Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Los flujos de datos están disponibles tanto en canalizaciones de Azure Data Factory como en canalizaciones de Azure Synapse Analytics. Este artículo se aplica a los flujos de datos de asignación. Si no está familiarizado con las transformaciones, consulte el artículo introductorio Transformar datos mediante flujos de datos de asignación.
Cuando termine de transformar los datos, escríbalos en un almacén de destino mediante la transformación del receptor. Cada flujo de datos requiere al menos una transformación de receptor, pero puede agregar tantos receptores como sea necesario para completar el flujo de transformación. Para escribir en receptores adicionales, cree nuevas secuencias a través de nuevas ramas y divisiones condicionales.
Cada transformación de receptor se asocia exactamente con un objeto de conjunto de datos o servicio vinculado. La transformación del receptor determina la forma y la ubicación de los datos en los que se desea escribir.
Conjuntos de datos insertado
Al crear una transformación de receptor, elija si la información del receptor se define dentro de un objeto de conjunto de datos o en la transformación. La mayoría de los formatos están disponibles solo en una opción o en la otra. Para obtener información sobre cómo usar un conector específico, consulte el documento adecuado del conector.
Cuando un formato se admita tanto en la opción en línea como en un objeto de conjunto de datos, existen ventajas para ambos. Los objetos de conjunto de datos son entidades reutilizables que se pueden usar en otros flujos de datos y actividades, como en la copia. Estas entidades reutilizables son especialmente útiles cuando se usa un esquema protegido. Los conjuntos de datos no se basan en Spark. En ocasiones, es posible que necesite reemplazar determinados valores o la proyección del esquema en la transformación del receptor.
Se recomiendan los conjuntos de datos insertados cuando se usan esquemas flexibles, instancias de receptor único u receptores con parámetros. Si el receptor contiene muchos parámetros, los conjuntos de datos insertados permiten no crear un objeto "ficticio". Los conjuntos de datos insertados se basan en Spark y sus propiedades son nativas para el flujo de datos.
Para usar un conjunto de datos insertado, seleccione el formato que desee en el selector Tipo de receptor. En lugar de seleccionar un conjunto de datos de receptor, seleccione el servicio vinculado al que desee conectarse.
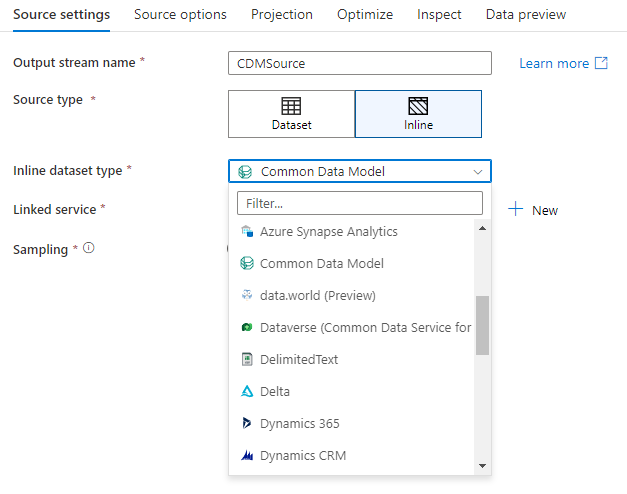
Base de datos del área de trabajo (solo áreas de trabajo de Synapse)
Al usar flujos de datos en áreas de trabajo de Azure Synapse, tendrá una opción adicional para recibir los datos directamente en un tipo de base de datos que se encuentra dentro del área de trabajo de Synapse. Esto mitigará la necesidad de agregar servicios o conjuntos de datos vinculados para esas bases de datos. Las bases de datos creadas mediante las plantillas de base de datos de Azure Synapse también son accesibles al seleccionar Base de datos del área de trabajo.
Nota
El conector Workspace DB de Azure Synapse está actualmente en versión preliminar pública y, en este momento, solo puede funcionar con bases de datos de Spark Lake.
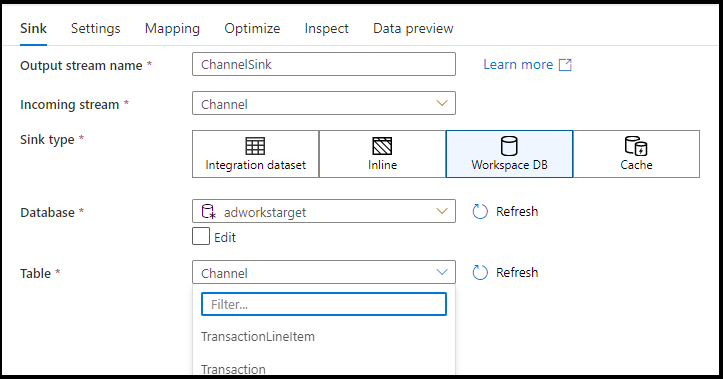
Tipos de receptores admitidos
El flujo de datos de asignación sigue un enfoque de extracción, carga y transformación (ELT) y funciona con conjuntos de datos de un almacenamiento provisional que están todos en Azure. Actualmente, se pueden usar los siguientes conjuntos de datos en una transformación de receptor.
Sugerencia
El fregadero puede tener un formato diferente al de la fuente. Este es un paso de cómo se puede transformar de un formato a otro. Por ejemplo, de un CSV a un fregadero de parquet. Es posible que tenga que realizar algunas transformaciones en el flujo de datos entre el origen y el receptor para que esto funcione correctamente. (Por ejemplo, Parquet tiene requisitos de encabezado más específicos que CSV).
| Conector | Formato | Conjunto de datos/insertado |
|---|---|---|
| Azure Blob Storage |
Avro Texto delimitado Delta JSON ORCO Parquet |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB para NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 |
Avro Texto delimitado JSON ORCO Parquet |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 |
Avro Modelo de Datos Común Texto delimitado Delta JSON ORCO Parquet |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database for MySQL | ✓/✓ | |
| Azure Database para PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Instancia administrada de Azure SQL | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Casa del Lago de Tela | ✓/✓ | |
| SFTP |
Avro Texto delimitado JSON ORCO Parquet |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Copo de nieve | ✓/✓ | |
| SQL Server | ✓/✓ |
La configuración específica de estos conectores se encuentra en la pestaña Configuración. La documentación de los conectores incluye información y ejemplos de script de flujo de datos basados en esta configuración.
El servicio tiene acceso a más de 90 conectores nativos. Para escribir datos en esos otros orígenes desde el flujo de datos, use la actividad de copia para cargar los datos desde un receptor compatible.
Configuración del receptor
Una vez que haya agregado un receptor, configúrelo a través de la pestaña Receptor. Aquí puede elegir o crear el conjunto de datos en el que escribe el receptor. Los valores de desarrollo de los parámetros del conjunto de datos se pueden definir en la configuración de depuración. (Requiere que esté activado el modo Depuración).
En el siguiente vídeo se explican varias opciones de receptor diferentes para los tipos de archivo delimitados de texto.
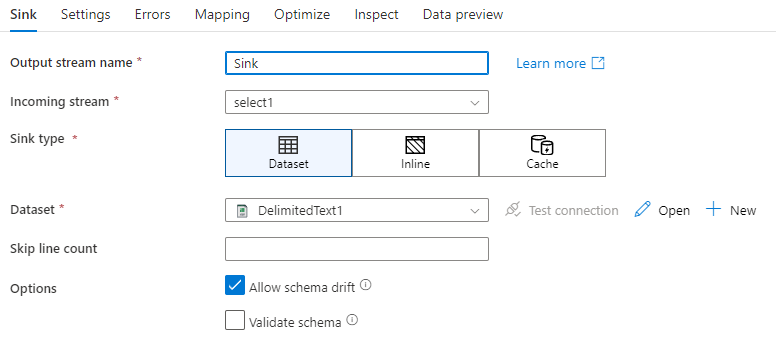
Desfase de esquema: el desfase de esquema es la capacidad del servicio de administrar de forma nativa los esquemas flexibles de los flujos de datos sin necesidad de definir explícitamente los cambios en las columnas. Habilite Permitir el desfase de esquema para escribir columnas adicionales sobre lo que se define en el esquema de datos del receptor.
Validar esquema: si se selecciona que se valide el esquema, se producirá un error en el flujo de datos si no se encuentra ninguna columna de la proyección de receptor en el almacén de receptor o si los tipos de datos no coinciden. Use esta opción para exigir que el esquema de receptor cumpla con el contrato de la proyección definida. Esto resulta útil en escenarios de receptor de base de datos para indicar que los nombres o los tipos de columna se modificaron.
Receptor de caché
Un receptor de caché se utiliza cuando un flujo de datos escribe datos en la memoria caché de Spark en lugar de en un almacén de datos. En los flujos de datos de asignación, puede hacer referencia a estos datos en el mismo flujo muchas veces con una búsqueda en caché. Esto resulta útil si desea hacer referencia a los datos como parte de una expresión, pero no desea unir explícitamente las columnas. Algunos ejemplos comunes en los que un receptor de caché puede ayudar son: buscar un valor máximo en un almacén de datos y buscar coincidencias de códigos de error en una base de datos de mensajes de error.
Para escribir en un receptor de caché, agregue una transformación de receptor y seleccione Caché como el tipo de receptor. A diferencia de otros tipos de receptor, no es necesario seleccionar un conjunto de datos ni un servicio vinculado porque no está escribiendo en un almacén externo.
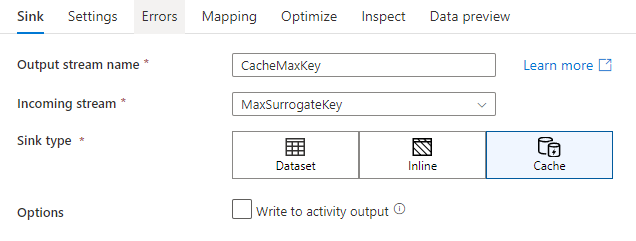
En la configuración del receptor, tiene la opción de especificar las columnas de clave del receptor de caché. Se usan como condiciones de coincidencia cuando se utiliza la función lookup() en una búsqueda en caché. Si especifica columnas de clave, no puede usar la función outputs() en una búsqueda en caché. Para obtener más información sobre la sintaxis de búsqueda de caché, consulte búsquedas en caché.
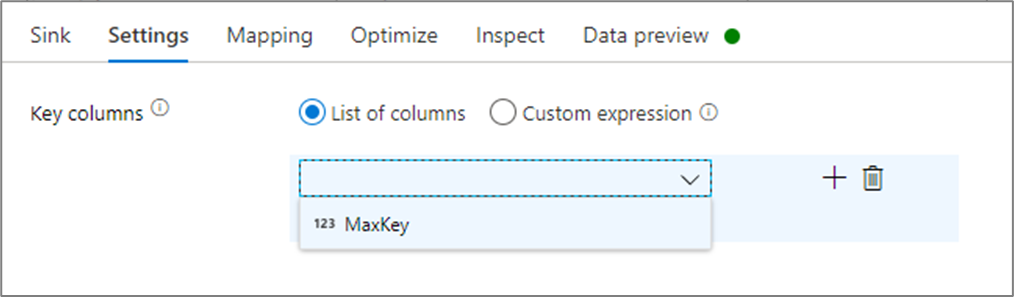
Por ejemplo, si se especifica una columna de clave única de column1 en un receptor de caché denominado cacheExample, la llamada a cacheExample#lookup() tendría un parámetro para especificar con qué fila del receptor de caché debe coincidir. La función genera una única columna compleja con subcolumnas para cada columna asignada.
Nota
Un receptor de caché debe estar en un flujo de datos completamente independiente de cualquier transformación que haga referencia a este a través de una búsqueda en caché. Un receptor de caché también debe ser el primer receptor escrito.
Escritura en la salida de la actividad
El receptor de caché puede escribir, opcionalmente, sus datos en la salida de la actividad de Data Flow que, a continuación, se puede usar como entrada para otra actividad de la canalización. Esto le permitirá pasar datos de forma rápida y sencilla fuera de la actividad de flujo de datos sin necesidad de conservar los datos en un almacén de datos.
Tenga en cuenta que la salida de Data Flow que se inserta directamente en la canalización está limitada a 2 MB. Por lo tanto, Data Flow intentará agregar a la salida tantas filas como pueda sin sobrepasar el límite de 2 MB, por lo que a veces es posible que no vea todas las filas en la salida de la actividad. Establecer "Solo primera fila" en el nivel de actividad de Data Flow también le ayuda a limitar la salida de datos de Data Flow si es necesario.
Método de actualización
En los tipos de receptor de base de datos, la pestaña Configuración incluye una propiedad llamada "Método de actualización". El valor predeterminado es insertar, pero también incluye las casillas de actualizar, upsert y eliminar. Para usar esas opciones adicionales, deberá agregar una transformación Alterar fila antes del receptor. El Alterar fila le permitirá definir las condiciones de cada una de las acciones de la base de datos. Si el origen es de habilitación de CDC nativo, puede establecer los métodos de actualización sin un Alterar fila, ya que el ADF ya conoce los marcadores de fila de insertar, actualizar, upsert y eliminar.
Asignación de campos
De forma similar a la transformación Selección, en la pestaña Asignación del receptor, puede decidir qué columnas de entrada se escribirán. De forma predeterminada, se asignan todas las columnas de entrada, incluidas las columnas desfasadas. Este comportamiento se conoce como asignación automática.
Cuando desactive la asignación automática, puede agregar asignaciones basadas en columnas o basadas en reglas. Con las asignaciones basadas en reglas, puede escribir expresiones con coincidencia de patrones. La asignación fija asigna nombres de columnas lógicas y físicas. Para más información sobre la asignación basada en reglas, consulte Patrones de columna en flujos de datos de asignación.
Ordenación de receptores personalizados
De forma predeterminada, los datos se escriben en varios receptores en un orden no determinista. El motor de ejecución escribe datos en paralelo a medida que se complete la lógica de transformación y el orden de los receptores puede variar en cada ejecución. Para especificar una ordenación de receptores exacta, habilite la opción Ordenación de receptores personalizada en la pestaña General del flujo de datos. Una vez habilitada, los receptores se escriben secuencialmente en orden ascendente.
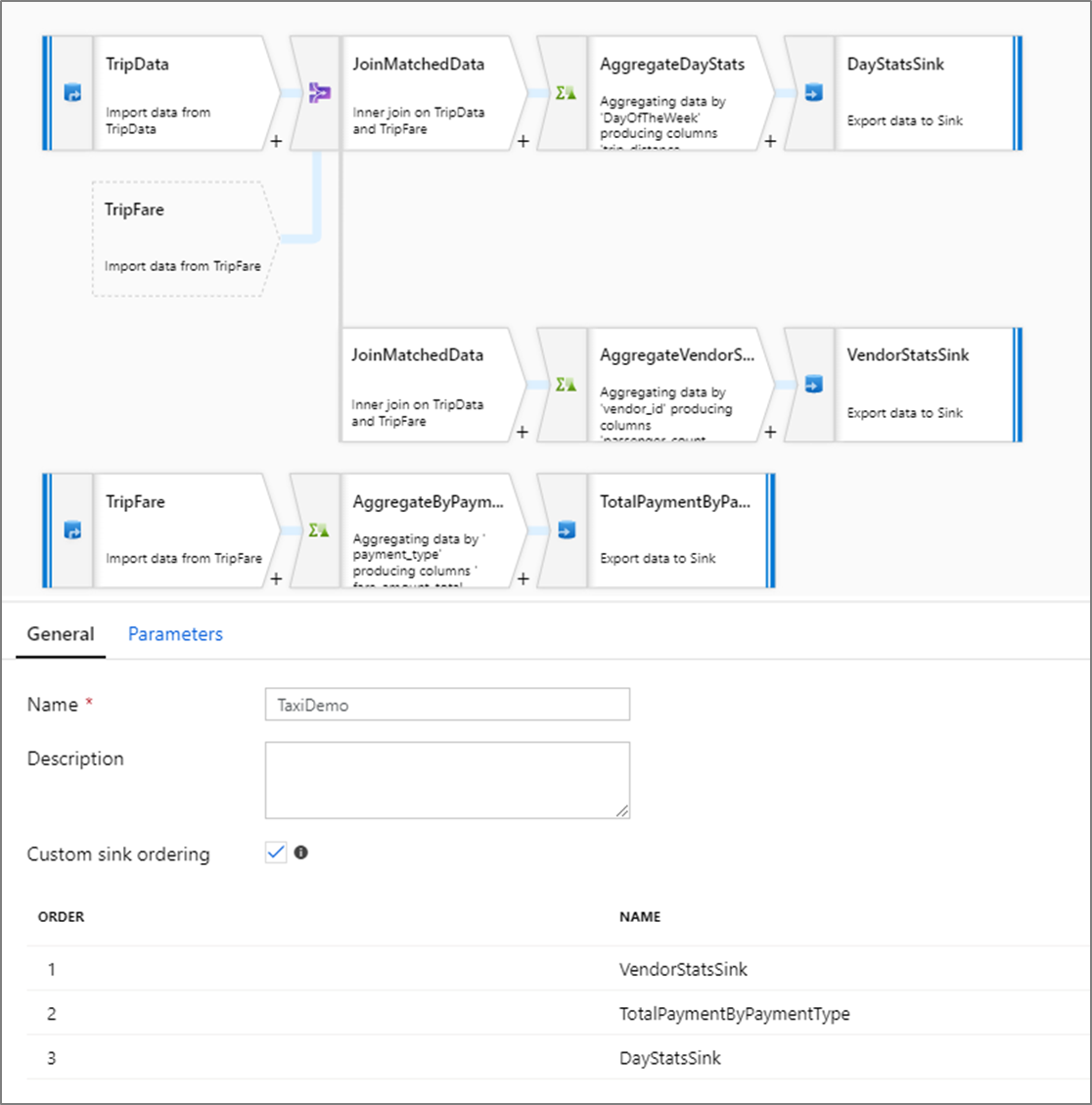
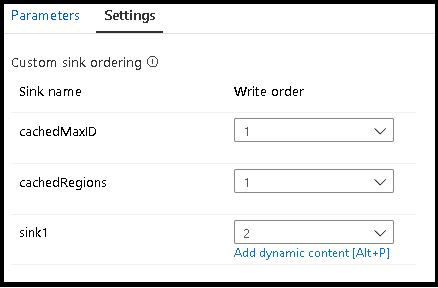
Nota
Al usar las búsquedas almacenadas en caché, asegúrese de que la ordenación del receptor tenga los receptores almacenado en caché establecidos en 1, el calor más bajo (o el primer valor) del orden.
Grupos de receptores
Si desea agrupar receptores, puede aplicar el mismo número de pedido para una serie de receptores. El servicio tratará esos receptores como grupos que se pueden ejecutar en paralelo. Las opciones para la ejecución en paralelo se mostrarán en la actividad de flujo de datos de la canalización.
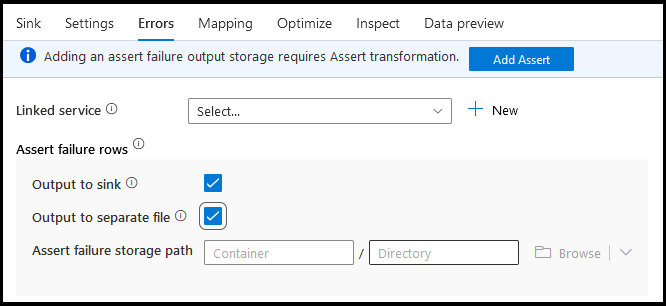
Errores
En la pestaña Errores del receptor, puede configurar el control de filas de error para capturar y redirigir la salida de los errores del controlador de base de datos y las aserciones con errores.
Al escribir en bases de datos, puede producirse un error en determinadas filas de datos debido a las restricciones establecidas por el destino. De forma predeterminada, la ejecución de un flujo de datos no funcionará al recibir el primer error. En algunos conectores, puede optar por Continuar en caso de error, que permite que el flujo de datos se complete, aunque haya filas individuales con errores. Actualmente, esta funcionalidad solo está disponible en Azure SQL Database y Azure Synapse. Para más información, consulte Control de filas de error en Azure SQL DB.
A continuación, se muestra un tutorial en vídeo sobre cómo usar el control de filas de error de base de datos automáticamente en la transformación del receptor.
En el caso de las filas con error de aserción, puede usar la transformación Assert de manera ascendente en el flujo de datos y, a continuación, redirigir las aserciones con error a un archivo de salida en la pestaña Errores del receptor. También tiene una opción aquí para omitir las filas con errores de aserción y no generar esas filas en el almacén de datos de destino del receptor.
Vista previa de los datos en el receptor
Al obtener una vista previa de los datos en modo de depuración, no se escribirá ningún dato en el receptor. Se devolverá una instantánea de la apariencia de los datos, pero no se escribirá nada en el destino. Para probar la escritura de datos en el receptor, ejecute una depuración de canalización desde el lienzo de canalización.
Script de flujo de datos
Ejemplo
A continuación se muestra un ejemplo de una transformación de receptor con el script de flujo de datos correspondiente:
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Contenido relacionado
Ahora que ha creado el flujo de datos, agregue una actividad de Data Flow a la canalización.