Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Nota:
En este artículo se trata Databricks Connect para Databricks Runtime 13.0 y versiones posteriores.
Para obtener información sobre cómo empezar a trabajar rápidamente con Databricks Connect para Databricks Runtime 13.0 y versiones posteriores, consulte Databricks Connect.
Para saber más sobre Databricks Connect para versiones anteriores de Databricks Runtime, consulte Databricks Connect para Databricks Runtime 12.2 LTS y versiones anteriores.
Databricks Connect permite conectar a clústeres de Azure Databricks entornos de desarrollo integrado populares, como Visual Studio Code y PyCharm, servidores de cuadernos y otras aplicaciones personalizadas.
En este artículo se explica cómo funciona Databricks Connect, se le guiará por los pasos para empezar a trabajar con Databricks Connect y se explica cómo solucionar problemas que pueden surgir al usar Databricks Connect.
Información general
Databricks Connect es una biblioteca cliente para Databricks Runtime. Permite escribir trabajos mediante las API de Spark y ejecutarlos de manera remota en un clúster de Azure Databricks en lugar de hacerlo en la sesión local de Spark.
Por ejemplo, al ejecutar el comando DataFrame spark.read.format(...).load(...).groupBy(...).agg(...).show() mediante Databricks Connect, la representación lógica del comando se envía al servidor Spark que se ejecuta en Azure Databricks para su ejecución en el clúster remoto.
Con Databricks Connect, puede:
Ejecutar trabajos de Spark a gran escala desde cualquier aplicación de Python. En cualquier lugar donde pueda ejecutar
import pyspark, ahora puede ejecutar trabajos de Spark directamente desde la aplicación sin necesidad de instalar ningún complemento de IDE ni utilizar scripts de envío de Spark.Nota:
Databricks Connect para Databricks Runtime 13.0 y versiones posteriores actualmente solo admiten la ejecución de aplicaciones de Python.
Ejecutar paso a paso y depurar código en el IDE incluso si se trabaja con un clúster remoto.
Iterar rápidamente al desarrollar bibliotecas. No es necesario reiniciar el clúster después de cambiar las dependencias de biblioteca de Python en Databricks Connect, porque las sesiones de cliente están aisladas entre sí en el clúster.
Apagar los clústeres inactivos sin perder el trabajo realizado. Como la aplicación cliente está desacoplada del clúster, no se ve afectada al reiniciar o actualizar el clúster, lo que normalmente provocaría la pérdida de todas las variables, RDD y objetos DataFrame definidos en un cuaderno.
Para Databricks Runtime 13.0 y versiones posteriores, Databricks Connect ahora se basa en Spark Connect de código abierto. Spark Connect presenta una arquitectura de servidor cliente desacoplada para Apache Spark que permite la conectividad remota a clústeres de Spark mediante la API DataFrame y los planes lógicos sin resolver como protocolo. Con esta arquitectura "V2" basada en Spark Connect, Databricks Connect se convierte en un cliente fino que es sencillo y fácil de usar. Spark Connect se puede insertar en todas partes para conectarse a Azure Databricks: en entornos de desarrollo integrado, cuadernos y aplicaciones, lo que permite a usuarios y asociados individuales crear experiencias de usuario nuevas (interactivas) basadas en Databricks Lakehouse. Para obtener más información sobre Spark Connect, consulte Introducción a Spark Connect.
Databricks Connect determina dónde se ejecuta y depura el código, como se muestra en la ilustración siguiente.
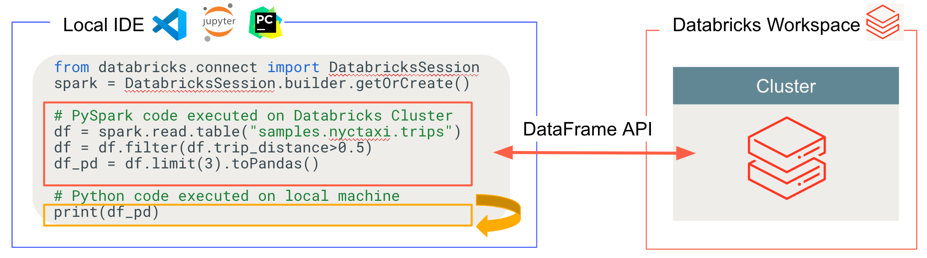
- Para ejecutar código: todo el código de Python se ejecuta localmente, mientras que todo el código pySpark que implique operaciones dataframe se ejecuta en el clúster en el área de trabajo remota de Azure Databricks y las respuestas de ejecución se envían de vuelta al autor de la llamada local.
- Para el código de depuración: todo Python se depura localmente, mientras que todo el código de PySpark continúa ejecutándose en el clúster en el área de trabajo remota de Azure Databricks. El código principal del motor de Spark no se puede depurar directamente desde el cliente.
Requisitos
En esta sección se enumeran los requisitos de Databricks Connect.
Un área de trabajo de Azure Databricks y su cuenta correspondiente habilitada para Unity Catalog. Consulte Introducción al uso de Unity Catalog y Habilitación de un área de trabajo para Unity Catalog.
Un clúster con Databricks Runtime 13.0 o versiones posteriores instalado.
Solo se admiten clústeres compatibles con Unity Catalog. Estos incluyen clústeres con modos de acceso compartido o asignados. Consulte Modos de acceso.
Debe instalar Python 3 en la máquina de desarrollo y la versión secundaria de la instalación de Python del cliente debe ser la misma que la versión secundaria de Python del clúster de Azure Databricks. En la tabla siguiente se muestra la versión de Python instalada con cada versión de Databricks Runtime.
Versión de Databricks Runtime Versión de Python 13.2 ML, 13.2 3.10 13.1 ML, 13.1 3.10 13.0 ML, 13.0 3.10 Nota:
Si desea usar UDF de PySpark, es importante que la versión secundaria instalada de la máquina de desarrollo de Python coincida con la versión secundaria de Python que se incluye con Databricks Runtime instalado en el clúster.
Databricks recomienda que tenga un entorno virtual de Python activado para cada versión de Python que use con Databricks Connect. Los entornos virtuales de Python ayudan a garantizar que usa las versiones correctas de Python y Databricks Connect juntas. Esto puede ayudar a reducir o acortar la resolución de problemas técnicos relacionados.
Por ejemplo, si usa venv en la máquina de desarrollo y el clúster ejecuta Python 3.10, debe crear un
venventorno con esa versión. El siguiente comando de ejemplo genera los scripts para activar unvenventorno con Python 3.10 y, a continuación, este comando coloca esos scripts en una carpeta oculta denominada.venvdentro del directorio de trabajo actual:# Linux and macOS python3.10 -m venv ./.venv # Windows python3.10 -m venv .\.venvPara activar este
venventorno con estos scripts, consulte Funcionamiento de venvs.La versión de los paquetes principal y secundario de Databricks Connect siempre debe coincidir con la versión de Databricks Runtime. Databricks recomienda usar siempre el paquete más reciente de Databricks Connect que coincida con la versión de Databricks Runtime. Por ejemplo, si usa un clúster de Databricks Runtime 13.1, use el paquete
databricks-connect==13.1.*.Nota:
Consulte las notas de la versión de Databricks Connect para una lista de las actualizaciones de mantenimiento y las versiones disponibles de Databricks Connect.
Usar el paquete más reciente de Databricks Connect que coincida con la versión de Databricks Runtime no es un requisito. A partir de Databricks Runtime 13.0, puede usar el paquete de Databricks Connect en todas las versiones de Databricks Runtime en o superior a la versión del paquete de Databricks Connect. Sin embargo, si desea usar características que están disponibles en versiones posteriores de Databricks Runtime, debe actualizar el paquete de Databricks Connect en consecuencia.
Configuración del cliente
Complete los pasos siguientes para configurar el cliente local de Databricks Connect.
Nota:
Antes de empezar a configurar el cliente de Databricks Connect, debe cumplir con los requisitos de este.
Sugerencia
Si ya tiene instalada la extensión de Databricks para Visual Studio Code, no es necesario seguir estas instrucciones de configuración.
La extensión de Databricks para Visual Studio Code ya cuenta con soporte técnico integrado de Databricks Connect para la versión Databricks Runtime 13.0 y posteriores. Vaya directamente a Ejecución o depuración de código de Python con Databricks Connect en la documentación de la extensión de Databricks para Visual Studio Code.
Paso 1: Instale el cliente de Databricks Connect
Con el entorno virtual activado, desinstale PySpark, si ya está instalado, ejecutando el comando
uninstall. Esto es necesario porque el paquetedatabricks-connectentra en conflicto con PySpark. Para información detallada, consulte Instalaciones de PySpark en conflicto. Para comprobar si PySpark ya está instalado, ejecute el comandoshow.# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkCon el entorno virtual aún activado, instale el cliente de Databricks Connect mediante la ejecución del comando
install. Use la opción--upgradepara actualizar cualquier instalación de cliente existente a la versión especificada.pip3 install --upgrade "databricks-connect==13.1.*" # Or X.Y.* to match your cluster version.Nota:
Databricks recomienda anexar la notación "dot-asterisk" para especificar
databricks-connect==X.Y.*en lugar dedatabricks-connect=X.Y, para asegurarse de que está instalado el paquete más reciente. Aunque esto no es un requisito, permite asegurarse de que puede usar las características más recientes que admite ese clúster.
Paso 2: Configuración de las propiedades de conexión
En esta sección, configurará las propiedades para establecer una conexión entre Databricks Connect y el clúster remoto de Azure Databricks. Estas propiedades incluyen la configuración para autenticar Databricks Connect con el clúster.
A partir de Databricks Connect para Databricks Runtime 13.1 y versiones posteriores, Databricks Connect incluye el SDK de Databricks para Python. Este SDK implementa el estándar de autenticación unificada del cliente de Databricks, un enfoque arquitectónico y programático consolidado y coherente para la autenticación. Este enfoque configura y automatiza la autenticación con Azure Databricks de manera más centralizada y predecible. Permite configurar la autenticación de Azure Databricks una vez y, a continuación, usar esa configuración en varias herramientas y SDK de Azure Databricks sin cambios adicionales en la configuración de autenticación.
Nota:
El SDK de Databricks para Python aún no ha implementado la autenticación MSI de Azure.
Databricks Connect para Databricks Runtime 13.0 solo admite la autenticación de token de acceso personal de Azure Databricks para la autenticación.
Recopile las propiedades de configuración siguientes.
- Nombre de instancia de área de trabajo de Azure Databricks. Se trata del mismo valor que el valor Nombre de host del servidor de su clúster. Consulte Obtención de los detalles de conexión de un clúster.
- Identificador del clúster. Puede obtenerlo de la dirección URL. Consulte Dirección URL e identificador del clúster.
- Cualquier otra propiedad necesaria para el tipo de autenticación de Databricks que quiera usar como se indica a continuación.
Configure la conexión dentro del código. Databricks Connect busca propiedades de configuración en el orden siguiente hasta que las encuentre. Una vez que las encuentra, deja de buscar en las opciones restantes:
Solo para la autenticación de tokens de acceso personal de Azure Databricks, la configuración directa de las propiedades de conexión, especificada a través de la
DatabricksSessionclasePara esta opción, que solo se aplica a la autenticación de token de acceso personal de Azure Databricks, especifica el nombre de la instancia del área de trabajo, el token de acceso personal de Azure Databricks y el identificador del clúster.
Los siguientes ejemplos de código muestran cómo inicializar la clase
DatabricksSessionpara la autenticación de token de acceso personal de Azure Databricks.Databricks no recomienda especificar directamente estas propiedades de conexión en el código. En su lugar, Databricks recomienda configurar las propiedades mediante las variables de entorno o los archivos de configuración, como se describe en las opciones posteriores. En los ejemplos de código siguientes se supone que se proporciona alguna implementación de las funciones propuestas de
retrieve_*para obtener las propiedades necesarias del usuario o de algún otro almacén de configuración, como Azure KeyVault.# By setting fields in builder.remote: from databricks.connect import DatabricksSession spark = DatabricksSession.builder.remote( host = f"https://{retrieve_workspace_instance_name()}", token = retrieve_token(), cluster_id = retrieve_cluster_id() ).getOrCreate() # Or, by using the Databricks SDK's Config class: from databricks.connect import DatabricksSession from databricks.sdk.core import Config config = Config( host = f"https://{retrieve_workspace_instance_name()}", token = retrieve_token(), cluster_id = retrieve_cluster_id() ) spark = DatabricksSession.builder.sdkConfig(config).getOrCreate() # Or, specify a Databricks configuration profile and # the cluster_id field separately: from databricks.connect import DatabricksSession from databricks.sdk.core import Config config = Config( profile = "<profile-name>", cluster_id = retrieve_cluster_id() ) spark = DatabricksSession.builder.sdkConfig(config).getOrCreate() # Or, by setting the Spark Connect connection string in builder.remote: from databricks.connect import DatabricksSession workspace_instance_name = retrieve_workspace_instance_name() token = retrieve_token() cluster_id = retrieve_cluster_id() spark = DatabricksSession.builder.remote( f"sc://{workspace_instance_name}:443/;token={token};x-databricks-cluster-id={cluster_id}" ).getOrCreate()Para todos los tipos de autenticación de Azure Databricks, un nombre de perfil de configuración de Azure Databricks, especificado mediante
profile()En el caso de esta opción, cree o identifique un perfil de configuración de Azure Databricks que contenga el campo
cluster_idy cualquier otro campo necesario para el tipo de autenticación de Databricks que quiere usar.Los campos de perfil de configuración necesarios para cada tipo de autenticación son los siguientes:
- Para la autenticación de token de acceso personal de Azure Databricks:
hostytoken. - Para la Autenticación de usuario a máquina (U2M) de OAuth:
host,azure_tenant_id,azure_client_id, yazure_client_secret. - Para la Autenticación de entidad de servicio de Azure:
host,azure_tenant_id,azure_client_id,azure_client_secret, y posiblementeazure_workspace_resource_id. - Para la Autenticación de la CLI de Azure:
host.
Luego, establezca el nombre de este perfil de configuración mediante la clase
Config.Como alternativa, puede especificar
cluster_idpor separado del perfil de configuración. En lugar de especificar directamente el id. del clúster en el código, en los ejemplos de código siguientes se supone que se proporciona alguna implementación de la función propuesta deretrieve_cluster_idpara obtener el id. del clúster del usuario o de algún otro almacén de configuración, como Azure KeyVault.Por ejemplo:
# Specify a Databricks configuration profile that contains the # cluster_id field: from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate()- Para la autenticación de token de acceso personal de Azure Databricks:
Solo para la autenticación de token de acceso personal de Azure Databricks, la
SPARK_REMOTEvariable de entornoPara esta opción, que se aplica solo a la autenticación de token de acceso personal de Azure Databricks, establece la variable de entorno
SPARK_REMOTEen la siguiente cadena, reemplazando los marcadores de posición con los valores adecuados.sc://<workspace-instance-name>:443/;token=<access-token-value>;x-databricks-cluster-id=<cluster-id>Y, a continuación, inicialice la clase
DatabricksSessioncomo se indica:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()Para establecer las variables de entorno, consulte la documentación del sistema operativo.
Para todos los tipos de autenticación de Azure Databricks, la
DATABRICKS_CONFIG_PROFILEvariable de entornoEn el caso de esta opción, cree o identifique un perfil de configuración de Azure Databricks que contenga el campo
cluster_idy cualquier otro campo necesario para el tipo de autenticación de Databricks que quiere usar.Los campos de perfil de configuración necesarios para cada tipo de autenticación son los siguientes:
- Para la autenticación de token de acceso personal de Azure Databricks:
hostytoken. - Para la Autenticación de usuario a máquina (U2M) de OAuth:
host,azure_tenant_id,azure_client_id, yazure_client_secret. - Para la Autenticación de entidad de servicio de Azure:
host,azure_tenant_id,azure_client_id,azure_client_secret, y posiblementeazure_workspace_resource_id. - Para la Autenticación de la CLI de Azure:
host.
Establezca la variable de entorno
DATABRICKS_CONFIG_PROFILEcon el nombre de este perfil de configuración. Y, a continuación, inicialice la claseDatabricksSessioncomo se indica:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()Para establecer las variables de entorno, consulte la documentación del sistema operativo.
- Para la autenticación de token de acceso personal de Azure Databricks:
Para todos los tipos de autenticación de Azure Databricks, una variable de entorno para cada propiedad de conexión
En esta opción, establezca la variable de entorno
DATABRICKS_CLUSTER_IDy cualquier otra variable de entorno necesaria para el tipo de autenticación de Databricks que quiere usar.Las variables de entorno necesarias para cada tipo de autenticación son las siguientes:
- Para la autenticación de token de acceso personal de Azure Databricks:
DATABRICKS_HOSTyDATABRICKS_TOKEN. - Para la Autenticación de usuario a máquina (U2M) de OAuth:
DATABRICKS_HOST,ARM_TENANT_ID,ARM_CLIENT_ID, yARM_CLIENT_SECRET. - Para la Autenticación de entidad de servicio de Azure:
DATABRICKS_HOST,ARM_TENANT_ID,ARM_CLIENT_ID,ARM_CLIENT_SECRET, y posiblementeDATABRICKS_AZURE_RESOURCE_ID. - Para la Autenticación de la CLI de Azure:
DATABRICKS_HOST.
Y, a continuación, inicialice la clase
DatabricksSessioncomo se indica:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()Para establecer las variables de entorno, consulte la documentación del sistema operativo.
- Para la autenticación de token de acceso personal de Azure Databricks:
Para todos los tipos de autenticación de Azure Databricks, un perfil de configuración de Azure Databricks denominado
DEFAULTEn el caso de esta opción, cree o identifique un perfil de configuración de Azure Databricks que contenga el campo
cluster_idy cualquier otro campo necesario para el tipo de autenticación de Databricks que quiere usar.Los campos de perfil de configuración necesarios para cada tipo de autenticación son los siguientes:
- Para la autenticación de token de acceso personal de Azure Databricks:
hostytoken. - Para la Autenticación de usuario a máquina (U2M) de OAuth:
host,azure_tenant_id,azure_client_id, yazure_client_secret. - Para la Autenticación de entidad de servicio de Azure:
host,azure_tenant_id,azure_client_id,azure_client_secret, y posiblementeazure_workspace_resource_id. - Para la Autenticación de la CLI de Azure:
host.
Asigne a este perfil de configuración el nombre
DEFAULT.Y, a continuación, inicialice la clase
DatabricksSessioncomo se indica:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()- Para la autenticación de token de acceso personal de Azure Databricks:
Si eliges usar la autenticación de token de acceso personal de Azure Databricks, puedes usar la utilidad
pysparkincluida para probar la conectividad con su clúster de Azure Databricks de la siguiente manera.Con el entorno virtual aún activado, ejecute el siguiente comando:
Si ya definió la variable de entorno
SPARK_REMOTEanteriormente, ejecute el siguiente comando:pysparkSi no definió la variable de entorno
SPARK_REMOTEanteriormente, ejecute el siguiente comando:pyspark --remote "sc://<workspace-instance-name>:443/;token=<access-token-value>;x-databricks-cluster-id=<cluster-id>"Aparece el shell de Spark, por ejemplo:
Python 3.10 ... [Clang ...] on darwin Type "help", "copyright", "credits" or "license" for more information. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 13.0 /_/ Using Python version 3.10 ... Client connected to the Spark Connect server at sc://...:.../;token=...;x-databricks-cluster-id=... SparkSession available as 'spark'. >>>En la solicitud de
>>>, ejecute un sencillo comando PySpark, comospark.range(1,10).show(). Si no hay errores, se ha conectado correctamente.Si se ha conectado correctamente, para detener el shell de Spark, presione
Ctrl + doCtrl + z, o ejecute el comandoquit()oexit().
Uso de Databricks Connect
En estas secciones se describe cómo configurar muchos entornos de desarrollo integrado y servidores de cuadernos populares para usar el cliente de Databricks Connect. O bien, puede usar el shell de Spark integrado.
En esta sección:
- JupyterLab con Python
- Jupyter Notebook clásica con Python
- Visual Studio Code con Python
- PyCharm con Python
- Eclipse con PyDev
- Shell de Spark con Python
JupyterLab con Python
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Si quiere usar Databricks Connect con JupyterLab y Python, siga estas instrucciones.
Para instalar JupyterLab, con el entorno virtual de Python activado, ejecute el siguiente comando desde el terminal o el símbolo del sistema:
pip3 install jupyterlabPara iniciar JupyterLab en el explorador web, ejecute el siguiente comando desde el entorno virtual de Python activado:
jupyter labSi JupyterLab no aparece en el explorador web, copie la dirección URL que comienza por
localhosto127.0.0.1desde su entorno virtual y escríbala en la barra de direcciones del explorador web.Crear un cuaderno nuevo: en el menú principal de JupyterLab, haga clic en Archivo > Nuevo > Cuaderno , seleccione Python 3 (ipykernel) y haga clic en Seleccionar.
En la primera celda del cuaderno, escriba el código de ejemplo o su propio código. Si usa su propio código, como mínimo debe inicializar
DatabricksSession, como se muestra en el código de ejemplo.Para ejecutar el cuaderno, haga clic en Run > Run All Cells. Todo el código de Python se ejecuta localmente, mientras que todo el código de PySpark que involucra operaciones de DataFrame se ejecuta en el clúster en el área de trabajo remota de Azure Databricks y las respuestas de ejecución se envían de vuelta al autor de la llamada local.
Para depurar el cuaderno, haga clic en el icono de error (Enable Debugger) situado junto a Python 3 (ipykernel) en la barra de herramientas del cuaderno. Establezca uno o varios puntos de interrupción y, a continuación, haga clic en Run > Run All Cells. Todo Python se depura localmente, mientras que todo el código de PySpark continúa ejecutándose en el clúster en el área de trabajo remota de Azure Databricks. El código principal del motor de Spark no se puede depurar directamente desde el cliente.
Para apagar JupyterLab, haga clic en File > Shut Down. Si el proceso de JupyterLab todavía se está ejecutando en el terminal o en el símbolo del sistema, detenga este proceso presionando
Ctrl + cy después escribiendoypara confirmar.
Para obtener instrucciones de depuración más específicas, consulte Depurador.
Jupyter Notebook clásica con Python
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Para usar Databricks Connect con Jupyter Notebook clásico y Python, siga estas instrucciones.
Para instalar JupyterLab Notebook clásico, con el entorno virtual de Python activado, ejecute el siguiente comando desde el terminal o el símbolo del sistema:
pip3 install notebookPara iniciar JupyterLab Notebook en el explorador web, ejecute el siguiente comando desde el entorno virtual de Python activado:
jupyter notebookSi JupyterLab Notebook no aparece en el explorador web, copie la dirección URL que comienza por
localhosto127.0.0.1desde su entorno virtual y escríbala en la barra de direcciones del explorador web.Cree un cuaderno nuevo: en el Jupyter Notebook clásico, en la pestaña Archivos, haga clic en Nuevo > Python 3 (ipykernel).
En la primera celda del cuaderno, escriba el código de ejemplo o su propio código. Si usa su propio código, como mínimo debe inicializar
DatabricksSession, como se muestra en el código de ejemplo.Para ejecutar el cuaderno, haga clic en Celda > Ejecutar todas. Todo el código de Python se ejecuta localmente, mientras que todo el código de PySpark que involucra operaciones de DataFrame se ejecuta en el clúster en el área de trabajo remota de Azure Databricks y las respuestas de ejecución se envían de vuelta al autor de la llamada local.
Para depurar el cuaderno, agregue la siguiente línea de código al principio del cuaderno:
from IPython.core.debugger import set_traceY, a continuación, llame a
set_trace()para escribir instrucciones de depuración en ese punto de ejecución del cuaderno. Todo Python se depura localmente, mientras que todo el código de PySpark continúa ejecutándose en el clúster en el área de trabajo remota de Azure Databricks. El código principal del motor de Spark no se puede depurar directamente desde el cliente.Para apagar el Jupyter Notebook clásico, haga clic en Archivo > Cerrar y detener archivo. Si el proceso de JupyterLab Notebook clásico todavía se está ejecutando en el terminal o en el símbolo del sistema, detenga este proceso presionando
Ctrl + cy después escribiendoypara confirmar.
Visual Studio Code con Python
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Sugerencia
La extensión de Databricks para Visual Studio Code ya cuenta con soporte técnico integrado de Databricks Connect para la versión Databricks Runtime 13.0 y posteriores. Consulte Ejecución o depuración de código de Python con Databricks Connect en la documentación de la extensión de Databricks para Visual Studio Code.
Si quiere usar Databricks Connect con Visual Studio Code y Python, siga estas instrucciones.
Inicie Visual Studio Code.
Abra la carpeta que contiene el entorno virtual de Python (Archivo > Abrir carpeta).
En el terminal de Visual Studio Code (Ver > Terminal), active el entorno virtual.
Establezca el intérprete de Python actual para que sea el que se encuentra en el entorno virtual:
- En la paleta de comandos (Ver > Paleta de comandos), escriba
Python: Select Interpretery, a continuación, presione Entrar. - Seleccione la ruta de acceso al intérprete de Python al que se hace referencia en el entorno virtual.
- En la paleta de comandos (Ver > Paleta de comandos), escriba
Agregue a la carpeta un archivo de código de Python (
.py) que contenga el código de ejemplo o su propio código. Si usa su propio código, como mínimo debe inicializarDatabricksSession, como se muestra en el código de ejemplo.Para ejecutar el código, haga clic en Ejecución > Ejecutar sin depurar en el menú principal. Todo el código de Python se ejecuta localmente, mientras que todo el código de PySpark que involucra operaciones de DataFrame se ejecuta en el clúster en el área de trabajo remota de Azure Databricks y las respuestas de ejecución se envían de vuelta al autor de la llamada local.
Para depurar el código:
- Con el archivo de código de Python abierto, establezca los puntos de interrupción en los que quiera que se detenga el código cuando se ejecuta.
- Haga clic en el icono Ejecutar y depurar de la barra lateral o haga clic en Ver > Ejecutar en el menú principal.
- En la vista Ejecutar y depurar, haga clic en el botón Ejecutar y depurar.
- Siga las instrucciones que aparecen en pantalla para empezar a ejecutar y depurar el código.
Todo Python se depura localmente, mientras que todo el código de PySpark continúa ejecutándose en el clúster en el área de trabajo remota de Azure Databricks. El código principal del motor de Spark no se puede depurar directamente desde el cliente.
Para obtener instrucciones de ejecución y depuración más específicas, consulte Configuración y ejecución del depurador y Depuración de Python en VS Code.
PyCharm con Python
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
IntelliJ IDEA Ultimate también proporciona compatibilidad de complementos para PyCharm con Python. Para más información, consulte Complemento de Python para IntelliJ IDEA Ultimate.
Si quiere usar Databricks Connect con PyCharm y Python, siga estas instrucciones.
- Inicie PyCharm.
- Cree un proyecto: haga clic en File > New Project.
- En Location, haga clic en el icono de carpeta y, a continuación, seleccione la ruta de acceso al entorno virtual.
- Seleccione Previously configured interpreter.
- En Interpreter, haga clic en los puntos suspensivos.
- Haga clic en System Interpreter.
- En Intérprete, haga clic en los puntos suspensivos y seleccione la ruta de acceso completa al intérprete de Python al que se hace referencia en el entorno virtual. A continuación, haga clic en Aceptar.
- Haga clic en Aceptar nuevamente.
- Haga clic en Crear.
- Haga clic en Create from Existing Sources.
- Agregue al proyecto un archivo de código de Python (
.py) que contenga el código de ejemplo o su propio código. Si usa su propio código, como mínimo debe inicializarDatabricksSession, como se muestra en el código de ejemplo. - Con el archivo de código de Python abierto, establezca los puntos de interrupción en los que quiera que se detenga el código cuando se ejecuta.
- Para ejecutar el código, haga clic en Ejecución > Ejecutar. Todo el código de Python se ejecuta localmente, mientras que todo el código de PySpark que involucra operaciones de DataFrame se ejecuta en el clúster en el área de trabajo remota de Azure Databricks y las respuestas de ejecución se envían de vuelta al autor de la llamada local.
- Para depurar el código, haga clic en Ejecución > Depurar. Todo Python se depura localmente, mientras que todo el código de PySpark continúa ejecutándose en el clúster en el área de trabajo remota de Azure Databricks. El código principal del motor de Spark no se puede depurar directamente desde el cliente.
- Siga las instrucciones que aparecen en pantalla para empezar a ejecutar o depurar el código.
Para obtener instrucciones de ejecución y depuración más específicas, consulte Ejecución sin configuración previa y Depuración.
Eclipse con PyDev
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Para usar Databricks Connect y Eclipse con PyDev, siga estas instrucciones.
- Inicie Eclipse.
- Cree un proyecto: haga clic en Archivo > Nuevo > Proyecto > PyDev > Proyecto de PyDev y , a continuación, haga clic en Siguiente.
- Especifique un nombre de proyecto.
- En Contenido del proyecto, especifique la ruta de acceso al entorno virtual de Python.
- Haga clic en Configurar un intérprete antes de continuar.
- Haga clic en Configuración manual.
- Haga clic en Nuevo > Buscar python/pypy exe.
- Navegue hasta la ruta de acceso completa al intérprete de Python al que se hace referencia en el entorno virtual y selecciónela. A continuación, haga clic en Abrir.
- En el diálogo Seleccionar intérprete, haga clic en Aceptar.
- En el diálogo Selección necesaria, haga clic en Aceptar.
- En el diálogo Preferencias, haga clic en Aplicar y cerrar.
- En el diálogo Proyecto de PyDev, haga clic en Finalizar.
- Haga clic en Abrir perspectiva.
- Agregue al proyecto un archivo de código de Python (
.py) que contenga el código de ejemplo o su propio código. Si usa su propio código, como mínimo debe inicializarDatabricksSession, como se muestra en el código de ejemplo. - Con el archivo de código de Python abierto, establezca los puntos de interrupción en los que quiera que se detenga el código cuando se ejecuta.
- Para ejecutar el código, haga clic en Ejecución > Ejecutar. Todo el código de Python se ejecuta localmente, mientras que todo el código de PySpark que involucra operaciones de DataFrame se ejecuta en el clúster en el área de trabajo remota de Azure Databricks y las respuestas de ejecución se envían de vuelta al autor de la llamada local.
- Para depurar el código, haga clic en Ejecución > Depurar. Todo Python se depura localmente, mientras que todo el código de PySpark continúa ejecutándose en el clúster en el área de trabajo remota de Azure Databricks. El código principal del motor de Spark no se puede depurar directamente desde el cliente.
Para obtener instrucciones de ejecución y depuración más específicas, consulte Ejecución de un programa.
Shell de Spark con Python
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
El shell de Spark funciona solo con la autenticación de token de acceso personal de Azure Databricks.
Si quiere usar Databricks Connect con el shell de Spark y Python, siga estas instrucciones.
Para iniciar el shell de Spark y conectarlo al clúster en ejecución, ejecute uno de los siguientes comandos desde el entorno virtual activado de Python:
Si ya definió la variable de entorno
SPARK_REMOTEanteriormente, ejecute el siguiente comando:pysparkSi no definió la variable de entorno
SPARK_REMOTEanteriormente, ejecute el siguiente comando:pyspark --remote "sc://<workspace-instance-name>:443/;token=<access-token-value>;x-databricks-cluster-id=<cluster-id>"Aparece el shell de Spark, por ejemplo:
Python 3.10 ... [Clang ...] on darwin Type "help", "copyright", "credits" or "license" for more information. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 13.x.dev0 /_/ Using Python version 3.10 ... Client connected to the Spark Connect server at sc://...:.../;token=...;x-databricks-cluster-id=... SparkSession available as 'spark'. >>>Consulte Análisis interactivo con el shell de Spark para obtener información sobre cómo usar el shell de Spark con Python para ejecutar comandos en el clúster.
Use la variable integrada
sparkpara representar el elementoSparkSessiondel clúster en ejecución, por ejemplo:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsTodo el código de Python se ejecuta localmente, mientras que todo el código de PySpark que involucra operaciones de DataFrame se ejecuta en el clúster en el área de trabajo remota de Azure Databricks y las respuestas de ejecución se envían de vuelta al autor de la llamada local.
Para detener el shell de Spark, presiona
Ctrl + doCtrl + z, o ejecute el comandoquit()oexit().
Ejemplos de código
Databricks proporciona varias aplicaciones de ejemplo que muestran cómo usar Databricks Connect. Consulte el repositorio databricks-demos/dbconnect-examples en GitHub.
También puede usar los siguientes ejemplos de código más simples para experimentar con Databricks Connect. En estos ejemplos se supone que usa la autenticación predeterminada para Databricks Connect.
Este ejemplo de código simple consulta la tabla especificada y, a continuación, muestra las cinco primeras filas de la tabla especificada. Para usar otra tabla, ajuste la llamada a spark.read.table.
from databricks.connect import DatabricksSession
spark = DatabricksSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Este ejemplo de código más largo hace lo siguiente:
- Crea un DataFrame en memoria.
- Crea una tabla con el nombre
zzz_demo_temps_tabledentro del esquemadefault. Si la tabla con este nombre ya existe, primero se elimina la tabla. Para usar un esquema o tabla diferente, ajuste las llamadas aspark.sql,temps.write.saveAsTableo ambas. - Guarda el contenido de DataFrame en la tabla.
- Ejecuta una consulta
SELECTen el contenido de la tabla. - Muestra el resultado de la consulta.
- Elimina la tabla.
from databricks.connect import DatabricksSession
from pyspark.sql.types import *
from datetime import date
spark = DatabricksSession.builder.getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Migrar Databricks Connect más reciente
Siga estas instrucciones para migrar el proyecto de código de Python existente o el entorno de codificación desde Databricks Connect para Databricks Runtime 12.2 LTS y versiones anteriores a Databricks Connect para Databricks Runtime 13.0 y versiones posteriores.
Nota:
Databricks Connect para Databricks Runtime 13.0 y versiones posteriores actualmente solo admite proyectos basados en Python y entornos de codificación.
Instale la versión correcta de Python como se muestra en los requisitos para que coincidan con el clúster de Azure Databricks, si aún no está instalado localmente.
Actualice el entorno virtual de Python para usar la versión correcta de Python para que coincida con el clúster, si es necesario. Para obtener instrucciones, consulte la documentación del proveedor de entorno virtual.
Con el entorno virtual activado, desinstale PySpark de su entorno virtual:
pip3 uninstall pysparkCon el entorno virtual aún activado, desinstale Databricks Connect para Databricks Runtime 12.2 LTS y versiones anteriores:
pip3 uninstall databricks-connectCon el entorno virtual aún activado, desinstale Databricks Connect para Databricks Runtime 13.0 y versiones posteriores:
pip3 install --upgrade "databricks-connect==13.1.*" # Or X.Y.* to match your cluster version.Nota:
Databricks recomienda anexar la notación "dot-asterisk" para especificar
databricks-connect==X.Y.*en lugar dedatabricks-connect=X.Y, para asegurarse de que está instalado el paquete más reciente. Aunque esto no es un requisito, permite asegurarse de que puede usar las características más recientes que admite ese clúster.Actualice el código de Python para inicializar la variable
spark(que representa una creación de instancias de la claseDatabricksSession, similar aSparkSessionen PySpark). Para obtener ejemplos de código, vea Paso 2: Configurar las propiedades de conexión.
Acceso a las utilidades de Databricks
En esta sección se describe cómo usar Databricks Connect para acceder a las utilidades de Databricks.
Puede llamar a funciones del Sistema de archivos de Databricks (DBFS) desde un área de trabajo de Azure Databricks. Para ello, se usa la variable de WorkspaceClient la clase dbfs. Este enfoque es similar a llamar a las utilidades de Databricks a través de la variable dbfs desde un cuaderno dentro de un área de trabajo. La clase WorkspaceClient pertenece al SDK de Databricks para Python, que se incluye en Databricks Connect para Databricks Runtime 13.0 y versiones posteriores.
Sugerencia
También puede usar el SDK de Databricks incluido para Python para acceder a cualquier API de REST de Databricks disponible, no solo a la API de DBFS. Consulte databricks-sdk en PyPI.
Para inicializar WorkspaceClient, debe proporcionar suficiente información para autenticar el SDK de Databricks para Python con el área de trabajo. Por ejemplo, puede:
Codifique de forma rígida la dirección URL del área de trabajo y el token de acceso directamente dentro del código y, a continuación, inicialice
WorkspaceClientcomo se indica a continuación. Aunque se admite esta opción, Databricks no la recomienda, ya que puede exponer información confidencial, como tokens de acceso, si el código se registra en el control de versiones o se comparte de otro modo:w = WorkspaceClient(host = "https://<workspace-instance-name>", token = "<access-token-value")Cree o especifique un perfil de configuración que contenga los campos
hostytokeny, a continuación, inicialiceWorkspaceClientcomo se indica a continuación:w = WorkspaceClient(profile = "<profile-name>")Establezca las variables de entorno
DATABRICKS_HOSTyDATABRICKS_TOKENde la misma manera que las ha establecido para Databricks Connect. A continuación, inicialiceWorkspaceClientcomo se indica:w = WorkspaceClient()
El SDK de Databricks para Python no reconoce la variable de entorno SPARK_REMOTE para Databricks Connect.
Para obtener más opciones de autenticación de Azure Databricks para el SDK de Databricks para Python, así como para saber cómo inicializar AccountClient en el SDK de Databricks para Python y acceder a las API REST de Databricks disponibles en el nivel de cuenta en lugar de en el nivel de área de trabajo, consulte databricks-sdk en PyPI.
En el ejemplo siguiente se crea un archivo denominado zzz_hello.txt en la raíz de DBFS dentro del área de trabajo, se escriben datos en el archivo, se cierra el archivo, se leen los datos del archivo y, a continuación, se elimina el archivo. En este ejemplo se supone que las variables de entorno DATABRICKS_HOST y DATABRICKS_TOKEN ya se han establecido:
from databricks.sdk import WorkspaceClient
import base64
w = WorkspaceClient()
file_path = "/zzz_hello.txt"
file_data = "Hello, Databricks!"
# The data must be base64-encoded before being written.
file_data_base64 = base64.b64encode(file_data.encode())
# Create the file.
file_handle = w.dbfs.create(
path = file_path,
overwrite = True
).handle
# Add the base64-encoded version of the data.
w.dbfs.add_block(
handle = file_handle,
data = file_data_base64.decode()
)
# Close the file after writing.
w.dbfs.close(handle = file_handle)
# Read the file's contents and then decode and print it.
response = w.dbfs.read(path = file_path)
print(base64.b64decode(response.data).decode())
# Delete the file.
w.dbfs.delete(path = file_path)
Sugerencia
También puede acceder a la utilidad de los secretos de las utilidades de Databricks a través de w.secrets, la utilidad de trabajos a través de w.jobs y la utilidad de biblioteca a través de w.libraries.
Deshabilitación de Databricks Connect
Los servicios de Databricks Connect (y Spark Connect subyacente) se pueden deshabilitar en cualquier clúster determinado. Para deshabilitar el servicio de Databricks Connect, define la siguiente configuración de Spark en el clúster.
spark.databricks.service.server.enabled false
Una vez que se deshabilite, las consultas de Databricks Connect que llegan al clúster se rechazan con un mensaje de error adecuado.
Establecimiento de las configuraciones de Hadoop
En el cliente, puede establecer configuraciones de Hadoop mediante la API spark.conf.set, que se aplica a las operaciones de DataFrame y SQL. Las configuraciones de Hadoop establecidas en sparkContext se deben establecer en la configuración del clúster o mediante un cuaderno. Esto se debe a que las configuraciones establecidas en sparkContext no están vinculadas a sesiones de usuario, sino que se aplican a todo el clúster.
Solución de problemas
En esta sección se describen algunos problemas comunes que pueden surgir con Databricks Connect y cómo resolverlos.
En esta sección:
- Error: StatusCode.UNAVAILABLE, StatusCode.UNKNOWN, Resolución DNS con errores o Recibido encabezado http2 con estado 500
- Versión de Python no coincidente
- Instalaciones de PySpark en conflicto
- Entrada ausente o en conflicto
PATHpara los archivos binarios - La sintaxis del nombre de archivo, el nombre del directorio o la etiqueta de volumen no es correcta en Windows
Error: StatusCode.UNAVAILABLE, StatusCode.UNKNOWN, Resolución DNS con errores o Recibido encabezado http2 con estado 500
Problema: al intentar ejecutar código con Databricks Connect, obtiene un mensaje de error que contiene cadenas como StatusCode.UNAVAILABLE, StatusCode.UNKNOWN, DNS resolution failed o Received http2 header with status: 500.
Causa posible: Databricks Connect no puede acceder al clúster.
Soluciones recomendadas:
- Asegúrese de que el nombre de la instancia del área de trabajo sea correcto. Si usa variables de entorno, asegúrese de que la variable de entorno relacionada esté disponible y sea correcta en la máquina de desarrollo local.
- Asegúrese de que el identificador del clúster sea correcto. Si usa variables de entorno, asegúrese de que la variable de entorno relacionada esté disponible y sea correcta en la máquina de desarrollo local.
- Asegúrese de que el clúster tenga la versión personalizada del clúster correcta y que sea compatible con Databricks Connect.
Versión de Python no coincidente
Compruebe que la versión de Python que utiliza localmente tiene al menos la misma versión secundaria que la versión existente en el clúster (por ejemplo, se admite 3.10.11 respecto de 3.10.10, pero no 3.10 respecto de 3.9).
Si tiene varias versiones de Python instaladas en el entorno local, asegúrese de que Databricks Connect utiliza la correcta; para ello, establezca la variable de entorno PYSPARK_PYTHON (por ejemplo, PYSPARK_PYTHON=python3).
Instalaciones de PySpark en conflicto
El paquete databricks-connect entra en conflicto con PySpark. Tener ambos instalados generará errores al inicializar el contexto de Spark en Python. Estos conflictos se pueden manifestar de varias maneras, incluidos errores de "flujo dañado" o "no se encontró la clase". Si tiene instalado PySpark en el entorno de Python, asegúrese de desinstalarlo antes de instalar databricks-connect. Una vez que desinstale PySpark, no olvide volver a instalar completamente el paquete de Databricks Connect:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==13.1.*" # or X.Y.* to match your specific cluster version.
Entrada PATH faltante o en conflicto para los archivos binarios
Es posible que la ruta de acceso PATH esté configurada para que comandos como spark-shell ejecuten otro archivo binario instalado previamente en lugar del que se incluye con Databricks Connect. Debe asegurarse de que los archivos binarios de Databricks Connect tengan prioridad, o bien quitar los instalados previamente.
Si no puede ejecutar comandos como spark-shell, también es posible que pip3 install no haya configurado automáticamente la ruta de acceso PATH y deberá agregar el directorio bin de instalación a la ruta de acceso PATH de manera manual. Es posible utilizar Databricks Connect con los IDE aunque no esté configurado.
La sintaxis del nombre de archivo, el nombre del directorio o la etiqueta de volumen no es correcta en Windows
Si utiliza Databricks Connect en Windows y ve lo siguiente:
The filename, directory name, or volume label syntax is incorrect.
Databricks Connect se instaló en un directorio con un espacio en la ruta de acceso. Una solución alternativa es hacer la instalación en una ruta de acceso de directorio sin espacios o configurar la ruta de acceso con el formato de nombre corto.
Limitaciones
Databricks Connect no admite las siguientes características de Azure Databricks y plataformas de terceros.
Limitaciones de la API de DataFrame de PySpark
- La clase
SparkContexty sus métodos no están disponibles. - No se admiten los conjuntos de datos distribuidos resistentes (RDD) ni los conjuntos de datos. Solo se admiten dataframes.
Limitaciones de Azure Databricks y Databricks Connect
- No se admiten consultas con una duración superior a 3600 segundos y se producirá un error.
- No se admite la sincronización del entorno de desarrollo local con el clúster remoto.
- Asegúrese de que la versión de Python y los paquetes de Python que use en el entorno de desarrollo local coincidan con sus equivalentes instalados en el clúster tanto como sea posible para ayudar a garantizar la compatibilidad del código y para ayudar a reducir los errores inesperados en tiempo de ejecución.
- Solo se admite Python. No se admiten R, Scala ni Java.
- No se admite el entrenamiento distribuido.
- Se admite MLflow, pero no la inferencia de modelos con
mlflow.pyfunc.spark_udf(spark, ...). Puede cargar el modelo localmente conmlflow.pyfunc.load_model(<model>)o puede encapsularlo como una UDF de Pandas personalizada. - No se puede cambiar el nivel de registro de Log4j a través de
SparkContext. - Mosaic no se admite.
Limitaciones del clúster de Azure Databricks
El usuario del área de trabajo de Azure Databricks que está asociado a un token de acceso que usa Databricks Connect debe tener permisos Puede asociar a o superiores para el clúster de destino.
CREATE TABLE table AS SELECT ...Los comandos SQL no siempre funcionan. En su lugar, usespark.sql("SELECT ...").write.saveAsTable("table").El acceso directo a credenciales de Azure Active Directory solo se admite en clústeres estándar que ejecutan Databricks Runtime 7.3 LTS y versiones posteriores, y no es compatible con la autenticación de la entidad de servicio.
Los tokens de Azure Active Directory (AD) no se actualizan automáticamente y expirarán una hora después de que se generen inicialmente.
Las utilidades de Databricks siguientes: