Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial se utiliza la interfaz de usuario (UI) de Azure Data Factory para crear una canalización de Data Factory que copie los datos de una base de datos de SQL Server en Azure Blob Storage. Cree y use una instancia de Integration Runtime autohospedado, que mueve los datos entre almacenes locales y en la nube.
Nota
En este artículo no se ofrece una introducción detallada a Data Factory. Para más información, consulte Introducción a Data Factory.
En este tutorial, realizará los siguientes pasos:
- Creación de una factoría de datos.
- Cree una instancia de Integration Runtime autohospedada.
- Creación de los servicios vinculados SQL Server y Azure Storage.
- Creación de los conjuntos de datos de SQL Server y Azure Blob.
- Creación de una canalización con una actividad de copia para mover los datos.
- Inicio de la ejecución de una canalización.
- Supervisión de la ejecución de la canalización
Requisitos previos
Suscripción de Azure
Antes de empezar, si no tiene una suscripción a Azure, cree una cuenta gratuita.
Roles de Azure
Para crear instancias de Data Factory, la cuenta de usuario que use para iniciar sesión en Azure debe tener un rol Colaborador o Propietario asignado o ser administrador de la suscripción de Azure.
Para ver los permisos que tiene en la suscripción, vaya a Azure Portal. En la esquina superior derecha, seleccione su nombre de usuario y luego seleccione Permisos. Si tiene acceso a varias suscripciones, elija la correspondiente. Para obtener instrucciones de ejemplo sobre cómo agregar un usuario a un rol, consulte Asignación de roles de Azure mediante Azure Portal.
SQL Server 2014, 2016 y 2017
En este tutorial, usará una base de datos de SQL Server como almacén de datos de origen. La canalización de la factoría de datos que crea en este tutorial copia los datos de esta base de datos de SQL Server (origen) a Blob Storage (receptor). Luego, cree una tabla denominada emp en la base de datos de SQL Server e inserte un par de entradas de ejemplo en la tabla.
Inicie SQL Server Management Studio. Si no está instalada en su máquina, vaya a Descarga de SQL Server Management Studio (SSMS).
Conéctese a una instancia de SQL Server con sus credenciales.
Cree una base de datos de ejemplo. En la vista de árbol, haga clic con el botón derecho en Bases de datos y, luego, seleccione Nueva base de datos.
En el cuadro de diálogo Nueva base de datos, escriba el nombre de la base de datos y haga clic en Aceptar.
Para crear la tabla emp e insertar en ella algunos datos de ejemplo, ejecute el siguiente script de consulta en la base de datos. En la vista de árbol, haga clic con el botón derecho en la base de datos que ha creado y, después, haga clic en Nueva consulta.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Cuenta de almacenamiento de Azure
En este tutorial, use una cuenta de almacenamiento de Azure (en concreto Blob Storage) de uso general como almacén de datos de destino o receptor. Si no dispone de una cuenta de Azure Storage de uso general, consulte Creación de una cuenta de almacenamiento. La canalización de la factoría de datos que crea en este tutorial copia los datos de la base de datos de SQL Server (origen) en Blob Storage (receptor).
Obtención de un nombre y una clave de cuenta de almacenamiento
En este tutorial, use el nombre y la clave de su cuenta de almacenamiento. Para obtener el nombre y la clave de la cuenta de almacenamiento, siga estos pasos:
Inicie sesión en Azure Portal con el nombre de usuario y la contraseña de Azure.
Seleccione Todos los servicios en el panel izquierdo. Use la palabra clave Almacenamiento para filtrar el resultado y, luego, seleccione Cuentas de almacenamiento.
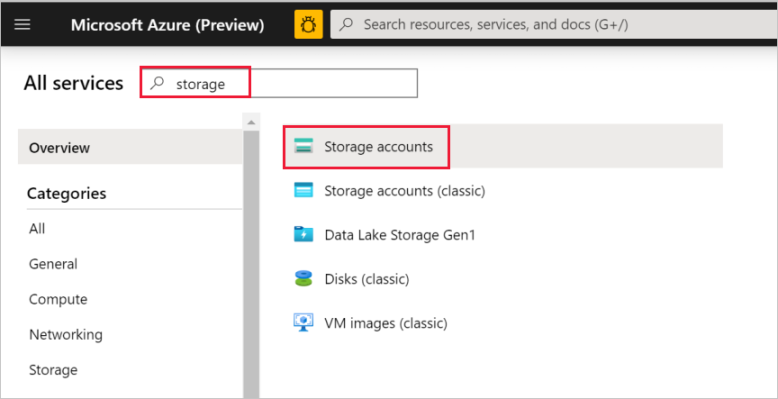
En la lista de cuentas de almacenamiento, filtre por su cuenta de almacenamiento, si fuera necesario. Después, seleccione su cuenta de almacenamiento.
En la ventana Cuenta de almacenamiento, seleccione Claves de acceso.
En los cuadros Nombre de la cuenta de almacenamiento y key1, copie los valores y péguelos en el Bloc de notas, u otro editor, para su uso posterior en el tutorial.
Creación del contenedor adftutorial
En esta sección se crea un contenedor de blobs denominado adftutorial en la instancia de Blob Storage.
En la ventana Cuenta de almacenamiento, vaya a Información general y, después, seleccione Contenedores.
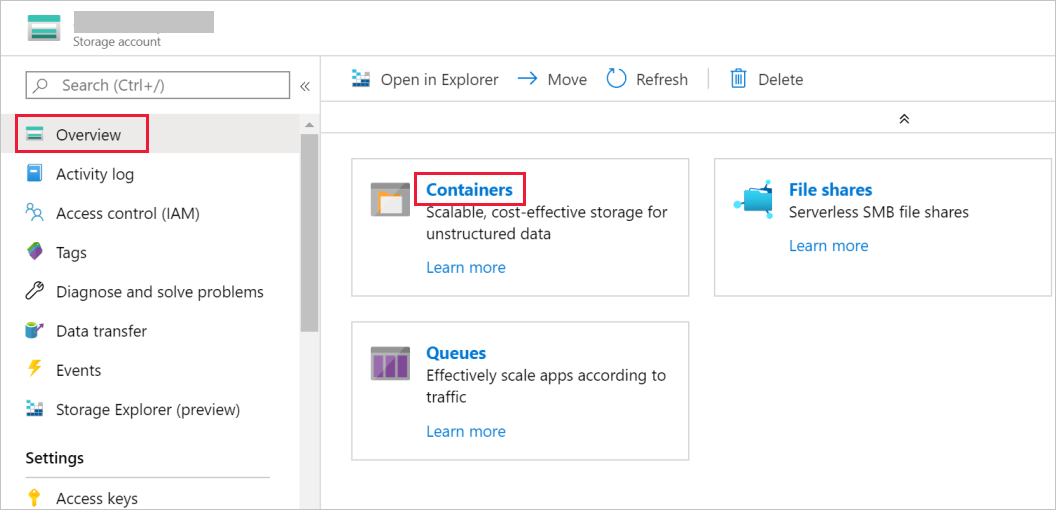
En la ventana Contenedores, seleccione + Contenedor para crear un nuevo contenedor.
En la ventana Nuevo contenedor en Nombre, escriba adftutorial. Seleccione Crear.
En la lista de contenedores, seleccione el contenedor adftutorial que acaba de crear.
Mantenga abierta la ventana contenedor de adftutorial. Úselo para comprobar la salida al final de este tutorial. Data Factory crea automáticamente la carpeta de salida de este contenedor, por lo que no es necesario que el usuario la cree.
Crear una factoría de datos
En este paso, creará una factoría de datos e iniciará la interfaz de usuario de Data Factory para crear una canalización en la factoría de datos.
Abra el explorador web Microsoft Edge o Google Chrome. Actualmente, la interfaz de usuario de Data Factory solo se admite en los exploradores web Microsoft Edge y Google Chrome.
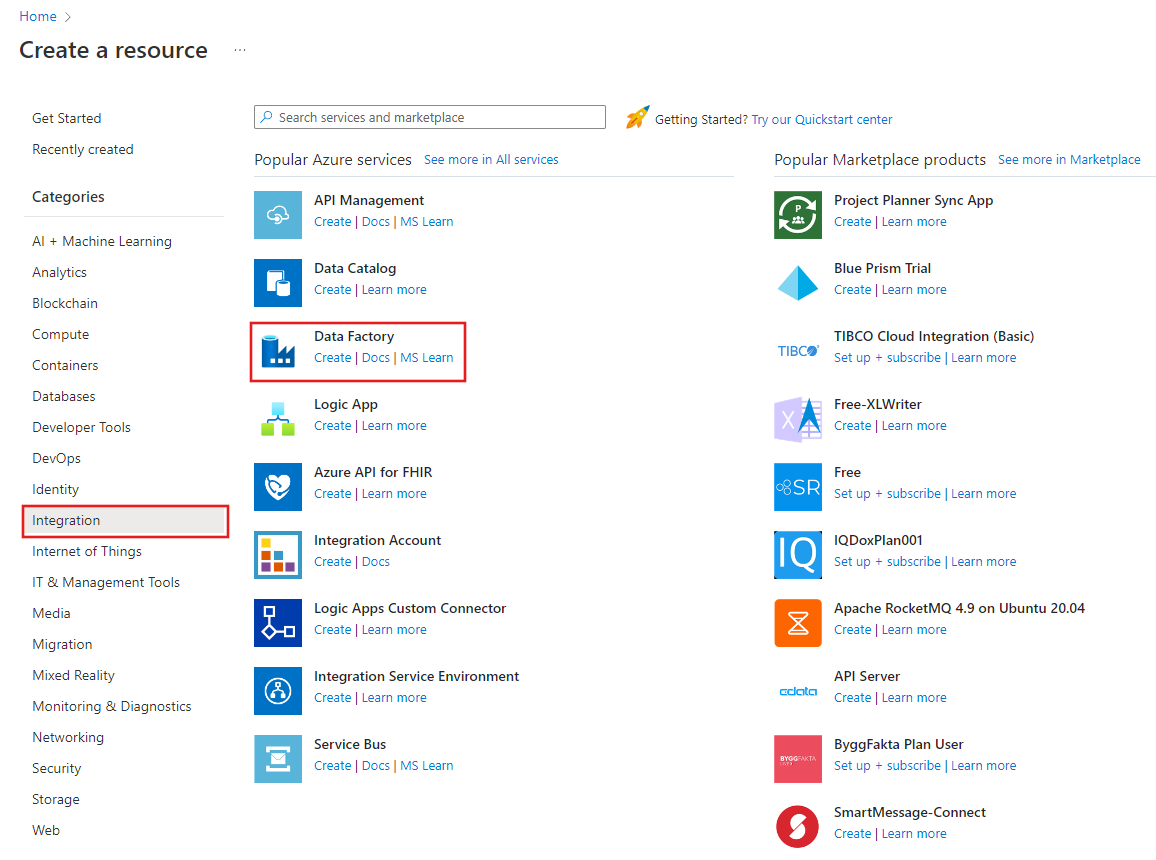
En el menú superior, seleccione Crear un recurso>Analytics>Data Factory :
En la página Nueva factoría de datos, en Nombre, escriba ADFTutorialDataFactory.
El nombre de la factoría de datos tiene que ser único a nivel global. Si ve el siguiente mensaje de error en el campo de nombre, cambie el nombre de la factoría de datos (por ejemplo, suNombreADFTutorialDataFactory). Para conocer las reglas de nomenclatura de los artefactos de Data Factory, consulte Azure Data Factory: reglas de nomenclatura.
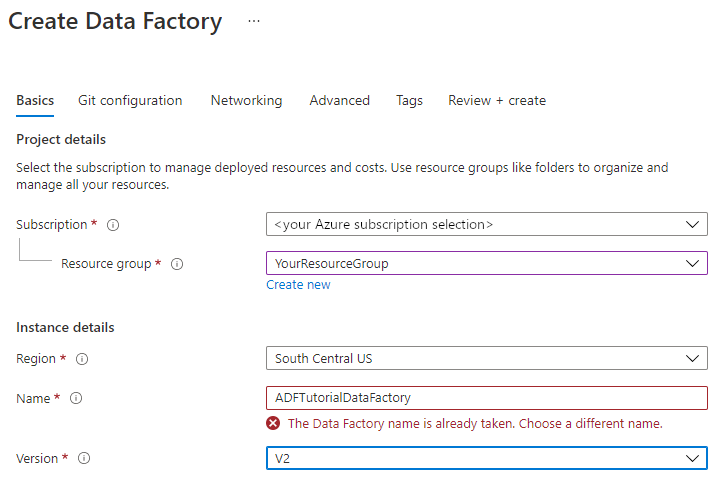
Seleccione la suscripción de Azure en la que quiere crear la factoría de datos.
Para Grupo de recursos, realice uno de los siguientes pasos:
Seleccione en primer lugar Usar existentey después un grupo de recursos de la lista desplegable.
Seleccione Crear nuevoy escriba el nombre de un grupo de recursos.
Para más información sobre los grupos de recursos, consulte Uso de grupos de recursos para administrar los recursos de Azure.
En Versión, seleccione V2.
En Ubicación, seleccione la ubicación de la factoría de datos. En la lista desplegable solo se muestran las ubicaciones que se admiten. Los almacenes de datos (por ejemplo, Azure Storage y SQL Database) y los procesos (por ejemplo, Azure HDInsight) que usa Data Factory pueden estar en otras regiones.
Seleccione Crear.
Una vez finalizada la creación, verá la página Data Factory tal como se muestra en la imagen:

Seleccione Abrir en el icono Abrir Azure Data Factory Studio para iniciar la interfaz de usuario de Data Factory en una pestaña independiente.
Crear una canalización
En la página principal de Azure Data Factory, seleccione Orchestrate (Organizar). Se crea automáticamente una canalización. Aparece la canalización en la vista de árbol y se abre su editor.
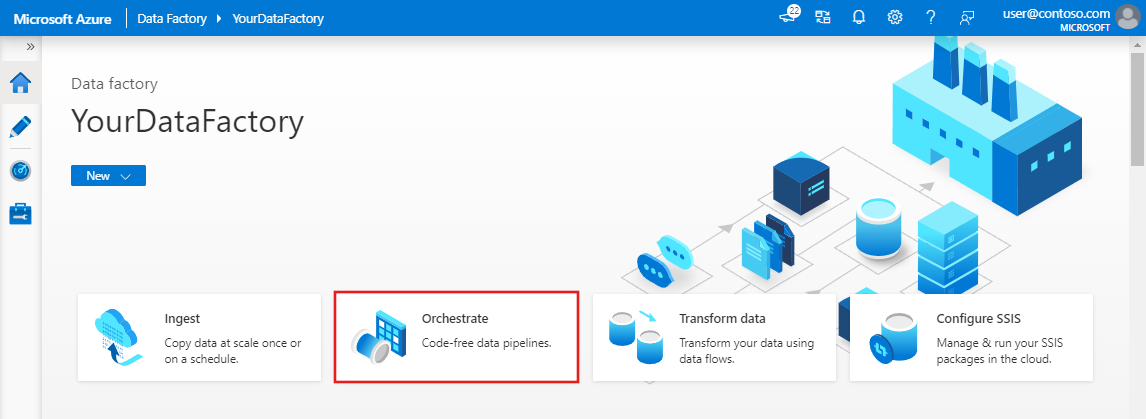
En el panel General, en Propiedades, especifique SQLServerToBlobPipeline en Nombre. A continuación, contraiga el panel; para ello, haga clic en el icono Propiedades en la esquina superior derecha.
En el cuadro de herramientas Activities (Actividades), expanda Move & Transform (Mover y transformar). Arrastre y coloque la actividad Copy (Copiar) en la superficie de diseño de la canalización. Establezca el nombre de la actividad en CopySqlServerToAzureBlobActivity.
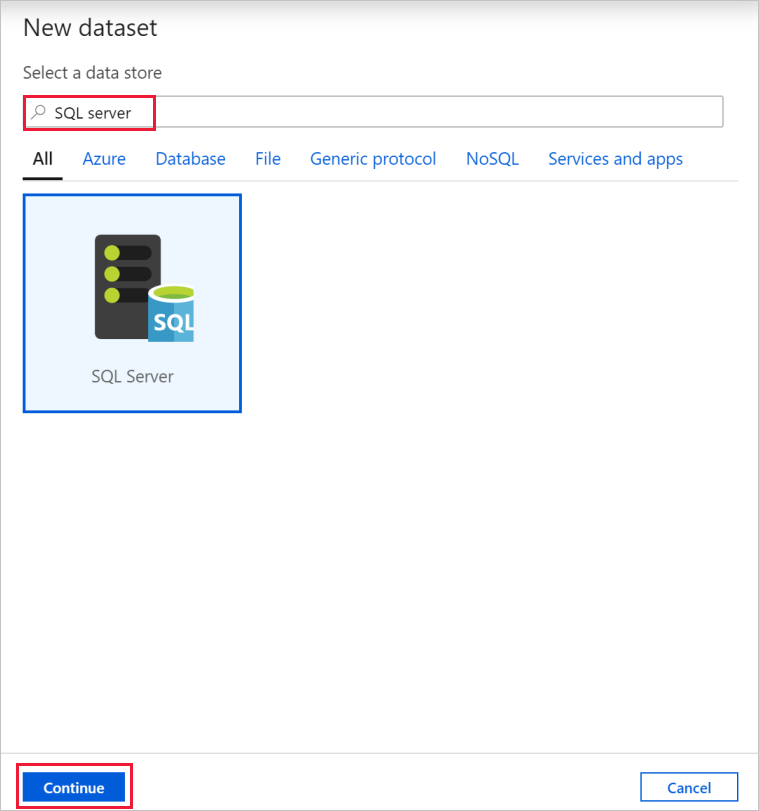
En la ventana Properties (Propiedades), cambie a la pestaña Source (Origen) y haga clic en + New (+ Nuevo).
En el cuadro de diálogo New Dataset (Nuevo conjunto de datos), busque SQL Server. Seleccione SQL Server y, luego, Continue (Continuar).
En el cuadro de diálogo Set Properties (Establecer propiedades), en Name (Nombre), escriba SqlServerDataset. En Linked service (Servicio vinculado), seleccione + New (+ Nuevo). En este paso se crea una conexión con el almacén de datos de origen (base de datos de SQL Server).
En el cuadro de diálogo New Linked Service (Nuevo servicio vinculado) agregue SqlServerLinkedService en Name (Nombre). En Connect via integration runtime (Conectar mediante IR), seleccione +New (+ Nuevo). En esta sección se crea una instancia de Integration Runtime autohospedada y se asocia con un equipo local con la base de datos de SQL Server. El entorno de ejecución de integración autohospedado es el componente que copia los datos de la base de datos de SQL Server de la máquina en Blob Storage.
En el cuadro de diálogo Integration Runtime Setup (Configuración de Integration Runtime), seleccione Self-Hosted (Autohospedado) y, después, seleccione Continue (Continuar).
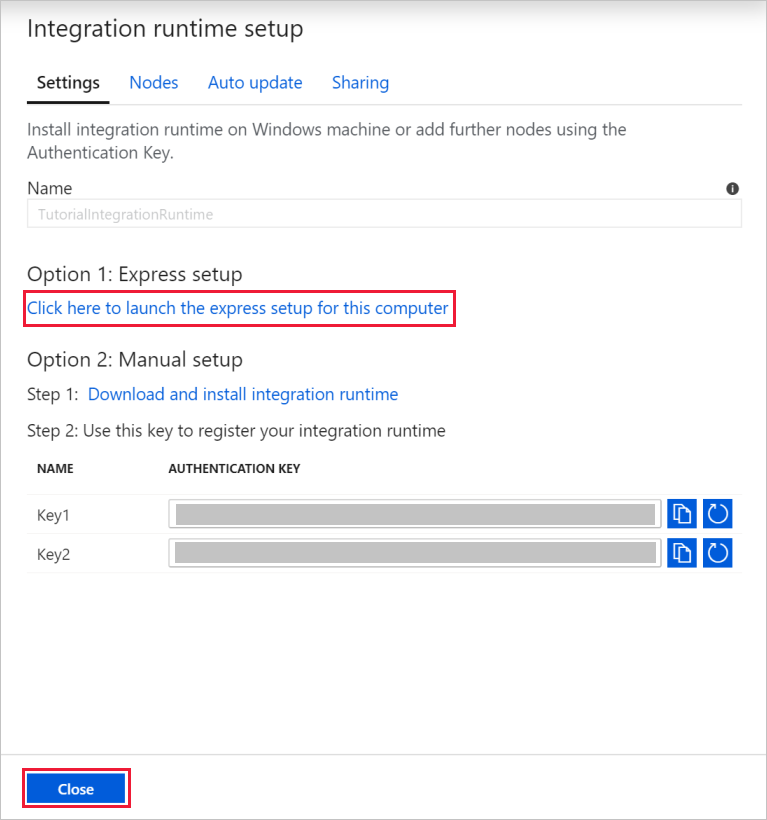
Como nombre, escriba TutorialIntegrationRuntime. Seleccione Crear.
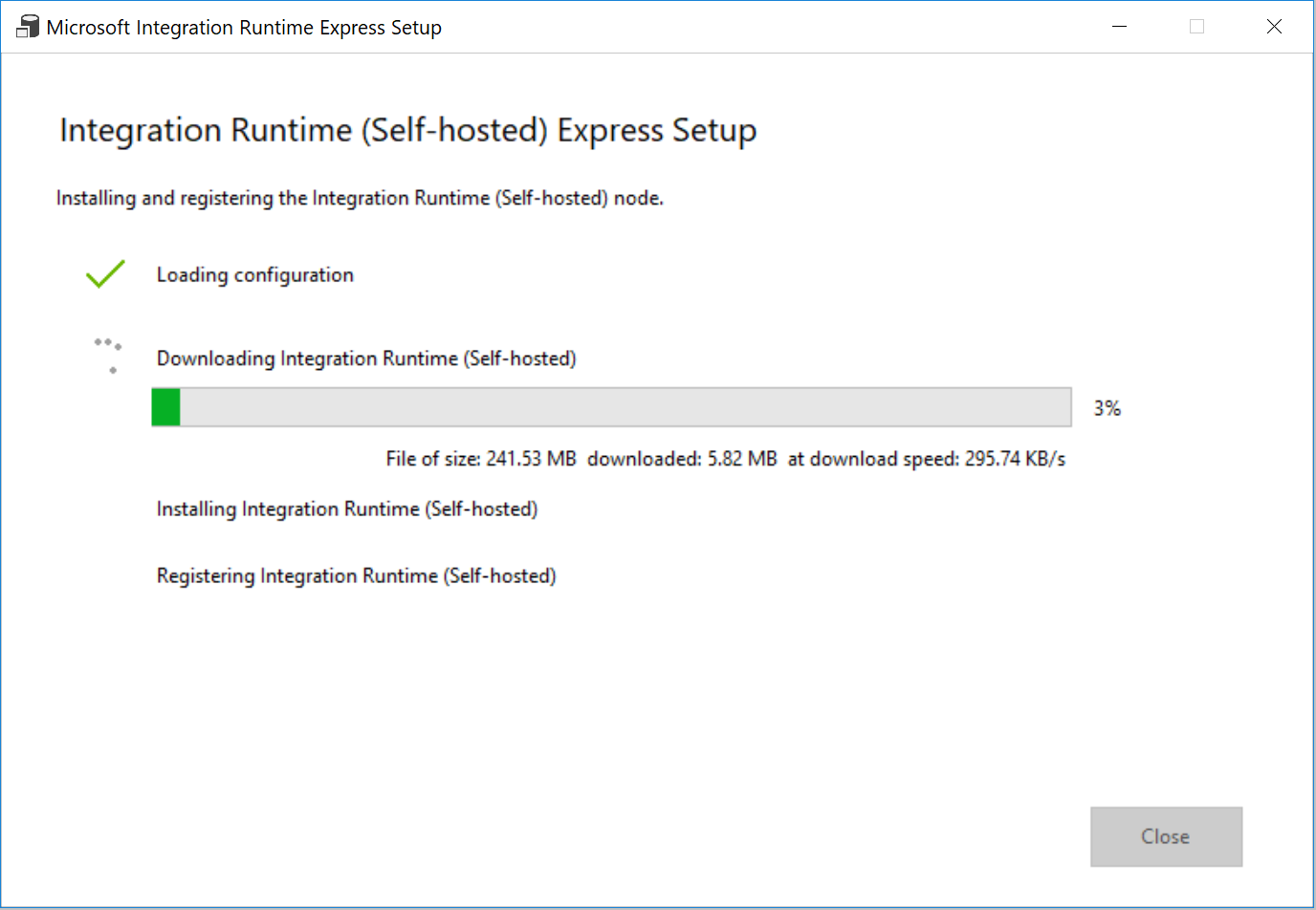
En Settings (Configuración), seleccione Click here to launch the express setup for this computer (Haga clic aquí para iniciar la configuración rápida en este equipo). Esta acción instala el entorno de ejecución de integración en la máquina y la registra en Data Factory. Como alternativa, puede usar la instalación manual para descargar el archivo de instalación, ejecutarlo y registrar la instancia de Integration Runtime con la clave.
En la ventana Integration Runtime (Self-hosted) Express Setup (Configuración rápida de Integration Runtime [autohospedado]), seleccione Close (Cerrar) cuando haya terminado el proceso.
En el cuadro de diálogo New Linked Service (SQL Server) (Nuevo servicio vinculado [SQL Server]), confirme que TutorialIntegrationRuntime está seleccionado en Connect via integration runtime (Conectar a través de IR). A continuación, siga estos pasos:
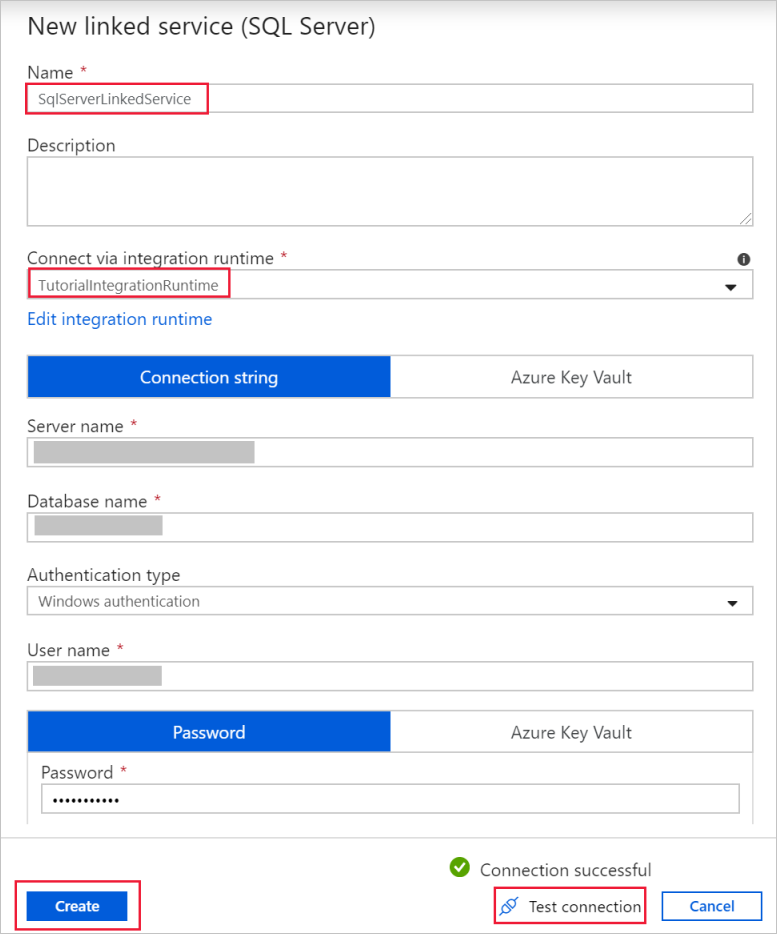
a) En Name (Nombre), escriba SqlServerLinkedService.
b. Escriba el nombre de la instancia de SQL Server en Server name (Nombre del servidor).
c. En el campo Database name (Nombre de la base de datos) especifique el nombre de la base de datos con la tabla emp.
d. En Authentication type (Tipo de autenticación) seleccione el tipo de autenticación adecuado que Data Factory debe usar para conectarse a la base de datos de SQL Server.
e. En User name (Nombre de usuario) y Password (Contraseña), escriba el nombre de usuario y la contraseña. Use midominio\miusuario como nombre de usuario si es necesario.
f. Seleccione Test connection (Probar conexión). Este paso permite confirmar que el servicio Data Factory puede conectarse a la base de datos de SQL Server mediante el entorno de ejecución de integración autohospedado que ha creado.
g. Seleccione Crear para guardar el servicio vinculado.
Una vez creado el servicio vinculado, se vuelve a la página Set Properties (Establecer propiedades) de SqlServerDataset. Siga estos pasos.
a) En Linked service (Servicio vinculado) confirme que ve SqlServerLinkedService.
b. En Nombre de la tabla, seleccione [dbo].[emp] .
c. Seleccione Aceptar.
Vaya a la pestaña con SQLServerToBlobPipeline o seleccione SQLServerToBlobPipeline en la vista de árbol.
Vaya a la pestaña Sink (Receptor) en la parte inferior de la ventana Properties (Propiedades) y seleccione + New (+ Nuevo).
En el cuadro de diálogo New Dataset (Nuevo conjunto de datos), seleccione Azure Blob Storage. Después, seleccione Continuar.
En el cuadro de diálogo Select Format (Seleccionar formato), elija el tipo de formato de los datos. Después, seleccione Continuar.

En el cuadro de diálogo Set Properties (Establecer propiedades), escriba AzureBlobDataset como nombre. Junto al cuadro de texto Linked service (Servicio vinculado), seleccione + New (+Nuevo).
En el cuadro de diálogo New Linked Service (Azure Blob Storage) [Nuevo servicio vinculado (Azure Blob Storage)], escriba AzureStorageLinkedService como nombre; en la lista de nombres Storage account (Cuenta de Storage) seleccione la cuenta de Storage. Pruebe la conexión y, a continuación, seleccione Create (Crear) para implementar el servicio vinculado.
Una vez creado el servicio vinculado, se vuelve a la página Set Properties (Establecer propiedades). Seleccione Aceptar.
Abra el conjunto de datos receptor. En la pestaña Connection (Conexión), realice los pasos siguientes:
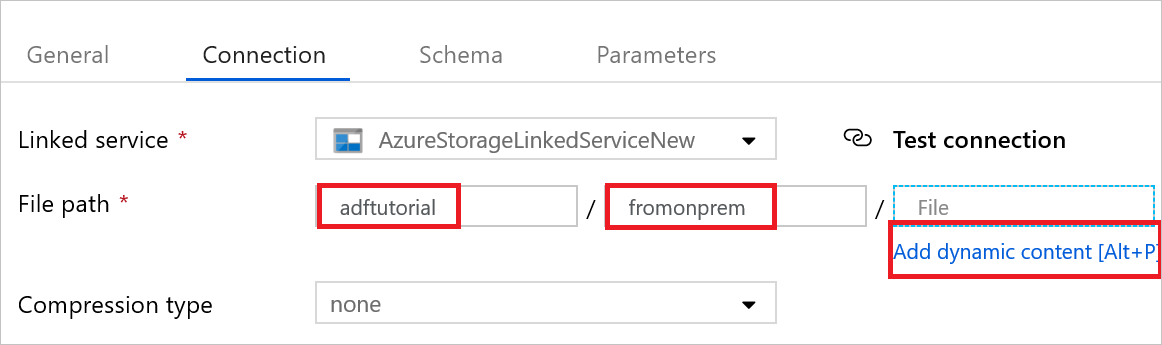
a) En Linked service (Servicio vinculado) confirme que AzureStorageLinkedService está seleccionado.
b. En File path (Ruta de acceso del archivo), escriba adftutorial/fromonprem en la parte Container / Directory (Contenedor / Directorio). Si no existe la carpeta de salida en el contenedor adftutorial, Data Factory la crea automáticamente.
c. En la parte File (Archivo), seleccione Add dynamic content (Agregar contenido dinámico).
d. Agregue
@CONCAT(pipeline().RunId, '.txt')y, después, seleccione Finish (Finalizar). Así cambiará el nombre del archivo a PipelineRunID.txt.Vaya a la pestaña con la canalización abierto o seleccione la canalización en la vista de árbol. En Sink Dataset (Conjunto de datos receptor) confirme que AzureBlobDataset está seleccionado.
Para comprobar la configuración de la canalización, seleccione Validate (Validar) en la barra de herramientas de la canalización. Para cerrar la salida de la validación de la canalización, seleccione el icono >>.
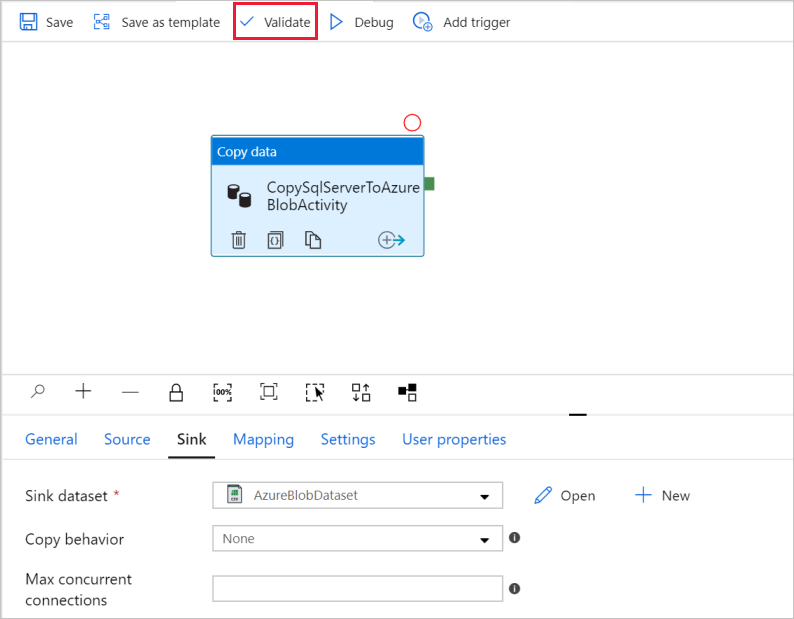
Para publicar las entidades que creó en Data Factory, seleccione Publish All (Publicar todo).
Espere hasta ver el mensaje emergente Publishing completed (Publicación finalizada). Para comprobar el estado de la publicación, seleccione el vínculo Show Notifications (Mostrar notificaciones) de la parte superior de la ventana. Para cerrar la ventana de notificaciones, seleccione Close (Cerrar).
Desencadenamiento de una ejecución de la canalización
Seleccione Add Trigger (Agregar desencadenador) en la barra de herramientas para la canalización y, después, seleccione Trigger Now (Desencadenar ahora).
Supervisión de la ejecución de la canalización
Vaya a la pestaña Monitor (Supervisar). Verá la canalización que ha desencadenado manualmente en el paso anterior.
Para ver las ejecuciones de actividad asociadas a la ejecución de la canalización, seleccione el vínculo SQLServerToBlobPipeline en NOMBRE DE CANALIZACIÓN.

En la página Ejecuciones de actividad, seleccione el vínculo Detalles (icono de gafas) para ver los detalles de la operación de copia. Para volver a la vista Ejecuciones de canalización, seleccione Ejecuciones de canalización en la parte superior.
Comprobación del resultado
La canalización automáticamente la carpeta de salida fromonprem en el contenedor de blobs adftutorial. Confirme que ve el archivo [pipeline().RunId].txt en la carpeta de salida.
Contenido relacionado
La canalización de este ejemplo copia los datos de una ubicación a otra en Blob Storage. Ha aprendido a:
- Creación de una factoría de datos.
- Cree una instancia de Integration Runtime autohospedada.
- Creación de los servicios vinculados SQL Server y Storage.
- Creación de conjuntos de datos de SQL Server y Blob Storage.
- Creación de una canalización con una actividad de copia para mover los datos.
- Inicio de la ejecución de una canalización.
- Supervisión de la ejecución de la canalización
Para ver una lista de los almacenes de datos compatibles con Data Factory, consulte los almacenes de datos que se admiten.
Para informarse acerca de cómo copiar datos de forma masiva de un origen a un destino, pase al tutorial siguiente: