Ejecución de un cuaderno de Python como trabajo mediante la extensión Databricks para Visual Studio Code
Este artículo describe cómo ejecutar un cuaderno de Python como un trabajo Azure Databricks usando la extensión Databricks para Visual Studio Code. Consulte ¿Qué es la extensión de Databricks para Visual Studio Code?.
Para ejecutar un archivo de Python como trabajo de Azure Databricks en su lugar, consulte Ejecución de un archivo de Python como trabajo mediante la extensión Databricks para Visual Studio Code. Para ejecutar un cuaderno de R, Scala, o SQL como trabajo de Azure Databricks, consulte Ejecución de un cuaderno de R, Scala o SQL como trabajo mediante la extensión Databricks para Visual Studio Code.
En esta información se asume que ya ha instalado y configurado la extensión de Databricks para Visual Studio Code. Consulte Instalación de la extensión de Databricks para Visual Studio Code.
Con la extensión y el proyecto de código abiertos, haga lo siguiente:
En el proyecto de código, abra el cuaderno de Python que quiere ejecutar como un trabajo.
Sugerencia
Para crear un archivo de cuaderno de Python en Visual Studio Code, comience haciendo clic en Archivo > Nuevo archivo, seleccione Archivo de Python y guarde el nuevo archivo con una extensión de archivo
.py.Para convertir el archivo
.pyen un cuaderno de Azure Databricks, agregue el comentario especial# Databricks notebook sourceal principio del archivo y agregue el comentario especial# COMMAND ----------antes de cada celda. Para obtener más información, consulte Importación de un archivo y conversión del archivo en un cuaderno.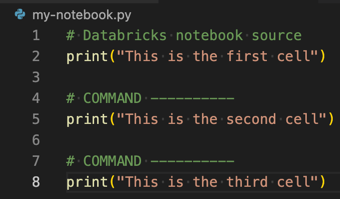
Realice una de las siguientes acciones:
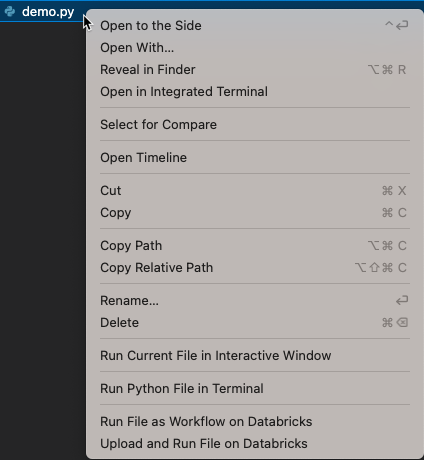
En la vista del Explorador (Ver > Explorador), haga clic con el botón derecho en el archivo de cuaderno y, a continuación, seleccione Ejecutar archivo como flujo de trabajo en Databricks en el menú contextual.
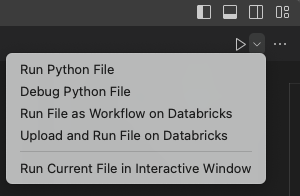
En la barra de título del editor de archivos de cuaderno, haga clic en la flecha desplegable situada junto al icono de reproducción (Ejecutar o depurar). A continuación, en la lista desplegable, haga clic en Ejecutar archivo como flujo de trabajo en Databricks.
Aparece una nueva pestaña del editor, titulada Ejecución de trabajo de Databricks. El cuaderno se ejecuta como un trabajo en el área de trabajo y el cuaderno y su salida se muestran en el área Salida de la nueva pestaña del editor.
Para ver información sobre la ejecución del trabajo, haga clic en el vínculo Id. de ejecución de tareas en la pestaña del editor de Ejecución de trabajos de Databricks. El área de trabajo se abre y los detalles de la ejecución del trabajo se muestran en el área de trabajo.