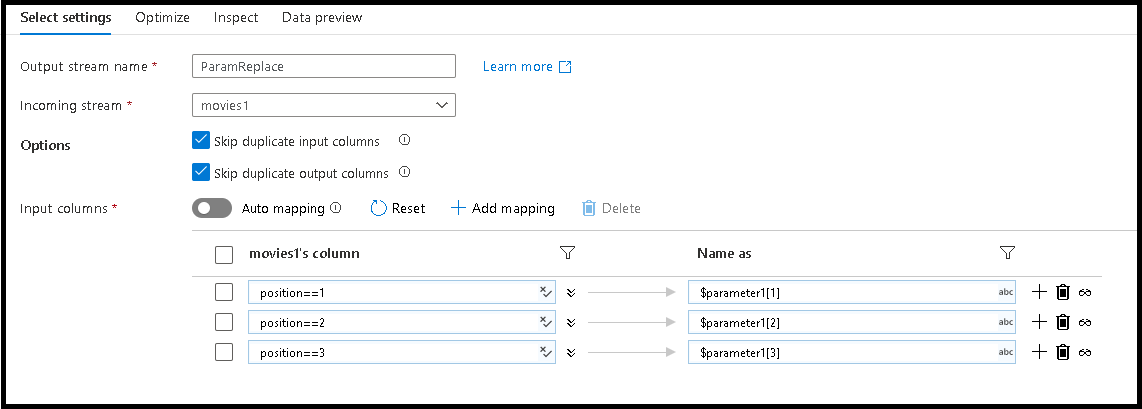
Seleccione las pestañas Inspeccionar y Vista previa de datos de la transformación Seleccionar para ver que los nuevos valores de nombre de columna
(a,b,c)reemplazan a los nombres de columna de películas, títulos y géneros originales
Creación de una búsqueda en caché de asignaciones de columnas externas
A continuación, se creará un receptor en caché para una búsqueda posterior. La caché leerá un archivo de configuración JSON externo que se puede usar para cambiar el nombre de las columnas dinámicamente en cada ejecución de canalización del flujo de datos.
- Vuelva al diseñador de flujo de datos y modifique el flujo de datos creado anteriormente. Agregue una transformación de receptor al origen
columnmappings. - Establezca el tipo de receptor en
Cache. - En Configuración, elija
prevcolumncomo columna de clave.
Búsqueda de nombres de columnas desde el receptor en caché
Ahora que ha almacenado el contenido del archivo de configuración en memoria, puede asignar dinámicamente nombres de columna entrantes a nuevos nombres de columna salientes.
- Vuelva al diseñador del flujo de datos y modifique el flujo de datos creado anteriormente. Seleccione la transformación de origen
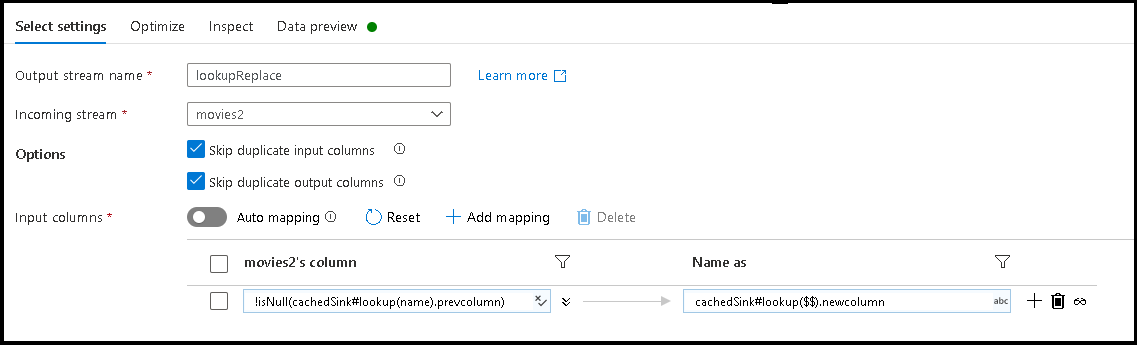
movies2. - Agregue una transformación Select (Seleccionar). Esta vez, se usará la transformación Select (Seleccionar) para cambiar el nombre de las columnas según el nombre de destino del archivo de configuración JSON que se almacena en el receptor en caché.
- Agregue una asignación basada en reglas. Para la condición de coincidencia, use esta fórmula:
!isNull(cachedSink#lookup(name).prevcolumn). - Para el nombre de la columna de salida, use esta fórmula:
cachedSink#lookup($$).newcolumn. - Lo que ha hecho es buscar todos los nombres de columna que coincidan con la propiedad
prevcolumndel archivo de configuración JSON externo y cambiar el nombre de cada coincidencia al nuevo nombrenewcolumn. - Seleccione las pestañas Vista previa de datos e Inspeccionar de la transformación Seleccionar; ahora debería ver los nuevos nombres de columna del archivo de asignación externa.
Contenido relacionado
- La canalización completa de este tutorial se puede descargar aquí
- Más información sobre los receptores de flujo de datos.