Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Si no está familiarizado con Azure Data Factory, consulte Introducción a Azure Data Factory.
En este tutorial, aprenderá los procedimientos recomendados que se pueden aplicar al escribir archivos en ADLS Gen2 o Azure Blob Storage mediante flujos de datos. Necesitará acceso a una cuenta de Azure Blob Storage o a una cuenta de Azure Data Lake Store Gen2 para leer un archivo parquet y, a continuación, almacenar los resultados en carpetas.
Requisitos previos
- Suscripción de Azure. Si no tiene una suscripción de Azure, cree un cuenta de Azure gratuita antes de comenzar.
- Cuenta de almacenamiento de Azure. El almacenamiento ADLS se puede usar como almacén de datos de origen y receptor. Si no tiene una cuenta de almacenamiento, consulte Crear una cuenta de almacenamiento de Azure para ver los pasos para crear una.
Los pasos de este tutorial dan por hecho que tiene:
Crear una factoría de datos
En este paso, creará una factoría de datos y abrirá la interfaz de usuario de Data Factory para crear una canalización en la factoría de datos.
Abra Microsoft Edge o Google Chrome. Actualmente, la interfaz de usuario de Data Factory solo se admite en los exploradores web de Microsoft Edge y Google Chrome.
En el menú de la izquierda, seleccione Crear un recurso>Integración>Data Factory.
En la página Nueva factoría de datos, en Nombre, escriba ADFTutorialDataFactory.
Seleccione el Azure subscription en el que desea crear la factoría de datos.
Para Grupo de recursos, realice uno de los siguientes pasos:
a) Seleccione Usar existente, y después seleccione un grupo de recursos existente de la lista desplegable.
b. Seleccione Crear nuevo y escriba el nombre de un grupo de recursos. Para obtener información sobre los grupos de recursos, consulte Use grupos de recursos para administrar los recursos de Azure.
En Versión, seleccione V2.
En Ubicación, seleccione la ubicación de la factoría de datos. En la lista desplegable solo se muestran las ubicaciones que se admiten. Los almacenes de datos (por ejemplo, Azure Storage y SQL Database) y los procesos (por ejemplo, Azure HDInsight) usados por la factoría de datos pueden estar en otras regiones.
Seleccione Crear.
Una vez finalizada la creación, verá el aviso en el centro de notificaciones. Seleccione Ir al recurso para ir a la página de Data Factory.
Seleccione Author & Monitor (Crear y supervisar) para iniciar la interfaz de usuario de Data Factory en una pestaña independiente.
Crear una canalización con una actividad de flujo de datos
En este paso, crearás una canalización que contenga una actividad de flujo de datos.
En la página principal de Azure Data Factory, seleccione Orchestrate.
En la pestaña General de la canalización, escriba DeltaLake en el campo Nombre de la canalización.
En la barra superior de Data Factory, deslice el control deslizante Depuración de Data Flow para activarlo. El modo de depuración permite realizar pruebas interactivas de la lógica de transformación en un clúster de Spark activo. Los clústeres de Data Flow tardan entre 5 y 7 minutos en prepararse y se recomienda a los usuarios que activen primero la depuración si planean realizar desarrollo de Data Flow. Para más información, consulte Modo de depuración.
En el panel Actividades expanda el acordeón Movimiento y transformación. Arrastre y coloque la actividad Data Flow del panel al lienzo de la canalización.
Construir la lógica de transformación en el entorno de flujo de datos
Tomará cualquier dato de origen (en este tutorial, usaremos un origen de archivos Parquet) y usará una transformación de receptor para que los datos lleguen en formato Parquet mediante los mecanismos más eficaces para ETL de lago de datos.

Objetivos del tutorial
- Elija cualquiera de los conjuntos de datos de origen de un nuevo flujo de datos 1. Uso de flujos de datos para particionar eficazmente el conjunto de datos receptor
- Coloque sus datos particionados en carpetas lacustres de ADLS Gen2.
Comenzar con un lienzo de flujo de datos en blanco
En primer lugar, vamos a configurar el entorno de flujo de datos para cada uno de los mecanismos que se describen a continuación para enviar datos a ADLS Gen2.
- Haga clic en la transformación de origen.
- Haga clic en el botón Nuevo situado junto al conjunto de datos en el panel inferior.
- Elija un conjunto de datos o cree uno nuevo. Para esta demo, usaremos un conjunto de datos de Parquet denominado datos de usuario.
- Agregue una transformación de columna derivada. Lo utilizaremos como una forma de establecer los nombres de carpeta que desee de una manera dinámica.
- Agregue una transformación de receptor.
Salida de carpeta jerárquica
Es común utilizar valores únicos en tus datos para crear jerarquías de carpetas y particionar tus datos en el lago. Es una muy buena forma de organizar y procesar datos en el lago y en Spark (el motor de proceso que hay detrás de los flujos de datos). Sin embargo, organizar el resultado de esta manera tendrá un impacto menor en el rendimiento. Observará una leve disminución en el rendimiento general de la tubería al usar este mecanismo en el sumidero.
- Vuelva al diseñador del flujo de datos y modifique el flujo de datos creado anteriormente. Haga clic en la transformación del receptor.
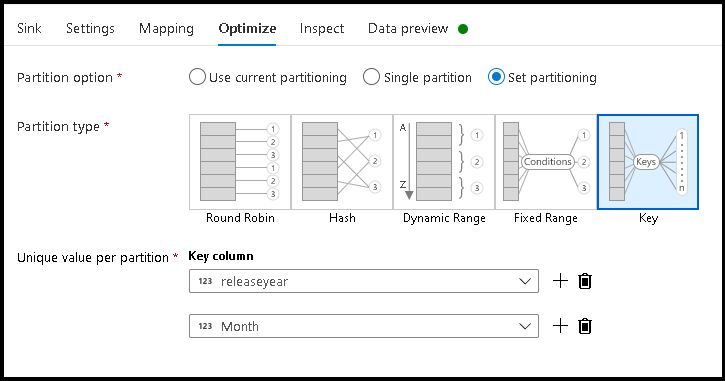
- Haga clic en Optimizar > Establecer partición > Clave.
- Escoja la columna o columnas para establecer la estructura jerárquica de las carpetas.
- Tenga en cuenta que el ejemplo siguiente utiliza el año y el mes como columnas para la nomenclatura de las carpetas. Los resultados serán carpetas con el formato
releaseyear=1990/month=8. - Al acceder a las particiones de datos en un origen de flujo de datos, apuntará solo a la carpeta de nivel superior anterior
releaseyeary usará un patrón de caracteres comodín para cada carpeta posterior, por ejemplo:**/**/*.parquet - Para modificar los valores de los datos, o incluso si es necesario generar valores sintéticos para los nombres de carpeta, use la transformación de columna derivada para crear los valores que desea usar en los nombres de carpeta.
Nombra la carpeta como valores de datos
Hay una técnica de receptor que tiene un rendimiento ligeramente mejor para los datos de lago con ADLS Gen2, pero que no ofrece las mismas ventajas que la creación de particiones de clave-valor, y es Name folder as column data. Mientras que el estilo de partición clave de la estructura jerárquica le facilitará el procesamiento de segmentos de datos, esta técnica utiliza una estructura de carpetas aplanada que permite escribir datos más rápidamente.
- Vuelva al diseñador del flujo de datos y modifique el flujo de datos creado anteriormente. Haga clic en la transformación del receptor.
- Haga clic en Optimizar > Establecer creación de particiones > Utilizar la creación de particiones actual.
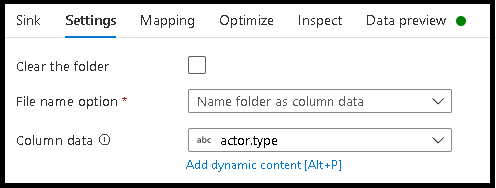
- Haga clic en Configuración > Asignar nombre a la carpeta como datos de columna.
- Elija la columna que desea utilizar para generar nombres de carpeta.
- Para modificar los valores de los datos, o incluso si es necesario generar valores sintéticos para los nombres de carpeta, use la transformación de columna derivada para crear los valores que desea usar en los nombres de carpeta.
Nombrar el archivo según valores de datos
Las técnicas mencionadas en los tutoriales anteriores son casos de uso adecuados para crear categorías de carpetas en el lago de datos. El esquema de nomenclatura de archivos predeterminado que emplean esas técnicas es usar el identificador de trabajo del ejecutor de Spark. Algunas veces querrá establecer el nombre del archivo de salida en un receptor de texto de flujo de datos. Se recomienda el uso de esta técnica solo para archivos pequeños. El proceso de combinar archivos de partición en un único archivo de salida es un proceso de ejecución prolongada.
- Vuelva al diseñador del flujo de datos y modifique el flujo de datos creado anteriormente. Haga clic en la transformación del receptor.
- Haga clic en Optimizar > Configurar particiones > Partición única. Este requisito de partición única crea un cuello de botella en el proceso de ejecución a medida que se combinan los archivos. Esta opción solo se recomienda para archivos pequeños.
- Haga clic en Configuración > Asignar nombre al archivo como datos de columna.
- Elija la columna que desea utilizar para generar nombres de archivo.
- Para modificar los valores de los datos, o incluso si es necesario generar valores sintéticos para los nombres de archivo, use la transformación de columna derivada para crear los valores que desea usar en los nombres de archivo.
Contenido relacionado
Más información sobre los receptores de flujo de datos.